
review | Machine learning based video coding optimizations: A survey
摘要
机器学习算法,尤其是那些采用深度学习的算法,能够从非结构化海量数据中发现知识并提供数据驱动的预测,为进一步升级视频编码技术提供了新的机会。在本文中,我们对基于机器学习的视频编码优化进行了综述,旨在为研究人员提供坚实的基础,并激发数据驱动视频编码的未来发展。
- 首先,我们分析视频数据的表示和冗余。
- 其次,我们回顾了视频编码标准的发展和关键要求。
- 随后,我们从高效率,低复杂度和高视觉质量这三个关键方对与基于机器学习的视频编码优化相关的最新进展和挑战进行了系统的调查。详细分析了他们的工作流程,代表性方案,性能,优点和缺点。
- 最后,确定挑战和机遇,这可以为学术界和工业界提供基础和未来研究的潜在方向。
1. 介绍
举了很多例子来说明数据量大。
在本文中,我们旨在提供基于机器学习的视频编码优化的全面概述。这项工作的主要贡献是:
1) 我们总结了视频的表示形式和冗余,并指出了视频编码中的三个关键挑战性问题;
2) 随后,我们概述了基于学习的低复杂度视频编码优化的最新进展,这些进展可分为统计,基于机器学习和基于端到端学习的方案。分析了他们的决策问题,代表性特征,工作流程,优缺点。
3) 我们回顾了基于学习的高效视频编码,它具有四个关键问题,包括预测编码,变换编码,熵编码和增强。介绍了他们的问题表述,代表性方案和编码性能。
4) 我们对主观视觉质量评估和基于学习的视觉质量预测进行了全面调查,这是感知视频编码的关键。基于特征提取和融合中学习模型的功能,将质量预测总结为四个类别,并进行了概述。
5) 确定了基于学习的视频编码优化中的挑战性问题和潜在的研究机会。
2. 视频数据的表示和冗余
2.1 视频数据的表示
可以将3D世界场景(\(P\))建模为具有7个参数的全光函数[5],
其中\(V_{x}, V_{y}, V_{z}\)表示3D世界坐标中的水平,垂直和深度观看位置,φ和θ表示观看方向,λ是频谱波长,t是动态场景的时间采样。 它也可以在笛卡尔坐标系中表示为[5]:
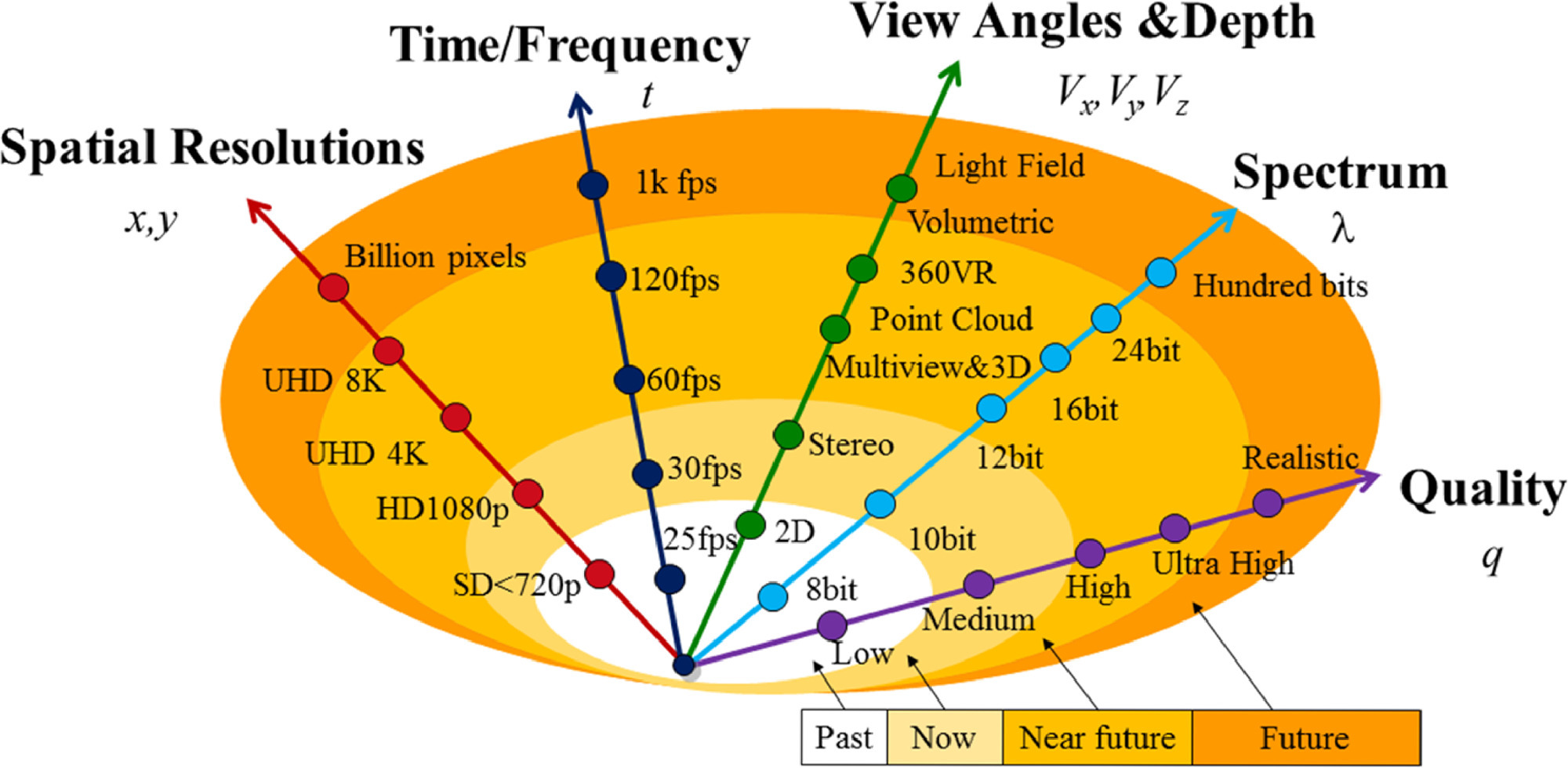
With the development of video technologies, the video representations are extended with the following five trends, as shown in Fig. 2. 1) spatial resolution (x,y): the spatial resolution of video (x,y) grows continuously to enhance the video clarity. It is from the Common Intermediate Format (CIF) (320 × 240) to Standard Definition (SD) (720p), HD (1080p) and now 4 K (3840 × 2160)/8 K (7680 × 4320), which may be further extended to billions of pixels beyond the fidelity of human vision. 2) Viewing angle and depth (Vx,Vy,Vz): the video formats are developed from 2D to stereo (2-views), multiview, free viewpoint video, 360° VR [10], light field and volumetric, towards providing 3D, immersive and six Degree of Freedoms (DoFs) vision. 3) Spectrum (λ) indicating color fidelity and amplitude resolution: Video develops from black/white, color with RGB, and now targets to the WCG and HDR for more colorful and higher dynamic presentations. It will even be upgraded to high spectrums with 16 to 24-bit per channel for some specific applications. 4) Time sampling (t): with the development of capturing and computational photography technologies [16], the video frame rate increases from 25/30 frames per second (fps) for SD video to 60 fps for HD video, and will probably be 120 fps or even higher frequency.
由于视频在采集、压缩、传输、处理或显示等过程中会产生失真,所以呈现给用户的视频不再是满足全光功能的原始表现,而是质量下降。因此,除了上述四个视频表现维度之外,从用户的角度来看,还有一个重要的维度,即质量(q)。随着通信和显示技术的发展,用户对视频体验质量(QoE)的要求不断提高。值得注意的是,视频的质量不仅限于画面质量或清晰度,还包括视觉舒适度、深度质量、疲劳、沉浸感、DoF、延迟等与视觉体验相关的视觉因素。一般由低、中、高发展到超高,趋于更加真实。从总体上看,视频呈现呈现出更加真实、交互性更强的趋势。然而,现实表现的数据量呈爆炸式增长,是传统2D视频的数千倍甚至数百万倍。因此,为了有效的编码,需要探索视频冗余。
2.2 视频中的信号和感知冗余
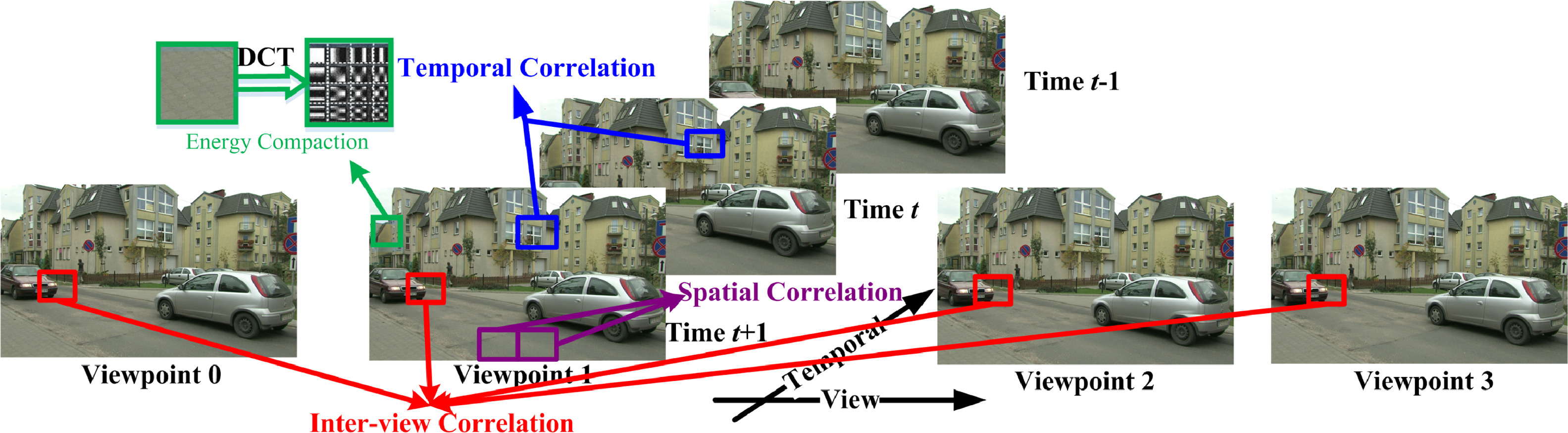
空间相关性:由于物体之间的相似性和高空间保真度,图像中空间相邻的像素或块之间具有高度的相关性
时间相关性:由于捕获帧率高,例如60帧,连续帧之间的内容高度相关,特别是静态区域
