错误模型(一)
错误模型试图回答的基本问题是:如何将“错误”传达给程序员和系统用户?
在回答这个问题时,最大的挑战之一就是定义错误的实际含义。大多数语言将Bug和可恢复的错误归为同一类,并使用相同的工具来处理它们。例如空引用或越界数组访问的处理方式与网络连接问题或解析错误相同。乍一看,这种一致性似乎不错,但它有根深蒂固的问题。尤其是,它具有误导性,并且经常导致不可靠的代码。
我们的总体解决方案是提供一个双管齐下的错误模型。一方面,由于编程错误,产生了fail-fast 异常,我们称之为快速终止。另一方面,您已经静态地检查了可恢复错误的异常。两者在编程模型和背后的机制上都非常不同。快速终止在一瞬间毫无歉意地破坏了整个过程,拒绝运行任何用户代码。)当然,异常有助于恢复,但是有深层类型的系统支持来帮助检查和验证。
这趟旅程漫长而曲折。为了讲述这个故事,我把这篇文章分成六个主要方面:
- 基础知识
- Bug是不可恢复的错误!
- 可靠性、容错性和隔离性
- Bug:终止、断言和契约
- 可恢复错误:类型定向异常
- 回顾与结论
基础知识
让我们从检查我们的体系结构原则、需求和从现有系统中获得的经验开始。
原则
当我们开始这段旅程时,我们提出了一个好的错误模型的几个要求:
可靠:错误模型是整个系统可靠性的基础。毕竟,我们在构建一个系统,所以可靠性是最重要的。你甚至可能会指责我们过分追求它。我们的口头禅指导了大部分编程模型的开发,它是“通过构造来纠正”
性能:常见的情况需要非常快。这意味着成功路径的开销尽可能接近于零。故障路径的任何额外成本都必须完全“按需付费”。与许多愿意过度惩罚错误路径的现代系统不同,我们有几个性能关键组件,这是不可接受的,因此错误也必须相当快。
并发性:现代系统多说是分布式,高度并发。这引起了其他错误模型中通常是事后考虑的问题。他们需要在我们的前面和中间。
可诊断的:调试失败,无论是交互的还是事后的,都需要是高效且容易的。
可组合的:错误模型的核心是一个编程语言特性,位于开发人员代码表达式的中心。因此,它必须与系统的其他特性提供熟悉的正交性和可组合性。集成单独编写的组件必须是自然、可靠和可预测的。
这是一个大胆的主张,但我认为我们最终取得了成功的所有方面。
基础知识
现有的错误模型不满足上述要求。至少不完全。如果一个维度做得好,另一个维度就会做得差。例如,错误代码可以有很好的可靠性,但许多程序员发现它们容易出错;此外,很容易做错误的事情——比如忘记检查一个——这显然违反了“成功之坑”的要求。考虑到我们所追求的极端可靠性水平,我们对大多数模型都不满意也就不足为奇了。如果您在优化易用性而不是可靠性,就像您在脚本语言中所做的那样,那么您的结论将会有很大的不同。像Java和C语言这样的语言很困难,因为它们正处于场景的十字路口——有时用于系统,有时用于应用程序——但总的来说,它们的错误模型非常不适合我们的需要。最后,还记得这个故事开始于2000年代中期,在开始之前,Rust和Swift可供我们考虑。从那以后,这三种语言在错误模型方面做了一些伟大的工作。
Error Codes
错误代码可以说是最简单的错误模型。这个想法非常基本,甚至不需要语言或运行时支持。函数只返回一个值(通常为整数)以指示成功或失败:
int foo() {
// <try something here>
if (failed) {
return 1;
}
return 0;
}
这是典型的模式,0表示成功,非0表示失败。调用者必须检查:
int err = foo(); if (err) { // Error! Deal with it. }
大多数系统提供表示错误代码集的常量,而不是幻数。可能有也可能没有函数可用于获取有关最新错误的额外信息(如标准C中的errno和Win32中的GetLastError)。返回代码在语言中并不特别,它只是一个返回值。
C长期使用错误代码。因此,大多数基于C的生态系统都是如此。使用返回代码规程编写的低级系统代码比任何其他规程都多。Linux做到了,无数的关键任务和实时系统也做到了。所以公平地说,他们有着令人印象深刻的业绩记录!
