
了解NTFS压缩
在您选中“压缩内容以节省磁盘空间”复选框之前,最好先了解一下这对磁盘上运行的快乐的小字节、字节和半字节有何影响。
备份应用程序在备份压缩文件时通常会收到ERROR U DISK U FULL errors,当驱动器上还有几GB的可用空间时,这会导致相当大的混乱。复制压缩文件时也可能出现其他问题。本文的目标是让读者更全面地了解压缩NTFS文件时到底发生了什么。
Compression Units
NTFS使用一个名为“压缩单元”的参数来定义数据流中压缩字节范围的粒度和对齐方式。压缩单元的大小完全基于NTFS簇大小(有关详细信息,请参阅下表)。在下面的描述中,缩写“CU”用于描述压缩单元和/或其尺寸。
CU的默认大小是16个簇,尽管CU的实际大小实际上取决于磁盘的簇大小。下面的图表显示了与每个有效的NTFS簇大小相对应的CU大小。
| Cluster Size | Compression Unit | Compression Unit (hex bytes) |
| 512 Bytes | 8 KB | 0x2000 |
| 1 KB | 16 KB | 0x4000 |
| 2 KB | 32 KB | 0x8000 |
| 4 KB | 64 KB | 0x10000 |
| 8 KB | 64 KB | 0x10000 |
| 16 KB | 64 KB | 0x10000 |
| 32 KB | 64 KB | 0x10000 |
| 64 KB | 64 KB | 0x10000 |
本机NTFS压缩在群集大小大于4KB的卷上不起作用,但仍可以使用稀疏文件压缩。
NTFS稀疏文件
NTFS的稀疏文件特性允许应用程序创建非常大的文件,这些文件主要由零范围组成,而无需为零范围实际分配LCN(逻辑群集)。对于代码头,可以通过使用FSCTL_SET_SPARSE IO控制代码调用DeviceIoControl来完成,如下所示。
BOOL SetSparse(HANDLE hFile) { DWORD Bytes; return DeviceIoControl(hFile, FSCTL_SET_SPARSE, NULL, 0, NULL, 0, &Bytes, NULL); }
若要指定零范围,则应用程序必须使用FSCTL_SET_ZERO_DATA IO控制代码调用DeviceIoControl。
BOOL ZeroRange(HANDLE hFile, LARGE_INTEGER RangeStart, LONGLONG RangeLength) { FILE_ZERO_DATA_INFORMATION FileZeroData; DWORD Bytes; FileZeroData.FileOffset.QuadPart = RangeStart.QuadPart; FileZeroData.BeyondFinalZero.QuadPart = RangeStart.QuadPart + RangeLength + 1; return DeviceIoControl( hFile, FSCTL_SET_ZERO_DATA, &FileZeroData, sizeof(FILE_ZERO_DATA_INFORMATION), NULL, 0, &Bytes, NULL); }
因为稀疏文件实际上不会为零范围分配空间,所以稀疏文件可以比父卷大。为此,NTFS创建一个占位符VCN(虚拟集群号)范围,不映射逻辑集群。任何访问“稀疏”范围的尝试都会导致NTFS返回一个满是零的缓冲区。访问分配的范围将导致对分配范围的正常读取。当数据写入稀疏文件时,会创建一个与包含写入字节的压缩单元边界完全对齐的分配范围。请参阅下面的示例。如果虚拟集群号vcn0x3a发生单字节写入,那么所有压缩单元3(vcn0x30-0x3f)将成为分配的LCN(逻辑集群号)范围。分配的LCN范围将填充零,并且单个字节将写入目标LCN中适当的字节偏移量。