视图间的相关性:通过多个位置或角度略有不同的摄像机同时捕捉三维世界场景,获得三维深度, 不同视图之间捕获的图像也高度相关。
信号冗余:基于符号出现概率的统计熵冗余(这个不知道是什么)
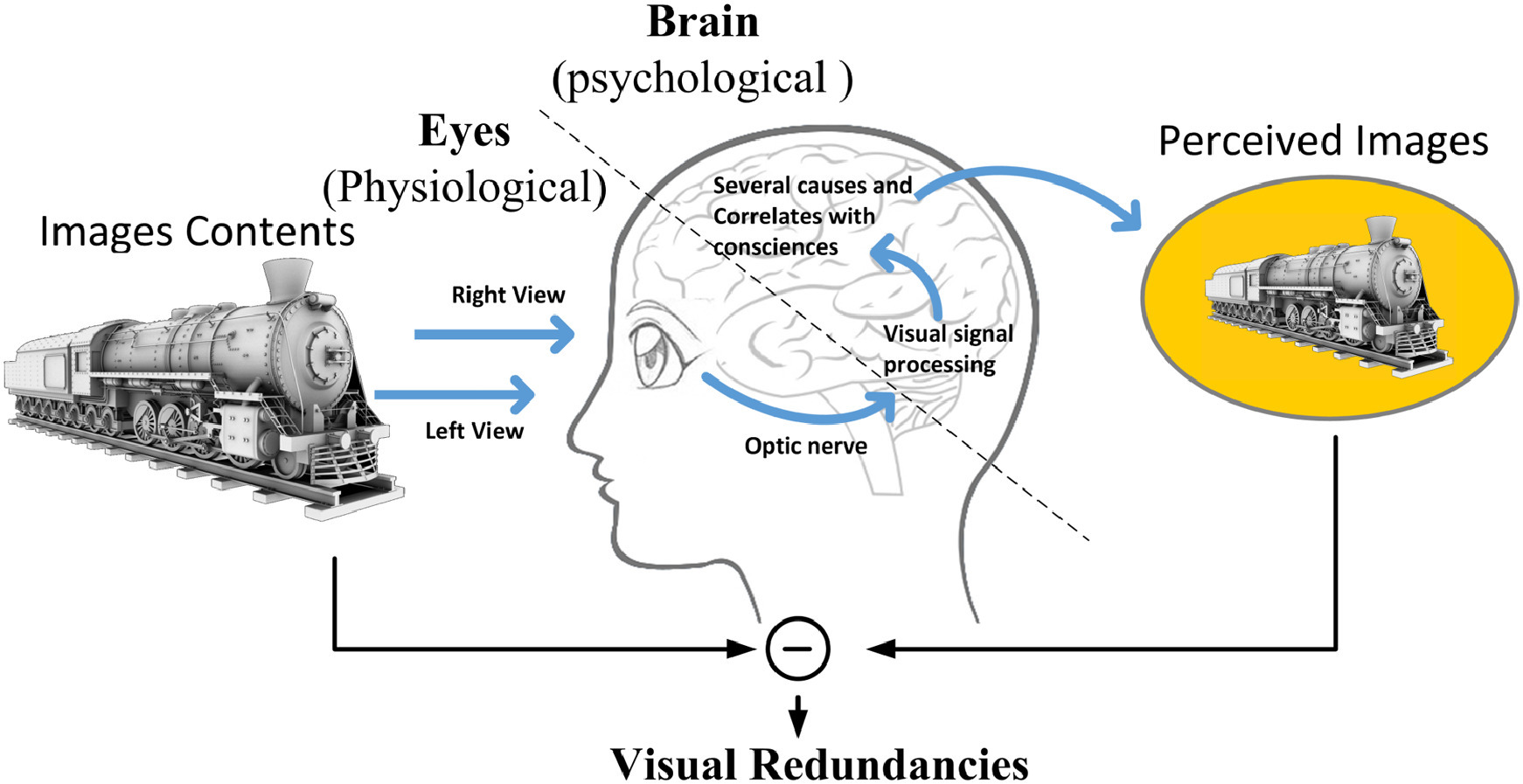
由于大多数视频最终都是由人类视觉系统(HVS)感知的,因此并非所有的视频变形都能被HVS感知到,这就解释了感知冗余的原理,如图4所示。HVS包括两个功能部分,眼睛和大脑。基于人类视觉视觉系统的生理(眼睛)和心理(大脑)研究,许多视觉道具和冗余被揭示和启发。例如,如果一幅图像的几个像素值具有非常细微的尺度变化,那么失真通常是不可察觉的,这就导致了仅仅是显著差异(JND)的概念。这些是眼睛的生理感知冗余。此外,感知敏感度随着视频内容、人类意识和兴趣而变化,即感兴趣区域(ROI),这与大脑的心理功能有关。此外,新的感知冗余仍在进一步探索中。视频编码的目的是在保持视觉质量的同时,尽可能多的挖掘和去除信号和感知冗余。在下一节中,我们将回顾视频编码标准的里程碑及其面临的主要挑战。
3. 视频编码标准的里程碑和具有挑战性的问题
3.1 视频编码标准的里程碑
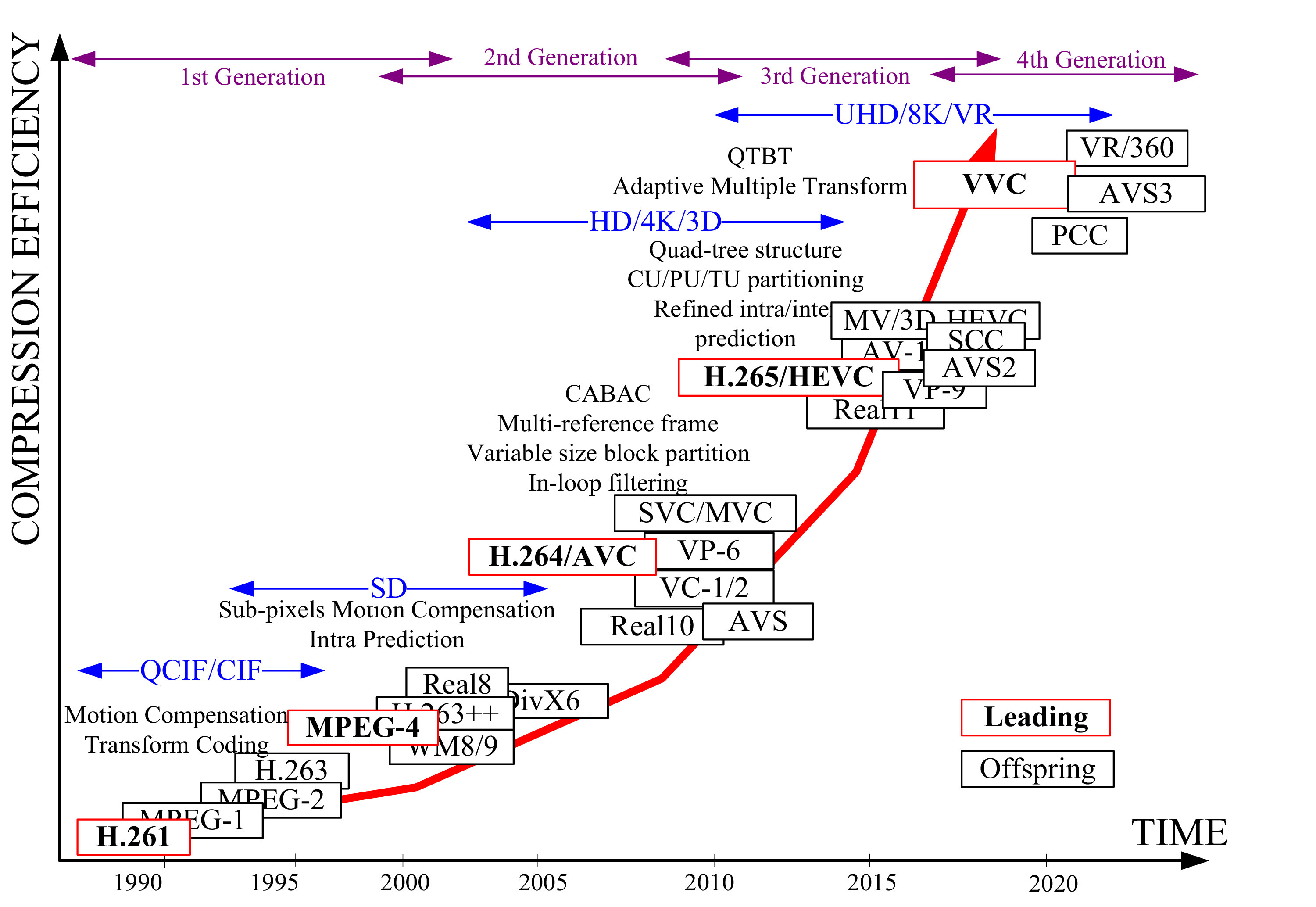
国际标准化组织(ISO/IEC)的电影专家组(MPEG)和国际电信联盟(ITU-T)的视频编码专家小组(VCEG)等世界范围内的研究人员和组织为视频编码的标准化和编码技术的进步做出了重要贡献。从图5可以看出编码标准的演变过程,在过去的三十年中,先后发布了四代的5个领先标准(H.261, MPEG-4, H.264/AVC [108], HEVC和VVC的红色矩形)。264/AVC标准是目前最成功的标准之一,在SD/HD视频应用中得到了广泛的应用。由于视频应用的高质量要求,出现了超高清视频31,流量负荷爆发式增长。2013年,MPEG和VCEG联合协作团队(JCT)针对超高清视频应用,标准化了第三代编码标准——高效视频编码(HEVC)[95]。它的扩展包括3D视频编码(3DVC),可扩展视频编码(SVC)和屏幕内容编码(SCC)也被开发用于不同的场景。在HEVC之外,由MPEG和VCEG专家组成的联合视频探索小组(Joint Video Exploration Team, IVET)于2015年成立,旨在探索HEVC之外的下一代视频编码(NGVC)的更复杂的视频编码算法。它的目标是为超高清(更高的分辨率、帧速率和比特深度)和HDR/WCG视频带来另一个50%的比特率节省,同时保持高的视觉质量给最终用户。此外,点云压缩(PCC)和360°全景VR视频编码标准也正在研究沉浸式3D和VR应用。此外,还开发了许多派生或扩展的标准,比如MV-HEVC, AVS in China, Real11 by RealNetworks, VP8/9 by谷歌,VC-1/2 by Microsoft, AV-1 by Alliance for Open Media (AOM)等。在进一步升级视频编码技术时,仍有一些共同和关键的问题需要解决。
3.2 视频编码优化的关键要求和挑战
视频编码的主要目标是在保持视频质量的同时最小化比特率。视频编码有三个关键要求:高压缩比、低复杂度和高视觉质量
3.2.1 压缩率
编码标准最重要的要求是压缩效率。每个视频编码标准的目标是将压缩比提高一倍。随着新标准中开发出越来越多的高级编码工具,压缩比已接近极限,几乎达到饱和。探索视频冗余并进一步提高压缩比变得至关重要且极具挑战性。
3.2.2 编码的复杂性
第二个关键需求是复杂性。编码和解码算法的编码复杂度与硬件成本、内存访问、计算能力等有关,与生产、使用和维护成本成正比。由于现行的编码标准采用了更先进、更复杂的编码算法来提高编码效率,使得编码复杂度比以前增加了几十倍甚至几百倍。此外,随着视图时空分辨率、位深度和视图数量的增加(如图2所示),视频编解码器的计算成本将成倍增加,可能是一百万倍。因此,为了实现UHD、3D、VR等实时逼真的广播,利用优化技术降低计算成本是非常必要的。
3.2.3 视觉质量
第三个关键要求是视觉质量,即QoE,因为在保持视觉质量的同时,视频需要尽可能的压缩。目前,图像/视频质量主要通过峰值信噪比(PSNR)或均方误差(MSE)来衡量,因为其简单。然而,PSNR和MSE并不能真正反映HVS的感知质量,HVS是一个复杂的非线性系统。虽然从心理学和生理学的角度揭示了许多重要的知觉因素,但对HVS的认识还很有限。开发一种广泛适用于视频编码的有效的质量度量来探索感知冗余是一个挑战。机器学习具有从非结构化的海量数据中发现知识的能力。许多新兴的工作利用学习算法来提高视频编码性能。根据三个关键的编码要求,一般可以分为三类,即基于学习的低复杂度编码优化,基于学习的高效编码优化和高质量编码优化。它们将在第4-6节中详细讨论。
4. 基于学习的低复杂度编码优化
4.1 视频编码中的模式判定
精细的可变块大小划分能够提高预测精度,因此减少了编码残差并且提高了预测编码中的编码效率。表1显示了从MPEG-1、2到H.264 / AVC,H.265以及持续进行的VVC的标准中的块模式演变。我们可以观察到,只有一种块,即表示为宏块的16×16块可用于H.261和MPEG-4。在H.264 / AVC中,存在七个可变块大小的分区候选,从16×16到4×4不等,分别是16×16、8×16、16×8、8×8、4×8、8×4和4×4 [108]。然后,在检查每种模式后,通过比率失真(RD)成本比较确定最佳模式。在H.265 / HEVC中,采用四叉树结构来划分每个编码树单元(CTU),其中四叉树中的编码单元(CU)大小从64×64到8×8不等[95]。对于每个CU,可以将其进一步划分为不同的预测单元(PU)模式,例如“跳过/合并”,2N×2N,N×2N,2N×N,nR×2N,nL×2N, 2N×nU,2N×nD和N×N用于INTER预测。 JVET正在进行的标准VVC采用四叉树加二叉树(QTBT)和三叉树(TT)进行块分区[1],它利用非对称二叉和三叉分区将叶子节点分为两个/三个不相等的子节点节点。此外,CU尺寸从256×256到8×8。
例如,MPEG-2,H.264 / AVC,H.265和VVC的帧内预测模式数分别为1、4 / 9、35和 67。同样,在帧间预测,参考帧选择,变换单元(TU),运动估计(ME)和环路滤波等方面,有了更精细的模式或参数,提高了编码效率。通过编码标准从H .264 / AVC向VVC的偏移,越来越多的块模式偏移被包括在内,这会使编码复杂度增加一倍。因此,需要有效的模式决策。