尽管返回码很简单,但它确实附带了一些问题;总之:
- 性能会受到影响。
- 编程模型的可用性可能很差。
- 最大问题:你可能会不小心忘记检查错误。
让我们依次讨论每一种语言,并举出上面提到的语言的例子。
性能
错误代码检测未通过“一般情况下零开销;特殊情况下按需付费”的测试:
对调用惯例影响。现在有两个值要返回(对于非void返回函数):实际返回值和可能的错误。这会消耗更多的寄存器和/或堆栈空间,从而降低调用的效率。内联当然有助于恢复可内联调用的子集。在任何被调用者可能失败的地方,都会有分支注入call site。我把这样的成本称为“花生酱”,很难直接衡量其影响。在某些系统里,我们能够进行实验和测量,并确认是的,确实,这里的成本是非常可观的。还有一个次要的影响是,因为函数包含更多的分支,所以更容易混淆优化器。
这可能会让一些人感到惊讶,因为毫无疑问,每个人都听说过“例外是缓慢的”,事实证明,他们不必如此。而且,如果做得好,它们会从热路径中获取错误处理代码和数据,这会提高I-cache和TLB的性能,而与上面的开销相比,这会明显降低它们的性能。许多高性能系统都是使用返回码构建的,所以您可能认为我在挑剔。和我们做的许多事情一样,一个容易受到批评的是我们采取了太极端的做法。但问题越来越重
忘了检查
很容易忘记检查返回码。例如,考虑下面函数:
int foo() { ... }foo();
// Keep going -- but foo might have failed!此时,您已经屏蔽了程序中潜在的严重错误。这很容易成为错误代码中最令人烦恼和最具破坏性的问题。正如我稍后将展示的,option types有助于解决函数式语言的这个问题。但在基于C的语言中,甚至在现代语法中,这是一个真正的问题。
这个问题不是理论上的。我遇到过很多忽略返回代码的错误,我相信你也遇到过。实际上,在开发这个非常错误的模型时,我的团队遇到了一些有趣的错误。例如,当我们将微软的语音服务器移植到我们系统时,我们发现80%的台湾中文(zh-tw)请求失败。然而,并没有以开发人员立即看到的方式失败;相反,客户会得到一个胡言乱语的回应。起初,我们以为是我们的错。但后来我们在原始代码中发现了一个默默吞没的HRESULT。一旦我们把它送到自己的系统,这个虫子就被扔到我们的脸上,被发现,并在移植后立即修复。这一经验无疑为我们提供了有关错误代码的意见。
令我惊讶的是,Go将未使用的导入设置为一个错误,但却错过了这个更为关键的错误。太近了!的确,你可以添加一个静态分析检查器,或者像大多数商用C++编译器那样使用一个“未使用的返回值”警告。但一旦你错过了将其添加到语言核心的机会,作为一项要求,这些技术都不会因为对噪音分析的抱怨而达到临界质量。
在我们的系统里,我们没有使用错误代码,但是不能意外忽略返回值对于系统的整体可靠性很重要。有多少次你调试一个问题却发现根本原因是你忘记使用的返回值?甚至有安全漏洞,这是根本原因。当然,让开发人员说忽略并不是万无一失的,因为他们仍然可能做错事。但这至少是明确和可审计的。
编程模型可用性
在带有错误代码的基于C的语言中,在函数调用之后,您将编写大量手工编写的if检查。如果您的许多函数都失败了(在分配失败也与返回代码通信的C程序中,这种情况经常发生),那么这可能特别乏味。返回多个值也很笨拙。在许多方面,返回代码的可用性实际上是优雅的。您可以重用非常简单的原语(整数、返回和if分支),这些原语可用于无数其他情况。在我看来,错误是编程的一个重要方面,语言应该能帮你解决这个问题。Go有一个很好的语法捷径,可以让标准的返回代码检查稍微轻松一些:
if err := foo(); err != nil {
// Deal with the error.
