Densite_RANK 函数
densite_RANK()是一个窗口函数,它为分区或结果集中的每一行分配一个等级,等级值之间没有间隔。
行的秩从行之前的不同秩值的数量增加1。
首先,PARTITION BY子句将FROM子句生成的结果集划分为多个分区。稠密_RANK()函数应用于每个分区。
其次,ORDER BY子句指定每个分区中稠密_RANK()函数操作的行的顺序。
如果一个分区有两行或多行具有相同的秩值,则这些行中的每一行都将被分配相同的秩。
与RANK()函数不同,densite_RANK()函数始终返回连续的秩值。
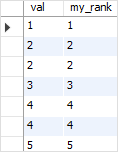
假设我们有一个表t,其中包含一些样本数据,如下所示:
CREATE TABLE t ( val INT ); INSERT INTO t(val) VALUES(1),(2),(2),(3),(4),(4),(5); SELECT * FROM t;
以下语句使用DENSE_RANK()函数为每一行指定一个列组:
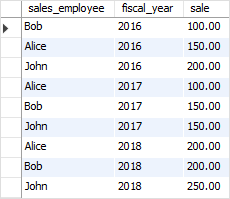
我们将使用在窗口函数教程中创建的sales表进行演示。
下面的语句使用DENSE_RANK()函数按销售额对销售人员进行排名。
SELECT sales_employee, fiscal_year, sale, DENSE_RANK() OVER (PARTITION BY fiscal_year ORDER BY sale DESC ) sales_rank FROM sales;
结果如下:
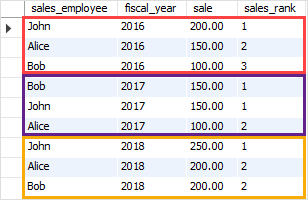
首先,PARTITION BY子句使用会计年度将结果集划分为多个分区。
其次,ORDERBY子句按销售降序指定销售人员的顺序。
第三,稠密_RANK()函数应用于每个分区,其行顺序由order by子句指定。

