.pdb 文件的内部结构
粗略察看一 下.pdb 文件,会发现在其起始位置存放的是这样一个字符串“Microsoft C/C++ program database 2.00”。可以看出 PDB 是 Program Database 的首字母缩写。在 MSDN 中或 Internet 上搜索一下有关 PDB 内部结构的信息,你会发现没有任何有用的信息,唯一例外的是,在 微软的基础知识文章中,微软申明此种格式是它有的(Microsoft Corporation, 2000d)。就连 Windows 的老大 Matt Pietrek 也承认:
“ PDB符 号 表 的 格 式 并 没 有 公 开 的 文 档 。( 就 连 我 也 不 知 道 其 确 切 的 格 式 , 唯 一 知 道 的 是,它会随着 Visual C++ 的 更 新 而 更 新 。)”( Pietrek 1997a )
或许,pdb 格式会随着 Visual C/C++一起更新,不过针对当前版本的 Windows 2000 我 可以确切的告诉你 PDB 符号文件的结构。这或许是首次公开的 PDB 格式文档。但首先,还 是让我们检查一下.dbg 和.pdb 文件是如何链接到一起的。
Windows 2000 的.dbg 文件的一个显著特性是:它们包含的数据很少,几乎可以忽略它 们的 CodeView子节。下面示例给出了 ntsokrnl.exe 的.dbg 文件所包含的整个 CodeView数据, 只有区区 32 字节。
Address | 00 01 02 03-04 05 06 07 : 08 09 0A 0B-0C 0D 0E 0F | 0123456789ABCDEF ---------|-------------------------:-------------------------|----------------- 00006590 | 4E 42 31 30-00 00 00 00 : 20 7D 23 38-54 00 00 00 | NB10.... }#8T... 000065A0 | 6E 74 6F 73-6B 72 6E 6C : 2E 70 64 62-00 00 00 00 | ntoskrnl.pdb...
通常,子节总是以一个 CV_HEADER 结构开始,该结构中包 含 CodeView 的版本标识。这一次,该版本标识是 NB10MSDN(Microsoft 2000a)没能告 诉我们有关这个特殊版本的更多信息: “ NB10 ,可执行文件的这一标识表示,其调试信息保存在独立的 PDB文件中。相应的格式还有NB09或NB11。”( MSDN Library—April 2000\Specifications\Technologies and Languages\Visual C++ 5.0 Symbolic Debug Information Specification\Debug Information Format )
我并不知道 NB11 格式的内部细节,不过 PDB 格式和前面讨论的 NB09 格式一样几乎 什么也没有。第一句话很明确的说明了为什么 NB10 数据块是如此的小。所有相关的信息都 被移到了独立的文件中了,因此这个 CodeView 子节的主要作用就是提供指向实际数据的链 接。如示例 1-8 所暗示的,在 ntoskrnl.pdb 文件中一定可以找到实际的符号信息。
CV_HEADER 结构是自解释的。其后的两个成员的偏移量分别为:0x8 和 0xC,它们的 名字分别为:dSignature 和 dAge,在.dbg 和.pdb 文件链接的过程中它们将扮演重要角色。 dSignature 是一个 32 位的 UNIX 风格的时间戳,它保存了调试信息构建的日期和时间(自 01-01-1970 以来逝去的秒数)。w2k_img.dll 提供了两个函数:imgTimeUnpack()和 imgTimePack()用来将 dSignature 和 Windows 风格的时间格式进行相互的转化。我还不是非 常清楚 dAge 成员的确切含义。目前知道的是:dAge 成员的初始值为 1,每次修改 PDB 数 据后其值就会增一。dSignature 和 dAge 共同构成一个 64 位的 ID,调试器可以使用它来验 证给定的 PDB 文件是否与它引用的.dbg 文件相匹配。PDB 文件在它的一个数据流中包含着 两个值的一个副本,因此调试器可以拒绝处理不相匹配的.dbg/.pdb 文件。
