
数据分析 - NumPy模块
安装
pip install numpy
数组定义
数组对象ndarray
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引
ndarray 对象是用于存放同类型元素的多维数组。
ndarray 中的每个元素在内存中都有相同存储大小的区域。
ndarray 内部由以下内容组成:
- 一个指向数据(内存或内存映射文件中的一块数据)的指针
- 数据类型或 dtype,描述在数组中的固定大小值的格子
- 一个表示数组形状(shape)的元组,表示各维度大小的元组
- 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要"跨过"的字节数。

数组属性
NumPy 数组的维数称为秩(rank),秩就是轴的数量,即数组的维度,一维数组的秩为 1,二维数组的秩为 2,以此类推
在 NumPy中,每一个线性的数组称为是一个轴(axis),也就是维度(dimensions)
很多时候可以声明 axis。axis=0,表示沿着第 0 轴进行操作,即对每一列进行操作;axis=1,表示沿着第1轴进行操作,即对每一行进行操作
-
ndarray.ndim:秩,即轴的数量或维度的数量

-
ndarray.shape:数组的维度,对于矩阵,n 行 m 列

-
ndarray.size:数组元素的总个数,相当于 .shape 中 n*m 的值

-
ndarray.dtype:ndarray 对象的元素类型

-
ndarray.itemsize:ndarray 对象中每个元素的大小,以字节为单位

-
ndarray.flags:ndarray 对象的内存信息

-
ndarray.real:对象实部

-
ndarray.imag:对象虚部

-
ndarray.data:包含实际数组元素的缓冲区,由于一般通过数组的索引获取元素,所以通常不需要使用这个属性。
数组类型对象dtype
-
Numpy基本类型

-
数据类型对象(numpy.dtype 类的实例)用来描述与数组对应的内存区域是如何使用,它描述了数据的以下几个方面
- 数据的类型(整数,浮点数或者 Python 对象)
- 数据的大小(例如, 整数使用多少个字节存储)
- 数据的字节顺序(小端法或大端法)
- 在结构化类型的情况下,字段的名称、每个字段的数据类型和每个字段所取的内存块的部分
- 如果数据类型是子数组,那么它的形状和数据类型是什么
字节顺序是通过对数据类型预先设定 < 或 > 来决定的。 < 意味着小端法(最小值存储在最小的地址,即低位组放在最前面)。> 意味着大端法(最重要的字节存储在最小的地址,即高位组放在最前面)。
-
numpy.dtype(object, align, copy)
- object:要转换为的数据类型对象
- align - 如果为 true,填充字段使其类似 C 的结构体
- copy - 复制 dtype 对象 ,如果为 false,则是对内置数据类型对象的引用

int8, int16, int32, int64 四种数据类型可以使用字符串 'i1', 'i2','i4','i8' 代替;S20代表特定长度的字符串,f4表示float32

结构化数据类型的使用,类型字段和对应的实际类型将被创建(方便同类数据的比较)


数组的广播
数组与标量或者不同形状的数组进行算术运算的时候,就会发生数组的广播
只能是一维数组,二维数组报错(本质可以看是标量,广播成相同形状的数组,按照一下的规则)

广播规则:
- 先比较形状,在比较维度,最后比较对应轴长度
- 如果两个数维度不相等,会在低维度数组形状左侧填充1,直到维度与高维度数组相等
- 如果两个数组维度相等时,要么对应轴的长度相同,要么其中一个轴长度为1,则兼容的数组可以广播,长度为1的轴会被扩展



创建数组的常用函数
创建一维数组
- numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0):创建一维数组
- object:类型可以是列表或者元组
- dtype:数组元素的数据类型
- copy:对象是否需要复制,可选
- order:创建数组的样式,C为行方向,F为列方向,A为任意方向(默认)
- subok:默认返回一个与基类类型一致的数组
- ndmin:指定生成数组的最小维度

-
numpy.arange(start,stop,step,dtype):创建数值范围并返回数组对象
- start:开始值
- stop:结束值,不包含
- step:步长,不写,默认1,该值可以为负
- dtype:数组元素类型

