

机器学习-数据可视化神器matplotlib学习之路(五)
这次准备做一下pandas在画图中的应用,要做数据分析的话这个更为实用,本次要用到的数据是pthon机器学习库sklearn中一组叫iris花的数据,里面组要有4个特征,分别是萼片长度、萼片宽度、花瓣长度、花瓣宽度,目标值是3种不同类型的花。
机器学习的时候在学习好这四个特征后就可以用来预测花的类型了,而图像化分析这些数据就是机器学习中很关键的步骤,接下来我们开始,先导入数据:
import pandas as pd from sklearn import datasets from sklearn import preprocessing data = datasets.load_iris()#载入iris数据 # data = preprocessing.scale(boston.data)#正则化数据 pd.set_option('display.max_columns', None) d1_x = pd.DataFrame(data.data, columns=data.feature_names) d1_y = pd.Series(data.target) print(d1_x.head()) print(d1_y.head())
部分数据展示如下,可以看出有4个不同特征,3种不同的话目标值分别是0,1,2
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) 0 5.1 3.5 1.4 0.2 1 4.9 3.0 1.4 0.2 2 4.7 3.2 1.3 0.2 3 4.6 3.1 1.5 0.2 4 5.0 3.6 1.4 0.2 0 0 1 0 2 0 3 0 4 0 dtype: int32
很多时间图像更能直观反映出数据,接下来开始正题:
from matplotlib import pyplot as plt import pandas as pd from sklearn import datasets from sklearn import preprocessing data = datasets.load_iris()#载入iris数据 # data = preprocessing.scale(boston.data)#正则化数据 pd.set_option('display.max_columns', None) d1_x = pd.DataFrame(data.data, columns=data.feature_names) d1_y = pd.Series(data.target) print(d1_x.head()) print(d1_y.head()) d1_x.plot(linestyle='--', marker='.', alpha=0.5) #DataFrame的画图方式,依赖于matplotlib d1_y.plot(linestyle='-', linewidth=1.5, alpha=0.5, color='b', label='type') plt.legend() plt.show()
是不是很简单,和之前plt.plot()的画图几乎一样的,结果如下:
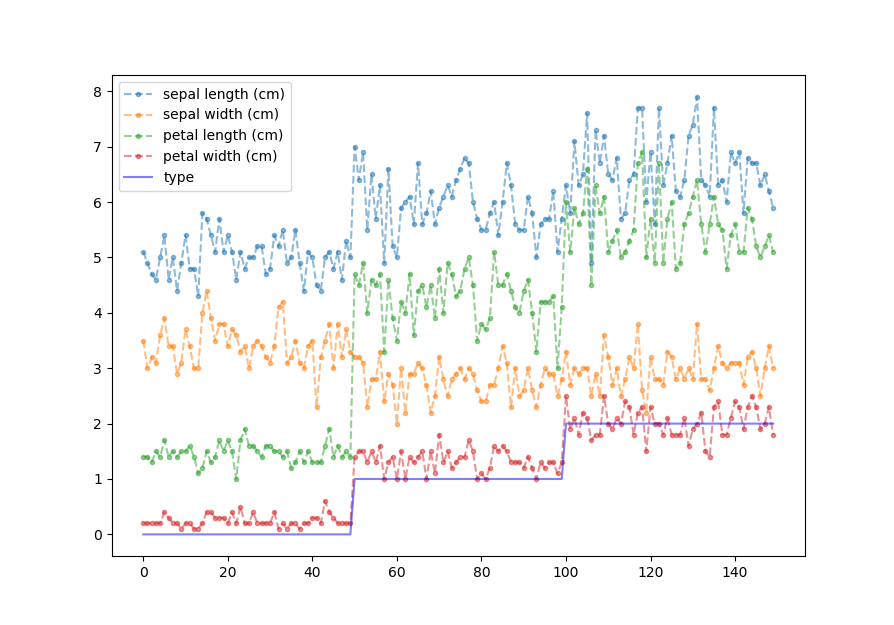
从上图中,比较直观的我可以看出,sepal width与花种类关系不大,其它三个特征则关系密切,根据这个图像分析从而可以进行下一步。
接下来,看看其它类型的图,由于这里数据不太适合条形图,那自己造一点数据吧:
from matplotlib import pyplot as plt import pandas as pd import numpy as np d1 = pd.DataFrame(np.random.rand(5, 3), columns=['A', 'B', 'C']) # 方法一 d1.plot.bar(cmap='summer') # 方法二 #d1.plot(kind='bar', colormap='cool') plt.show()
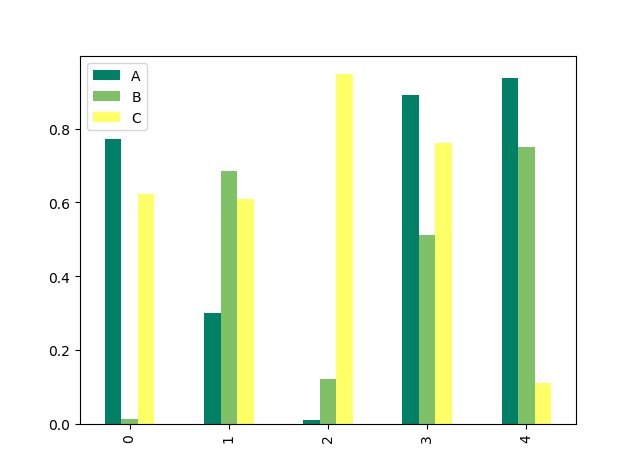
画条形图有两中方式,看代码,是不是很简单,其它图形就不全部都写出来了,方式都差不多,今天就到这里了。
