浅谈mysql底层索引
索引
B+树特征:数据全部放在叶子结点,并且按照索引字段递增排序。
扫描表的方式:
- 全表扫描
- 辅助索引+回表
假如一张表有abcde五个字段,a为主键。
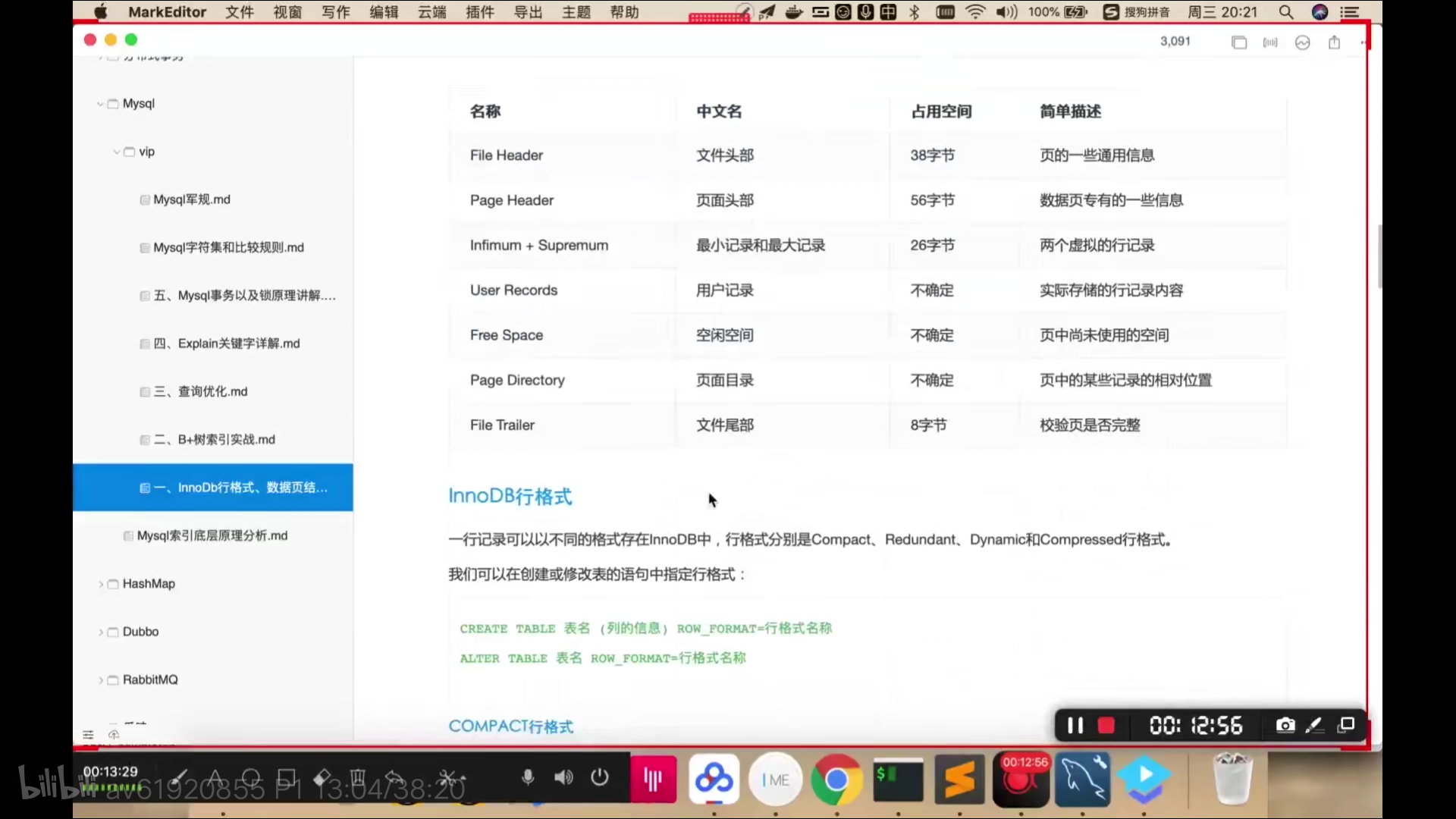
在innodb中,一页默认是16KB。有如下
- 主键索引
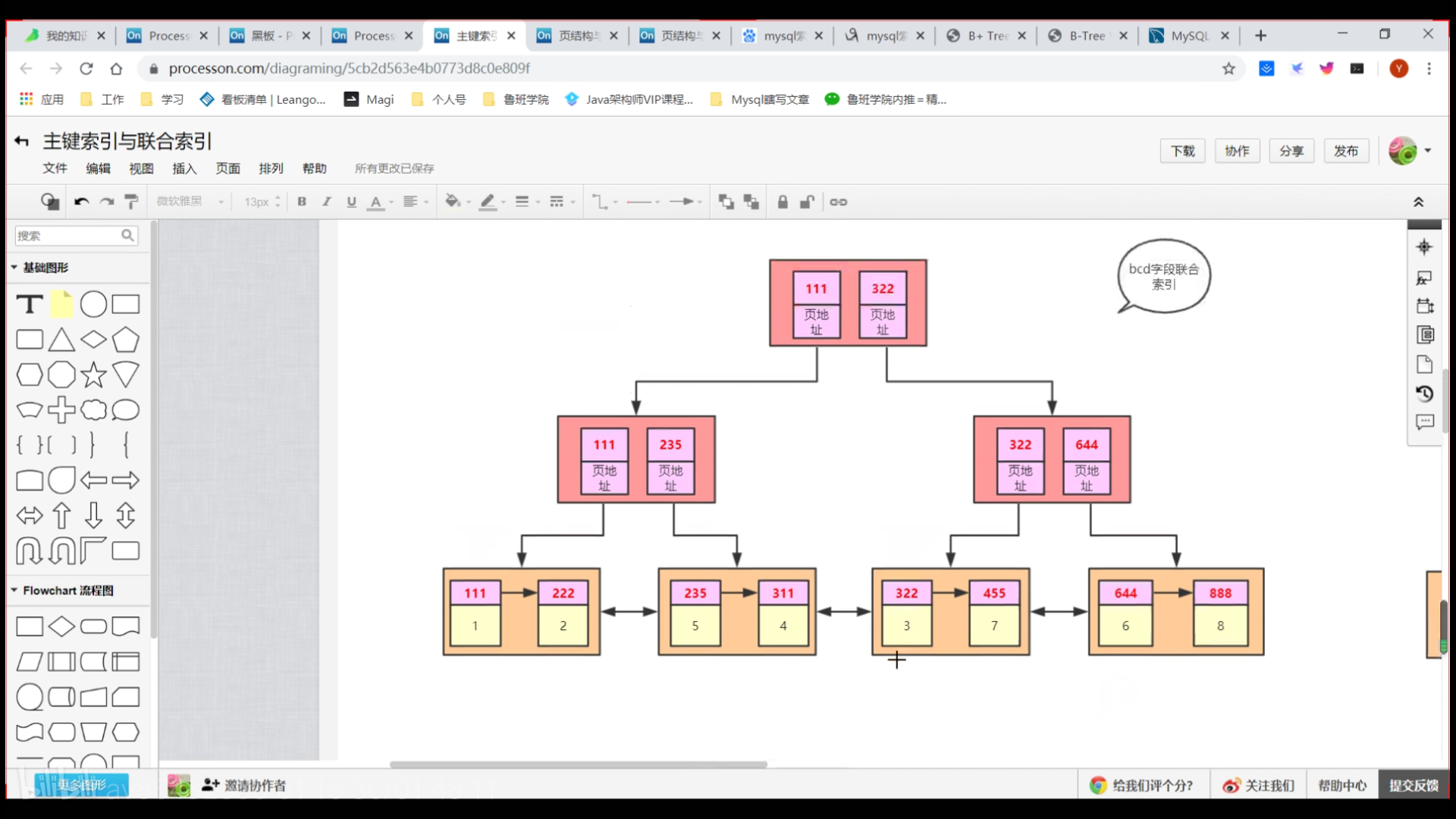
每一行都有隐藏的rowID,没有设置主键时,rowID则变成主键。 - 联合索引
假如bcd三个字段联合索引, **回表的意思是通过联合索引查出来的主键,再通过主键索引查询数据。 **
MySQL5.7以前会回表多次,
5.7及以后做了优化会回表一次。
