python requests 接口: 调用百度开发者平台图片文字识别接口
1、get请求:
(1)图灵聊天机器人
import requests import json url="http://www.tuling123.com/openapi/api" apiKey="ec961279f453459b9248f0aeb6600bbe" while True: try: info=input() if info=="bye": print("see you again") break params={"key":apiKey,"info":info} r=requests.get(url=url,params=params) r=json.loads(r.text) print(r["text"]) except: break
2、post请求
import requests import json url="http://httpbin.org/post" data={"name":"god","age":"∞"} res=requests.post(url=url,data=json.dumps(data)) print(res.text)
3、json格式化文件。
import json res={"name":"张三","age":1} with open("dic.json","w") as f: json.dump(res,f) with open("dic.json","r") as f: r=json.load(f) print(r['name'])
4、token鉴权
(1)注册百度开发者平台:https://passport.baidu.com/v2/?reg
(2)新手指南:http://ai.baidu.com/ai-doc/REFERENCE/Ck3dwjgn3
识别图片中文字: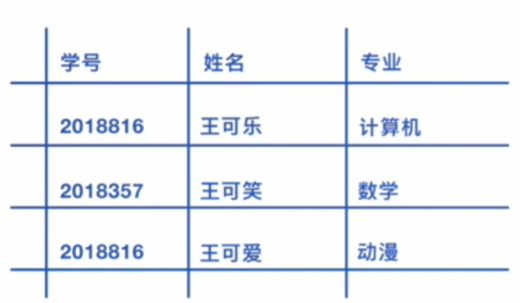
import requests import json import base64 API_KEY="KgKqmpVH9LGphO423uZ0wcGD" SECRET_KEY="bb65GOAo0CsqlI6E3PyrzZbgkdsyUsDT" img_url="https://699pic.com/tupian-401907129.html" TOKEN_URL = 'https://aip.baidubce.com/oauth/2.0/token' #通用文字识别 OCR_URL = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic" """ 获取token """ def fetch_token(): params = {'grant_type': 'client_credentials', 'client_id': API_KEY, 'client_secret': SECRET_KEY} #返回字典 try: res=requests.get(url=TOKEN_URL,params=params,timeout=2).json() except Exception as err: return err if "access_token" in res.keys(): return res["access_token"] else: return 'please overwrite the correct API_KEY and SECRET_KEY' """ 读取本地图片 """ def read_file(image_path): try: with open(image_path,"rb") as fp: img=base64.b64encode(fp.read()) return img except Exception as e: return e """ 调用远程服务 """ def request(url,data=None): req=requests.post(url,data) return req.json() """读取文字 """ def get_word(res): text="" for words_result in res["words_result"]: text=text+words_result["words"] return text if __name__=="__main__": token=fetch_token() image_path="test.PNG" params={"image":read_file(image_path)} url="{}?access_token={}".format(OCR_URL,token) res=request(url,params) req=get_word(res) print(req) """output""" 学号姓名专业2018816王可乐计算机2018357王可笑数学2018816王可爱动漫 """
5、session会话保持
import requests s = requests.session() params={"username":"admin","password":"passwd"} s.post(url,data=params) res=s.get(url) print(res.text)
6、使用cookie
import requests cookies={"a":"b"} res=requests.get(url,cookies=cookies) print(res.text)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号