}
注意,我们已经调用了foo并检查了一行中的错误是否为non-nil。很整洁。然而,可用性问题并不止于此。通常,给定函数中的许多错误应该共享一些恢复或修正逻辑。许多C程序员使用标签和goto来构造这样的代码。例如:
int error;
// ...
error = step1();
if (error) {
goto Error;
}
// ...
error = step2();
if (error) {
goto Error;
}
// ...
// Normal function exit.
return 0;
// ...
Error:
// Do something about `error`.
return error;
不用说,这是一种只有母亲才会喜欢的密码。在像D、C和Java这样的语言中,您终于有了finally blocks来更直接地编码这个“before scope exits”模式。同样,微软的专有扩展C++最终也供了。D提供范围,Go提供延迟。所有这些都有助于消除goto错误模式。
接下来,假设我的函数想要返回一个实际值,并且可能会出错?我们已经烧掉了返回槽,所以有两种明显的可能性:
- 我们可以将返回槽用于这两个值中的一个(通常是错误),将另一个槽(像指针参数一样)用于这两个值中的另一个(通常是实际值)。这是C语言中常见的方法。
- 我们可以返回一个数据结构,在它的结构中携带两者的可能性。我们将看到,这在函数式语言中很常见。但是在一种像C,甚至Go-even这样缺乏参数多态性的语言中,您会丢失关于返回值的输入信息,所以这不太常见。当然,C++增加了模板,因此原则上它可以做到这一点,但是因为它增加了异常,所以缺少返回代码的生态系统。
Returning Values “On The Side”
C中第一种方法的示例如下:
int foo(int* out) { // <try something here> if (failed) { return 1; } *out = 42; return 0; }
真正的值必须“真正的值必须“在边上”返回,这使得callsites很笨拙:”返回,这使得callsites很笨拙:
int value; int ret = foo(&value); if (ret) { // Error! Deal with it. } else { // Use value... }
除了笨拙之外,此模式还会干扰编译器的明确赋值分析,从而削弱您获得有关使用未初始化值之类的良好警告的能力。Go以更好的语法来解决这个问题,这要归功于多值返回:
func foo() (int, error) {
if failed {
return 0, errors.New("Bad things happened")
}
return 42, nil
}
因此,callsites要干净得多。再加上早期的“如果检查错误,则使用单行”功能(这是一个微妙的转折,因为乍一看,值返回不在范围内,但确实在范围内),这样做会更好:
if value, err := foo(); err != nil {
// Error! Deal with it.
} else {
// Use value ...
}
注意,这也有助于提醒您检查错误。然而,这并不是一帆风顺的,因为函数可以返回一个错误而不返回任何其他错误,此时忘记检查它和C语言一样简单。
正如我上面提到的,有些人会在可用性方面反对我。我想。使用错误代码的一大吸引力是对当今过于复杂的语言的反叛。我们已经失去了很多让C如此优雅的东西——你通常可以看到任何一行代码,猜出它翻译成什么机器代码。我不反对这些观点。事实上,我非常喜欢Go的模型,而不是unchecked异常和Java的checked异常的化身。我们是否做了太多的尝试和要求,等等,你很快就会看到?我不确定。Go的错误模型往往是语言中最具分裂性的一个方面;这可能很大程度上是因为你不能像在大多数语言中那样草率地处理错误。最后,很难对它们进行比较。我相信两者都可以用来编写可靠的代码。
数据结构中的返回值
函数式语言通过将一个值或一个错误的可能性打包到一个数据结构中来解决许多可用性挑战。因为如果你想对callsite上的值做任何有用的事情,你就不得不把错误和值分开,这要归功于数据流的编程风格,你可能会这样做,所以很容易避免忘记检查错误的致命问题。
要了解现代人对此的看法,请查看Scala的选项类型。不幸的是,一些语言,比如ML家族的语言,甚至Scala(由于它的JVM传统),将这个优雅的模型与未检查异常的世界混合在一起。这玷污了单数据结构方法的优雅。
Haskell做了一些更酷的事情,在仍然使用错误值和本地控制流的情况下给人一种异常处理的错觉:C++程序员在异常或错误返回代码是否正确的问题上存在着一个古老的争论。尼克拉斯·沃思认为例外是GoTo的转世,因此在他的语言中省略了它们。Haskell以一种外交的方式解决了这个问题:函数返回错误代码,但是错误代码的处理并不会使代码变得丑陋。
这里的技巧是支持所有熟悉的抛出和捕获模式,但使用monad而不是控制流。尽管Rust也使用错误代码,但它也是功能性错误类型的样式。例如,假设我们正在Go中编写一个名为bar的函数:我们希望调用foo,如果失败,只需将错误传播给调用方:
func bar() error {
if value, err := foo(); err != nil {
return err
} else {
// Use value ...
