
1.为什么合批能提升性能,如何查看系统的drawcall
比如我们游戏场景中有100个物体,我们绘制每个物体的时候,提交给GPU,然后来绘制;
CPU:准备好数据,然后通过我们CPU与GPU通讯,给GPU提交数据,下达渲染命令
CPU-->内存--->提交数据给GPU显存;CPU传递的参数给shader;
CPU--->GPU-->下达渲染指令-->GPU开机,绘制CPU提交过来的3D模型
100个物体,分100次提交,CPU-->提交数据-->GPU下令绘制100次,开销就大
GPU每次处理三角形顶点数目有限制,比如GPU每次最多处理N个顶点数,100个物体,一个一个提交给GPU的面数,远远小于GPU的能力,GPU每次开机都是浪费的;本来可以处理1000个面,但每次开机只给50个面,那么白白浪费掉了GPU的性能。
如果100个物体一次性提交,GPU一次把它绘制完成,GPU只需要接受一次绘制渲染的指令,就可以把所有的物体渲染出来,GPU效率提升了,能够避免反复提交某些数据,如此CPU的效率也提升起来了,这就是合批的好处
把N个物体合到一次提交给GPU,GPU一次绘制搞定,这个过程叫合批。
CPU给GPU下达一次渲染指令,我们叫drawcall
批次数目/drawcall数目:一个游戏场景中的物体分几次提交给GPU绘制的数目
2.合批常用的技术原理与缺点
尽可能的让游戏场景中的物体能在一个较少的批次数目里面完成合批渲染--->这样就降低了drawcall
降低drawcall,那么渲染效率就会提升。
合批原则
同一个材质的物体,就有合批的可能
场景物体的渲染顺序
当绘制一个场景的时候,引擎会为场景物体生成一个绘制顺序
A1A2A3A4A5A6B1B2B3B4B5B6
合批常用技术
1.美术处理:场景美术可以根据需求把场景做到一个物体,或者少数几个里面--->节约渲染批次,比如:关卡,把真个关卡做到一个fbx模型文件里面
2.美术资源做好以后,引擎采用合批技术来进行合批,把多个不同的物体一起提交绘制
静态合批:
游戏引擎会将”能够合批“(同一个材质球)的”静态物体“(需要标记为静态不可移动物体)合到一次,提交给GPU;预先合并好这些静态物体成一个整体的网格,然后提交给GPU进行渲染
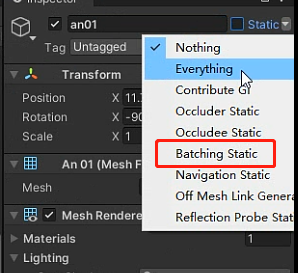
缺点:
1)要求物体是静态的
2)预先计算好合并整体网格,增加合并后的内存开销
3)把所有的网格合并到一起:有一些情况是一定要关闭静态合批的,如:森林成百上千的树,开启静态合批,合并以后,每棵树都有一个网格,那么1000棵树就会有1000个这样的网格,网格的开销和内存的开销就会暴涨,如果没有开静态合批,那么只会有一个网格。
动态合批:
游戏引擎将能够动态合批的物体的每个顶点,CPU根据它的矩阵,来计算出合批物体的每个顶点对应的世界空间的坐标,然后就把这些物体的顶点(世界空间下的顶点)加一个单位矩阵,提交给GPU,GPU就会把它们一起绘制出来,每一次绘制都要做一次计算
基于世界空间的坐标系,我们重新给这些动态和皮的物体来重新建模,重新建模后一起的顶点 + 材质提交给GPU,然后由GPU绘制出来
缺点:动态合批是一个双刃剑,CPU要消耗运算性能,来把模型的顶点转换到世界空间下(普通模式下是GPU计算的),CPU的开销和drawcall减少得到的性能提升之间做平衡
优点:合批带来的性能提升
注意:所以使用动态的合批的时候,要关注下,付出和收获是不是成比例。
动态合批是引擎自动处理的,所以引擎会对能够动态合批的物体,会有一些条件的限制
限制:顶点数目不宜过多
GPU Instancing的合批:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2020-02-10 js把列表转换成字符串