-
numpy.linspace(start,stop,num,endpoint,retstep,dtype):创建等差数组
- num:设置生成的元素个数
- endpoint:设置是否包含结束值,False不包含,True包含,默认是True
- retstep:设置是否返回步长,False不返回,默认值,True返回,如果是True,返回值是二元组,包括数组和步长


-
numpy.logspace(start,stop,num,endpoint,base,dtype):创建等比数组
- start:开始值:base**start
- stop:结束值:base**stop
- base:底数

创建二维数组
-
numpy.array(object)
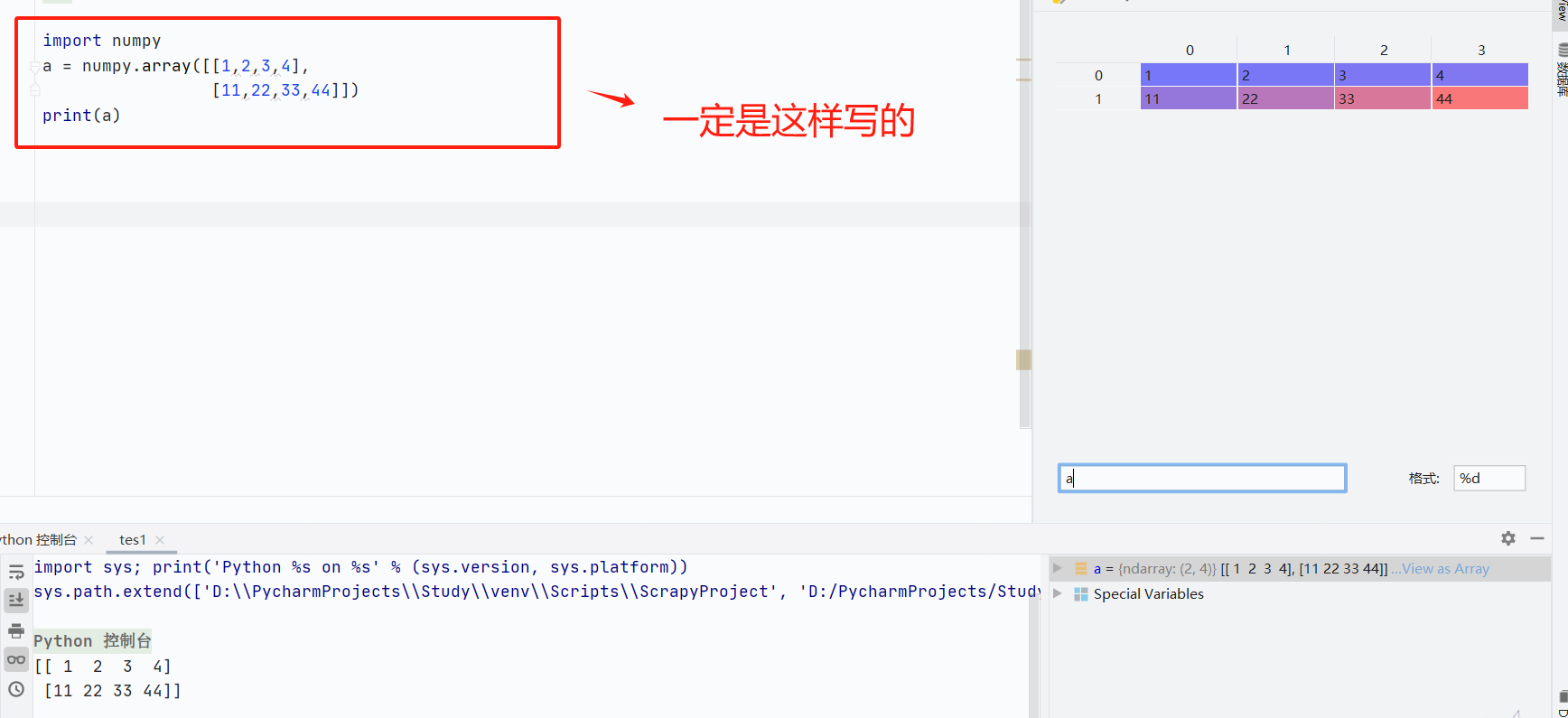
-
numpy.ones(shape,dtype=None):根据形状和数据类型生成全为1的数组
shape:数组的形状(几行几列)