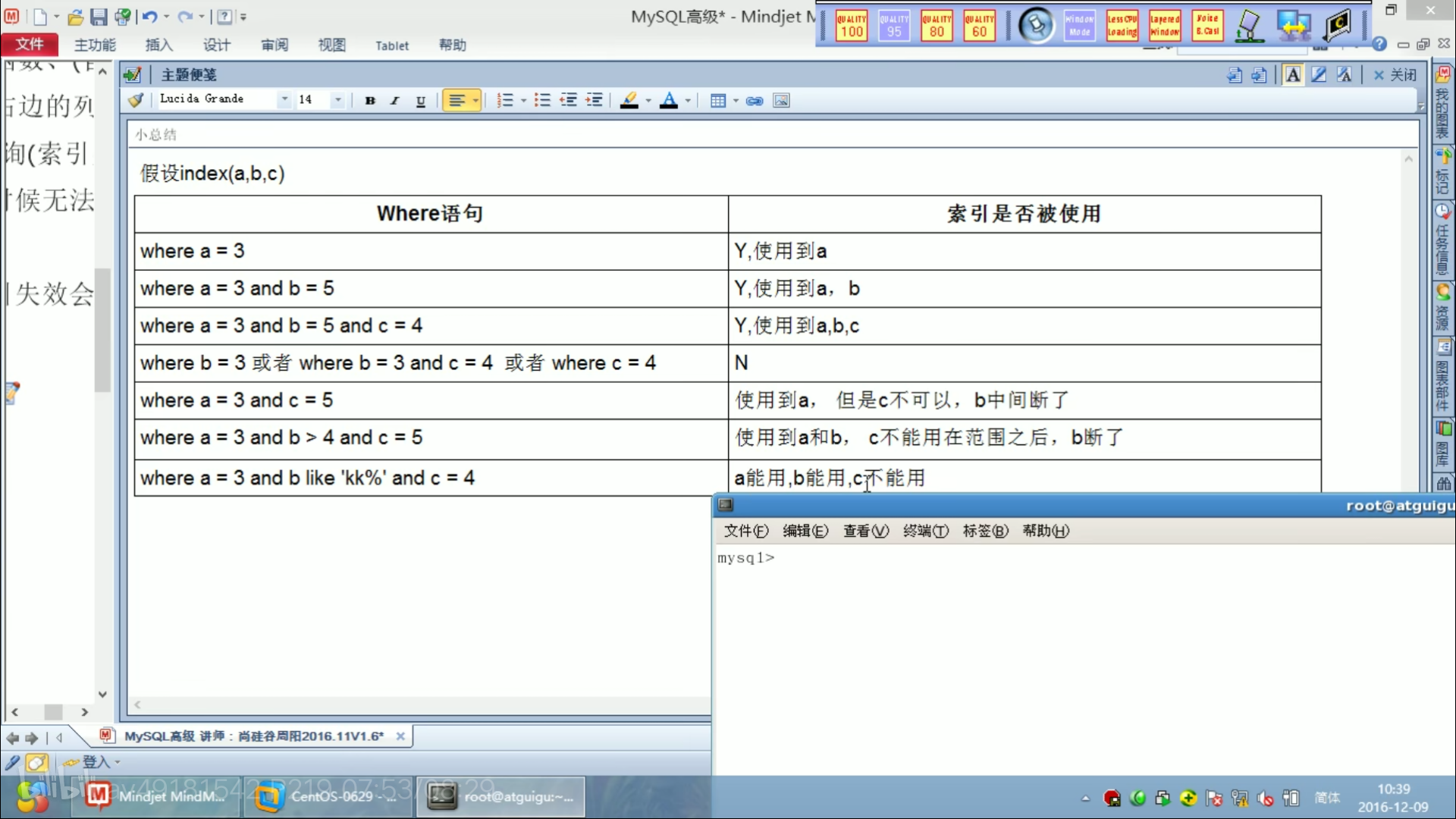
索引的最左前缀原则
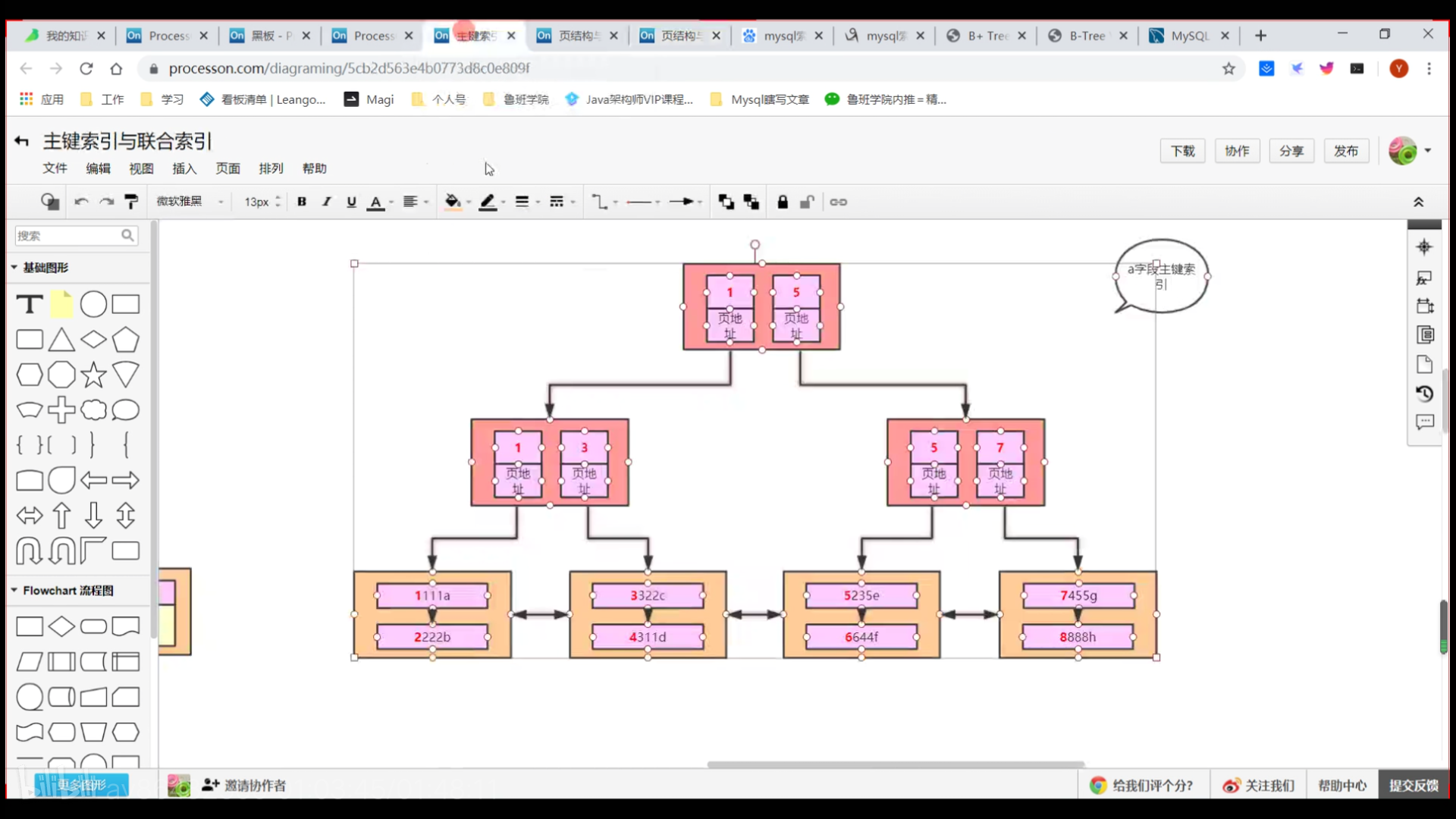
因为bcd三个字段不是主键,有可能重复,所以B+树索引的非叶子节点除了bcd字段还保存着主键。
null值是最小的
innodb(聚集)
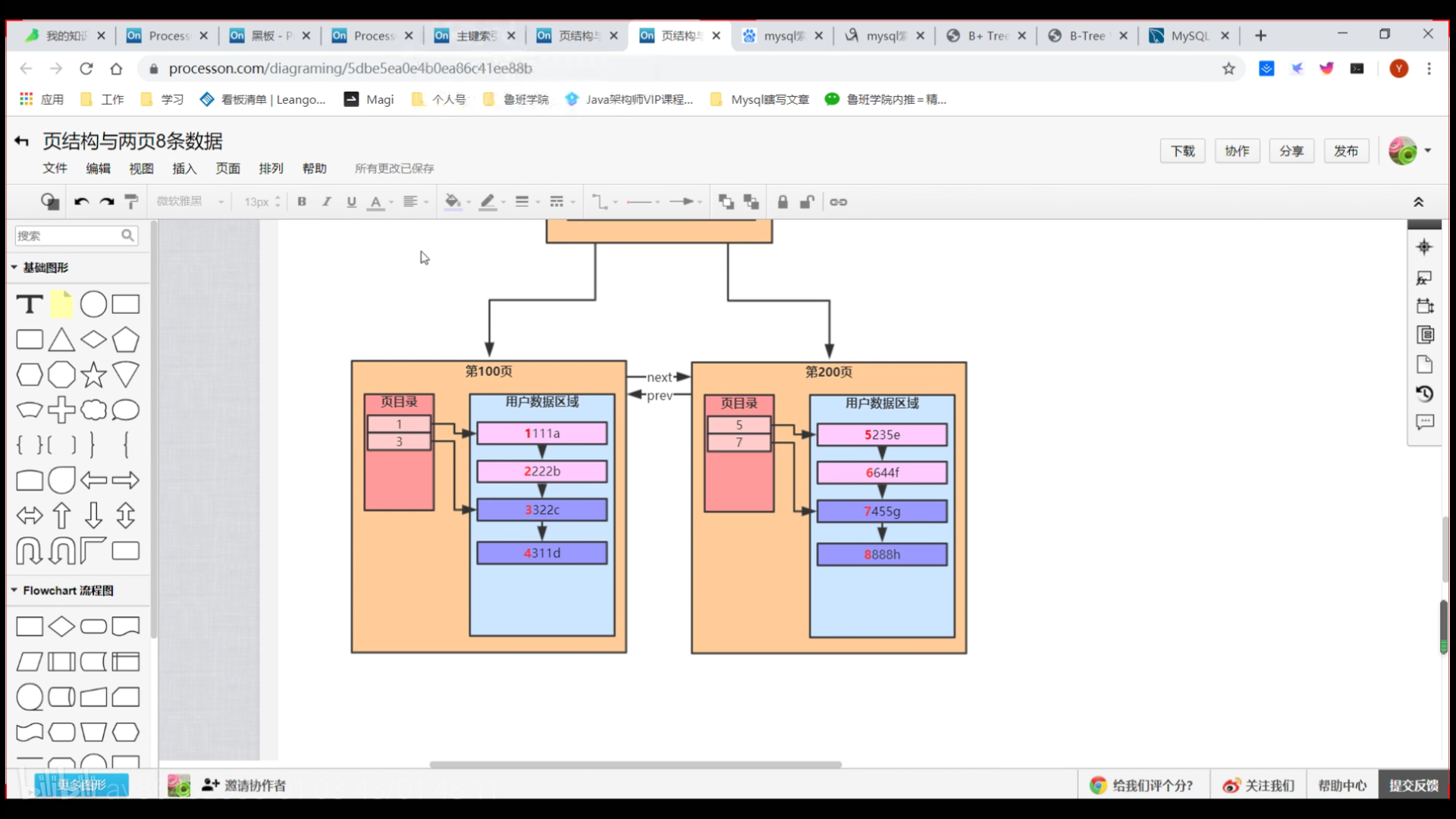
下图是数据页格式和innodb行格式,dynamic是默认格式
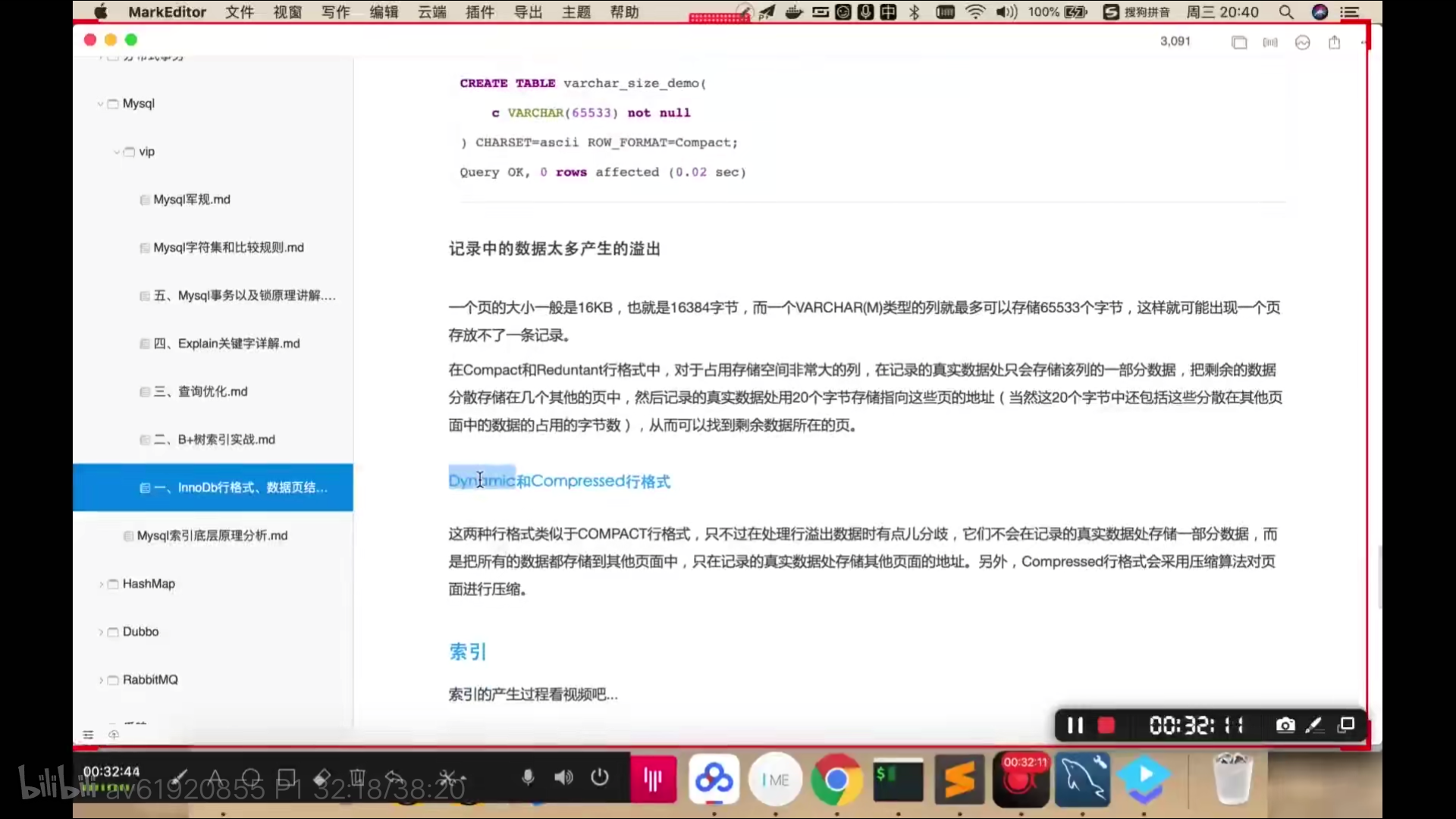
下图是聚集索引:叶子结点包含了所有的数据记录
- .frm 表结构
- .ibd 数据+索引
为什么innodb必须要有主键,并且推荐主键时整型且是自增的?