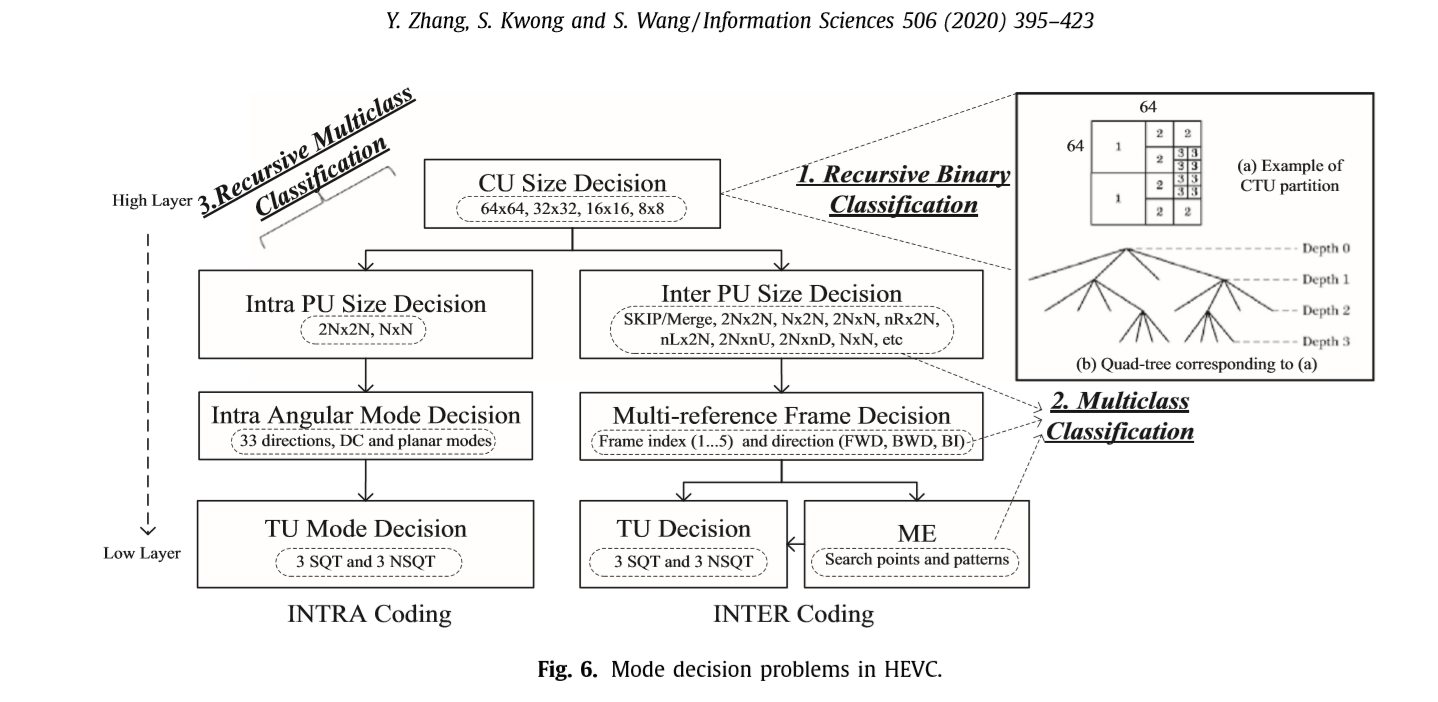
4.2 模式决策问题表示
视频编码的模式决策问题是在多个候选模式中选择最优的模式。此外,多个决策层通常以递归形式构造。一般模式决策问题是通过最小化候选(C)块和参考(R)块之间的RD代价(J)来寻找最优模式集\(\{\alpha *, \beta *, \gamma *\}\),其数学表达式为
C是候选模式,R是参考图像块。J(.)计算两个快之间的RD cost,\(\alpha,\beta\) 和\(\gamma\)是候选块的模型参数。例如,CU模式,运动向量和参考帧的序号。图6展示了HEVC不同层模式选择的问题。例如,通过确定CU是否被分割,可以将CU的大小决策表示为一个递归的二进制分类。一些层,如PU的尺寸决定,INTRA模式和多参考帧的选择,也可以表示为多类分类问题,因为有多个候选模式。此外,多决策层可以表示为递归的多类分类,这更加复杂。共有5个递归循环用于内部编码,包括顶部的CU、PU、reference frame、TU和ME。对于HEVC INTRA编码,它有四个循环,分别是CU、PU、angular prediction mode和TU size。
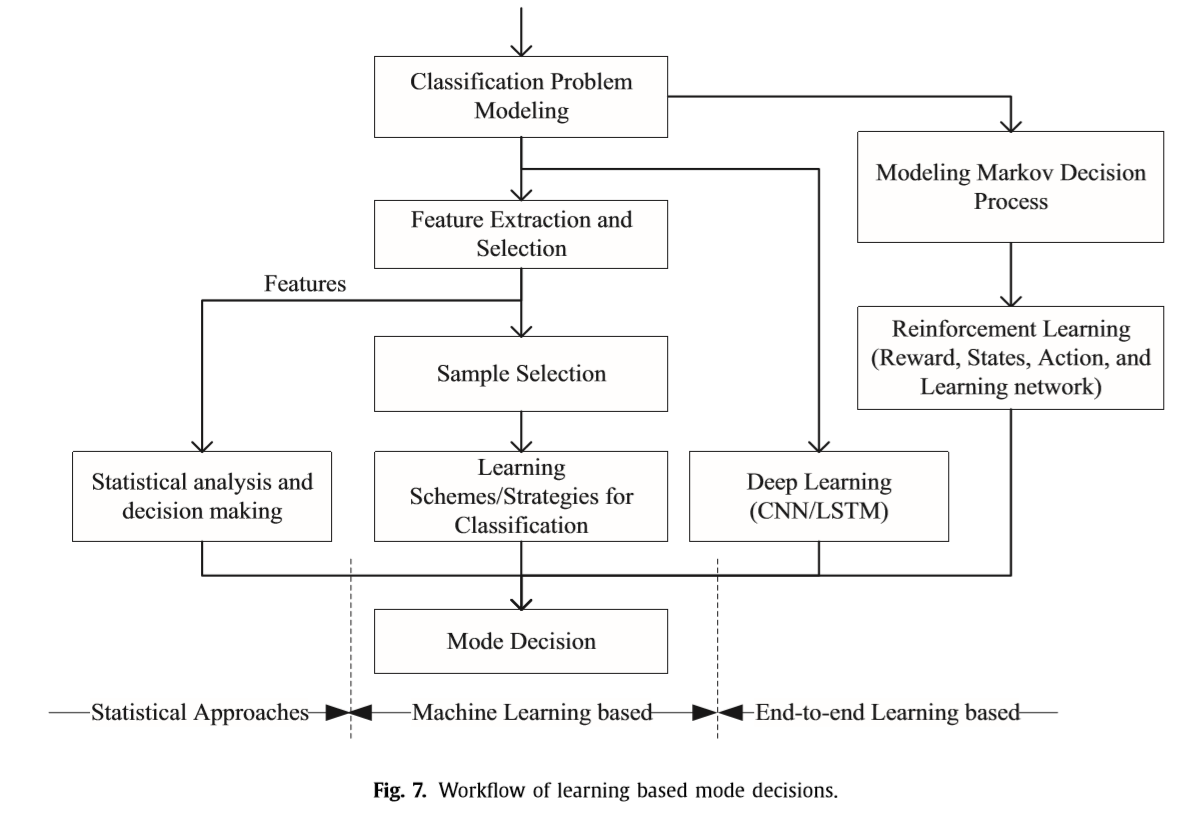
4.3 基于学习的快速模式决策
为了充分解决视频编码中的模式决策问题,现有的快速模式决策研究可分为统计方法、基于机器学习的方案和基于端到端学习的方案三大类。图7显示了这三种基于学习的模式决策的一般工作流程。
4.3.1 统计方法
编码复杂度对于H.264/AVC及更高标准至关重要。大量的统计方法被运用到减少视频编码器的复杂度上来。【68】提出了一种基于运动同质性的帧间模式决策算法,该算法使用了4x4的运动向量场,一些运动同质区域被帧间模式跳过。【90】提出了一种自适应的快速多帧选择算法,它可以利用相邻块之间的额相关性和之前搜索过的参考帧的ME信息(ME是什么)。【129】发展了一种统计的提早终止的跳过/快速模式,它是基于RD cost在H.264/MVC中提出的。HEVC有更多的候选模式也更复杂。为了减少HEVC的模式选择复杂性,【59】基于贝叶斯决策规则,采用RD cost作为PU早跳和早终止的关键特征。此外,在帧内编码中,RD cost分配和空间相关性被联合用于快速CU模式决策。在【91】中,HEVC一种快速帧内模式决策算法被提出,它联合利用了帧内CU四叉树结构的相关性和相邻CU的时间空间相关性,相邻的CU的运动向量和RD cost被发现有很强的相关性。在【128】中,提早终止和早跳模式被联合用于HEVC帧内编码中,在帧内编码中RD cost是被用作重要的特征,不同决策层的复杂度在可接受的率失真变差的前提下被联合最小化。
基本上,它们都是为了快速决策的统计方法。这些方法通用的编码框架如图7左边所示。首先,它抽取了认为设计的重要特征,例如RD cost,加权相邻CU的CU深度和或者运动向量,以及时间空间相关性。基于经验和统计确定每个重要特征的硬阈值和软阈值,来得到决策置顶中的决策高准确性。这个算法的优点是简单,易于实施,硬件友好。同时他们经常非常有效,因为他们具有非常有限的复杂度。然而他们的缺点是,1)只有一小部分数量的的特征可以被利用到每个算法中,经常是1到3个特征,这样就限制了每个模式的辨别力。2)这些特征经常是独立地个别地工作。3)这些算法的阈值经常是由一个小的数据集统计出来的,例如一小段的视频帧或序列,这样会减少这些算法的自适应性。使用更严格的预值经常提高自适应性但是会增加复杂度。
4.3.2 基于机器学习的模式决策
模式决策问题都可以看作分类问题,学习算法然后被应用于视频编码中的模式分类。在H.264/AVC中,大量的工作将机器学习运用到模式决策中。在这些方案中,7个候选模式被划分为几个子集。7个候选模式被划分为几个子集,被训练好的模型预测。二分类器,包括支持向量机,无监督聚类,反向传播神经网络和决策树等等,在H.264/AVC中,已经被用于跳过一些模式,或者在7个候选模式中决定最好的模式。同时大量的特征,已经进一步发展,比如,通过sad,时间空间相关性,跳过模式rd cost,帧内和帧间sad,运动向量区别和梯度,将RD cost归一化。
与h.264/AVC比较,Hevc有更复杂的决策问题,包括递归的4叉树模式决策,多类的tu和pu模式决策。除此之外,Hevc有更加多数量的,候选模式,这样分类任务变得更加有挑战性。在过去的这些年中,基于hevc帧内和帧间编码优化,做了许多机器学习的工作。
对于hvc帧间编码,[111],基于无监督k近邻金字塔运动发散聚类(PMD)确定最佳CU,这是从下采样帧的光流中产生的。Hevc中的cu大小决定,是一个递归的过程,[88],通过有权重的svm,提出了一个针对每个四叉树cu层划分的早终止算法,其中错误分类造成的RD cost的增加,作为了svm训练中的权重。【130】进一步将四叉树CU划分建模为三级按等级划分的二分问题,以及分别在决策层学习了SVM优化仿真。同时,优化的线下学习参数被推导出来实现RD表现和减少复杂度之间的平衡。【138】基于模糊支持向量机增强了CU决策,它在学习过程中考虑了样本和特征选择。
除此之外,贝叶斯决策规则,决策数,基于Neyman Pearson的规则,马尔可夫随机域,和马尔可夫链蒙特卡罗模型来解决,帧间cu尺寸决策问题。除此之外,多种增强和集成学习算法,也被用来提高预测准确率。例如使用多个支持向量机和随机森林来review系统。表2显示了特征,分类器,以及基于模式决策的有代表性的学习方案的编码表现,它们在不同的配置下,包括了全部帧内,LDP,LDB,RA。
在帧间编码中,除了CU的大小决策外,还有PU、TU的大小决策和参考帧的选择问题。由于CU的大小是模式决策的外侧循环,所以PU的大小是在给定CU的条件下确定的。在[139]中,PU的大小决策被表述为一个多类问题,并由一个多类SVM来解决。由于跳跃模式在各CU中被选择为最优模式的概率较大,因此采用二叉支持向量机算法对跳跃/合并模式进行预测,来提前终止PU模式决策。在[89]中,利用残差系数方差与TU大小的相关性来减少给定CU/PU块的TU候选模式,然后利用贝叶斯定理检测来预测TU大小。其中,CU、PU、TU和参考帧的选择处于不同的模式决策水平,可以联合进行编码间的优化。然而,联合分类问题是递归的、层次化的,所以要实现最优会更加复杂。