-
numpy.zeros(shape,dtype=None):根据形状和数据类型生成全为0的数组

-
numpy.full(shape,fill_value,dtype=None):根据指定形状和数据类型生成数组,并且用指定数据填充
fill_value:指定填充数据
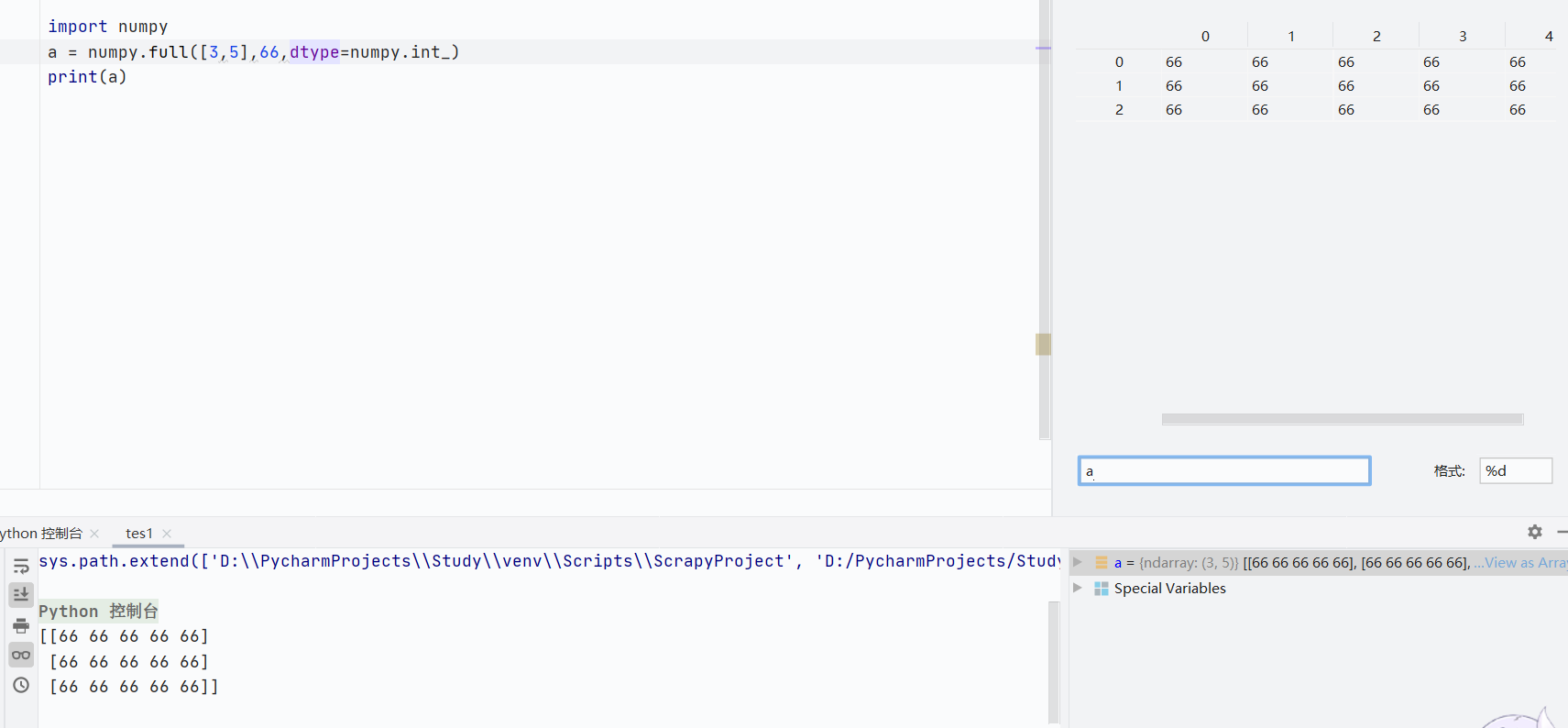
-
numpy.identity(n,dtype=None):创建单位矩阵(即对角线为1,其他元素为0)
n:数组形状