}
}
Rust的后面版本不再简洁了。然而,它可能会让C程序员对它的外来模式匹配语法感到不安(这是一个真正的问题,但不是一个解决方案)。然而,任何熟悉函数式编程的人可能都不会眨眼,这种方法肯定会提醒您处理错误:
fn bar() -> Result<(), Error> {
match foo() {
Ok(value) => /* Use value ... */,
Err(err) => return Err(err)
}
}
但现在好多了。试试看 try! ,将样板文件(如最近的示例)简化为单个表达式:
fn bar() -> Result<(), Error> {
let value = try!(foo);
// Use value ...
}
这将我们带到一个美丽的甜蜜的地方。它确实受到我前面提到的性能问题的影响,但是在所有其他方面都做得很好。仅仅这一点是不完整的——为此,我们需要 fail-fast)——但正如我们将看到的那样,它远远优于目前广泛使用的任何其他基于异常的模型。
Exceptions
例外的历史是迷人的。在这段旅程中,我花了无数个小时回顾这个行业的发展历程。这包括阅读一些原始的论文-像1975年的经典,异常处理:问题和一个提议的符号-除了看看几种语言的方法:Ada,Eiffel,Modula-2和3,ML,和,最鼓舞人心的,CLU。许多论文比我总结这漫长而艰辛的旅程做得更好,所以我在这里不会这么做。相反,我将专注于哪些是可行的,哪些是不可行的,以构建可靠的系统。在开发错误模型时,可靠性是我们上述要求中最重要的。如果你不能对失败做出适当的反应,那么你的系统,顾名思义,就不会很可靠。操作系统一般来说需要可靠。不幸的是,最常见的模型——未经检查的异常——在这个维度上是最糟糕的。
由于这些原因,大多数可靠的系统使用返回码而不是异常。它们使我们能够对错误条件进行局部推理并决定如何做出最佳反应。但我已经超越了自己。我们挖进去吧。
未检测 Exceptions
快速回顾一下。在未检查的异常模型中,抛出并捕获异常,而不作为类型系统或函数签名的一部分。例如:
// Foo throws an unhandled exception: void Foo() { throw new Exception(...); } // Bar calls Foo, and handles that exception: void Bar() { try { Foo(); } catch (Exception e) { // Handle the error. } } // Baz also calls Foo, but does not handle that exception: void Baz() { Foo(); // Let the error escape to our callers. }
在这个模型中,任何函数调用(有时是任何语句)都可以抛出异常,将控制权非本地转移到其他地方。哪里?谁知道呢。没有用于指导分析的注释或类型系统构件。因此,任何人都很难对程序在抛出时的状态、异常在调用堆栈上传播时发生的状态更改(可能在并发程序中的线程之间)以及在捕获或未处理时的结果状态进行推理。
当然可以试试。要做到这一点,需要阅读API文档,对代码进行手动审计,大量依赖代码审查,还要有足够的运气。这里的语言一点也帮不了你。因为失败是罕见的,所以这并不像听起来那么灾难性。我的结论是,这就是为什么许多业内人士认为未经检查的异常“足够好”的原因。他们会避开您的方式,而不去寻找常见的成功途径,而且,由于大多数人不会在非系统程序中编写健壮的错误处理代码,因此抛出异常通常会让您很快摆脱困境。抓捕然后继续行动也经常奏效。没有伤害,没有犯规。从统计学上讲,程序是有效的
对于脚本语言来说,统计正确性是可以接受的,但是对于操作系统的最低级别,或者任何关键任务应用程序或服务,这不是一个合适的解决方案。我希望这没有争议。
由于异步异常,.NET使情况变得更糟。C++也有所谓的“异步异常”:这些是由硬件错误触发的故障,如访问违规。然而,在.NET中它变得非常糟糕。任意线程几乎可以在代码的任何位置注入失败。即使是在任务的左右两边!因此,在源代码中看起来像原子的东西并不是这样的。我在10年前就写了这篇文章,尽管随着.NET普遍认识到线程中止是有问题的,风险已经降低,但挑战仍然存在。新的corecrl甚至缺少AppDomains,而新的ASP.NETCore1.0堆栈当然不像以前那样使用线程中止。但是api仍然存在。