特征是学习算法预测精度的关键。表2中还列出了一些具有代表性的模式决策特征,基本可以分为5类:1)当前块的前期编码信息/预分析;2)空间相关信息;3)时间相关信息;4)全局纹理和运动信息。具有良好代表性的特征将显著提高识别能力和预测精度在基于学习的模式决策中,坏的或不相关的特征可能对预测产生负面影响。此外,增加特征的数量会增加输入数据的维数,从而增加特征提取的复杂度和在线学习的复杂度。因此,需要使用特征选择算法来选择更多的表示特征。[88]提出了一种基于滤波的特征选择方案,用F-score作为特征相关测量,从10个特征中选出5个最重要的特征。在[133]中,穷举搜索从23个特征中选出13个特征。虽然离线情况下不考虑特性选择开销,但是如果我们有大量的特性集,这将非常耗时。基本上,相关著作|111、8130,138、42、72、15、26,110、25,139,101、89,133]中的这些特征都是手工制作的特征,很难找到可靠的判别特征来进行模式判定。由于视频编码中存在多个模式决策层,包括CU大小、PU、TU、参考帧选择等,不同的决策问题和帧类型通常需要不同的特征。另外,由于视频内容的多样性,如自然场景、快速运动、监控、屏幕内容等,需要专门设计特征来适应视频。因此,为了更好地权衡模式决策问题的准确性和开销,可能需要进一步进行在线特征选择。
样本选择也是基于学习的模式决策解决训练数据不平衡问题的一个重要问题,这在文献[88,130,138,132]中已经得到了考虑。由于基准视频编码器可以使用穷举全RDO确定最优模式,因此可以标记足够的训练数据。但由于帧与视频内容相似,可能会产生相似的样本,造成样本冗余。此外,训练样本在类别之间和类别内部是不均匀分布的。例如,在决定CU尺寸时,例如64×64的CU数量比8×8或16×16CU的数量要少得多。此外,样本的子类在一个类中分布也不均匀。为了解决这个问题,通常使用sub- and - up抽样[132]方法来实现平衡数据。此外,[88,130,138]还考虑了误分类的成本类型和程度,如RD成本和复杂性,采用了代价敏感学习方法。
内部编码的复杂度低于内部编码;然而,特征提取和学习的复杂性开销更为关键。Duanmu等人采用决策树分类器来分类block块(即,自然图像或屏幕内容),CU分区和定向块。开发了六维特征。然后,在当前模式编码速率低于统计阈值时,提前终止序列模式检查过程。Zhang等[132]提出了基于支持向量机的两阶段内尺寸决策分类方法,利用第一个离线支持向量机分类器来预测分形、非分形和不确定度,然后利用第二阶段在线支持向量机分类器从第一个分类器中提取不确定度预测。每个CU决策层使用不同的特性集来最小化复杂性开销。Liu等[66]进一步利用双svm模型进行CU深度决策,同时采用图像纹理复杂度、方向复杂度、子CU复杂度和量化参数(QPs)等四维特征。
在HEVC内部编码中,除了CU大小决策外,还有35种角度预测模式,是一个多类决策问题。在HEVC中,不是检查所有的35模式,而是采用粗糙模式判定(RMD)来选择一个小的模式(3到8 + MPM模式)来完成全部RDO。H. Zhang等人[123]提出了一种渐进粗糙模式搜索(progressive rough mode search, pRMS)来选择性地检查潜在模式,而不是遍历RMD中的所有35个候选模式。T. Zhang等[125]利用水平方向(AGH)和垂直方向(AGV)的平均梯度来确定块体方向的大致范围。这些是统计方法。此外,随机森林在[83]中被用来估计一个内部预测模式,其中只有4个像素反映了一个块的方向性,作为关键特征来减少复杂性开销。HEVC和VVC的复杂度分别降低了18.3%和17.2%。很少有研究使用机器学习工具来处理内部预测模式。主要原因是:1)每个INTRA预测模式的复杂度降低,机器学习复杂度开销不再是可以忽略不计的;
这些基于学习的模式决策方案的主要工作流程如图7所示。首先,将视频编码中的模式决策模型化为分类问题,如二分类、多级二分类和多类分类问题。其次,开发一些手工特征和可训练的分类器来解决分类问题。这些工作的优点是:1)联合利用多个特征;2)由于分类器能够将输入的特征向量非线性地映射到高维特征空间中,从而提高了预测精度和识别率。为每个类构造最优的分离超平面。然而,这些算法的缺点是1)模型是手工制作的。为每一个决策问题找到有效的特征是困难的,这是耗时的,需要专业的领域理解。特征的选择和提取是影响分类性能的关键问题。2)利用在线学习模式提取特征并学习最优超平面存在复杂度开销,它在特征维数和训练样本数量较大的情况下尤为关键。3)通常需要一个最优的参数确定来实现复杂度降低和RD退化之间的良好权衡。
4.3.3 基于端到端深度学习的策略
近年来,深度神经网络(NN)[51]显著提高了预测性能,在视觉信号处理和模式识别中得到了广泛的应用。由于传统的基于机器学习的模式很难找到有效的特征,许多研究者致力于探索基于端到端的深度学习ng的模式决策方案[69,70,50,55,114,112,34,35]。Liu等[69]应用卷积神经网络(Convolutional Neural Network, CNN)对源图像块的纹理进行分析,从而减少帧内编码中CU模式的最大数目。在设计CNN架构时,考虑量化对编码成本的影响,引入QP。此外,在[70]中,针对INTRA CU大小的决策,开发了一个硬件CNN加速器,其中网络只配置了两个卷积层、一个池隐含层和两个全连接层。原始像素的输入块64×64、32×32、16×16和8×8不是训练不同的CNN,而是通过局部平均和子采样将其归一化为8×8矩阵,从而共享一个CNN网络。Laude等人[50]探索用CNN分类器代替RDO过程对每个CU进行INTRA预测,结果仅报告了0.52%的BDBR损失。然而,复杂性分析并没有被报道。Xu等人提出了一种提前终止的分级CNN来预测CU内分区[55],并提出了一种分级的长短时记忆(long - and - short Memory, LSTM)网络来预测CU间模式[114],其中进一步探讨了时间依赖性。该网络共享了用于特征提取的卷积层,以降低复杂度,并针对不同的CU决策采用不同的全连接(FC)层。所提出的CNN和LSTM有数百万个参数,并且还需要上百万次的加法和乘法,它们非常复杂,但不包括在总体复杂度中。Kim等人采用基于多层感知器(MLP)的神经网络对HEVC内部和内部的CU深度决策进行分裂或非分裂预测。在[112]中,Xu等人提出了一种基于CU深度决策的分级LSTM网络来预测H.264到HEVC转码的CTU分区,其中包括MV、块分区等四维手工制作的特征映射。比特和残数被输入到网络中。最新的JVET在正在进行的VVC中采用了QTBT块划分结构,以5倍或更高的计算复杂度提高了编码效率。为了降低VVC的内部编码复杂度,Jin等[34,35]将QTBT划分深度范围建模为5类分类问题,利用CNN预测QTBT中的CU深度范围。复杂度降低了43.69%,BDBR增加了0.77%,同时CNN预测的复杂度开销为编码器的4.51%。在这些作品中,高维特征从原始像素块(例如,32 x 32或64 x 64),显示为底五行表2中,只使用一块内的信息,传统的有用的特性,比如时空相关性和RD成本,尚未考虑。CNN采用了少量的卷积层,例如2到5层,以降低复杂度开销。它们被提出用于内部编码,而对内部编码的研究还很少。