创建随机数组
-
numpy.random.rand(d0,d1,...,dn):该函数返回[0.0,1.0)的随机浮点数
d0,d1,...dn表示数组的形状

-
numpy.random.randint(low,high,size,dtype):该函数返回[low,high)的随机整数

-
numpy.random.normal(loc,scale,size):该函数返回正态分布随机整数
- loc:表示平均值
- scale:表示标准差

-
numpy.random.randn(d1,d2,...dn):该函数返回标准正态分布随机数,即平均数为0,标准差为1的正态分布随机数

数组的切片和索引
索引访问
-
ndarray[index]:一维数组的索引访问和Python内置序列类型索引访问一样


-
ndarray[index]:一维数组的索引访问和Python内置序列类型索引访问一样
-
二维数组索引访问

-
ndarray[所在0轴索引][所在1轴索引]
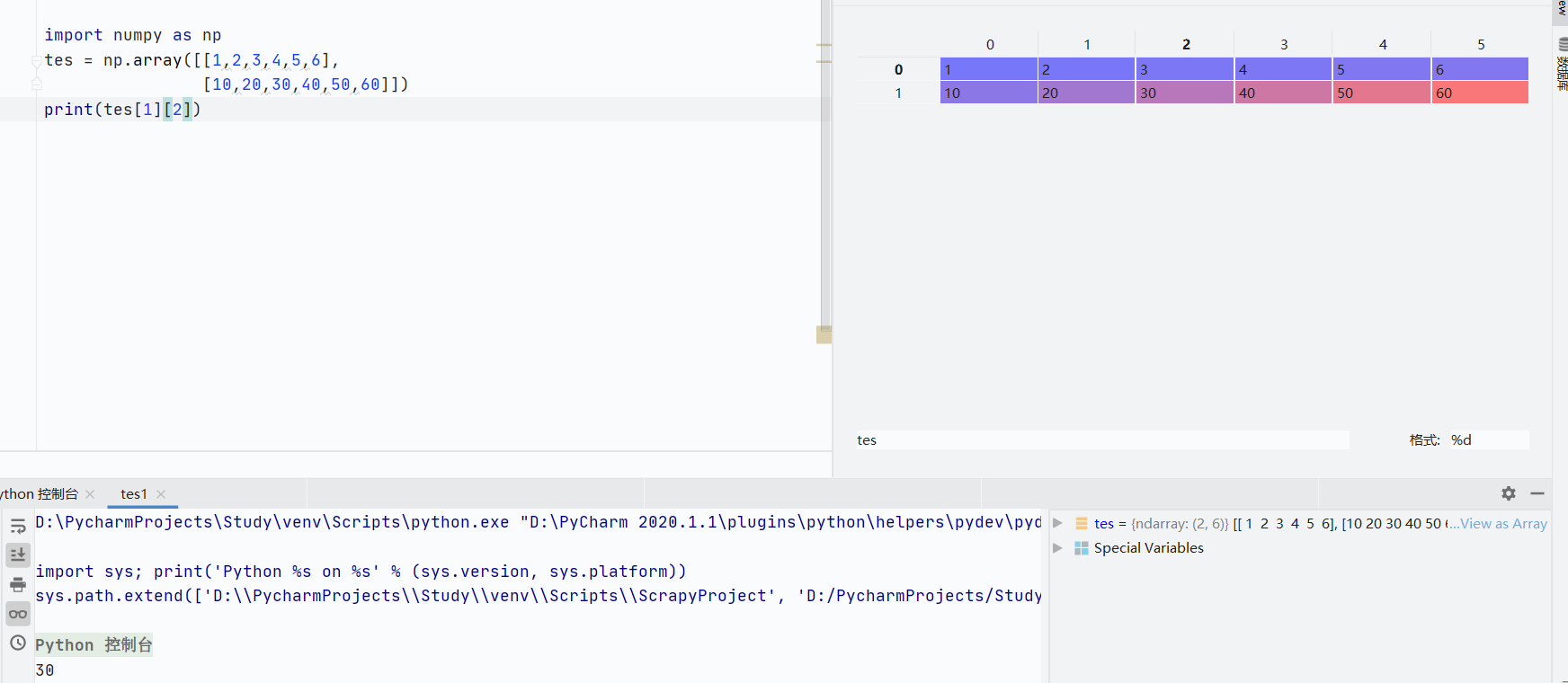
-
ndarray[所在0轴索引,所在1轴索引]