C#的首席设计师安德斯·赫茨伯格(Anders Hejlsberg)接受了一次著名的采访,他称之为“检查异常的麻烦”。从系统程序员的角度来看,这其中的大部分让你挠头。没有任何声明证实C的目标客户是rapid应用程序开发人员,而不仅仅是:
比尔·维纳斯:但是在这种情况下,即使是在一种没有检查异常的语言中,你也不会破坏他们的代码吗?如果foo的新版本将抛出一个新的异常,客户应该考虑处理这个异常,难道他们的代码不是因为他们在编写代码时没有预料到这个异常而被破坏的吗?
安德斯:不,因为在很多情况下,人们不在乎。他们不会处理这些异常。它们的消息循环周围有一个底层异常处理程序。那个处理程序只会弹出一个对话框,说明出了什么问题并继续。程序员通过编写try finally's everywhere来保护代码,因此如果发生异常,他们会正确地退出,但实际上他们对处理异常并不感兴趣。
这让我想起了Visual Basic中的On Error Resume Next,以及Windows窗体自动捕获和吞咽应用程序抛出的错误并尝试继续的方式。我并不是因为安德斯的观点而责怪他;见鬼,因为C#的大受欢迎,我相信,考虑到当时的气候,这是正确的选择。但这肯定不是编写操作系统代码的方法。C++至少尝试用抛出异常规范提供比未检查异常更好的东西。不幸的是,这一功能依赖于动态执行,它在瞬间敲响了丧钟。
如果我编写了一个函数void f()throw(SomeError),那么f的主体仍然可以自由调用抛出SomeError以外的函数。类似地,如果我声明f不抛出异常,使用void f()throw(),仍然可以调用抛出的对象。因此,为了实现声明的契约,编译器和运行时必须确保,如果发生这种情况,将调用std::unexpected来作为响应中断进程。
我不是唯一一个承认这个设计是错误的人。事实上,throw现在已经被弃用了。一个详细的WG21论文,它描述了异常规范,描述了C++是如何在这里结束的,并且在其开篇陈述中提供了这一点:实践证明,异常规范几乎毫无价值,同时给程序增加了可衡量的开销。
有人列举了三个反对throw的理由。三个原因中的两个是动态选择的结果:运行时检查(及其相关的不透明故障模式)和运行时性能开销。第三个原因,在泛型代码中缺乏组合,可以使用适当的类型系统来处理(无可否认,这是要付出代价的)。
但最糟糕的是,治疗方法依赖于另一个动态实施的构造——noexcept说明符——在我看来,它和疾病一样糟糕。
“异常安全”是C++社区中经常讨论的一种实践。这种方法巧妙地从调用方的角度对函数在故障、状态转换和内存管理方面的行为进行了分类。一个函数可以分为四种:不抛出意味着保证了前进的进程,不会出现异常;强安全意味着状态转换是原子性的,失败不会留下部分提交的状态或损坏的不变量;基本安全意味着,尽管一个函数可能部分提交状态更改,不变量不会被破坏,泄漏也不会被阻止;最后,没有安全意味着一切皆有可能。这种分类法非常有帮助,我鼓励任何人对错误行为都要有意识和严谨,可以使用这种方法或类似的方法。即使你在使用错误代码。问题是,在使用未经检查的异常的系统中,基本上不可能遵循这些准则,除了叶节点数据结构调用一组小的、易于审核的其他函数。想想看:为了保证所有地方的强安全性,您需要考虑所有函数调用抛出的可能性,并相应地保护周围的代码。这要么意味着要防御性地编程,信任另一个函数有文档记录的英语散文(它没有被计算机检查),运气好,只调用noexcept函数,要么只希望得到最好的结果。多亏了RAII,基本安全性的无泄漏方面更容易实现——而如今由于智能指针,这一点非常常见——但即使是损坏的不变量也很难防止。文章异常处理:一种错误的安全感很好地总结了这一点。
对于C++,真正的解决方案很容易预测,而且很简单:对于健壮的系统程序,不要使用异常。这是嵌入式C++的方法,除了C++的许多实时和关键任务准则之外,包括NASA的喷气推进实验室。Mars上的C++肯定不会在任何时候使用异常。
因此,如果你能安全地避免异常,并坚持C++中类似C的返回代码,那又有什么用呢?