在基于深度学习的端到端的模式决策方案中,可以将原始像素/块或底层特征(如motion和variance)作为输入,然后通过监督学习或反向学习来学习中高层特征。最后,使用更强大的分类器(如全连接MLP)输出结果。这些作品[69,70,50,55,114,112,34,35]的优点是1)成千上万的特征可以从数据【114】中学习到,不需要设计专业的手工制作的特征。2)增加卷积层数可以提高预测精度,即,更深。它还能解决复杂的多类分类问题。3)其他该模型具有丰富的标记模式数据和鲁棒学习模型。然而,其缺点包括1)端到端深度学习非常复杂,有时其复杂性甚至比深度网络的编码器还要高。因此,需要在编码增益(复杂度降低或其他性能)和复杂度开销之间进行良好的权衡。2)压缩不同质量的视频需要多个学习网络,比如不同的QP。3)在端到端学习中,如果训练数据不充分或选择不当,可能会出现过拟合问题。4)深度神经网络的最优超参数需要通过经验确定,这一点很难解释。5)学习网络中只使用当前CU中的像素,而不考虑传统的有用的特征信息,如时空相关性。到目前为止,需要外接加速器[70],增加了硬件成本。基于深度学习的方案的编码性能仅能与统计方法或传统的基于机器学习的方案相媲美,这就需要进一步的研究。
强化学习(RL)[3]是机器学习的另一个热点分支,在工业界和学术界也备受关注。与传统的监督学习和非监督学习不同,它关注的是在一个环境中通过最大化累积奖励来采取行动。在[54]中,Li等人提出了一种基于端到端actor-批评家RL的HEVC CU提前终止方案。图8给出了基于RL的CU决策框架,其中CrtNN和ActNN分别表示批评家神经网络和演员神经网络。将CU决策过程建模为Markov决策过程(MDP),将CU编码作为环境,CU深度预测器作为agent,分割和非分割作为动作,RD损失作为奖励。基于端到端的角色-批评家RL算法,从CU决策轨迹离线学习CU决策分类器。最后,将学习到的ActNN加入到视频编码器中,对CU分区进行预测。事实上,HEVC四叉树CU结构很难被建模为MDP。此外,还使用了5个手工特性和单层NNs来减少复杂性开销,这可能会限制编码性能。将RL应用于HEVC模式决策是一项开创性的工作。虽然RL的复杂度降低程度仅与传统的基于机器学习的算法(34.34% ~ 43.33%)相当,但RL在处理更复杂的决策和控制问题方面具有强大的潜力。它还具有提高网络训练的性能和灵活性的优点,值得进一步研究。
4.4 讨论
现有的基于学习的快速模式决策方法主要是对CU/PU模式决策进行优化,因为CU/PU决策是外环,复杂度最大。此外,其他内环模式决策依赖于CU/PU决策的结果。为了发挥机器学习算法的优势,提高编码效率,有必要弥补编码算法与机器学习算法之间的差距[130]。制定CU/PU决策流程是很容易的,以适应学习算法,可以很好解决的二分类问题,如SVM、决策树、Bayes决策规则等。相反,对于一些候选模式较多的模块,如INTRA angular prediction |123]和ME,其建模和求解的难度较大。此外,对于每个模式而言,它们的复杂度是低的,在快速模式决策中而言,减少了潜在的复杂度。
随着视频编码技术的发展,为了实现更高的压缩效率,引入了更多的细化模式。例如,模内模数增加到67个;启用更灵活的分区结构,例如QTBTTT;VVC中可用的CU尺寸增加到256x256[95]。在这种情况下,编码复杂度会增加,而低复杂度优化变得更加关键。同时,VVC中的各种模式决策问题也越来越复杂。因此,数据驱动的模式决策和先进的学习工具,如前馈CNN、deep RL[3]和deep NN,是这些复杂模式决策问题可能的良好解决方案,值得进一步研究。此外,可以对多个不同的循环或决策层进行联合优化,使编码复杂度最小化。
5. 基于学习的高效编码优化
目前的视频编码标准遵循基于块的混合框架,该框架包括预测编码、变换编码和熵编码三大部分,如图9所示。预测编码利用了视频信号的视时空相关性,这是视频冗余的主要部分。变换编码在频域内对能量进行压缩,然后在有损编码中利用更大的尺度对高频等高频不敏感频率进行量化。最后,利用熵编码来减少信号的统计熵冗余。此外,还采用了增强算法,包括预处理/后处理和内循环滤波,以提高重建视频的质量。在本节中,我们针对以上四部分提出了基于学习的高效编码优化方法。表3总结了基于学习的高效编码的问题求解和编码性能,其优化模块如图9所示。
5.1 基于学习的预测编码
由于二维视频具有较高的空间保真度和捕获帧率,其内容在时空上具有很强的相关性。预测编码,例如帧内和帧间预测,是用来消除空间和时间冗余的。只有少量的模式向量和原始数据与预测数据之间的差异被编码和传输。因此,预测编码的基本问题可以表述为找到一个映射函数f)来最小化原始块(Xo)和预测块(Xp)之间的差异,其表示形式为
\(\|\cdot\|_{p, q}\)表示\(L_{p, q}\)归一化操作。它表示q和p为2和1时的欧几里德范数,或q和p为2时的弗洛贝尼乌斯范数;r是表示映射函数f()的最优参数或边信息的编码比特,\(r_{\mathrm{T}}\)是目标比特。\(\hat{\mathbf{X}}_{t}\)和\(\hat{\mathbf{X}}_{t-k}\)是Xo在时间t和t-k时重构的时空块。注意,在公式4中还没有考虑到变换和量化。寻找最优映射函数f(),通过最小化相邻块之间的差异来预测块Xo。图10展示了基于预测的视频编码学习的三个典型的关键案例,包括插值、帧内和帧间预测。图10(a)为空间插值和上采样预测情况,利用所学习的模型从源像素(黄色)预测邻近或子像素(蓝色、红色和绿色圆点)。最后,由源像素和预测像素组成插值图像。图10(b)为空间内预测,利用所学习的模型对周围空间相邻像素(黄色像素)的白色块进行预测。图10(c)为时间相邻块的内预测,即时域插值。