-
-
花式索引
花式索引返回的新数组与花式索引数组形状形同
花式索引返回的新数组,属于深层复制- 整数列表索引


- 整数数组索引:整数数组索引是指使用一个数组来访问另一个数组的元素。这个数组中的每个元素都是目标数组中某个维度上的索引值
import numpy as np b = np.array([[1,23,45,9,30,364], [379,120,82,82,4,890], [2500,41,771,392,85,17], [82,80,157,36,5,445], [247,1056,571,567,15,67]]) m =np.array([1,4]) n = np.array([2,3]) TesB = b[m,n] print('用一维数组做二维数组的索引:%s,轴是%s'%(TesB,TesB.ndim)) m1= [1,4] n1 = [2,3] TesB1 = b[m1,n1] print('用列表做二维数组的索引:%s,轴是%s'%(TesB1,TesB1.ndim)) m2 = np.array([[1,2,3], [2,3,4]]) n2 = np.array([[0,1,3], [1,2,3]]) TesB2 = b[m2,n2] print('用二维数组做二维数组的索引:%s,轴是%s'%(TesB2,TesB2.ndim))
- 整数列表索引
-
布尔索引:传递布尔索引,从数组过滤出我们需要的元素
1. 布尔索引必须要与索引的数组形状相同,否则报错
2. 布尔索引返回的新数组是原数组的副本,与原数组不共享相同的数据空间,即新数组的修改不会影响原数组,即深层复制-
直接用True,False进行过滤

-
通过布尔运算(如:比较运算符)来获取符合指定条件的元素的数组

-
切片访问
-
一维数组切片访问与Python内置的序列类型切片访问一样
-
ndarray[start:end]

-
ndarray[start: end : step]

-
-
二维数组切片访问
ndarray[所在0轴的切片,所在1轴的切片]

数组的常用操作
数组的修改
-
numpy.T(numpy.transpose)数组的转置

-
numpy.reshape(arr, newshape, order='C'):修改数组的形状
- arr:要修改形状的数组
- newshape:整数或者整数数组,新的形状应当兼容原有形状
- order:'C' -- 按行,'F' -- 按列,'A' -- 原顺序,'k' -- 元素在内存中的出现顺序(按行或者按列修改填充)

-
numpy.resize(arr, shape):函数返回指定大小的新数组

-
numpy.ravel(a, order='C/F')
- order:'C' -- 按行,'F' -- 按列,'A' -- 原顺序,'K' -- 元素在内存中的出现顺序。

- order:'C' -- 按行,'F' -- 按列,'A' -- 原顺序,'K' -- 元素在内存中的出现顺序。
数组的连接
-
numpy.concatenate((a1,a2),axis):沿指定轴连接多个数组
- a1和a2是要连接的数组,除指定轴外其他轴的元素个数必须相同
- axis是沿指定轴的索引,默认为0轴

-
numpy.stack(arrays, axis):函数用于沿新轴连接数组序列(维度会加一)
- arrays:相同形状的数组序列
- axis:返回数组中的轴,输入数组沿着它来堆叠

-
numpy.vstack((a1,a2)):相当于concatenate((a1,a2),axis=0)

-
numpy.hstack((a1,a2)):相当于concatenate((a1,a2),axis=1)

数组的分割
-
numpy.split(ary,indices_or_sections,axis):该函数指沿指定轴分割多个数组
- ary:需要分割的数组
- indices_or_sections:整数或者数组;整数必须要能平均分割,否则报错;数组沿指定轴的切片操作
import numpy as np tes = np.array([[1,2,3,4,1,1], [7,8,9,10,3,3], [5,6,11,12,4,2], [1,2,3,4,1,1], [5,1,5,16,7,3]]) tes1 = np.arange(1,24,3) m = 2 n = np.array([1,3]) print('整数:%s'%(np.split(tes1,m))) print('数组:%s'%(np.split(tes,n))) print('数组,按照1轴:%s'%(np.split(tes,n,axis=1)))
-
numpy.vsplit(ary,indices_or_sections):相当于split(ary,indices_or_sections,axis=0)