答:innodb要有主键索引,并且innodb底层是B+树,非叶子节点存储的是主键,在查找时要比较主键大小,整型比字符串效率高。自增可以避免叶子结点作分裂以及自动平衡。
为什么非主键索引的叶子结点存储的是主键值?
答:一致性和节省存储空间。
myisam(非聚集)
堆表:查询时和插入顺序一样
表的引擎设为myisam时,会生成三个文件,
- .frm 表结构
- .MYD 存数据的
- .MYI 存索引的
事务
四种隔离机制:
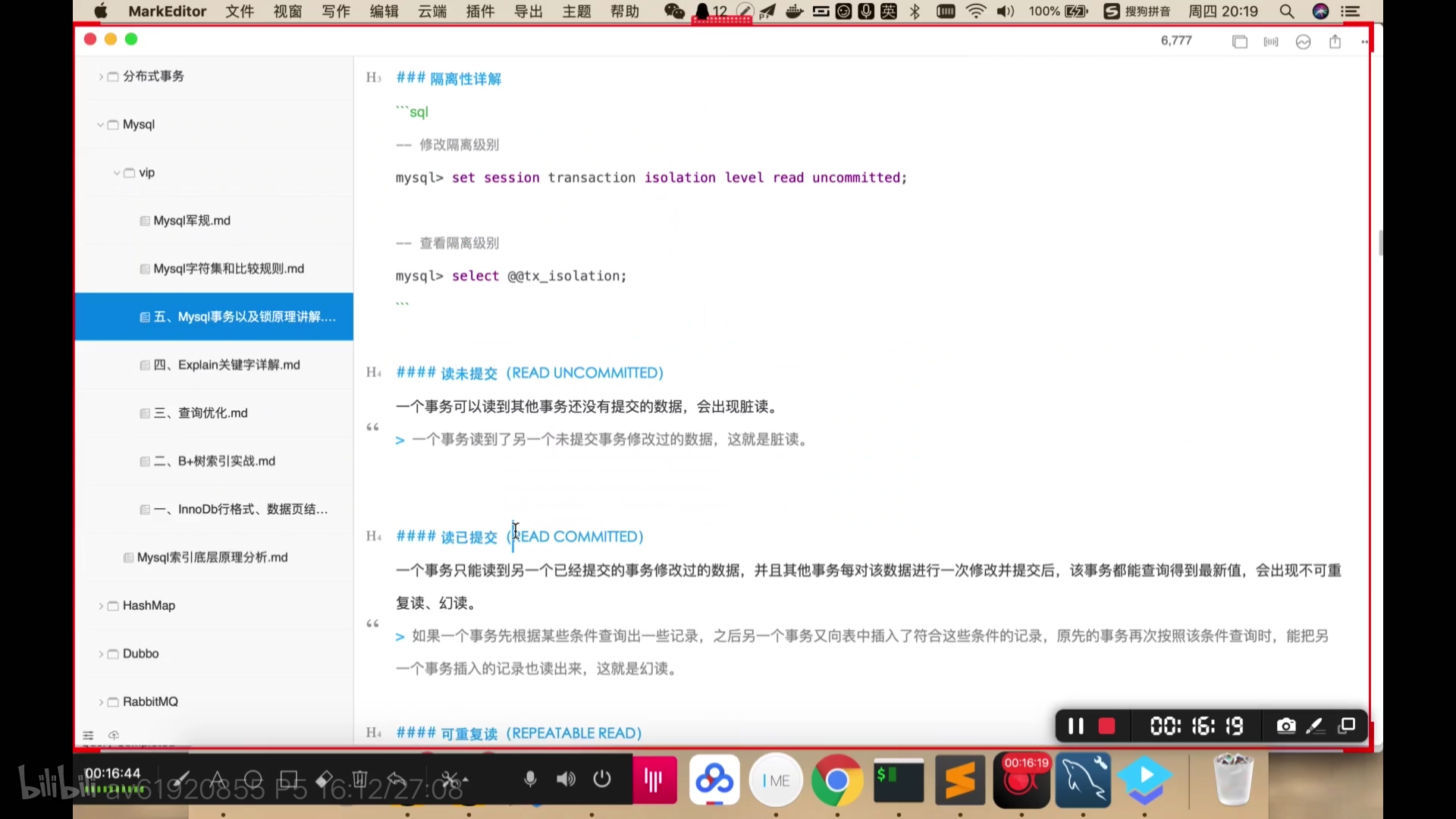
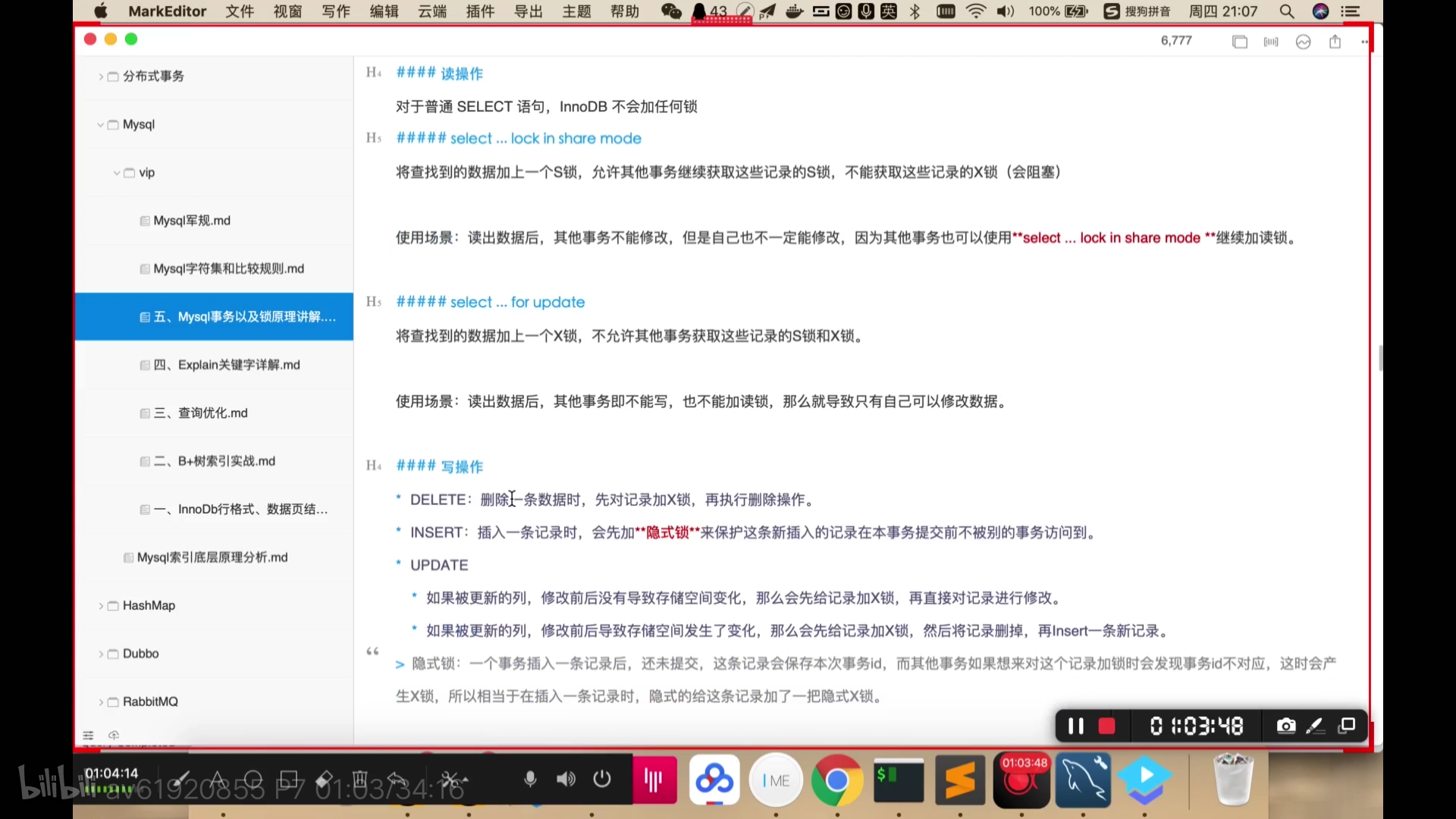
读未提交:A B开启事务,A修改字段还没有commit,B就可以查看到。这是脏读。
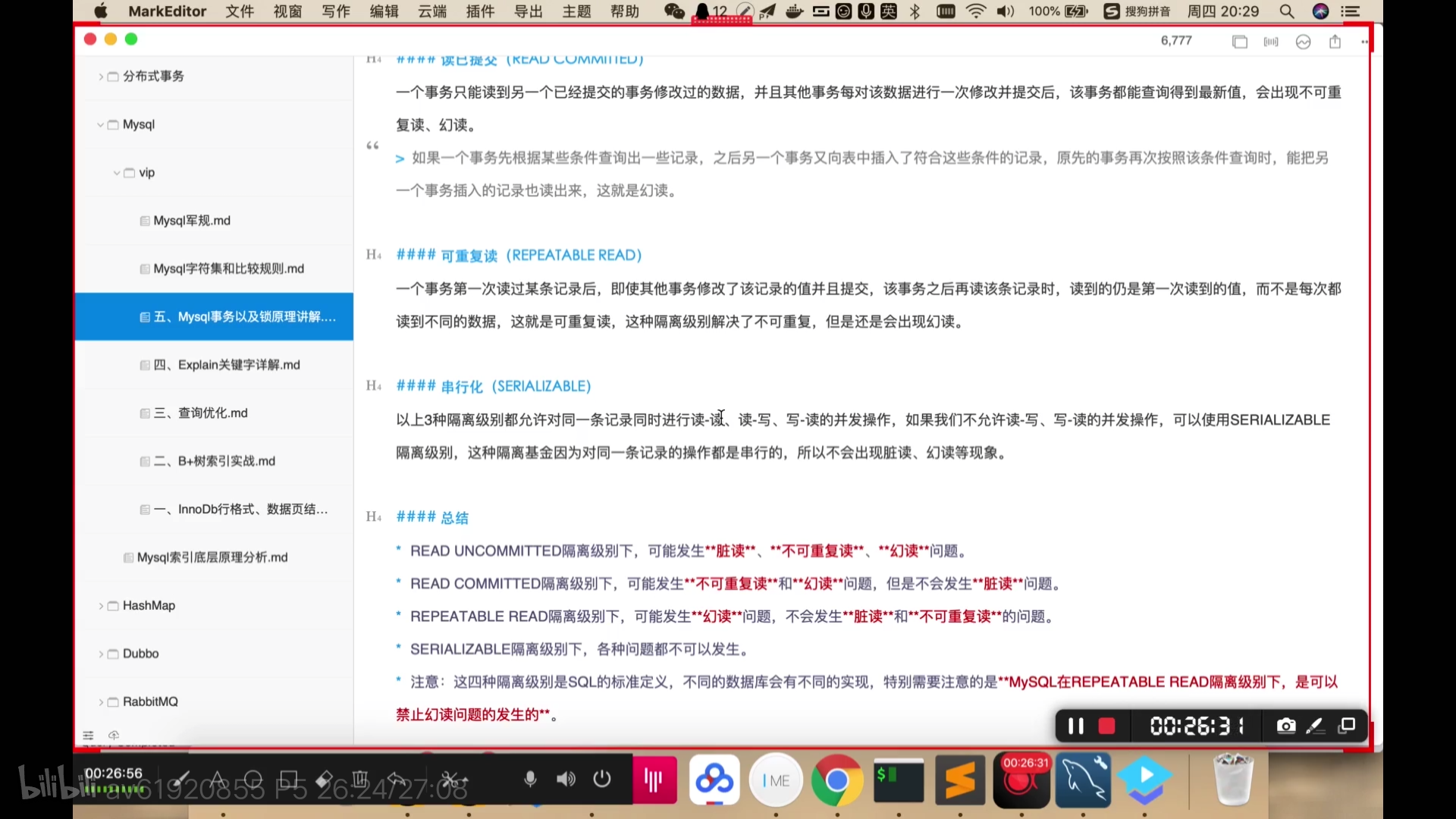