整个C++生态系统都使用异常。要遵守上述指导,您必须避免使用语言的重要部分,以及图书馆生态系统的重要部分。要使用标准模板库吗?太糟糕了,它使用异常。想使用Boost吗?太糟糕了,它使用异常。你的分配器可能抛出错误的分配。等等。这甚至会导致疯狂,就像人们创建现有库的分叉来消除异常一样。例如,Windows内核有自己的不使用异常的STL分支。这种生态系统的分岔既不令人愉快,也不实用。
这一团糟使我们陷入困境。尤其是因为许多语言使用未经检查的异常。很明显,它们不适合编写低级、可靠的系统代码。(我确信我会通过这样直率地说出一些C++敌人)在多年后在MIDRI中编写代码后,它会让我流泪,并编写使用未经检查的异常的代码;即使简单地代码审查也是一种折磨。但“谢天谢地”,我们已经检查了Java的异常,以便从中学习和借鉴……对吧?
检测的Exceptions
啊,检查了异常。几乎每一个Java程序员,以及每一个从一臂之遥观察Java的人,都喜欢敲打这个碎布娃娃。不公平的是,在我看来,当你将其与未经检查的异常混乱进行比较时。在Java中,您基本上知道一个方法可能抛出什么,因为一个方法必须这样做:
void foo() throws FooException, BarException { ... }
现在调用方知道调用foo可能导致抛出FooException或BarException。在调用的地方,程序员现在必须决定:
1)按原样传播抛出的异常,
2)捕获并处理它们,或者
3)以某种方式转换抛出的异常类型(甚至可能“完全忘记”该类型)。例如:
// 1) Propagate exceptions as-is: void bar() throws FooException, BarException { foo(); } // 2) Catch and deal with them: void bar() { try { foo(); } catch (FooException e) { // Deal with the FooException error conditions. } catch (BarException e) { // Deal with the BarException error conditions. } } // 3) Transform the exception types being thrown: void bar() throws Exception { foo(); }
- 异常用于传递不可恢复的错误,如空解引用、除以零等。
- 由于我们的小朋友RuntimeException,您实际上并不知道可能抛出的所有内容。因为Java对所有错误条件都使用异常,甚至是上面提到的bug,所以设计人员意识到人们会对所有这些异常规范感到恼火。所以他们引入了一种未经检查的异常。也就是说,方法可以在不声明的情况下抛出它,因此调用方可以无缝地调用它。
- 尽管签名声明异常类型,但在调用站点上没有指示调用可能引发的异常。
- 人们讨厌他们。
