
webpack4之路(4)-优化进阶
1.使用SplitChunksPlugin插件进行代码分割
什么是代码分割:
它允许你将一个文件分割成多个文件。如果使用得好,它能大幅度的提高应用性能。主要原因是因为我们代码是基于浏览器缓存代码。每当我们对某一个文件做点点改变时webpack重新打包,引入的hash名字就会变化,导致访问站点时用户要重新进行下载更新。而我们用的依赖却很少变动。所以我们应该要把依赖分离成单独的文件。这样用户就不需要重新下载。
首先我们先安装一个插件,并在两个js文件引入并使用
npm i loadsh
import _ from "loadsh"; // 引入loadsh const arr = [12,3,5,6,5,1,2,4,2,] console.log(_.chunk(arr,2))
我们可以先在不配置前进行打包看效果:
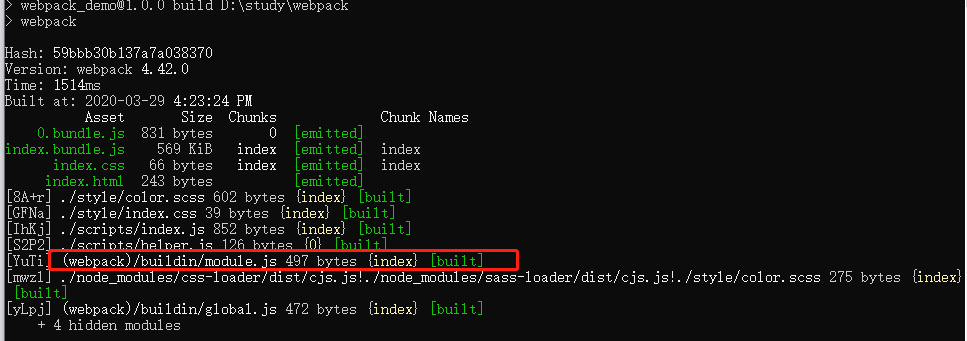
同时你会在看到打包出来的两个js文件里都包含了loadsh库的一份拷贝,这非常不友好。其实webpack的默认行为会给共享库创建分离的文件,就是涉及到异步chunks,即我们异步导入文件。现在我们稍微改下我们的webpack.config.js配置
optimization: { splitChunks: { chunks: "all" } },
现在进行打包你就会发现变化了
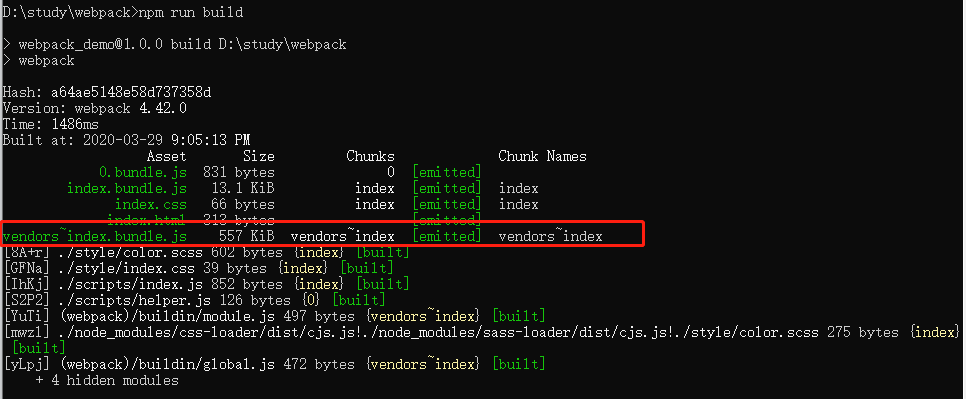
现在我们看到创建了一个附加名叫vendors~index.bundle.js的文件,其包含了loadsh库。事实上这全靠配置中本身默认固有 一个cacheGroups的配置
optimization:{ splitChunks: { /** 1. 三个值 async 仅提取按需载入的module initial 仅提取同步载入的module all 按需、同步都有提取 */ chunks: "all", // 只有导入的模块 大于 该值 才会 做代码分割 (单位字节) minSize: 30000, // 提取出的新chunk在两次压缩之前要小于多少kb,默认为0,即不做限制 maxSize: 0, // 被提取的chunk最少需要被多少chunks共同引入 minChunks: 1, // 按需加载的代码块(vendor-chunk)并行请求的数量小于或等于5个 maxAsyncRequests: 5, // 初始加载的代码块,并行请求的数量小于或者等于3个 maxInitialRequests: 3, // 默认命名 连接符 automaticNameDelimiter: '~', /** name 为true时,分割文件名为 [缓存组名][连接符][入口文件名].js name 为false时,分割文件名为 [模块id][连接符][入口文件名].js 如果 缓存组存在 name 属性时 以缓存组的name属性为准 */ name: true, // 缓存组 当符合 代码分割的 条件时 就会进入 缓存组 把各个模块进行分组,最后一块打包 cacheGroups: { // 如果 引入文件 在node_modules 会被打包 这个缓存组(vendors) vendors: { // 只分割 node_modules文件夹下的模块 test: /[\\/]node_modules[\\/]/, // 优先级 因为如果 同时满足 vendors、和default 哪个优先级高 就会打包到哪个缓存组 priority: -10 }, default: { // 表示这个库 至少被多少个chunks引入, minChunks: 2, priority: -20, // 如果 这个模块已经 被分到 vendors组,这里无需在分割 直接引用 分割后的 reuseExistingChunk: true } } } }
首先,vendors这一项指明了包括来自node_modules目录中的文件。其实default这一项表示默认的缓存组,包括其他共享模块。我们还应该仔细看看上面的配置项才能更好的进行使用哦。
目前了解到的就是这些,如果以后工作有更好优化再来记录。
参考资料:

