
变量的内存分配情况
接触过编程的人都知道,高级语言都能通过变量名访问内存中的数据。那么这些变量在内存中是如何存放的呢?程序
又是如何使用这些变量的呢?
首先,来了解一下C语言的变量是如何在内存分布的。C语言有全局变量(Global)、本地变量(Local)、静态变量
(Static)和寄存器变量(Register)。每种变量都有不同的分配方式。先来看下面这段代码:

编译后的执行结果是:

输出的结果就是变量的内存地址。其中v1、v2、v3是本地变量,g1、g2、g3是全局变量,s1、s2、s3是静态变量。你
可以看到这些变量在内存中是连续分布的,但是本地变量和全局变量分配的内存地址差了十万八千里,而全局变量和静态
变量分配的内存是连续的。这是因为本地变量和全局/静态变量是分配在不同类型的内存区域中的结果。对于一个进程的
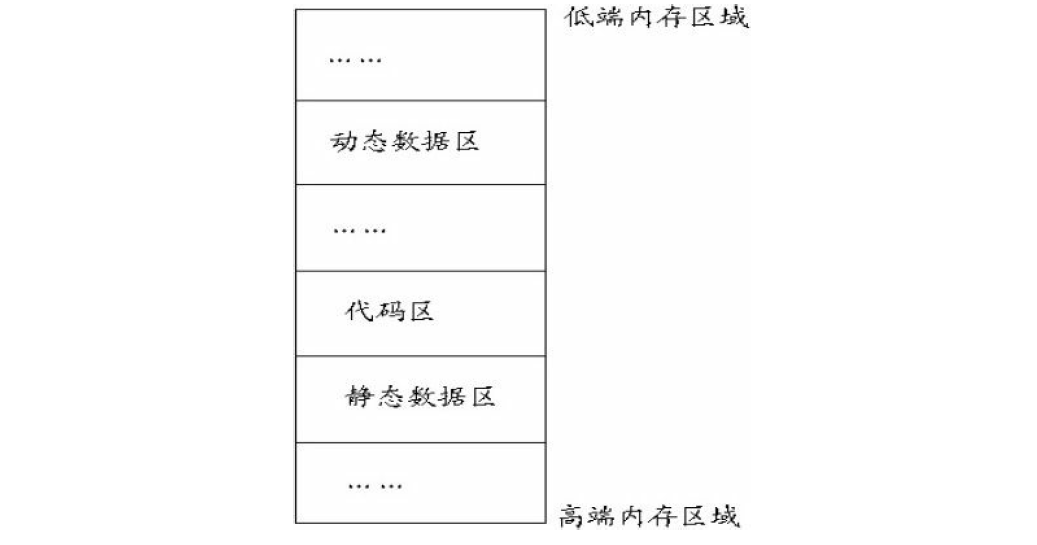
内存空间而言,可以在逻辑上分成3个部分:代码区、静态数据区和动态数据区。动态数据区一般就是“堆栈”。“栈
(stack)”和“堆(heap)”是两种不同的动态数据区。栈是一种线性节构,堆是一种链式节构。进程的每个线程都有私有
的“栈”,所以每个线程虽然代码一样,但本地变量的数据都是互不干扰的。
一个堆栈可以通过“基地址”和“栈顶”地址来描述。全局变量和静态变量分配在静态数据区,本地变量分配在动态数据
区,即堆栈中。程序通过堆栈的基地址和偏移量来访问本地变量,如下图所示。
堆栈是一个先进后出的数据结构,栈顶地址总是小于等于栈的基地址。我们可以先了解一下函数调用的过程,以便对
堆栈在程序中的作用有更深入的了解。不同的语言有不同的函数调用规定,这些因素有参数的压入规则和堆栈的平衡。
Windows API的调用规则和ANSI C的函数调用规则是不一样的,前者由被调函数调整堆栈,后者由调用者调整堆栈。两者
通过“_stdcall”和“_cdecl”前缀区分。先看下面这段代码:

编译后的执行结果是:

