
LeetCode 30. 串联所有单词的子串 | Python
30. 串联所有单词的子串
题目来源:力扣(LeetCode)https://leetcode-cn.com/problems/substring-with-concatenation-of-all-words
题目
给定一个字符串 s 和一些长度相同的单词 words。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。
注意子串要与 words 中的单词完全匹配,中间不能有其他字符,但不需要考虑 words 中单词串联的顺序。
示例 1:
输入:
s = "barfoothefoobarman",
words = ["foo","bar"]
输出:[0,9]
解释:
从索引 0 和 9 开始的子串分别是 "barfoo" 和 "foobar" 。
输出的顺序不重要, [9,0] 也是有效答案。
示例 2:
输入:
s = "wordgoodgoodgoodbestword",
words = ["word","good","best","word"]
输出:[]
解题思路
思路:滑动窗口
先用最简单的思路去尝试看能否解决问题。题目中说明要我们找到子串与 words 的单词完全匹配。那么最简单的思路就是判断子串是否符合,符合就将索引放到列表中,最后返回。

具体的做法如上图,循环遍历索引,判断子串是否符合。这里主要的问题是如何判断子串是否符合?
题目中有个提示【注意子串要与 words 中的单词完全匹配,中间不能有其他字符,但不需要考虑 words 中单词串联的顺序。】,也就是说题目中并不要求子串完全按照顺序,只需要对应个数相等且中间连接部分不会有其他字符。这样就算匹配。
这里,我们可以借助哈希表解决。一个哈希表存储 words 的信息,键存储的是单词,值存储的是单词出现的个数。另外一个哈希表同样键存储的是单词,值存储单词出现的个数,这个哈希表在遍历字符串的同时进行维护,然后与前面的哈希表中的值进行比对。这里会出现如下情况:
- 当遍历存储的值大于存储 words 的哈希表中的 value 值时,显然是不成立的。进行判断下一个子串
- 当小于的时候,接着进行判断。
- 当子串完全符合的情况,那么这就是要找的子串,将其索引存入列表中,最后返回。
但这里其实不必移动 1 个字符去匹配。题目有提及【一些长度相同的单词 words】,也就是说 words 中的单词的长度都是一样的。这样,每次移动就可以移动的偏移量就是单词的长度。
那么对单词使用滑动窗口,步长就是单词的长度 word_len。那么在 0 ~ word_len 的范围内,这里每个都作为滑动窗口的起点,进行滑动,就能覆盖所有字符串的组合。
下图为示例 1 以及使用滑动窗口的大致图解:
示例 1
输入:
s = "barfoothefoobarman",
words = ["foo","bar"]
输出:[0,9]
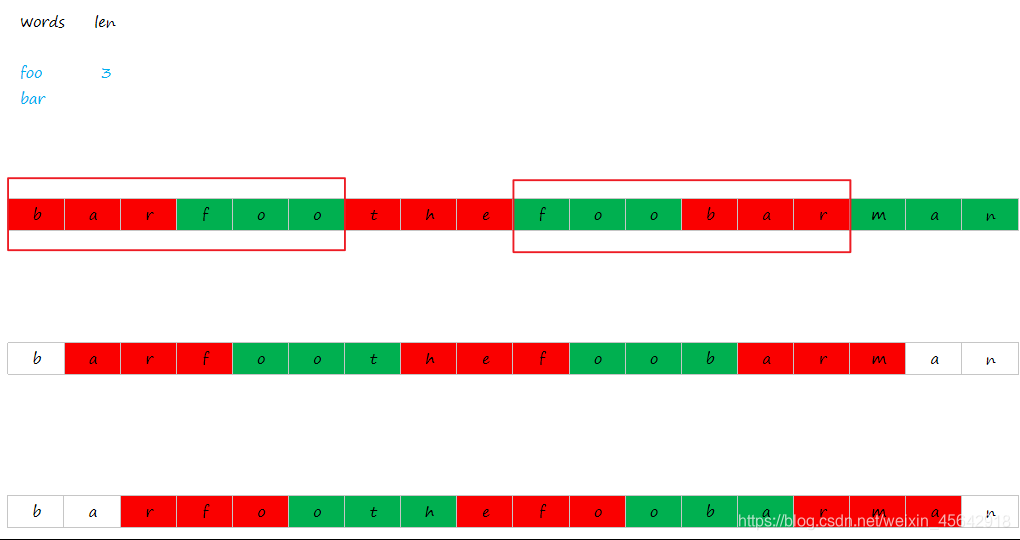
具体实现的代码如下。
代码实现
class Solution:
def findSubstring(self, s: str, words: List[str]) -> List[int]:
from collections import Counter
# 处理特殊情况
if not s or not words:
return []
# 哈希表统计单词出现次数,用以后续比较
word_cnt = Counter(words)
# 单词长度
word_len = len(words[0])
# 返回结果列表
ans = []
# 遍历,进行窗口滑动
for i in range(word_len):
left = i
right = i
cnt = 0
# 哈希表记录窗口的单词出现次数
window = Counter()
# 限定边界
# 这里表示窗口的内容不足以组成串联所有单词的子串,循环结束
while left + len(words) * word_len <= len(s):
# 窗口单词出现的次数,与 word_cnt 对比
while cnt < len(words):
word = s[right:right+word_len]
# 如果单词不在 words 中,或者此时单词数量大于 words 中的单词数量时,退出循环另外处理
# 单词次数相等也跳出另外判断
# 否则更新哈希表 window
if (word not in words) or (window[word] >= word_cnt[word]):
break
window[word] += 1
cnt += 1
right += word_len
# 先判断哈希表是否相等,相等则加入返回列表中
if word_cnt == window:
ans.append(left)
# 再处理单词数溢出的情况
# 区分在于单词是否在 words 中
if word in words:
# 剔除左边部分
left_word = s[left: left+word_len]
window[left_word] -= 1
left += word_len
cnt -= 1
else:
# 如果单词不在 words 中,
# 清空哈希表,重置窗口开始位置
right += word_len
window.clear()
left = right
cnt = 0
return ans
实现结果
总结
- 题意要求子串与 words 中单词匹配,那么就用最简单的思路,遍历字符串,判断子串是否与 words 中的单词是否匹配;
- 主要的难题在于如何判断是否匹配?题目中提及【中间不能有其他字符,但不需要考虑 words 中单词串联的顺序】,也就是说求得连续且单词个数相等时,就可以判定为匹配;
- 综合考虑,可以使用滑动窗口来解决问题。又有题目中说明 words 中的单词长度是一致的,那么滑动窗口的步长就是单词的长度 word_len。
- 在 0 ~ word_len 的范围内,每个位置都作为滑动窗口的起点,进行滑动,这样就能覆盖所有子串的组合。
文章原创,如果感觉写得还好,欢迎关注点赞。微信公众号《书所集录》同步更新,同样欢迎关注。