无论你何时遇到格式未知的数据结构,你应该做的第一件事就是使用十六进制 Dump 浏览器察看这些结构。本书附带的w2k_dump.exe可很好的完成这一工作。通过检查Windows 2000 PDB 文件,如 ntoskrnl.pdb 或 ntfs.pdb,你会发现这些文件拥有如下一些共同特性:
- 这些文件似乎都被划分为多个大小固定的块,一般情况下,每个块的大小为 0x400 字节。
- 某些块包含一长串 1,但偶而会被一小段连续的 0 打断。
- 文件中的信息并不必须是连续的。有时,数据会在块的边界处突然结束,但又会在 文件的其它地方继续开始。
- 有些数据块会在文件中反复出现。
CodeView 的 NB10 子节 typedef struct _CV_NB10 // PDB reference { CV_HEADER Header; DWORD dSignature; // seconds since 01-01-1970 DWORD dAge; // 1++ BYTE abPdbName[]; // zero-terminated } CV_NB10, *PCV_NB10, **PPCV_NB10; #define CV_NB10_ sizeof(CV_NB10)
终弄清这些复合文件的典型特点花费了我不少时间。复合文件是将一个小型文件系统 打包到一个单一文件中。“文件系统”这一修饰词可很好的解释上面得到的观察结果:
- 一个文件系统会将磁盘细化为大小固定的扇区,一组扇区又构成一个文件(此文件 件大小可变)。由扇区构成的文件可位于磁盘的任何位置上,并不要求必须是连续 的。文件/扇区的对应关系定义在文件目录中。
- 一个复合文件将一个原始磁盘文件细化为大小固定的页,一组页构成一个流 (stream),并且流的大小可变。由页构成的复合文件可位于原始文件中的任何位 置,这些页并不必须是连续的。流和页的对应关系定义在流目录中。
很显然,文件系统中的格式和复合文件格式差不多是一一对应的,只需简单的将“扇区” 替换为“页”,将“文件”替换为“流(Stream)”。对照文件系统可以很好的解释为什么 PDB 文件是按大小固定的块组织起来的,同时还解释了为什么这些块并不一定都是连续的。不过, 一页中几乎都是二进制 1 的块又代表什么呢?实际上,这种类型的数据在文件系统中是很常 见的。为了跟踪磁盘上已用和还未使用的扇区,很多文件系统都维护了一个二进制位的分配 数组,数组中的每个二进制位对应文件系统中的一个扇区(或一簇扇区)。如果一个扇区未 使用,其对应的二进制位就将被设置为 1。当文件系统为文件分配空间时,它就会扫描这个 分配位数组,以找出未使用的扇区。在将扇区加入到文件中后,文件系统就将对应得分配位 设为 0。复合文件的页和流也采用了相似的处理方式。一长串的二进制 1 代表还未使用的页, 二进制 0 表示对应的页已分配给某个流。
现在唯一的问题就是为什么有些数据块会在 PDB 文件中反复出现。同样的事情也出现 在磁盘的扇区上。当文件系统中的一个文件被多次重写时,每个写操作可能会使用不同的扇 区来存放数据。因此,磁盘上某些空扇区中可能会包含旧数据的副本。这在文件系统中不算 是什么问题。如果扇区在分配数组中标识为未使用,那么该扇区上有什么数据就无所谓了。 这样的扇区很快就会在另一个文件中被使用,其原有内容将被新的数据覆盖掉。对应文件系 统的这一特性,我们再来看复合文件,这意味着我们观察到的那些重复的页应该是修改留下 的副本。可以安全地忽略它们;我们唯一需要关心的就是那些在流目录(stream directory) 中被引用到的页。
现在已经介绍完了PDB文件的基本结构,接下来我们将检查构成PDB文件的那些基本的 数据块。列表1-23给出了PDB头部的布局。在PDB_HEADER的开始位置有一个文件字符串 给出了当前PDB的版本标识。该标识字符串以EOF字符(ASCII码为0x1A)结束。在其后还 有一个附加的数字:0x0000474A,如果将该数字解释为字符串的话,则为:”JG\0\0”。或许 这代表PDB格式的初设计者吧。嵌入的EOF字符有一个很好的作用:如果普通用户在控制 台窗口中使用type ntoskrnl.pdb,那么将不会显示其后的数据,显示出来的信息只是:Microsoft C/C + + program database 2.00。Windows 2000所有的符号文件都是PDB 2.00 版。显然,曾经存在过PDB 1.00格式,而且其结构似乎与现在的有很大不同。
