

神经网络的数据表示
前面例子使用的数据存储在多维 Numpy 数组中,也叫张量(tensor)。 张量这一概念的核心在于,它是一个数据容器。它包含的数据几乎总是数值数据,因此它是数字的容器。你可能对矩阵很熟悉,它是二维张量。张量是矩阵向任意维度的推广, 张量的维度(dimension)通常叫作轴(axis)。
1、标量(0D 张量)
仅包含一个数字的张量叫作标量(scalar,也叫标量张量、零维张量、0D 张量)。在 Numpy 中,一个 float32 或 float64 的数字就是一个标量张量(或标量数组)。你可以用 ndim 属性来查看一个 Numpy 张量的轴的个数。标量张量有 0 个轴(ndim == 0)。张量轴的个数也叫作阶(rank)。


import numpy as np x = np.array(12) x #输出array(12) x.ndim #输出0
2、向量(1D 张量)
数字组成的数组叫作向量(vector)或一维张量(1D 张量)。一维张量只有一个轴。维度 (dimensionality)可以表示沿着某个轴上的元素个数(比如 5D 向量),也可以表示张量中轴的个 数(比如 5D 张量)。
x = np.array([12, 3, 6, 14, 7]) x #输出array([12, 3, 6, 14, 7]) x.ndim #输出1 #这个向量5个元素,所以被称为5D向量。 #不要把5D向量和5D张量弄混。5D 向量只有一个轴,沿着轴有5个维度,而5D张量有5个轴(沿着每个轴可能有任意个维度)。
3、矩阵(2D 张量)
向量组成的数组叫作矩阵(matrix)或二维张量(2D 张量)。矩阵有 2 个轴(通常叫作行和 列)。你可以将矩阵直观地理解为数字组成的矩形网格。
x = np.array([[5, 78, 2, 34, 0], [6, 79, 3, 35, 1], [7, 80, 4, 36, 2]]) x.ndim #输出2 #第一个轴上的元素叫作行(row),第二个轴上的元素叫作列(column)。在上面的例子中, [5, 78, 2, 34, 0] 是 x 的第一行,[5, 6, 7] 是第一列。
4、3D张量与更高维张量
将多个矩阵组合成一个新的数组,可以得到一个 3D 张量,你可以将其直观地理解为数字组成的立方体。
x = np.array([[[5, 78, 2, 34, 0], [6, 79, 3, 35, 1], [7, 80, 4, 36, 2]], [[5, 78, 2, 34, 0], [6, 79, 3, 35, 1], [7, 80, 4, 36, 2]], [[5, 78, 2, 34, 0], [6, 79, 3, 35, 1], [7, 80, 4, 36, 2]]]) x.ndim #输出3
将多个3D张量组合成一个数组,可以创建一个 4D 张量,以此类推。深度学习处理的一般是 0D 到 4D 的张量,但处理视频数据时可能会遇到 5D 张量。
5、关键属性
张量是由以下三个关键属性来定义的。
轴的个数(阶)——例如,3D 张量有 3 个轴,矩阵有 2 个轴。这在 Numpy 等 Python 库中也叫张量的 ndim。
形状——这是一个整数元组,表示张量沿每个轴的维度大小(元素个数)。例如,前面矩阵示例的形状为 (3, 5),3D 张量示例的形状为 (3, 3, 5)。向量的形状只包含一个元素,比如 (5,),而标量的形状为空,即 ()。
数据类型(在 Python 库中通常叫作 dtype)——这是张量中所包含数据的类型,例如,张量的类型可以是 float32、uint8、float64 等。在极少数情况下,你可能会遇到字符 (char)张量。注意,Numpy(以及大多数其他库)中不存在字符串张量,因为张量存储在预先分配的连续内存段中,而字符串的长度是可变的,无法用这种方式存储。
#首先加载 MNIST 数据集。 from keras.datasets import mnist (train_images, train_labels), (test_images, test_labels) = mnist.load_data() #给出张量 train_images 的轴的个数,即 ndim 属性。 print(train_images.ndim) 3 #形状。 print(train_images.shape) (60000, 28, 28) #数据类型,即 dtype 属性。 print(train_images.dtype) uint8 #这里 train_images 是一个由8位整数组成的3D张量。更确切地说,它是 60 000个矩阵组成的数组,每个矩阵由 28×28 个整数组成。每个这样的矩阵都是一张灰度图像,元素取值范围为 0~255。 #我们用 Matplotlib 库(Python 标准科学套件的一部分)来显示这个 3D 张量中的第 4 个数字 digit = train_images[4] import matplotlib.pyplot as plt plt.imshow(digit, cmap=plt.cm.binary) plt.show()
6、在 Numpy 中操作张量
在前面的例子中,使用语法 train_images[i] 来选择沿着第一个轴的特定数字。选择张量的特定元素叫作张量切片(tensor slicing)。
#下面这个例子选择第10~100个数字(不包括第 100 个),并将其放在形状为 (90, 28, 28) 的数组中。 my_slice = train_images[10:100] print(my_slice.shape #(90, 28, 28) #它等同于下面这个更复杂的写法,给出了切片沿着每个张量轴的起始索引和结束索引。 注意,: 等同于选择整个轴。 my_slice = train_images[10:100, :, :] my_slice.shape #(90, 28, 28) #等同于前面的例子 my_slice = train_images[10:100, 0:28, 0:28] my_slice.shape #(90, 28, 28)
一般来说,可以沿着每个张量轴在任意两个索引之间进行选择。例如,你可以在所有图像的右下角选出14 像素×14 像素的区域:
my_slice = train_images[:, 14:, 14:]
也可以使用负数索引。与 Python 列表中的负数索引类似,它表示与当前轴终点的相对位置。 你可以在图像中心裁剪出 14 像素×14 像素的区域:
my_slice = train_images[:, 7:-7, 7:-7]
7、数据批量的概念
深度学习中所有数据张量的第一个轴(0 轴,因为索引从 0 开始)都是样本轴 (samples axis,有时也叫样本维度)。在 MNIST 的例子中,样本就是数字图像。 此外,深度学习模型不会同时处理整个数据集,而是将数据拆分成小批量。
#批量大小为 128。 batch = train_images[:128] #然后是下一个批量。 batch = train_images[128:256] #然后是第 n 个批量。 batch = train_images[128 * n:128 * (n + 1)] #对于这种批量张量,第一个轴(0 轴)叫作批量轴(batch axis)或批量维度(batch dimension)。
8、现实世界中的数据张量
你需要处理的数据总是以下类别之一。
向量数据:2D 张量,形状为 (samples, features)。
时间序列数据或序列数据:3D 张量,形状为 (samples, timesteps, features)。
图像:4D 张量,形状为 (samples, height, width, channels) 或 (samples, channels, height, width)。
视频:5D 张量,形状为 (samples, frames, height, width, channels) 或 (samples, frames, channels, height, width)。
9、向量数据
这是最常见的数据。对于这种数据集,每个数据点都被编码为一个向量,因此一个数据批量就被编码为 2D 张量(即向量组成的数组),其中第一个轴是样本轴,第二个轴是特征轴。
#人口统计数据集, 其中包括每个人的年龄、邮编和收入。 每个人可以表示为包含3个值的向量,而整个数据集包含100000个人,因此可以存储在形状为 (100000, 3) 的 2D 张量中。 #文本文档数据集, 将每个文档表示为每个单词在其中出现的次数(字典中包含20000个单词)。 每个文档被编码为包含20000个值的向量(每个值对应于字典中每个单词的出现次数) 整个数据集包含500个文档,因此可以存储在形状为 (500, 20000) 的张量中
10、时间序列数据或序列数据
当时间(或序列顺序)对于数据很重要时,应该将数据存储在带有时间轴的 3D 张量中。 每个样本可以被编码为一个向量序列(即 2D 张量),因此一个数据批量就被编码为一个 3D 张 量。根据惯例,时间轴始终是第 2 个轴(索引为 1 的轴)。
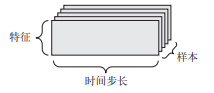
#股票价格数据集 每一分钟,我们将股票的当前价格、前一分钟的最高价格和前一分钟的最低价格保存下来,因此每分钟被编码为一个3D向量。 整个交易日被编码为一个形状为 (390, 3) 的2D张量(一个交易日有 390 分钟),而250天的数据则可以保存在一个形状为 (250, 390, 3) 的3D张量中。 这里每个样本是一天的股票数据。 #推文数据集。 我们将每条推文编码为280个字符组成的序列,而每个字符又来自于128个字符组成的字母表。 每个字符可以被编码为大小为128的二进制向量(只有在该字符对应的索引位置取值为 1,其他元素都为 0。 那么每条推文可以被编码为一个形状为 (280, 128) 的 2D 张量,而包含100万条推文的数据集则可以存储在一个形状为 (1000000, 280, 128) 的张量中。
11、图像数据
图像通常具有三个维度:高度、宽度和颜色深度。虽然灰度图像(比如 MNIST 数字图像) 只有一个颜色通道,因此可以保存在 2D 张量中,但按照惯例,图像张量始终都是 3D 张量,灰度图像的彩色通道只有一维。因此,如果图像大小为 256×256,那么128张灰度图像组成的批量可以保存在一个形状为 (128, 256, 256, 1) 的张量中,而128张彩色图像组成的批量则可以保存在一个形状为 (128, 256, 256, 3) 的张量中。