稀疏字典学习(DL)能够以线性组合或多个基本元素的形式找到输入数据的稀疏表示,这些基本元素在字典中也表示为原子。它被广泛应用于图像处理的超分辨率/插值[100]、去噪和重建[98]。该混合编码框架的内部和内部预测编码可以表示为一个上采样问题,其中块在低比特率的预测编码中向下采样,然后在解码器上向上采样到其原始分辨率,以实现高视觉质量的重建。通过训练过完备字典来解决上采样问题,提高了对低质量视觉数据的重建质量。在[109]中,Xiong等人提出了一种用于重建帧的稀疏时空表示。然后利用在线学习[17]来提高字典学习的收敛速度。此外,多尺度[99]和渐进式词典学习[18]被广泛用于学习时空词典,利用底层和增强层之间的层间相关性进行质量、时空可伸缩的视频编码。在此外,利用最新的CNN[21,44,57,40]也利用了上采样问题。Dong等人在[21]中提出了ar图像超分辨率CNN (ar image Super-Resolution CNN, SRCNN),该方法利用一种轻量级的结构化CNN来学习低分辨率和高分辨率图像之间的端到端映射。Kim等人在[44]中受到VGG-net的启发,将网络深度增加到20层,提出了一个非常深的卷积网络,用于图像的超分辨率,记作VDSR。Li等人在[57]中提出了基于cnn的帧内编码块上采样方案,包括帧内编码循环中的块上采样和帧上采样来细化块边界。基于down/up-sampling编码框架,CNN被训练在空间和时间维度的压缩视频提高空间分辨率[40]。图11和12显示的视觉质量和PSNR值的插值比较结果,它们来自传统bi-cubic,稀疏编码、SRCNN VDSR方法。


我们可以看到,基于学习的方案可以显著提高不同内容的超分辨率图像的质量,大约在2.27 dB到7.06 dB之间。基于CNN的方案[21,44]能够取得更好的效果。由于亚像素ME和运动补偿(MC)需要亚像素插值,因此采用CNN对分数像素MC[116,117,65],从整数像素预测分数像素。在[117]中,提出了一种分数像素参考生成CNN (FRCNN)来生成HEVC中分数像素ME的参考图像,在HEVC中训练多个指定的FRCNNs来插值不同位置的分数像素。平均达到1.3%到3.9% BDBR增益,编码器的复杂性增加到原来的80.77倍,解码器增加到原来的6.94倍。[65]提出了一个基于更深并分组分段插值方法变异CNN (GVCNN)的one-for-all分数插值网络,通过处理不同的QP和亚像素位置来提高插值通用性。对于RA、LDB和LDP配置,它实现了0.9%、1.2%和2.2%的平均BDBR增益。然而,编码器和解码器的复杂性增加到是原来HEVC的5.29和1548.58倍,这看起来是不可负担的。
除了up-sampling问题,预测编码也可以被认为对空间和时间的预测像素值或模式,如图10所示(b)和(c)。[52]提出了一种有效的基于多线预测方法的,除了最近的相邻的行和列更多的参考线正被使用。采用全连通网络学习从相邻重建像素到当前块[53]的端到端映射,将当前块的更多上下文信息输入到全连通网络。一个限制是网络必须针对每个块大小进行训练。在[138]中,在帧内预测中,从相邻的CU预测像素被建模为一个内画问题,并使用生成式对抗网络(GAN)模型来完成,其架构如图13所示。
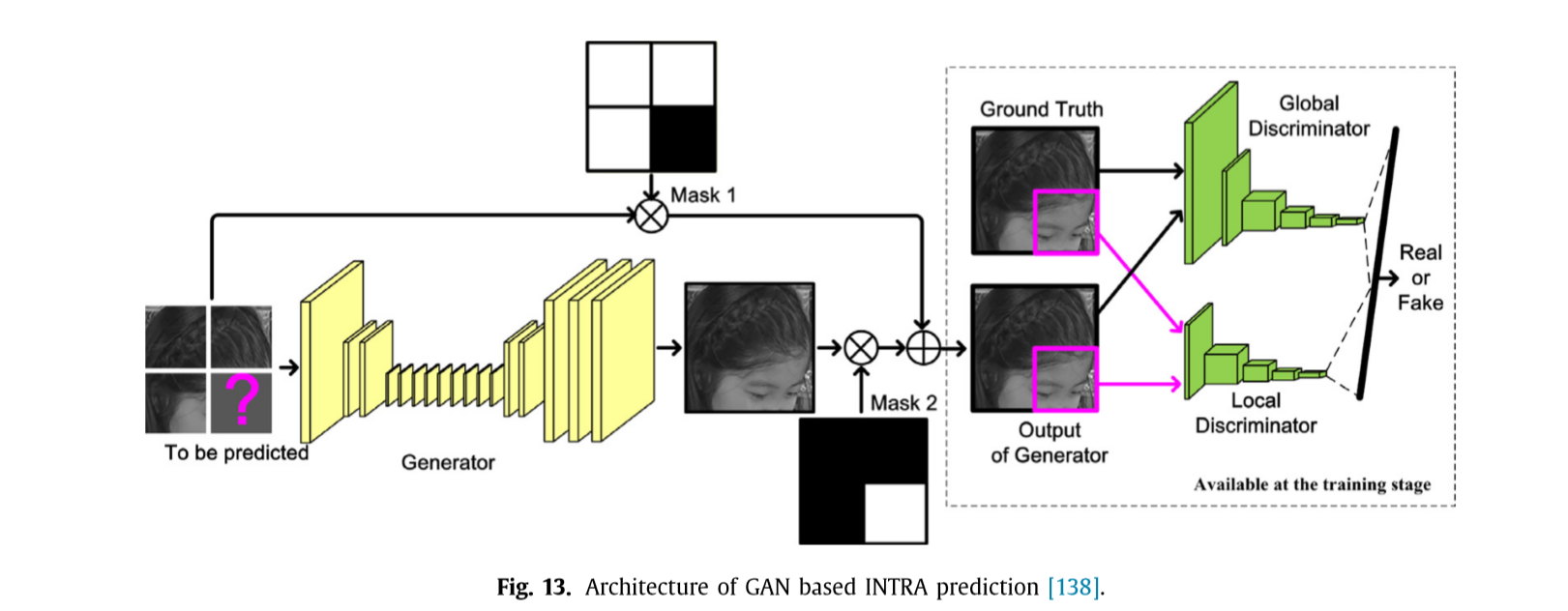
右下方mask里面的CTU将分别由左方,上方和左上方重建的CTUs进行预测。使用全局和局部鉴别器来改进帧内预测生成器的学习。为每个CTU生成了额外的35个内部模式候选项,并将它们合并到编码器和解码器中,以便在RDO过程中进行RD比较。图14显示了在HEVC中基于GAN和传统角度预测的64 x 64 CU的INTRA预测示例,其中测量了SAD。基于GAN的方案在SAD和视觉质量方面有较好的预测结果。HEVC和VVC的平均BDBR增益分别为6.6%和6.75%,非常有前景。然而,编码和解码的复杂度显著增加,HEVC平均提高7.0倍,VVC平均提高160倍,VVC平均提高2.5倍,VVC平均提高257倍。Chen等人在预测编码的时空相干性建模中提出了体素cnn的概念,并将其纳入到ME和混合预测网络中。此外,研究了双向RNN在视频压缩[47]中利用时间信息进行预测。利用更多的像素信息和先进的预测技术,提高了帧内编码的效率。Zhao等[137]使用CNN来推断INTER - bi预测的预测块,而在[136]中对参考图像进行了改进以提高INTER预测的准确性。基于学习的时间帧高效预测编码尚处于起步阶段,需要进一步研究。
5.2 基于学习的变换编码
(下面这一段是基础知识,我懂的)

Karhunen-Loeve变换(KLT)是一种将像素数据投影到特征向量上的理想线性变换。它通过最小化数据与它们张成的子空间之间的距离来逐个挑选基向量。KLT依赖于数据,需要源数据来估计转换核心。然后,需要将核心传输到解码器,这增加了rc位的开销。离散余弦变换(DCT)是一种仅使用实数进行傅里叶变换的方法,它接近于马尔可夫过程的KLT性能。由于管道实现的快速分解和强大的能量压缩特性,它在JPEG和第一代编码标准中得到了广泛的应用。此外,变换基是固定的。在DCT的基础上,在H.264/AVC中提出了4x4整数余弦变换(ICT)将DCT浮点运算改为整数[108]。为了提高能量压缩转换大块,Hardmard变换与4x4 ICT联合工作16 x 16块。在HEVC中,基于DCT提出了不同的TU尺寸(4 x4、8 x8、16 x16、32 x32)和变换核。传统的DCT变换假设信号为平稳的高斯分布,从而得到最优的变换,但对于残差预测来说,这种最优变换并不总是最优的。为了进一步提高性能,提出了基于内容的变换,如方向自适应变换[76]和模式相关方向变换(Mode Dependent Directional transform, MDDT)[2],用于变换不同类型的数据源,如不同的内部预测模式。通过在编码环中测试一组变换核,在VVC中引入自适应多重变换(AMT)[6],通过RD成本比较,选择最优基。然后,将变换基的一个指标显式地传递给译码器,并通过基于学习的预测来改进【77】.