#define PDB_SIGNATURE_200 \ "Microsoft C/C++ program database 2.00\r\n\x1AJG\0" #define PDB_SIGNATURE_TEXT 40 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - typedef struct _PDB_SIGNATURE
{
BYTE abSignature [PDB_SIGNATURE_TEXT+4]; // PDB_SIGNATURE_nnn
} PDB_SIGNATURE, *PPDB_SIGNATURE, **PPPDB_SIGNATURE; #define PDB_SIGNATURE_ sizeof (PDB_SIGNATURE) // ----------------------------------------------------------------- #define PDB_STREAM_FREE -1 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - typedef struct _PDB_STREAM
{
DWORD dStreamSize; // in bytes, -1 = free stream
PWORD pwStreamPages; // array of page numbers
} PDB_STREAM, *PPDB_STREAM, **PPPDB_STREAM; #define PDB_STREAM_ sizeof (PDB_STREAM) // ----------------------------------------------------------------- #define PDB_STREAM_MASK 0x0000FFFF
#define PDB_STREAM_MAX (PDB_STREAM_MASK+1) #define PDB_STREAM_DIRECTORY 0
#define PDB_STREAM_PDB 1
#define PDB_STREAM_TPI 2
#define PDB_STREAM_DBI 3
#define PDB_STREAM_PUBSYM 7 typedef struct _PDB_ROOT
{
WORD wCount; // < PDB_STREAM_MAX
WORD wReserved; // 0
PDB_STREAM aStreams []; // stream #0 reserved for stream table
} PDB_ROOT, *PPDB_ROOT, **PPPDB_ROOT; #define PDB_ROOT_ sizeof (PDB_ROOT) #define PDB_PAGES(_r) \
((PWORD) ((PBYTE) (_r) \
+ PDB_ROOT_ \
+ ((DWORD) (_r)->wCount * PDB_STREAM_))) // ----------------------------------------------------------------- #define PDB_PAGE_SIZE_1K 0x0400 // bytes per page
#define PDB_PAGE_SIZE_2K 0x0800
#define PDB_PAGE_SIZE_4K 0x1000 #define PDB_PAGE_SHIFT_1K 10 // log2 (PDB_PAGE_SIZE_*)
#define PDB_PAGE_SHIFT_2K 11
#define PDB_PAGE_SHIFT_4K 12 #define PDB_PAGE_COUNT_1K 0xFFFF // page number < PDB_PAGE_COUNT_*
#define PDB_PAGE_COUNT_2K 0xFFFF
#define PDB_PAGE_COUNT_4K 0x7FFF // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - typedef struct _PDB_HEADER
{
PDB_SIGNATURE Signature; // PDB_SIGNATURE_200
DWORD dPageSize; // 0x0400, 0x0800, 0x1000
WORD wStartPage; // 0x0009, 0x0005, 0x0002