-
numpy.hsplit(ary,indices_or_sections):相当于split(ary,indices_or_sections,axis=1)

数组的迭代
- numpy.nditer(a)
import numpy as np
m =np.random.randint(1,30,(3,4))
for i in np.nditer(m):
print(i)
print(type(np.nditer(m)))

a 和 a.T 的遍历顺序是一样的,也就是他们在内存中的存储顺序也是一样的

- numpy.nditer(a, order='F'):Fortran order,即是列序优先
- numpy.nditer(a, order='C'):C order,即是行序优先,默认

数组元素的修改
-
numpy.append(arr, values, axis=None)函数在数组的末尾添加值。 追加操作会分配整个数组,并把原来的数组复制到新数组中。 此外,输入数组的维度必须匹配否则将生成ValueError;函数返回的始终是一个一维数组
-
arr:输入数组
-
values:要向arr添加的值,需要和arr形状相同(除了要添加的轴)
-
axis:默认为 None。
当axis无定义时,是横向加成,返回总是为一维数组!

当axis有定义的时候,分别为0和1的时候。
当axis为0的时候,数组是加在底下(列数要相同)。

当axis为1时,数组是加在右边(行数要相同)

-
-
numpy.insert(arr, obj, values, axis):函数在给定索引之前,沿给定轴在输入数组中插入值
- arr:输入数组
- obj:在其之前插入值的索引
- values:要插入的值
- axis:沿着它插入的轴,如果未提供,则输入数组会被展开

-
numpy.delete(arr, obj, axis)
- arr:输入数组
- obj:可以被切片,整数或者整数数组,表明要从输入数组删除的子数组
- axis:沿着它删除给定子数组的轴,如果未提供,则输入数组会被展开

数组的聚合(数组元素之间)
-
求和
- numpy.sum(a,axis=None)
- numpy.nansum(a,axis=None):该函数忽略NaN
- numpy.ndarray.sum(axis=None)

-
求最大值
-
numpy.amx(a,axis=None)
-
numpy.nanmax(a,axis=None):该函数忽略NaN
-
numpy.ndarray.max(axis=None)

-
numpy.armax(a,axis=-1,kind='quicksort',order=None):函数返回的是数组值从小到大的索引值

-
数组的排序,条件筛选函数
-
numpy.unique(arr, return_index, return_inverse, return_counts):函数用于去除数组中的重复元素
- arr:输入数组,如果不是一维数组则会展开
- return_index:如果为true,返回新列表元素在旧列表中的位置(下标),并以列表形式储
- return_inverse:如果为true,返回旧列表元素在新列表中的位置(下标),并以列表形式储
- return_counts:如果为true,返回去重数组中的元素在原数组中的出现次数

-
numpy.sort(a,axis=-1,kind='quicksort',order=None):按照轴对数组进行排序,即轴排序
- a:表示要排序的数组
- axis:表示排序的轴索引,默认是-1,表示最后一个轴
- kind:表示排序类型,quicksort:快速排序,为默认值,mergesort:并归排序;heapsort:堆排序
- order:表示排序字段

-
numpy.argsort(a,axis=-1,kind='quicksort',order=None):函数返回的是数组值从小到大的索引值

-
ndarray.where(condition,x,y):ndarray 对象的元素类型
- condition:表示条件,当只存在条件时,返回符合条件的元素坐标,以元组方式返回

import numpy as np m = np.random.rand(5,4) n1= np.where(m>0.5) d = zip(n1[0],n1[1]) ###返回坐标对对象,可以通过for循环,也可以知己通过list列出所有坐标对 print(list(d))
-
x,y:表示条件成立返回x,条件不成立返回y