读已提交:A B开启事务,A修改字段,commit之后,B才可以查看到。这是不可重复读。A添加字段,commit之后,B才显示多了一条数据。这是幻读。
不可重复读:A B开启事务,A修改字段,commit之后,B也commit之后才可以查看到。 读的不会发生幻读了(因为有MVCC机制),MySQL已经对其进行了优化。
MVVC机制
版本链和readview

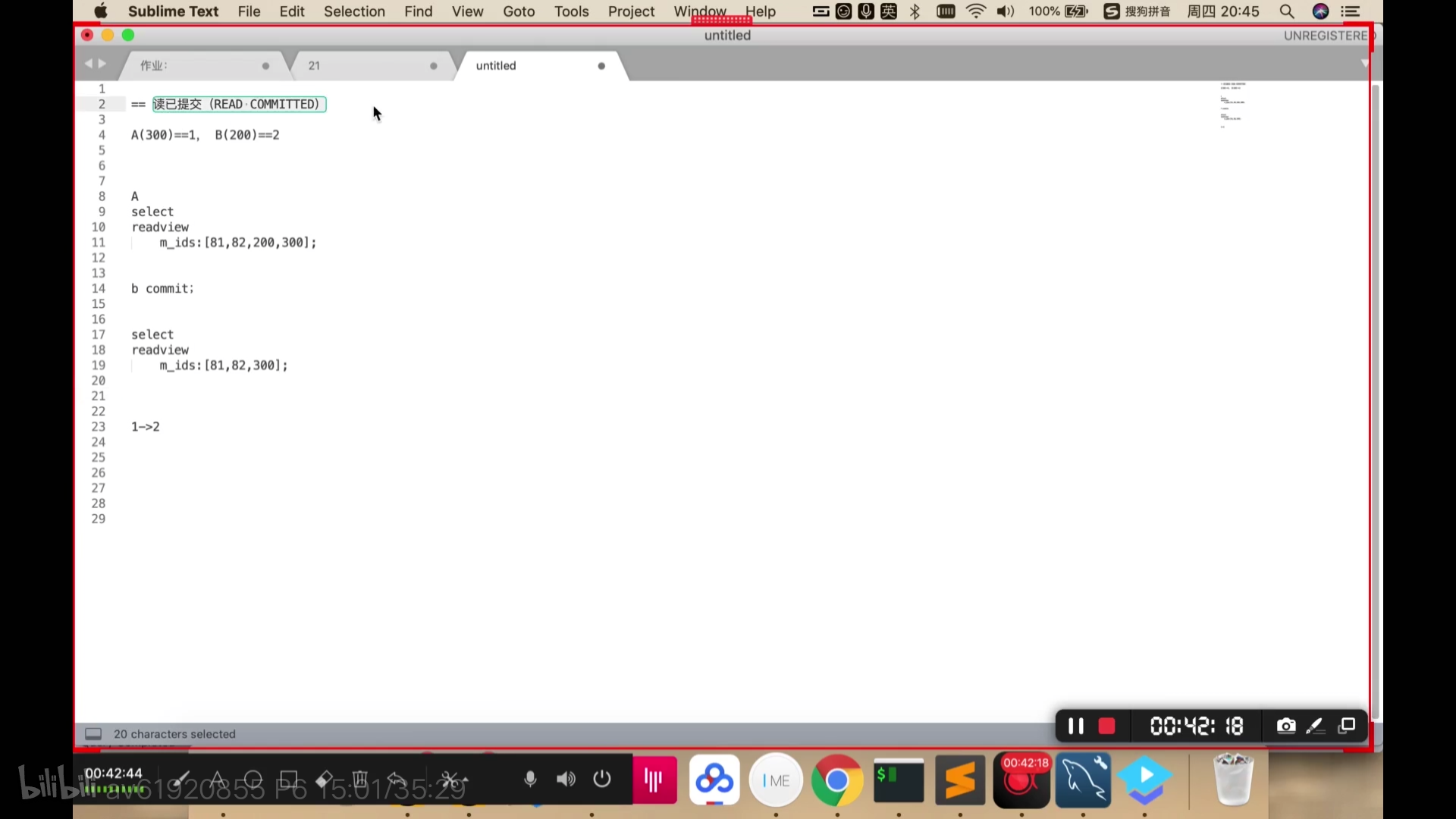
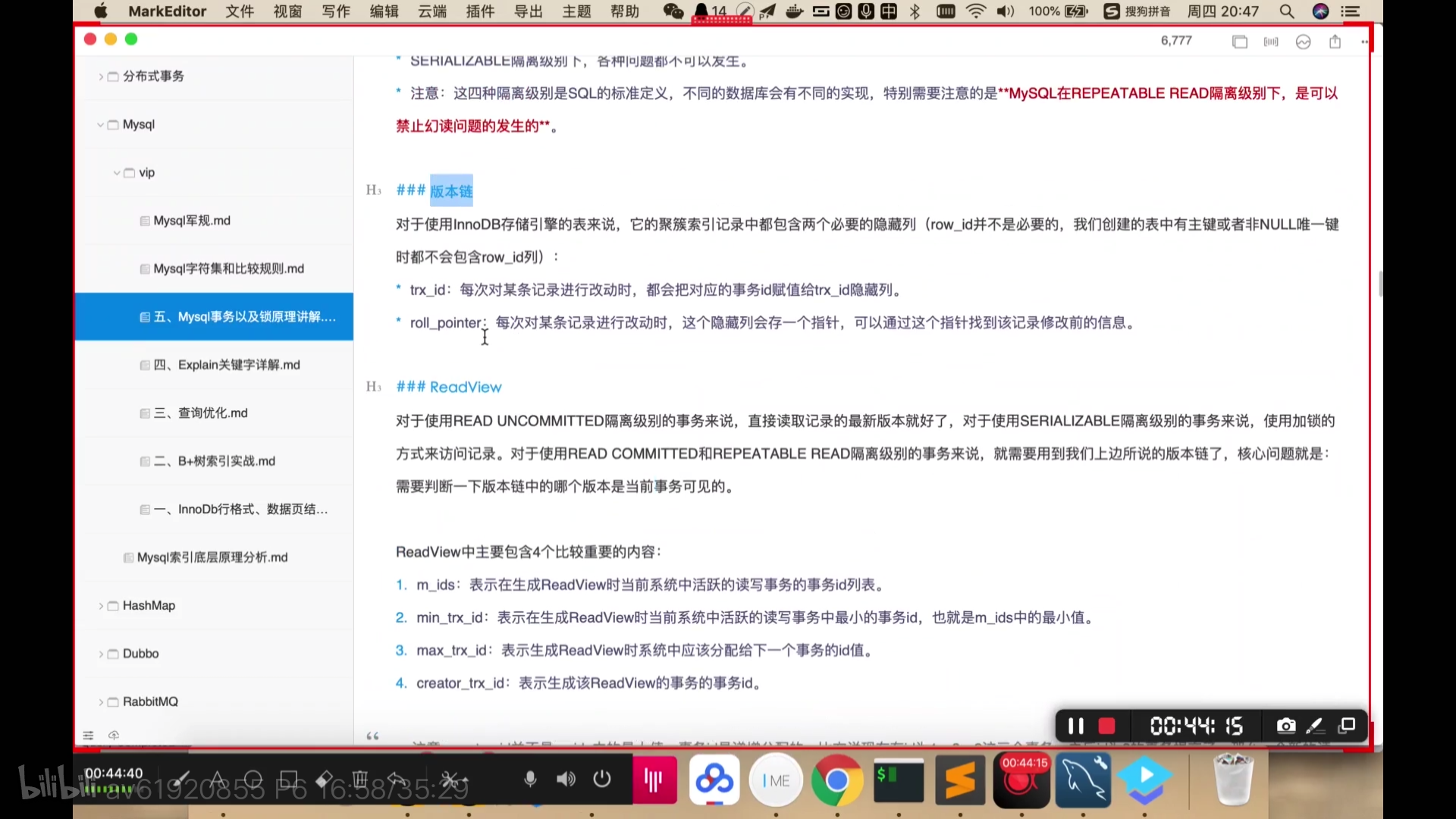
readview中有m_ids,当中保存的是活跃的事务id, 别的事务会读取最新的已提交的数据。读已提交和不可重复读的区别见下图。
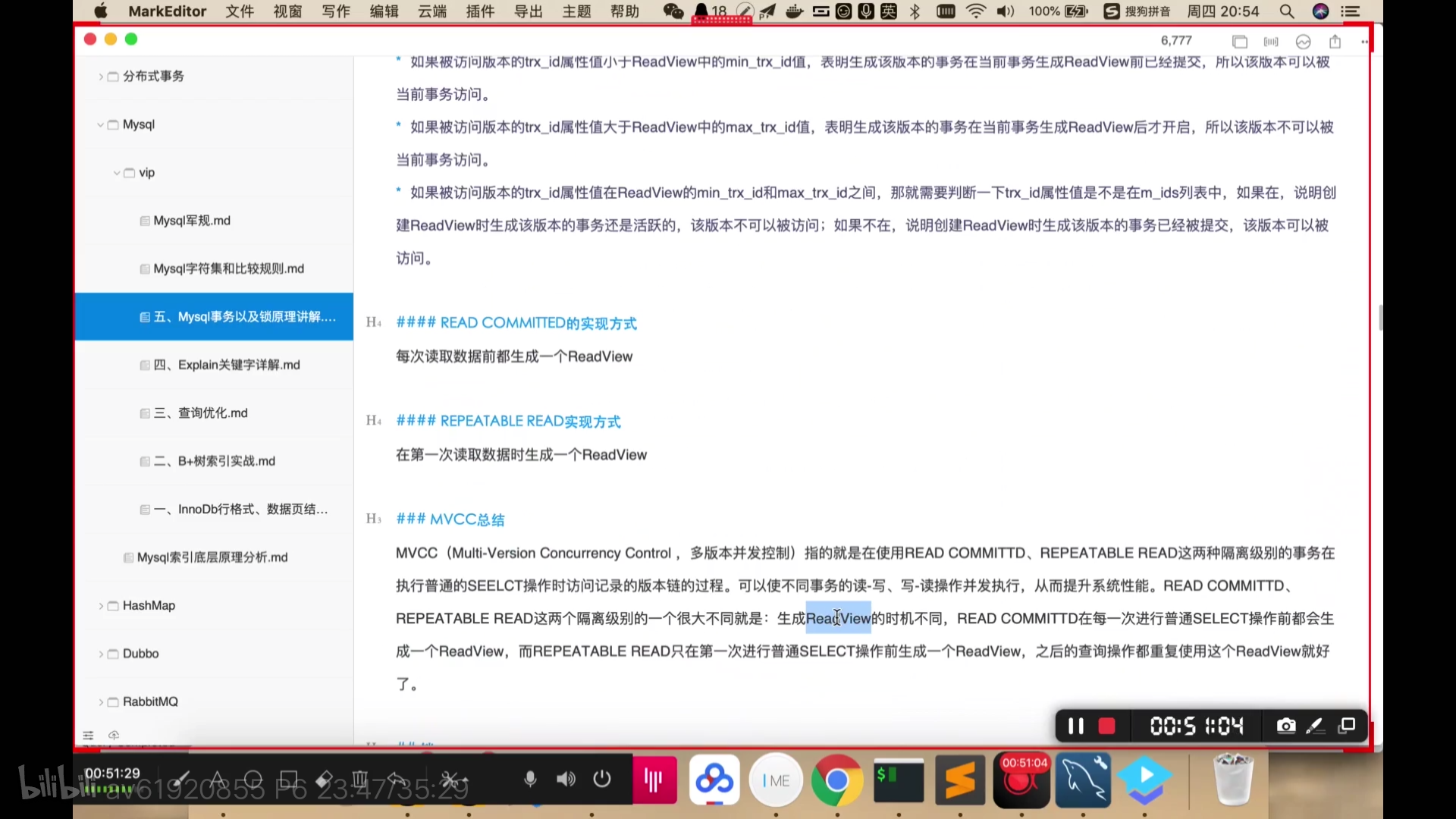
MVCC机制(下图重要)