WORD wFilePages; // file size / dPageSize
PDB_STREAM RootStream; // stream directory
WORD awRootPages []; // pages containing PDB_ROOT
} PDB_HEADER, *PPDB_HEADER, **PPPDB_HEADER; #define PDB_HEADER_ sizeof (PDB_HEADER)
在标识字符串之后偏移量为 0x2C 处有一个名为 dPageSize 的 DWORD 类型的值,它代 表的是复合文件中每个页所占的字节数。合法的值可以是:0x0400(1KB)、0x800(2KB) 和 0x1000(4KB)。wFilePages 成员记录了 PDB 文件使用的页的总数。将 wFilePages 与 dPageSize 相乘即可得到该 PDB 文件的大小。wStartPage 是一个从零开始的页码,它指向第 一个数据页。该页的字节偏移量可由该页的页码乘以每页的大小得到。通常的值为:页号为 9 的 1KB 页(字节偏移量为 0x2400),页号为 5 的 2KB 页(字节偏移量为 0x2800)或者页 号为 2 的 4KB 页(字节偏移量为 0x2000)。在 PDB_HEADER 和第一个数据页之间的空间 保留给分配位数组,并总是从第二个页开始。这意味着,如果页大小为 1 或 2KB,则 PDB 文件使用 0x10000(64K)个分配位,每位对应 0x2000 字节(8KB)的页,如果页大小为 4KB,则使用 0x8000(32K)个分配位,每位对应 0x1000 字节(4KB)的页。以此类推, 这意味着,在页大小为 1KB 的情况下,PDB 文件可容纳 64MB 数据,在页大小为 2KB 或 4KB 的情况下,PDB 文件可容纳 128MB 数据。
PDB_HEADER 后的 RootStream 和 wRootPages[]成员记录了 PDB 文件中流目录的位 置。就像前面提到的,PDB 文件是由一组长度可变的流构成的,这些流中才包含有实际的 数据。流的位置及其内容是由一个单一的流目录管理的。流目录自身也存储在一个流中。我 称这个特殊的流为“Root Stream”。Root Stream 中保存着流目录(该流目录可能位于 PDB 文件的任何位置)。PDB_HEADER 的 Rootstream 和 wRootPages[]成员提供了 Root Stream 的 位置和大小。PDB_STREAM 子结构的 dStreamSize 成员给出了流目录占用的页的数目,这 些页的首地址保存在 wRootPages[]数组中,这些页包含实际的数据。
现在让我们用一个小例子来说明这一点。示例 1-9 给出了 ntoskrnl.pdb 的 PDB_HEADER 的十六进制 Dump 的部分内容。这里引用到的值由下划线标识出来。显然,这个 PDB 文件 使用的页的大小为 0x400 字节(1KB),一共使用了 0x02D1(721)个页,这样该文件的大 小则为 0xB4400(十进制 738,304)。使用 dir 命令可验证这个大小是正确的。Root Stream 的 大小为 0x5B0 字节(1456 字节),由于每个页的大小为 0x400 字节(1KB),则意味着 wRootPages[]数组中包含两项,分别位于偏移量为 0x3C 和 0x3E 处。数组中的两项内容都是 页码,需要将此页码与页大小相乘才能得到对应的字节偏移量。此处,该字节偏移量为: 0xB2000 和 0xB2800。
上面后一行给出的计算结果是 ntoskrnl.pdb 文件的流目录所占用的两组文件页的首地 址,其范围分别为:0xB2000----0xB23FF 和 0xB2800----0xB29AF。示例 1-10 给出了这些范 围的部分内容。 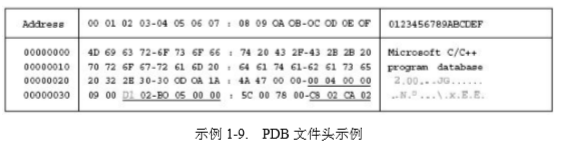
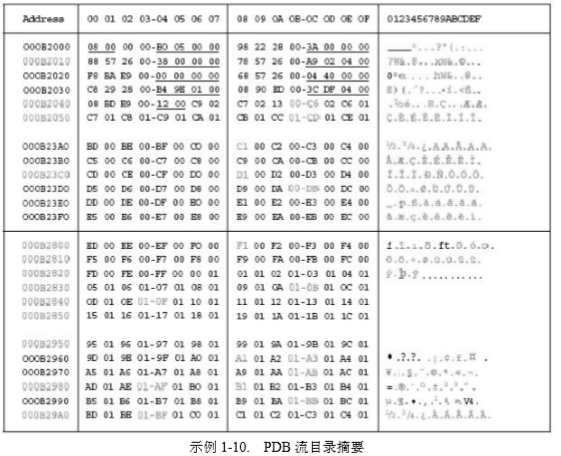