-
多条件时,&表示与,|表示或

- condition:表示条件,当只存在条件时,返回符合条件的元素坐标,以元组方式返回
-
numpy.extract(condition,arr) 函数根据某个条件从数组中抽取元素,返回满条件的元素。
- condition:numpy数组,元素为布尔值

- condition:numpy数组,元素为布尔值
数组的算术函数(数组之间;需要注意的是数组必须具有相同的形状或符合数组广播规则。)
-
numpy.add(object)

-
numpy.mod() 计算输入数组中相应元素的相除后的余数。
-
numpy.remainder():同上

-
numpy.power() 函数将第一个输入数组中的元素作为底数,计算它与第二个输入数组中相应元素的幂

数组的其他数学计数统计类函数
-
numpy.around(a,decimals):函数返回指定数字的四舍五入值
- a: 数组
- decimals: 舍入的小数位数。 默认值为0。 如果为负,整数将四舍五入到小数点左侧第n位的近似的

-
numpy.floor() 返回小于或者等于指定表达式的最大整数,即向下取整

-
numpy.ceil() 返回大于或者等于指定表达式的最小整数,即向上取整

-
numpy.median() 函数用于计算数组 a 中元素的中位数(中值)

-
numpy.mean(a, axis=None, dtype=None, out=None, keepdims=
) 函数返回数组中元素的算术平均值,如果提供了轴,则沿其计算;算术平均值是沿轴的元素的总和除以元素的数量 - a: 输入的数组,可以是一个 NumPy 数组或类似数组的对象。
- axis: 可选参数,用于指定在哪个轴上计算平均值。如果不提供此参数,则计算整个数组的平均值。可以是一个整数表示轴的索引,也可以是一个元组表示多个轴
- dtype: 可选参数,用于指定输出的数据类型。如果不提供,则根据输入数据的类型选择合适的数据类型
- out: 可选参数,用于指定结果的存储位置。
- keepdims: 可选参数,如果为True,将保持结果数组的维度数目与输入数组相同。如果为False(默认值),则会去除计算后维度为1的轴。

-
numpy.ptp(a, axis=None, out=None, keepdims=
, initial= , where= )函数计算数组中元素最大值与最小值的差(最大值 - 最小值) -
a: 输入的数组,可以是一个 NumPy 数组或类似数组的对象

-
axis: 可选参数,用于指定在哪个轴上计算峰-峰值。如果不提供此参数,则返回整个数组的峰-峰值。可以是一个整数表示轴的索引,也可以是一个元组表示多个轴。

-
out: 可选参数,用于指定结果的存储位置
-
keepdims: 可选参数,如果为 True,将保持结果数组的维度数目与输入数组相同。如果为 False(默认值),则会去除计算后维度为1的轴。(保持数组维度一样)

-
-
numpy.percentile(a, q, axis):百分位数是统计中使用的度量,表示小于这个值的观察值的百分比
- a: 输入数组
- q: 要计算的百分位数,在 0 ~ 100 之间
- axis: 沿着它计算百分位数的轴
数组的字符串函数
这些函数在字符数组类(numpy.char)中定义,以下类举几个,用法和字符串的函数差不多
-
numpy.char.add(arr1,arr2) :函数依次对两个数组的元素进行字符串连接

-
numpy.char.multiply(arr,i) 函数执行多重连接
- a:数组
- i:重复次数

-
numpy.char.center(a, width, fillchar=) 函数用于将字符串居中,并使用指定字符在左侧和右侧进行填充

-
numpy.char.split(a, sep=..., maxsplit=...) 通过指定分隔符对字符串进行分割,并返回数组。默认情况下,分隔符为空格

数组的保存读取
- numpy.save(file,arr,allow_pickle=True,fix_imports=True)
- file:表示文件名/文件路径
- arr:表示要存储的数组
- allow_pickle:为布尔值,表示是否允许使用pickle来保存数组对象
- fix_imports:为布尔值,表示是否允许在Python2中读取Python3保存的数据



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· PowerShell开发游戏 · 打蜜蜂
· 在鹅厂做java开发是什么体验
· 百万级群聊的设计实践
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战
· 永远不要相信用户的输入:从 SQL 注入攻防看输入验证的重要性