锁机制
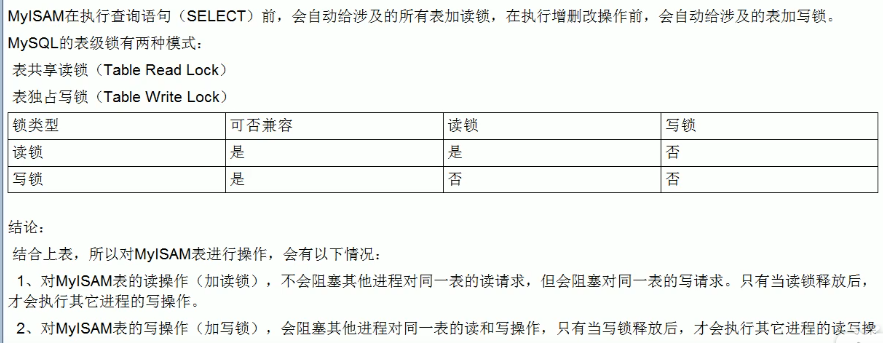
表锁(Myisam):

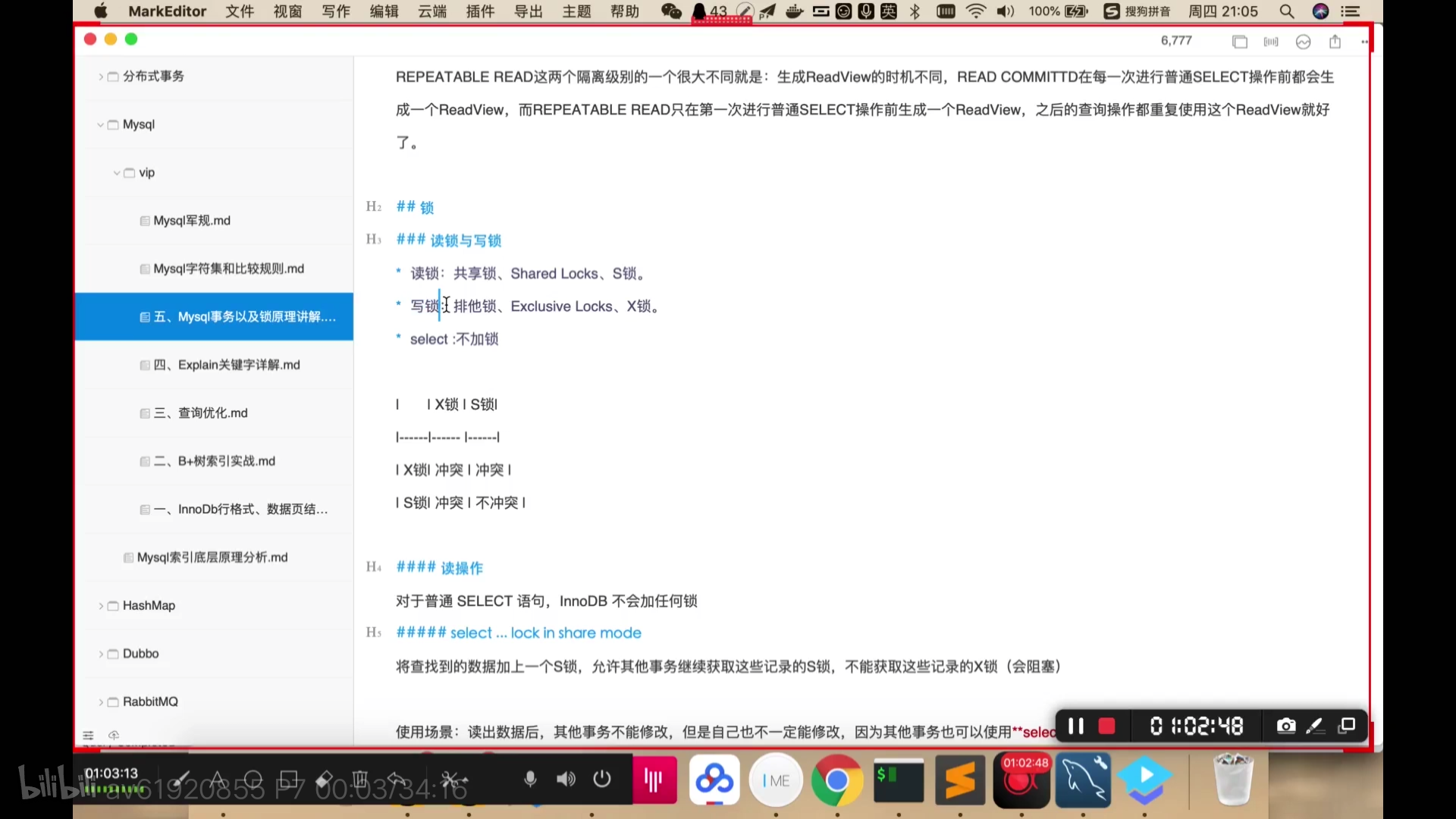
总结:
- 偏向MyISAM存储引擎,开销小,加锁快,无死锁,锁定粒度大,发生锁冲突的概率最高,并发最低。
- 偏向InnoDB存储引擎,开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
表锁(innodb):
在读已提交隔离级别下
事务提交之后,锁就释放。
查询时使用的是主键或者唯一索引,只会锁那一行数据。
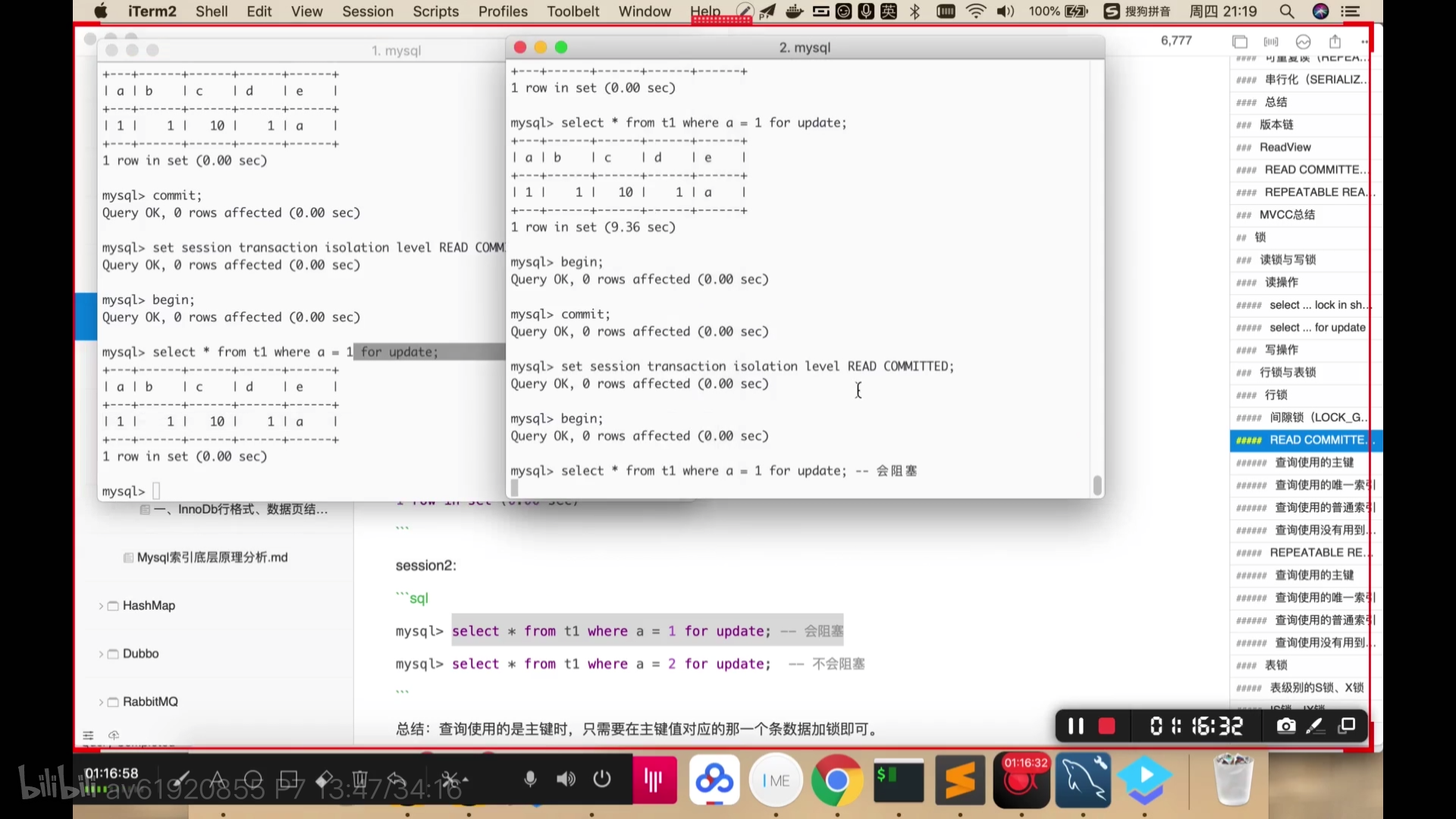
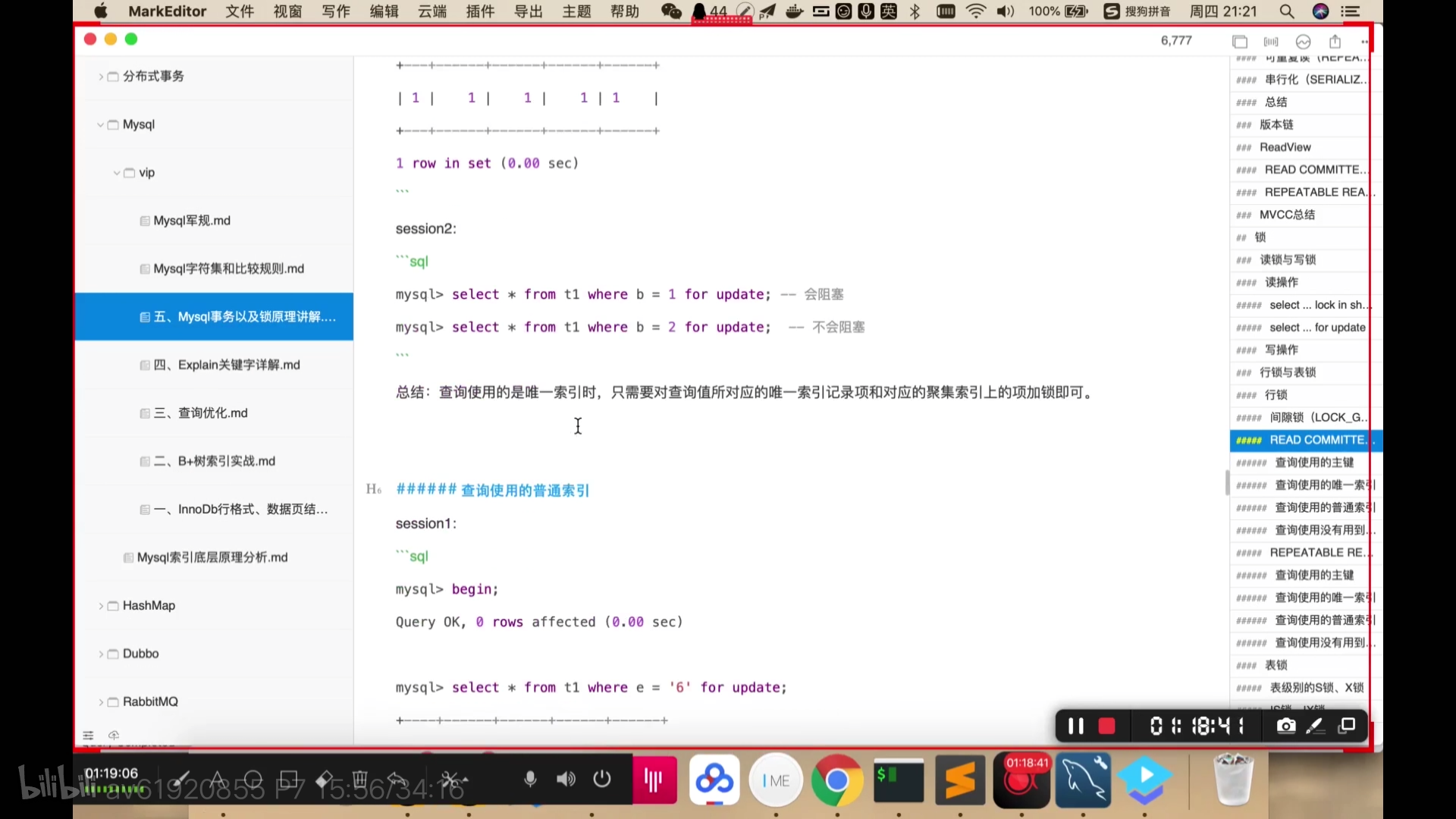