流目录由两个部分构成:一个 PDB_ROOT 结构的文件头部分,该结构定义在列表 1-24 中,另一部分是由 16 位页码构成的数组。PDB_ROOT 结构中的 wCount 成员记录了保存在 PDB 文件中的流的数目。aStream[]数组包含多个 PDB_STREAM 结构(参见列表 1-23),每 个 PDB_STREAM 结构代表一个流,紧随 aStream[]数组之后在就是页码数组。在示例 1-10 中,流的个数为 8,对应的偏移量为 0xB2000,该位置已用下划线标识出。随后的 8 个 PDB_STREAM 结构分别给出了这 8 个流的大小:0x5B0、0x3A、0x38、0x402A9、0x0、0x4004、 0x19EB4 和 0x4DF3C。这些值也都以下划线标识出。在 1KB 页模式下,流的大小为:0x2、 0x1、0x1、0x101、0x0、0x11、0x68 和 0x138,这样可计算出这些流总共占用了 0x2B6 个 页。在 PDB_STREAM 数组之后,第一个以下划线标识出来的值是页码列表中的第一个页码。 这里每个页码占用 2 个字节,这里需要考虑的是,页目录被属于其他部分的一个页截断了, 故页目录随后的偏移量为应为:0xB2044+0x400+(0x2B6*2)=0xB29B0,示例 1-10 很好的展 示了这一点。
PDB 的流目录结构
#define PDB_STREAM_DIRECTORY 0
#define PDB_STREAM_PDB 1
#define PDB_STREAM_TPI 2
#define PDB_STREAM_DBI 3
#define PDB_STREAM_PUBSYM 7 // - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - typedef struct _PDB_ROOT
{
WORD wCount; // < PDB_STREAM_MAX
WORD wReserved; // 0
PDB_STREAM aStreams []; // stream #0 reserved for stream table
} PDB_ROOT, *PPDB_ROOT, **PPPDB_ROOT; #define PDB_ROOT_ sizeof (PDB_ROOT) #define PDB_PAGES(_r) \
((PWORD) ((PBYTE) (_r) \
+ PDB_ROOT_ \
+ ((DWORD) (_r)->wCount * PDB_STREAM_)))
要找到给定的流所对应的页码需要一定的技巧,因为页目录除了流的大小之外,没有提 供任何信息。如果你对 3 号流感兴趣,那么你必须计算流 1 和流 2 所占用的页的数目,以获 取 3 号流在页码数组中的起始索引。一旦定位了指定流的页码列表,读取流中的数据就很简 单了。只需要遍历页码列表,将列表中的每个页码和每页的大小相乘,就可获得此页码对应 页的文件偏移量,然后从该偏移量处开始读取页的内容,反复如此,直到到达流的结束处, 就可读取整个流的内容了。猛地一看,解析一个 PDB 文件似乎非常费劲。但从另一个角度 看却十分简单-----因为这要比解析一个.dbg 文件简单的多。PDB 格式的这种清晰的随机访问 机制,将读取一个流的任务简化为读取连续的大小固定的页。这种优雅的数据访问机制让我 很是吃惊。
当更新一个已存在的 PDB 文件时,PDB 格式的优势就非常明显了。将使用连续的结构 体的数据插入到一个文件中,意味着将移动大量的原有数据。PDB 文件从文件系统借鉴来 的随机访问架构允许以小的开销完成删除或插入数据的操作,就像文件系统中的文件可以 很容易的修改一样。当一个流在增大时,只需改动流目录或则收缩页的边界。这种非常重要 的特性大为提高了 PDB 文件更新的灵活性。微软在基本知识库中正式提供这样一片文章: “信息:PDB 和 DBG 文件-----它们是什么以及它们是如何工作的”: “ .PDB扩展了“ Program database ”架构。此种文件用来存放调式信息,这种格式随 Visual C++ 1.0 一起引入。在将来, .PDB 文件还将包含其它的项目状态信息。格式改变的一 个重要动机是为了允许程序调试版的增量链接,第一次改变随 Visual C++ 2.0 引入。” ( Microsoft Corporation 2000e )
现在 PDB 文件的内部结构已经很清晰了,下一个问题是如何识别这些流的具体内容。 在检查完 PDB 文件的各个方面后,我得出这样一个结论:每一种流都用于特定的目的。第 一个流似乎总是包含一个流目录,第二个流包含用于验证该 PDB 文件是否与其关联的.dbg 文件相匹配的信息。例如,该流中包含的 dSignature 和 dAge 成员应该和 NB10 CodeView 节 中的对应成员一致。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号