在[85]中,通过引入低范数正则化优化对MDDT算法进行了改进,以获得鲁棒的收益算法,并在优化过程中实施稀疏约束。类似地,在78]中,将剩余块划分为若干类并分别进行转换。在此基础上,提出了一种基于退火的学习方法来提高算法的性能。这些算法与AMT相似,主要的区别是使用了学习算法来预测最佳的变换基C,减少了开销索引位rc。许多可选择的尝试[37,38,81,64]探索以更少或更有效的方式转换残留物。在[37]中,提出了一种基于字典学习的新变换方法,该方法将残数转化为转换系数的个数来构造字典字典。在[38]中,针对HEVC中的编码预测残差,提出了一种级联稀疏/DCT两层表示方法,该方法通过训练字典来表示低比特率下的结构化残差信号模式,并通过级联DCT表示方法来减少高比特率下的开销比特。在[81]中,支持向量机被用来近似DCT系数,其中数据是在给定的精度水平内建模的,基于支持向量机在训练中选择有限数量的样本作为支持向量的特性。应用于图像编码,其性能优于JPEG。在[64]中,我们使用CNN来模拟类dct变换,其中基于CNN的变换将块像素非线性映射为稀疏系数,而基于CNN的逆变换将系数映射为块像素。3个convolutional layer和1个FC layer被用来训练CNN。在网络训练的损失函数中考虑了失真和比特率。与JPEG相比,在低比特率下有了相当大的改进。然而,现有的CNN网络是使用原始块像素、固定块大小和图像编码进行处理的,进一步的整合和研究将是有趣的。
Kuo等人提出了一种带增广核变换的前馈数据驱动的子空间近似,简称为Saak变换[48],其中的核来自于输入的二阶统计量。此外,在零化激活的非线性中加入一个调整偏置,即Saab变换[49]。Saak和Saab变换是主成分分析(PCA)降维的变体。不需要数据标签和反向传播。Saak和Saab变换已成功地用于图像分类和伪造,并取得了良好的效果。它们在视频编码中的应用将是一项有趣而有价值的研究。变换编码是继预测编码之后的一种降维问题。数据相关转换是一个很有前途的趋势。到目前为止,基于学习的变换编码的性能优于JPEG和INTRA编码。然而,它们对编码间的有效性还需要更多的研究。因此,如何提高基于学习的变换编码的有效性,并将其与量化和预测编码相结合,将是未来的研究热点。同时,需要考虑基于学习的转换的通用性和特殊性。
5.3 基于学习的增强算法

\(\|\mathbf{y}-\mathbf{H x}\|_{q, p}\)是\(L_{q, p}\)归一化,\(\Omega(\mathbf{x})\)是约束条件,限制了最优解的范围,入是平衡参数。如果H是单位矩阵,则y只包含加性噪声,(10)成为图像去噪问题;如果H是模糊算子,(10)表示去模糊问题;若H为下采样算子或模糊与下采样相结合的复合算子,则(10)为图像超分辨率问题;如果H是采样矩阵或掩模,则(10)表示图像内画问题。恢复的x越好,将增强应用于视频编码时,编码性能越好。根据图像优化问题的类型和应用于视频编码的模块,将增强算法分为两类:内循环过滤和预处理/后处理。
第一类是针对编解码器的内环路滤波模块,在编码或解码过程中,滤波后的块作为后续块的参考。在[12]中,提出了一种基于自学习的图像去块框架,将去块描述为一种基于形态成分分析(MCA)的图像分解任务。该方案利用块匹配和三维滤波算法对低频和高频部分进行分解。Park等人[74]提出了一种利用CNN (IFCNN)进行内环路滤波的方法来提高重建图像的质量,由于在编码器和解码器中使用了相同的训练权值,因此不需要信令比特。为了进一步提高编码效率,提出了一种用于内环滤波的剩余高速公路CNN[133],其中RHCNN由多个剩余高速公路单元和卷积层组成。在HEVC中,除了去块和样本自适应偏移(SAO)滤波器外,还使用了RHCNN作为高维滤波器来提高重构帧的质量,平均降低了3.38%的比特率,但代价是编码复杂度的3倍左右。Jia等人设计了一个多维CNN模型进行环路滤波,并针对不同区域进行了内容感知的多模型CNN。它实现了4.2%到6.0%的内部和内部配置BDBR增益,而编码和解码复杂性增加到2.14倍和156.10倍。此外,Li等人[56]提出了一种基于DenseNet的HEVC多帧内环路滤波(Multi-frame In-loop Filter, MIF)方案,该方案联合使用多个连续的时间帧来增强滤波性能。另外,常规的SAO、In -loop filter和MIF之间有模式选择,如图15所示。这些方案在编码过程的循环中提高了重构块的质量,不仅提高了重构图像的质量,而且在后续的INTRA或INTER预测中以增强后的图像/块作为参考时,提高了编码效率。这些循环内增强可能在块之间具有顺序数据依赖性,这对并行性有负面影响。此外,在RDO中多次调用循环内增强,大大增加了编码和解码的复杂度。
另一类是图像增强的预处理/后处理算法。在[19]中,提出了一种基于CNN的HEVC后处理算法,该算法采用可变滤波大小的残差学习CNN (VRCNN)来提高编码性能,加速网络训练。与传统的编码器优化方案不同,Wang等[105]侧重于提高解码器端的视频质量,采用了非常深入的CNN来消除失真,提高了hevc压缩视频的质量。在接收端,利用数据库中的人脸补丁恢复低质量的人脸区域。深CNN被用来模拟视频编码的翻领功能[61],它建立了一个端到端从解码帧映射到一个增强Zhang et al。[134]提出了一种自适应残余网络(攻击)高质量的视频编码,图像复原,捷径是用来减少模型的复杂性。在[140]中,我们使用CNN模型来提高大小图像的同步质量,并将其应用于3D-HEVC编码器的内循环视图合成优化(In -loop View Synthesis Optimization, VSO)和解码器的out-loo重构。在[122]中,提出了一种新的质量增强方法,该方法使用多重构或递归残差网络(MRRN),其中设计了一个递归残差结构来捕获压缩伪影的多尺度相似性。与环路内滤波器相比,预处理/后处理模块将在编码环路外的重构阶段进行。它们可用于编码器和解码器,或仅用于解码器端。此外,由于脱离了编码循环,数据依赖性较弱,这有利于视频编码的块并行性。然而,编码增益比内循环方案要低。另外,由于量化所造成的失真程度不同,需要针对不同的QPs 133、56、19,122进行多个学习模型的训练,可以进一步改进。看看
高效编码的关键是预测样本值、模式或去相关系数。决策学习和深度学习是提高预测和编码效率的两种有效工具。然而,即使使用相同的训练数据和参数设置,基于深度学习的优化实际上也很难在理论上解释和再现。另外,基于学习的相关工作主要集中在预测、增强和转换编码的优化上。熵编码很少被提及。最近只有一项研究关注于熵编码[93],该研究使用神经网络来预测多级算术引擎语法内部模式的概率分布。在不同的设置下,节省了0.33%和1.13%的比特率。其主要原因是熵编码问题难以建模,难以充分利用学习算法的优势。
基于学习的方案,尤其是使用深度学习的方案,能够获得有希望的编码收益,但会造成更大的复杂性开销和硬件成本,虽然启用了GPU加速,但编码器和解码器分别增加了数倍和数百或数千倍[65,138]。这些基于学习的方案的低复杂度或低成本的适应性是标准化和实际应用的迫切需要。由于视频不仅用于观看,还可以用于人脸识别、机器人视觉、检索等识别任务,除了保持较高的视觉质量外,还需要保留与识别任务相关的关键特征[20]。在这种情况下,考虑多目标和特性的编码优化值得进一步研究。
许多研究人员也在寻求提出新的基于学习的编码框架的可能性,该框架不同于基于混合块的编码,可以适应不同的环境,如移动或云计算环境的分布式编码[94]。除了将CNN应用于现有的编码模块外,还利用了新的端到端压缩框架[33]。这些编码算法的编码效率优于INTRA编码,并且有很大的潜力获得更高的增益。
6. 基于学习的视频质量评估

感知视频编码器是一种可能的尝试性解决方案,开发一种与HVS一致的感知质量度量Q成为关键。到目前为止,已经发展了许多视觉质量评价(Visual Quality Assessment, VQA)指标,如SSIM[106]、FSIM[124]、Multi-Scale SSIM (MS-SSIM)[107]、MOVIE[84]等。然而,与PSNR相比,还没有一个普遍接受的感知质量指标。HVS是一个复杂的非线性系统。虽然许多重要的知觉因素在心理学和生理学的角度上都有所揭示,但对HVS和人脑的认识还很有限,还在探索中。建立一个与人类感知一致的有效的视觉质量指标是一个挑战。机器学习通过从数据中挖掘视觉因素并实现数据驱动的解决方案提供了新的机会。在本节中,VQAs主要分为主观和客观两大类,并进行了详细的分析。
6.1 主观视觉视频评估和有标签的数据
在主观的VQA中,一组受试者被邀请对给定程序和测试环境下的一系列失真图像或视频的质量进行评分。然后,将处理后的受试者平均意见得分(MOS)或差异MOS (DMOS)作为地面真实质量,反映HVS的视觉反应。为了使主观的VQA更加僵化和理性,ITU-T和ITU-R于1997年成立了视频质量专家组(VQEG),专注于主客观的视觉质量研究。发布了一系列建议,以确定主观测试方法、程序和环境,如ITU-R BT.500[29]和BT.710[30]电视和高清电视图像,BT.1788为见BT.1438[28]用于立体图像,BT.2021用于3D视频系统[80]。
主观质量评价实验主要有两方面的贡献。首先,它们在HVS机制下更易于理解,并显示出新的视觉特性。例如,对比敏感功能(CSF),视觉注意力和ROI,视觉灵敏度,JND,深度感知,视觉掩蔽效应,双目融合和竞争等,在过去的几十年里已经进行了研究。它们是面向目标质量度量的特性和模型设计的基础。另一个贡献是标记失真图像/视频的质量分数,这将是设计和验证客观质量指标的数据来源和地面真实标签。
一般情况下,一个数据集包含多个具有不同内容和时空特征的源图像/视频,记为n,然后用不同类型的畸变量(如压缩、模糊或白噪声)和度对其进行畸变,分别记为P和Q。失真图像/视频的总数为Nx Px q其中的内容将由若干受试者观看并评分,例如,35,剔除异常值后的统计平均质量将是一个失真图像/视频的质量标签。图16为2000年以来典型VQA数据集中的畸变图像/视频数量,其中包括自然图像、屏幕内容图像(SCI)、立体图像和视频数据集。我们可以观察到,TID2013最大的数据集大约有3000个标记图像,而大多数图像数据集小于1000个。此外,视频数据集更少,其标签数据只有100到150,这是一个非常小的数字。尽管近年来越来越多的数据集被标记和发布,但由于不同的属性(SD/HD、2D/3D、图像/视频、SCI/自然内容)、失真、尺度类型(质量/深度、MOS/DMOS、标准化)和设置(显示、测试环境、查看条件、过程),它们很难被联合使用。此外,图像或视频苔藓通常从平均值的离散五程度规模质量5比1,对应“优秀”、“良好”、“公平”、“穷人”和“坏”,这可能不够准确测量编码失真水平,例如,51 HEVC和100年的JPEG压缩。细粒度的主观质量评估[126]和数据集[104,62]是这是一个有趣的、正在兴起的研究主题,但是,它比粗粒度的研究要费力得多。
事实上,对大量的图像或视频进行主观的VQA标注是费力、昂贵、耗时的[92]。然而,主观质量并不能应用于其他未知视频和内环路视觉信号处理。因此,需要客观的质量度量。在设计客观质量度量时,对视觉感知机制的理解是开发有效特征的关键。此外,数据集将是培训、验证和测试基于学习的VQA的重要数据源。创建大而细粒度的数据集[126,92]是一项挑战,但对于开发可靠且有能力的VQA模型来说是至关重要的。
6.2 基于机器学习的主观视觉质量评估