查询时使用普通索引,会对查询出来的所有行加锁,其他行没加锁。
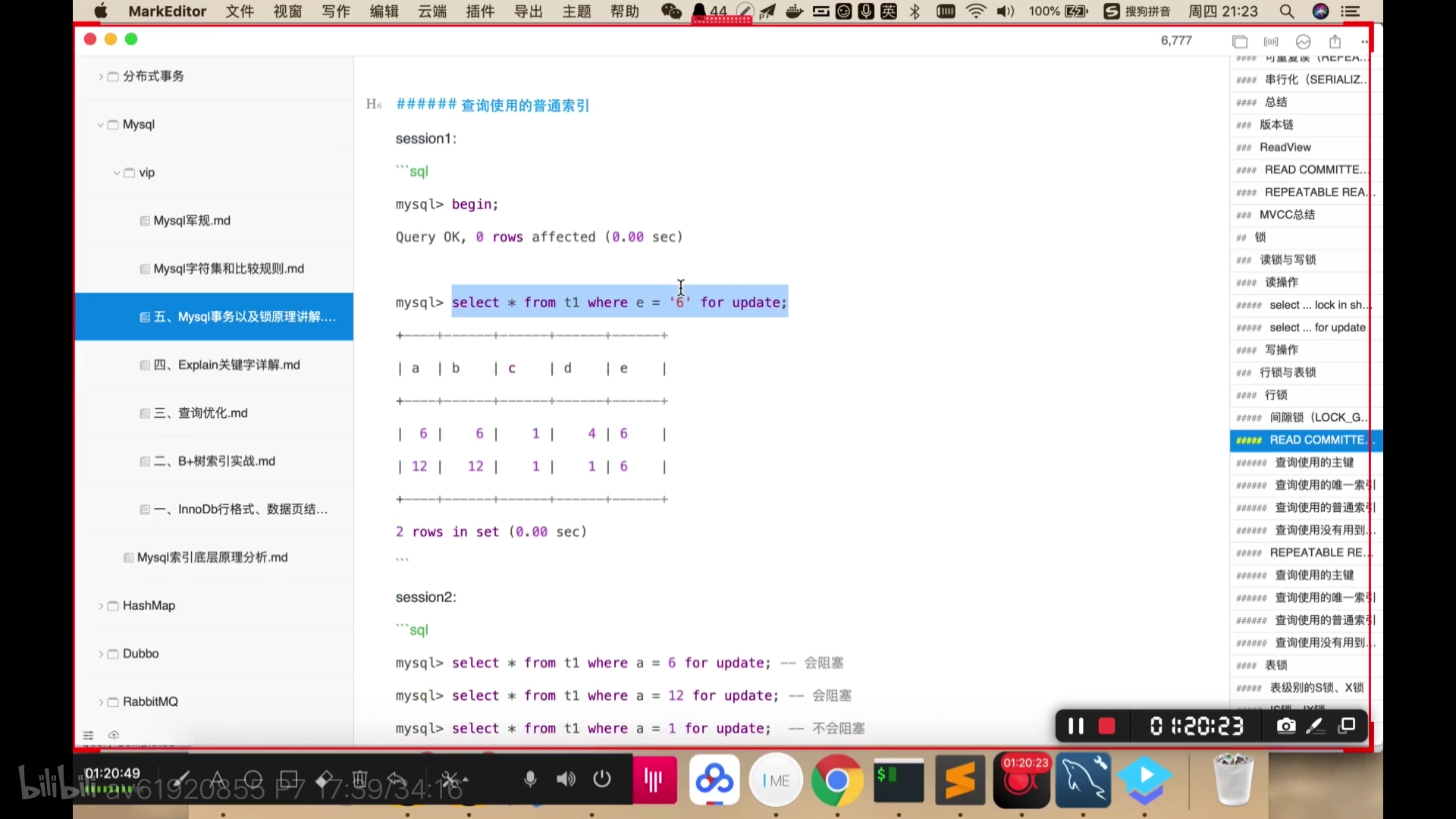
查询时没有使用索引,也会对查询出来的所有行加锁,其他行没加锁。 再添加数据不会阻塞
在可重复读隔离级别,下会加入间隙锁
在普通索引下,例如e字段的索引,如果已经对e=2的记录加了锁,则也会对其间隙也加上锁。新插入间隙上的记录会阻塞,不在间隙上不阻塞;若e>2,则对大于2的全部加锁了。, 这是避免了幻读。
查询时,该字段没有使用索引(也就是全表扫描),也会对查询出来的所有行加锁,其他行 包括间隙 也都加了锁。 再添加数据会阻塞,也避免了幻读。
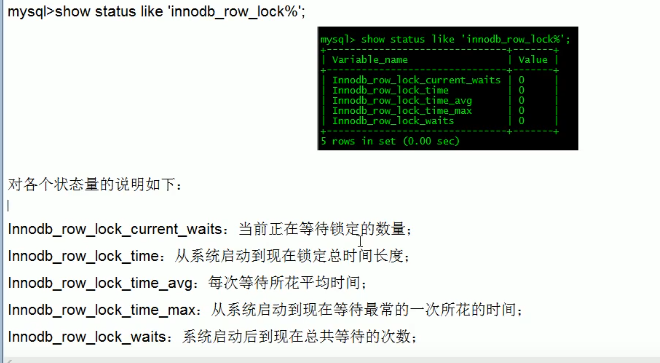
分析系统中的行锁争夺情况
varchar类型字段不加单引号‘’会强制类型转换,从而会是行锁升级为表锁。---这是真的?