[...] - ALLOCATED (,,,) - Compressed { } - Sparse (or free) range / 00000000000000000000000000000000000000000000000000000000000000000000000000000000 VCN 00000000000000001111111111111111222222222222222233333333333333334444444444444444 \ 0123456789abcdef0123456789abcdef0123456789abcdef0123456789abcdef0123456789abcdef CU0 CU1 CU2 CU3 CU4 |++++++++++++++||++++++++++++++||++++++++++++++||++++++++++++++||++++++++++++++| { }[..............]{ } Extents { VCN = 0x0 LEN = 0x30 CU0 - CU2 VCN = 0x30 LEN = 0x10: LCN = 0x2a21f CU3 VCN = 0x10 LEN = 0x10 CU4 }
下面是使用稀疏文件API创建的2GB文件的屏幕截图。
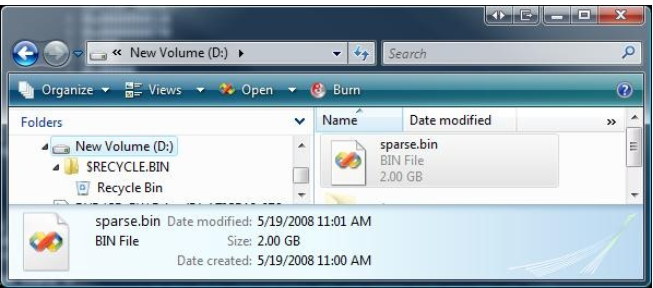
请注意,这个卷只有76.9MB,但在根文件夹中有一个2GB的文件。
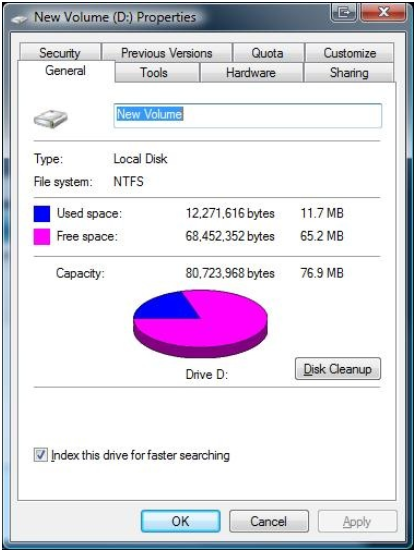
如果我们试图用COPY命令复制这个稀疏文件,它将失败。这是因为COPY不知道如何复制文件上的稀疏属性,所以它试图在D:的根目录中创建一个真正的2GB文件。当尝试将大型数据库文件从一个卷移动到另一个卷时,可能会发生这种情况。如果您的数据库应用程序使用稀疏属性,那么在将数据库移动到其他卷时,最好使用数据库软件的备份/还原功能。
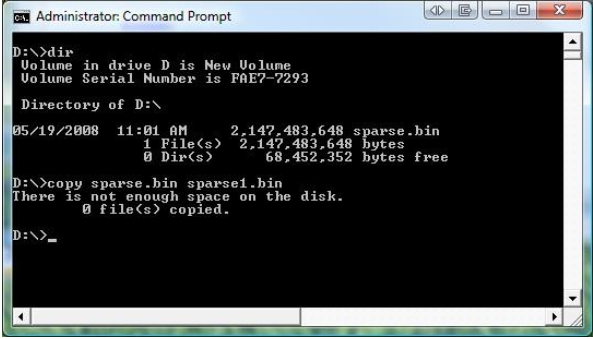
现在让我们用COMPACT实用程序查看文件的属性。请注意,该文件显示为压缩文件,并且具有巨大的压缩比。
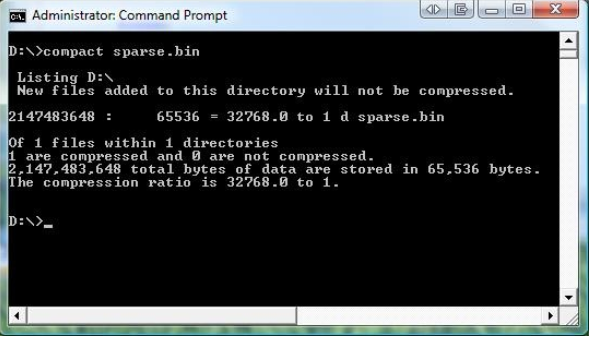
如果您返回并从资源管理器查看文件属性,您将注意到没有压缩复选框(或任何其他指示文件已压缩)。这是因为shell不检查文件中的稀疏位。
简而言之,在将稀疏文件从一个位置移动到另一个位置时要小心。应用程序告诉文件系统零范围的偏移量,因此您应该始终将稀疏文件的管理留给创建它们的应用程序。手动移动或复制稀疏文件可能会导致意外结果。
NTFS Compression
既然我们已经讨论了稀疏文件,我们将继续讨论传统的NTFS压缩。NTFS通过将数据流分成CU来压缩文件(这与稀疏文件的工作方式类似)。当创建或更改流内容时,数据流中的每个CU都被单独压缩。如果压缩导致减少一个或多个群集,则压缩单元将以其压缩格式写入磁盘。然后将稀疏VCN范围固定到压缩VCN范围的末尾以进行对齐(如下例所示)。如果数据压缩不足以将一个集群的大小缩小,那么整个CU将以未压缩的形式写入磁盘。
这种设计使得随机访问非常快,因为只有一个CU需要解压缩才能访问文件中的任何单个VCN。不幸的是,大型顺序访问相对较慢,因为许多CU的解压需要执行顺序操作(如备份)。
在下面的示例中,压缩文件由六组映射对(编码的文件范围)组成。三个分配的范围与三个稀疏范围共存。稀疏范围的目的是保持压缩单元边界上的VCN对齐。这可以防止NTFS在用户希望读取文件中的小字节范围时不得不解压缩整个文件。第一个压缩单元(CU0)压缩了12.5%(这使得分配的范围缩小了2个VCNs)。在文件扩展数据块中添加了一个额外的空闲VCN范围,作为CU尾部释放的lcn的占位符。第二个分配的压缩单元(CU1)与第一个相似,只是CU压缩了大约50%。