另一类是客观质量评估,评估失真视频的质量分数。根据引用的可用性,VQA指标可以分为完全引用(FR)、减少引用(RR)和无引用(NR)。FR需要一个“完美的”质量的图像/视频,我。e,参考完全可用,RR需要部分侧信息,NR没有参考信息。MSE和PSNR是FR VQA指标,由于其简单性,在视频编码中得到了广泛的应用。他们是直接的,但不够准确,以表示在HVS的感知质量。随着人们对人机交互越来越多的了解,许多有特色的VQAs被开发出来以代表网络时代的失真。
根据特征和融合算法,VQA指标可以分为四类:基于手工特征的、基于手工特征+学习的、基于特征学习的和基于端到端学习的方法,如图17所示。表4总结了这四种类型中典型VQA指标的特性和学习算法。在第一类中,PSNR和MSE仅采用失真图像和参考图像的平方像素差作为唯一特征。SSIM[106]引入亮度、对比度和结构比较,并结合这三个指标来评估图像质量。此外,还进一步考虑了视觉信息保真度(Visual Information Fidelity, VIF)[87]和梯度相似度(gradient similarity)[63]。这些是图像质量度量。提出了一种视频质量度量(Video Quality Metric, VOM)[75],它采用了空间信息丢失、边缘向对角方向移动、色度扩散、增强的空间增益、时间损伤和局部色彩损伤等7个关键特征。然后将它们与加权总和结合起来,确定权重。Seshadrinathan等人提出了基于运动的视频完整性评价指标(MOVIE)[84],用于视频质量评估,其中使用Gabor系数估计空间质量,然后使用运动信息进行调整。考虑图像/视频区域的不同重要性,采用感知加权的MSE[27]进行池化。这类VQA指标的工作流程是提取手工制作的特征,并根据经验进行融合,用于质量预测,如图17(a)所示。它们通常简单直接,但是很难适应各种图像/视频内容。随着更多的脑灵感特征被揭示,加入更多的特征可以提高预测的准确性和适应性。然而,融合高维特征变得越来越具有挑战性。
在第二类中,引入了机器学习算法来解决融合多个特征的问题。Lin等人开发了一种用于立体图像的FR质量度量。通过双目对抗模型,提取左视和右视的Gabor特征。最后,利用支持向量回归(SVR)学习特征与质量分数之间的映射函数。Xue等[115]利用高斯(Gaussian)的梯度幅度(GM)和拉普拉斯(Laplacian),并利用SVR学习回归模型。Moorthy等人[71]提出了NR图像质量评估的两步框架,命名为DIIVINE。首先利用基于小波系数和广义高斯分布(GGD)的支持向量机对图像的失真类型进行分类,然后利用SVR对图像的质量分数进行预测。文献102提出了一种基于学习的实时流媒体RR视频质量评估方法,该方法在服务器端学习无监督受限玻尔兹曼机(RBMs),在客户端使用传输RBM模型进行NR测量。Yang等[119]将深度信念网络(Deep Belief Network, DBN)应用于融合二维手工特征和三维深度感知图的立体图像盲度量评估。Li等人[58]提出了视频多方法ssessment Fusion (VMAF)算法,该算法将抗噪信噪比(AN-SNR)、细节损失测度(DLM)、VIF和均值共定位像素差(MCPD)四种方法与SVM分类器融合来预测质量分数。它声称比其他广泛使用的客观指标更好地反映了人类对视频质量的感知,并已在行业中得到应用,如Netflix的视频流媒体。这些工程的工作流程如图17(b)所示。首先,提取手工特征并使用可训练学习算法将特征映射到最终的质量分数。这些指标的性能高度依赖于提取的手工特性的有效性。由于用于模型链接的标记数据有限,很容易发生过拟合,需要进一步提高跨数据库验证的有效性。现有的视频数据集更是少之又少,基于视频的VQA学习的文献更是少之又少。
第三类是基于特征学习的方法,即从数据中学习特征。他们尝试解决有效特征提取的困难,如图17(c)所示。Shao等人[86]通过使用一组基向量i来学习字典来表示图像的潜在结构。e、学习有代表性的特征。然后融合稀疏系数向量生成的质量指标。Ye等[120]提出了一种用于NR图像质量评估的无监督学习框架CORNIA,该框架从未标记的图像块中学习一个可视码本,然后使用监督线性SVM预测其质量。Zhang等[135]利用多个时间层重构视频,并学习时间字典来表示合成三维视频中闪烁的伪影。除了手工制作的功能外,他们还可以学习更多的区别性功能。同时,学习图像/视频的特征,不需要质量标签。然而,更高层次的特征,如稀疏系数向量[86]、相位和幅值相似性[135],也需要人工设计。这个过程可以看作是一个特征转换。
随着深度学习在图像识别领域的突破,研究者尝试将深度学习应用于VQA研究中[39,7,24,127,4,118,41,43,45]。,第四类如图17(d)所示。Kang等人[39]使用CNN进行NR图像质量的通用评估,将特征学习与质量回归相结合,形成整体、端到端-eno的方式。Bosse等人[7]在图像质量评估中采用了Siamese网络,该网络针对FR进行了训练,但通过提取部分网络可以用于NR。Fan等人提出了一种基于或多专家CNN的通用NR图像质量评估方法。它通过CNN对失真类型进行分类,并针对每种失真类型训练特定的专家-CNN。然后将每个expert-CNN的输出汇总为最终的图像质量分数。Zhang等[127]利用CNN的转移学习提出了FR视频质量评估。他们先对网络中的失真图像进行预训练,然后利用小型视频质量数据库将其转换成视频。Bampis等人将连续视频质量预测问题表述为一个时间序列预测问题,并利用RNNs预测质量分数。Yan等人,118]pro。提出了一种基于两流CNN的NR图像质量预测器,其中一流关注图像强度,另一流从梯度中学习结构特征。Kim等人提出了一种基于CNN的全向图像NR质量评价方法。它首先预测每个patch的质量分数,并将这些分数汇总为全向图像的分数。然后,在人类感知向导的帮助下,使用对抗性学习来评估预测的分数,从而获得一个鉴别器。这些基于端到端学习的VQA度量可以自动地、同时地从原始可视数据中学习特性和映射功能。此外,这些端到端方案通过对MOS数据的拟合,可以显著提高预测性能。然而,HVS背后的机制很难解释,如果没有再培训,所学的知识就不能转移或适用于其他任务。
此外,最具挑战性的问题之一是基于深度学习的方法需要非常大量的标记数据用于培训[127,43]。如果训练数据集不够或不能充分代表真实世界的视频,学习模型可能难以处理各种内容和失真[92]。此外,数据的缺乏可能会导致严重的过拟合问题。事实上,只有非常有限的标记图像可用于质量评估,这对视频数据集来说更加重要,如6.1节所述。一个初步的解决方案是通过标记每个patch[24]的质量来增加数据,而不是整个图像。这种增强通常是在假设图像或视频中的所有补丁都具有相同的质量的情况下进行的,这可能不成立。另一种尝试是使用现有的度量来生成足够的[45]培训质量分数。深度神经网络本质上是一种模拟,因此也可能存在偏差。一个现有的度量标准,而不是HVS感知。此外,在当前阶段,模型是从大量的数据中学习的,而对非常少的数据进行了验证和测试。如何解决数据可用性问题或如何从小数据中学习值得更多的工作。转移学习[127,97,73]从一个有大量数据的领域转移学到的知识是一个可能的解决方案,值得进一步研究。
6.3 进一步讨论
将VQA算法应用于视频编码模块作为质量目标时,需要将VQA算法从基于图像/视频的算法调整为基于块的算法[113]。然后,对速率失真理论的适应也应该重新考虑,因为它最初是基于MSE设计的[82,67]。在应用于视频编码之前,一种简便的方法是建立VQA和MSE之间的数学关系。然而,这种近似降低了VQA的准确性。此外,目前的VQAs针对不同的应用,如图像[24,118]、视频[58,127,4]、立体声/3D[119,120]或全向虚拟现实[41]。因此,感知视频编码算法将通过使用这些指标进行专门设计。适用于不同应用的通用VQA是首选,但难以实现。另一个具有挑战性的问题是计算复杂性。由于在质量预测中采用了更先进的特征提取工具和学习分类器,计算复杂度显著增加。RDO中频繁调用基于学习的VQA算法,特别是基于深度学习的方案,使得编码算法非常复杂。如何将VQA,尤其是性能较好的基于学习的VQA集成到复杂度可接受的视频编码中是值得研究的。
7. 结论和将来的工作
7.1 结论
本文系统综述了近年来机器学习视频编码优化的研究进展和面临的挑战,旨在为研究人员提供一个坚实的基础,为数据驱动的视频信号处理开辟新的领域。本研究主要从基于学习的低复杂度优化、基于学习的高效编码优化和基于学习的视觉质量评估三个关键方面展开。在每个部分,问题的制定,工作流程,关键技术的进展,优势和挑战的问题。这些基于学习的视频编码优化可以以更智能的方式对视频进行编码,显著提高某些编码模块的编码性能。问题表示是连接编码算法和机器学习算法之间的桥梁,它决定了利用学习算法的优势和最大化编码效率的能力。为了更好的适应和有效性,在使用学习工具时,需要对特征提取与选择、实例/样本选择和成本函数进行适当的设计。端到端深度学习是一种能够显著提高视频编码预测和分类精度的新兴工具。仍然需要对问题的形成和适应进行更多的调查。同时,这种复杂性开销是一个重要的问题,应该在实际应用中得到很好的解决。总之,基于学习的编码优化有许多优点和潜力,这将是一个学术界和工业界有前途的方向。
7.2 将来的工作
在对相关工作进行回顾的基础上,出现了一些有前途的研究方向:
- 智能/智能视频编码:不仅可以对视频进行更智能的编码,提高编码效率,还可以使编码后的视频具有更高级的认知信息,如人脸/人识类别、对象识别/甚至检测、字幕和评论等智能视频应用。将分析和记录任务与编码任务相结合,不仅可以更有效地重用视频信息,而且可以降低解码、识别、分析和检索的复杂度。在这种情况下,视频编码需要考虑分析或识别的关键特征。
- 学习算法是提高编码性能的关键因素之一。将主动学习、集成学习、强化学习、转移学习、深度学习等先进的学习算法应用到视频编码中,以解决新一代视频编码标准中更为复杂的决策问题是值得的。例如:VCC及将来的工作。
- 基于感知的视频编码技术是一个很有发展前景的研究领域,值得进一步研究。其中最重要的问题之一是建立一个在准确性、复杂性和适应性方面得到广泛认可的客观的视觉感知模型,这就需要对人机交互和大规模的主观视觉数据有更多的理解,才能进行模型训练和可靠的验证。同时,将基于学习的感知模型作为成本准则合理地集成到各个视频编码模块中,在编码复杂度和适应性方面都存在一定的挑战。有效的实现和基于感知的RDO理论需要进一步的研究。
- 基于深度学习的视频编码优化有望在预测、滤波、增强、变换、控制以及新的编码框架等方面不断引起研究兴趣。更高的编码可以预期,潜在的技术改进将带来收益。然而,计算复杂度是优化过程中必须考虑的关键问题。
- 基于机器学习的视频编码方案,尤其是基于深度学习的视频编码方案,具有硬件低、成本低的特点,将成为视频编码领域的一个重要课题。
- 机器学习模型,尤其是深度学习模型,高度依赖于训练数据,即、数据依赖关系。离线学习模型在训练后是固定的,一旦应用到一种新的视频内容或发布中,编码性能可能会下降。引入在线学习或转移学习来更新学习模型是非常重要的。此外,还需要考虑学习模型的普遍性和特殊性之间的权衡。
我们认为基于学习的编码优化是未来视频编码的一个很有前途的研究方向。更多的学习算法和优化技术将不断研究和引入视频编码,以实现更低的复杂度、更高的编码效率、更高的视觉质量和更智能的功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号