索引优化
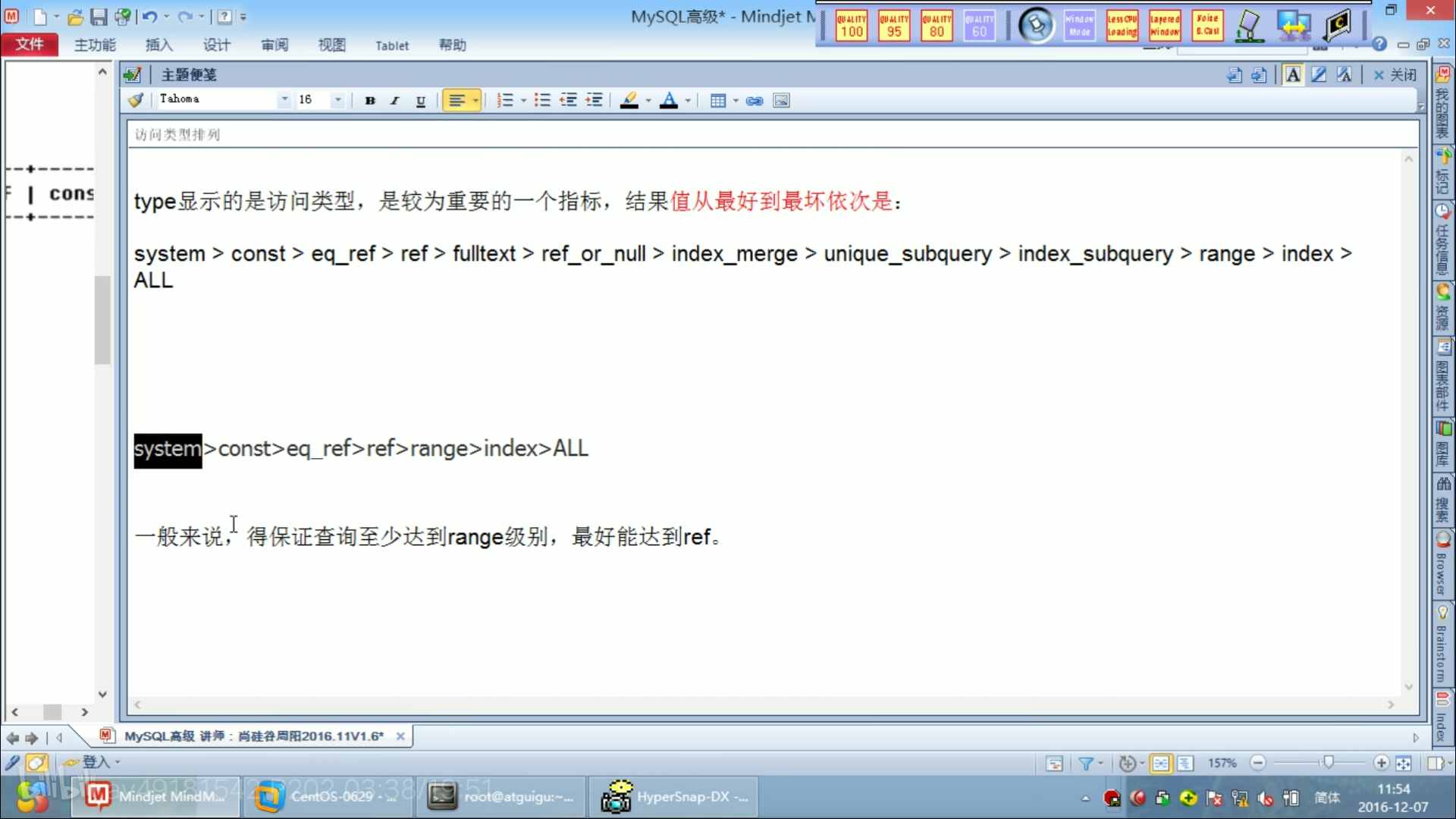
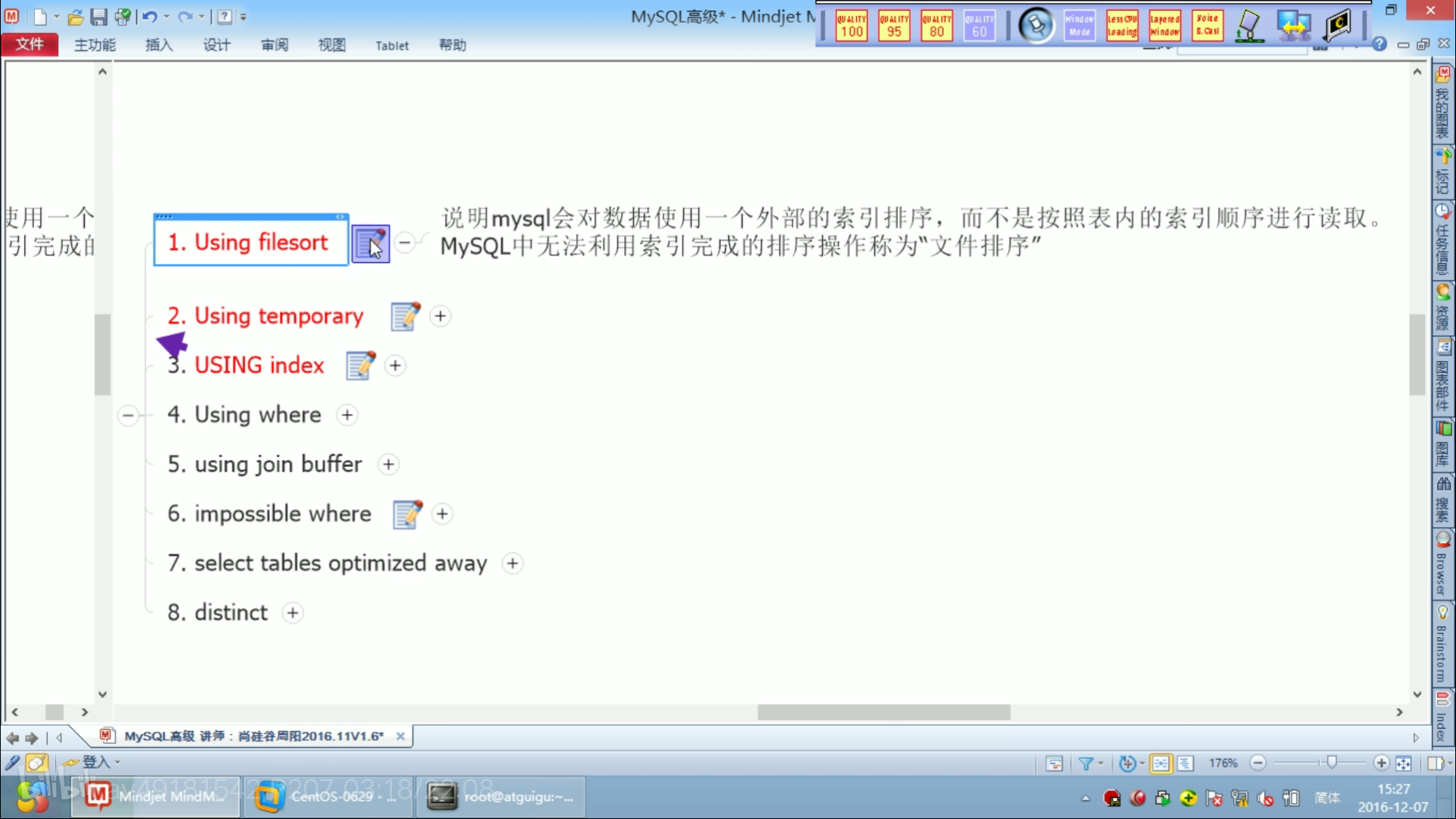
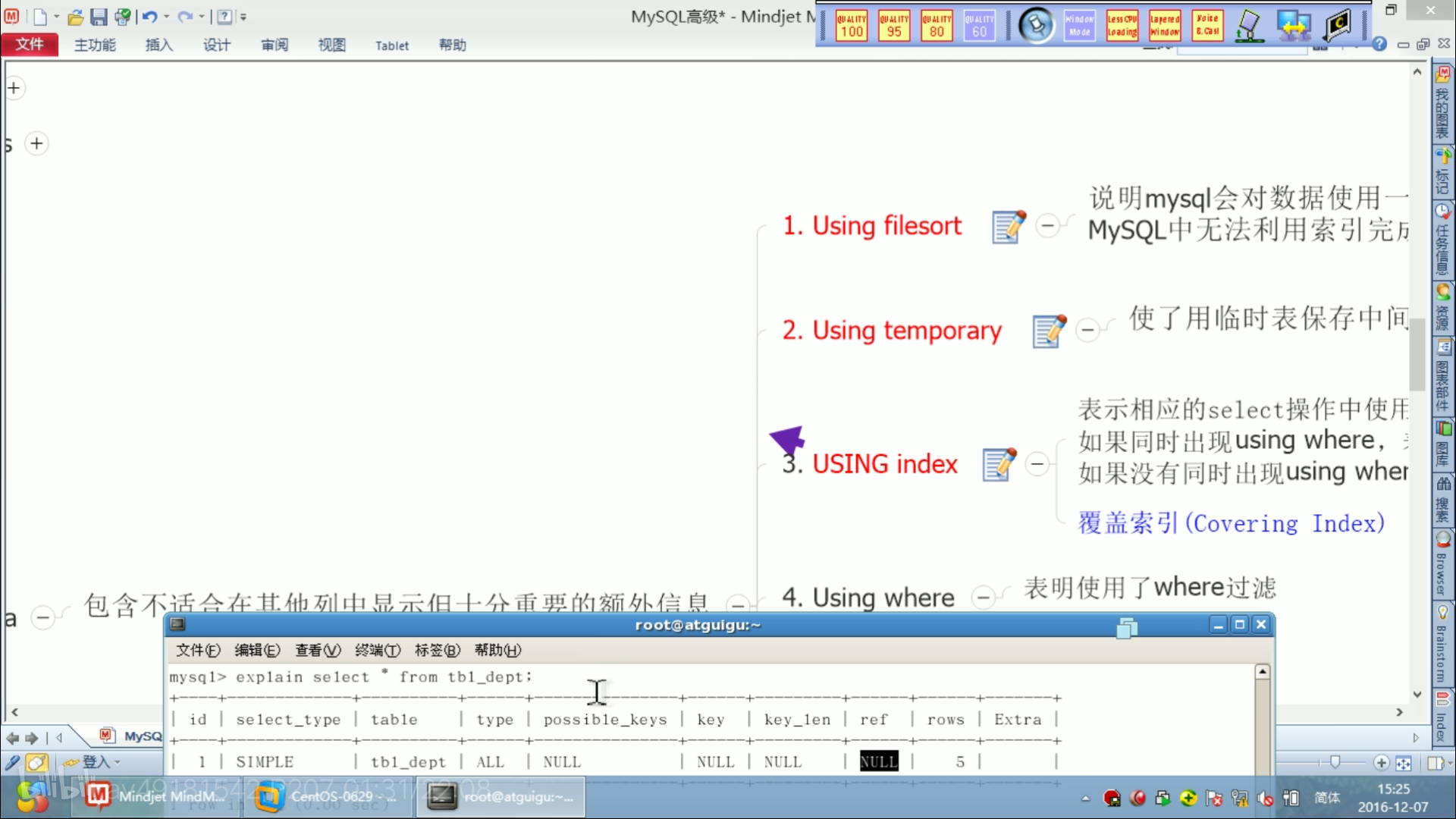
extra中的using filesort和using temporary是最不好的。
using index 好!