NTFS不能压缩CU2和CU3,但部分CU4可压缩69%。因此,CU2和CU3未压缩,而CU4从VCN 0x40压缩到0x44。因此,CU2、CU3和CU4是一个单独的运行,但该运行包含压缩和未压缩VCN的混合。
注意:每组括号代表已分配或可用空间的连续运行。一组NTFS映射对描述了每组括号。
[...] - ALLOCATED (,,,) - Compressed { } - Sparse (or free) range / 00000000000000000000000000000000000000000000000000000000000000000000000000000000 VCN 00000000000000001111111111111111222222222222222233333333333333334444444444444444 \ 0123456789abcdef0123456789abcdef0123456789abcdef0123456789abcdef0123456789abcdef CU0 CU1 CU2 CU3 CU4 |++++++++++++++||++++++++++++++||++++++++++++++||++++++++++++++||++++++++++++++| (,,,,,,,,,,,,){}(,,,,,,){ }[...............................,,,,){ } Extents { VCN = 0x0 LEN = 0xe : LCN = 0x29e32d CU0 VCN = 0xe LEN = 0x2 CU0 VCN = 0x10 LEN = 0x8 : LCN = 0x2a291f CU1 VCN = 0x18 LEN = 0x8 CU1 VCN = 0x20 LEN = 0x25 : LCN = 0x39dd49 CU2 - CU4 VCN = 0x45 LEN = 0xb CU4 }
现在我们来讨论这个设计的局限性。下面是一些在读/写压缩文件时出错的例子。
Disk full error during a backup read operation or file copy
- NTFS确定正在访问哪个压缩单元。
- 读取压缩单元的整个分配范围。
- 如果单元没有被压缩,那么我们跳到第5步。否则,NTFS将尝试保留(但不分配)将解压缩的CU写回磁盘所需的空间。如果磁盘上的可用空间不足,则应用程序在读取期间可能会出现错误“磁盘已满”。
- CU将在内存中解压缩。
- 解压后的字节范围将映射到缓存中并返回到请求应用程序。
- 如果CU的一部分在缓存中被改变…
步骤3中的保留磁盘空间将变为已分配空间。
铜的含量将被压缩并冲洗回新分配的区域(LCN位置通常不会改变)。
CU中的任何可恢复磁盘空间都将被释放。
Failure to copy a large file to a compressed folder
这是压缩中最常见的问题,目前的解决方案是教育用户了解限制。NTFS压缩大约为每16个数据簇创建一个文件片段。因为标准压缩允许的最大集群大小是4K,所以允许的最大压缩单元是64KB。为了将一个100GB的文件压缩成64KB的部分,最终可能会有1638400个片段。编码1638400个片段对于文件系统来说是有问题的,并且可能导致创建压缩文件失败。在Vista及更高版本上,文件复制将失败,并受到状态“文件”和“系统”的限制。在早期版本中,状态代码为status\u unficient\u RESOURCES。如果可能,请避免对较大或对系统性能至关重要的文件使用压缩。
我收到了来自NTFS主要开发负责人关于这个博客的反馈。幸运的是,大多数反馈都很好,但他要求我增加一个最大尺寸的建议。根据我们开发团队的研究,对于集群大小为4KB的卷上的压缩文件,50-60GB是一个“合理的大小”。对于集群大小较小的卷,这个“合理大小”会急剧下降。
压缩.VHD(虚拟硬盘)文件会导致虚拟机性能降低