总之,人们对Java中检查异常的厌恶主要来自于,或者至少被上面的其他三个项目大大加强了。由此产生的模型似乎是两个世界中最糟糕的。它不能帮你编写防弹代码,而且很难使用。你最终在代码中写下了很多乱七八糟的东西,却没有什么好处。对你的界面进行版本控制是件麻烦事。我们稍后会看到,我们可以做得更好。
那个版本控制点值得深思。如果坚持一种类型的抛出,那么版本控制问题并不比错误代码更糟糕。一个函数要么失败,要么没有。如果你把API的版本1设计成没有失败模式,然后想在版本2中添加失败,你就完蛋了。在我看来,你应该这样。API的故障模式是其设计的一个关键部分,也是它与调用者之间的契约。正如在调用方不需要知道的情况下不会悄悄地更改API的返回类型一样,也不应该以语义上有意义的方式更改其故障模式。稍后再讨论这个有争议的问题。
CLU有一个有趣的方法,正如Barbara Liskov在1979年的一篇论文中所描述的,CLU中的异常处理。注意,他们非常关注“语言学”;换句话说,他们想要一种人们会喜欢的语言。在callsites中检查和重新分页所有错误的需要感觉更像是返回值,但是编程模型有一种更丰富和稍微声明的感觉,即我们现在所知道的异常。最重要的是,信号(他们的名字为投掷)被检查。如果出现意外信号,也可以使用方便的方法终止程序。
Exceptions的普遍问题
大多数异常系统都会有一些主要的错误,不管它们是否被选中。
首先,抛出一个异常通常是非常昂贵的。这几乎总是由于堆栈跟踪的收集。在托管系统中,收集堆栈跟踪还需要删除元数据,以创建函数符号名称字符串。但是,如果错误被捕获并处理,那么在运行时甚至不需要这些信息!诊断更好地在日志和诊断基础结构中实现,而不是在异常系统本身中实现。这些问题是正交的。不过,要真正解决上面的诊断需求,需要有东西能够恢复堆栈跟踪;千万不要低估printf调试的能力以及堆栈跟踪对它的重要性。
接下来,异常会严重损害代码质量。我在我的最后一篇文章中提到了这个话题,在C++的上下文中有关于这个主题的好文章。由于没有静态类型的系统信息,很难在编译器中对控制流建模,这会导致优化器过于保守。
大多数异常系统出错的另一件事是鼓励处理错误的粒度太粗。返回代码的支持者喜欢错误处理本地化为特定的函数调用。(我也是!)在异常处理系统中,很容易将粗粒度的try/catch块放在大量的代码上,而不必对个别的失败做出仔细的反应。这会产生几乎肯定是错误的脆弱代码;如果不是今天,那么在不可避免的重构之后,这将在未来发生。这很大程度上与拥有正确的语法有关。
最后,抛出的控制流通常是不可见的。即使使用Java来注释方法签名,也不可能审计代码体并准确地查看异常的来源。静默控制流与goto或setjmp/longjmp一样糟糕,并且使编写可靠的代码非常困难。
我们在哪儿?
在继续之前,让我们回顾一下我们的现状:
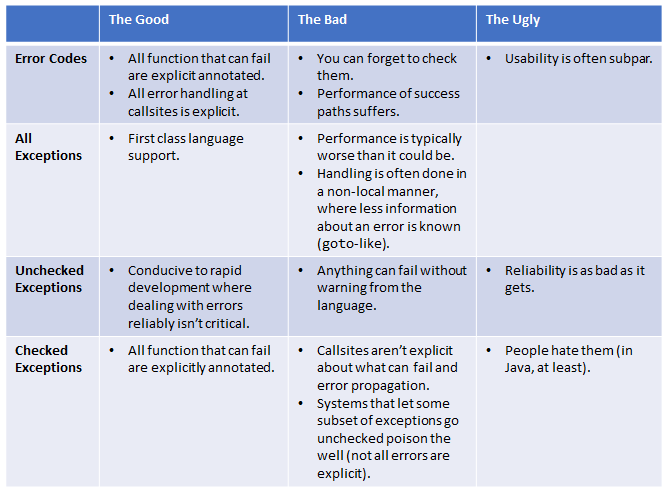
如果我们能把所有的好物都拿走,把坏蛋和丑恶的东西都抛在脑后,不是很好吗?仅此一项就将是向前迈出的一大步。但这还不够。这让我想到了我们第一个重要的“啊哈”时刻,它塑造了未来的一切。对于一类重要的错误,这些方法都不合适。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号