#通道在后(channels-last)的约定(在 TensorFlow 中使用) ensorFlow 机器学习框架将颜色深度轴放在最后:(samples, height, width, color_depth)。, #通道在前(channels-first)的约定(在 Theano 中使用) Theano 将图像深度轴放在批量轴之后:(samples, color_depth, height, width)。 如果采用Theano 约定,前面的两个例子将变成 (128, 1, 256, 256) 和 (128, 3, 256, 256)。 Keras 框架同时支持这两种格式。
12、视频数据
视频可以看作一系列帧, 每一帧都是一张彩色图像。由于每一帧都可以保存在一个形状为 (height, width, color_ depth) 的 3D 张量中,因此一系列帧可以保存在一个形状为 (frames, height, width, color_depth) 的 4D 张量中,而不同视频组成的批量则可以保存在一个 5D 张量中,其形状为 (samples, frames, height, width, color_depth)。
一个以每秒4帧采样的60秒YouTube视频片段。视频尺寸为144×256,这个 视频共有240帧。 4个这样的视频片段组成的批量将保存在形状为 (4, 240, 144, 256, 3) 的张量中。总共有 106 168 320 个值! 如果张量的数据类型(dtype)是 float32,每个值都是 32 位,那么这个张量共有 405MB。 现实生活中遇到的视频要小得多,因为它们不以 float32 格式存储,而且通常被大大压缩,比如 MPEG 格式。
以上内容来自《python深度学习》,仅作学习笔记记录~