下面详细解释函数调用的过程中堆栈的分布:
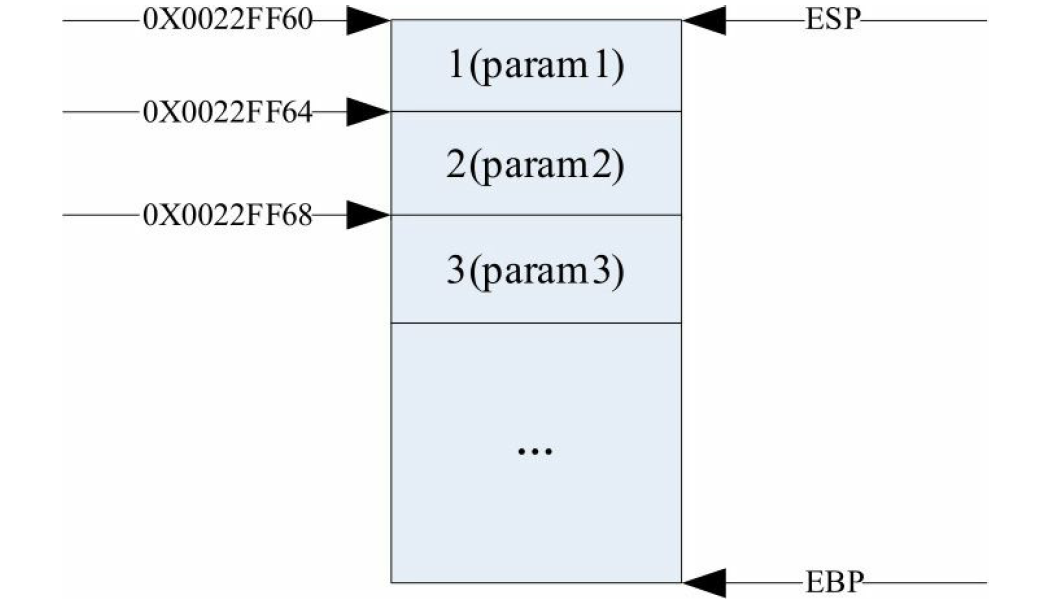
在堆栈中分布变量是从高地址向低地址分布,EBP指向栈底指针,ESP是指向栈顶的指针,根据__stdcall调用约定,参
数从右向左入栈,所以首先,3个参数以从右到左的次序压入堆栈,先压“param3”,再压“param2”,最后压入“param1”。
栈内分布如下图所示。
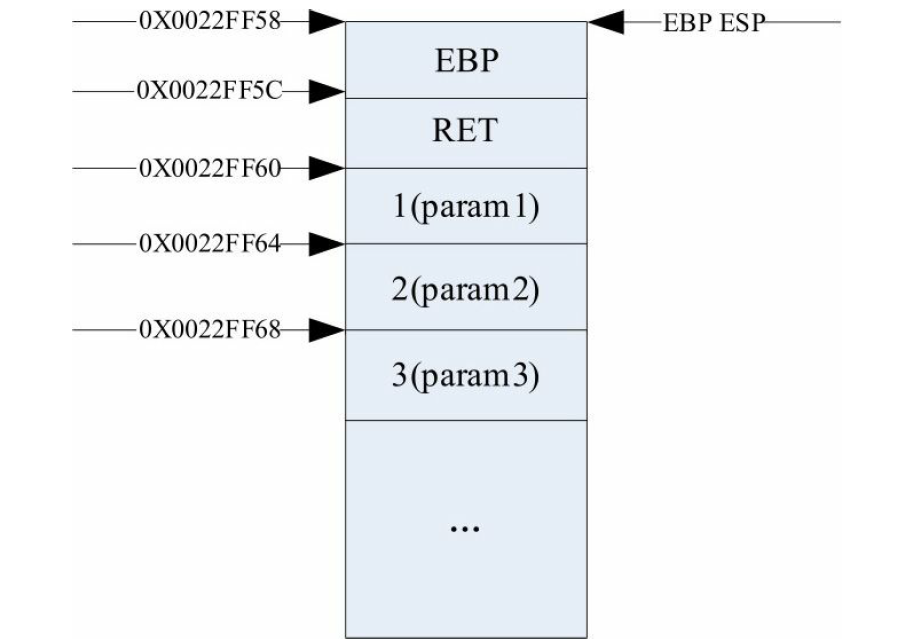
然后函数的返回地址入栈,栈内分布如下图所示。

通过跳转指令进入函数。函数地址入栈后,EBP入栈,然后把当前的ESP的值给EBP,汇编下指令为:

此时栈底指针和栈顶指针指向同一位置,栈内分布为如下图所示。
然后是int var1=param1;int var2=param2;int var3=param3;也就是变量var1,var2,var3的初始化(从左向右的顺序入
栈),按声明顺序依次存储到EBP-4,EBP-8,EBP-12位置,栈内分布如下图所示。

Windows下的动态数据除了可存放在栈中,还可以存放在堆中。了解C++的朋友都知道,C++可以使用new关键字来
动态分配内存。来看下面的C++代码:

程序执行结果为:

可以发现用new关键字分配的内存既不在栈中,也不在静态数据区