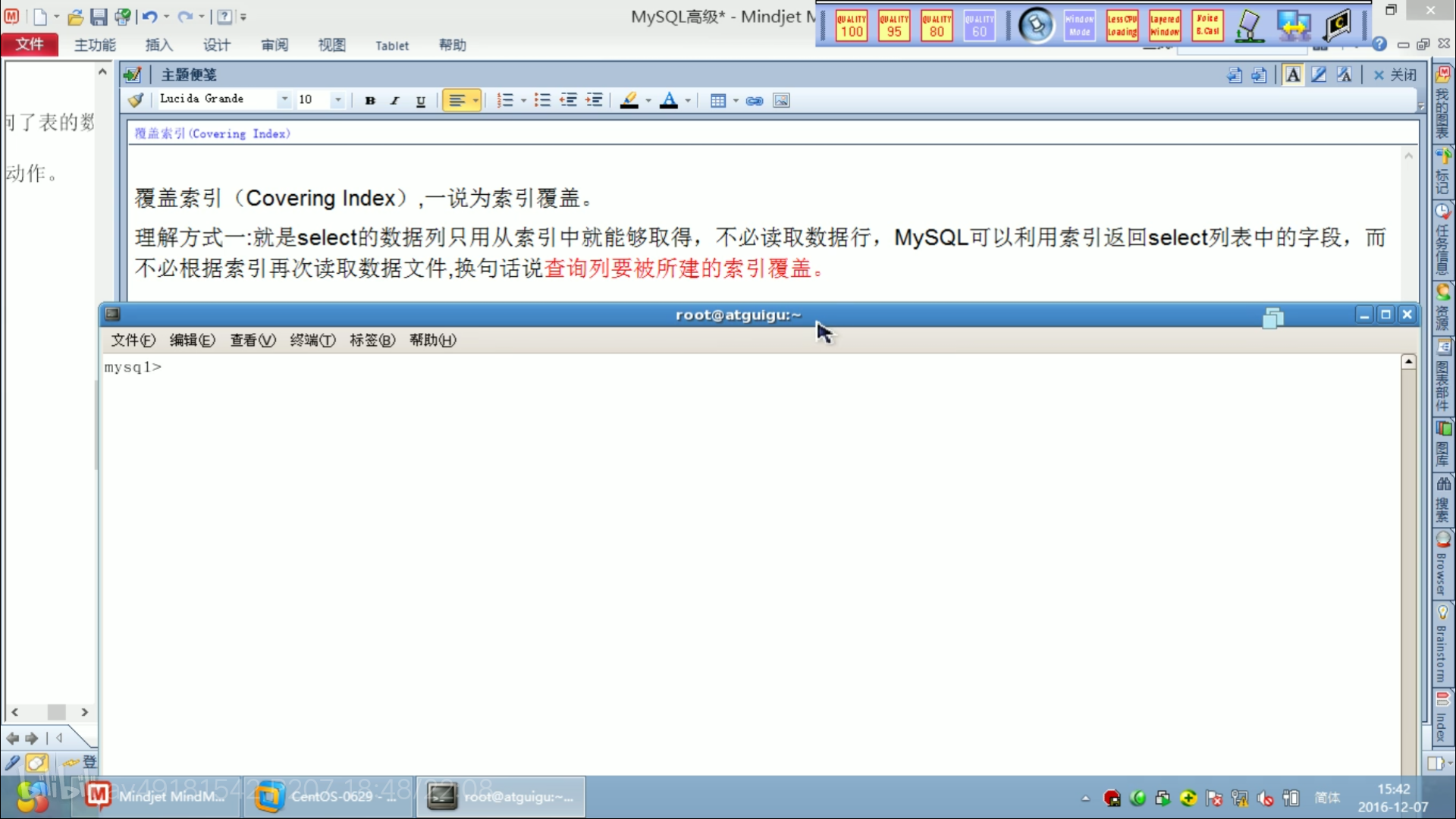
覆盖索引:
优化
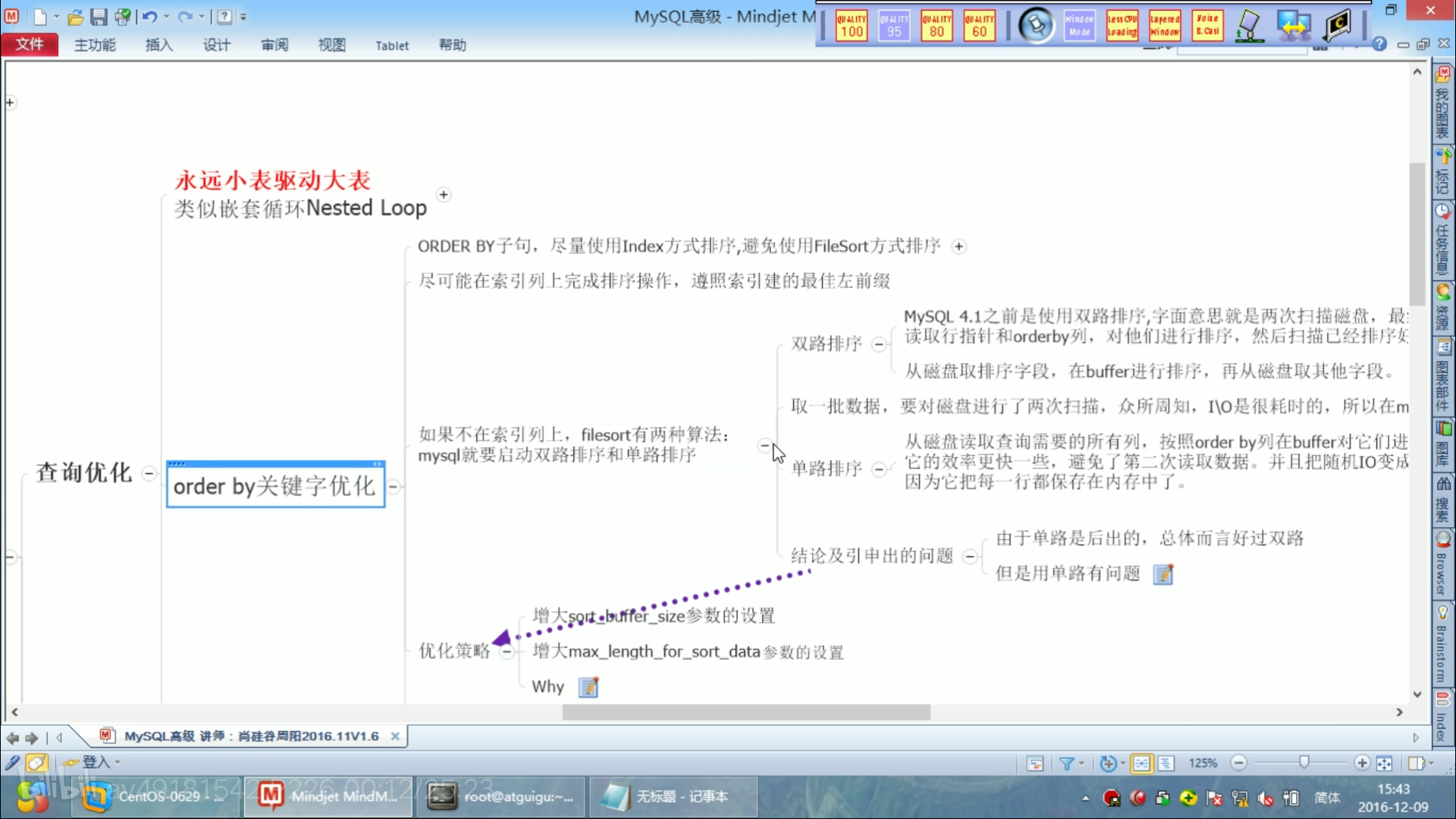
**单表**:范围查询时,where a>1 后面的条件用不到索引。详情见最左前缀原则。
**两表** :使用join,是 left join 则在右表相应字段建立索引。是 right join 则在左表相应字段建立索引。
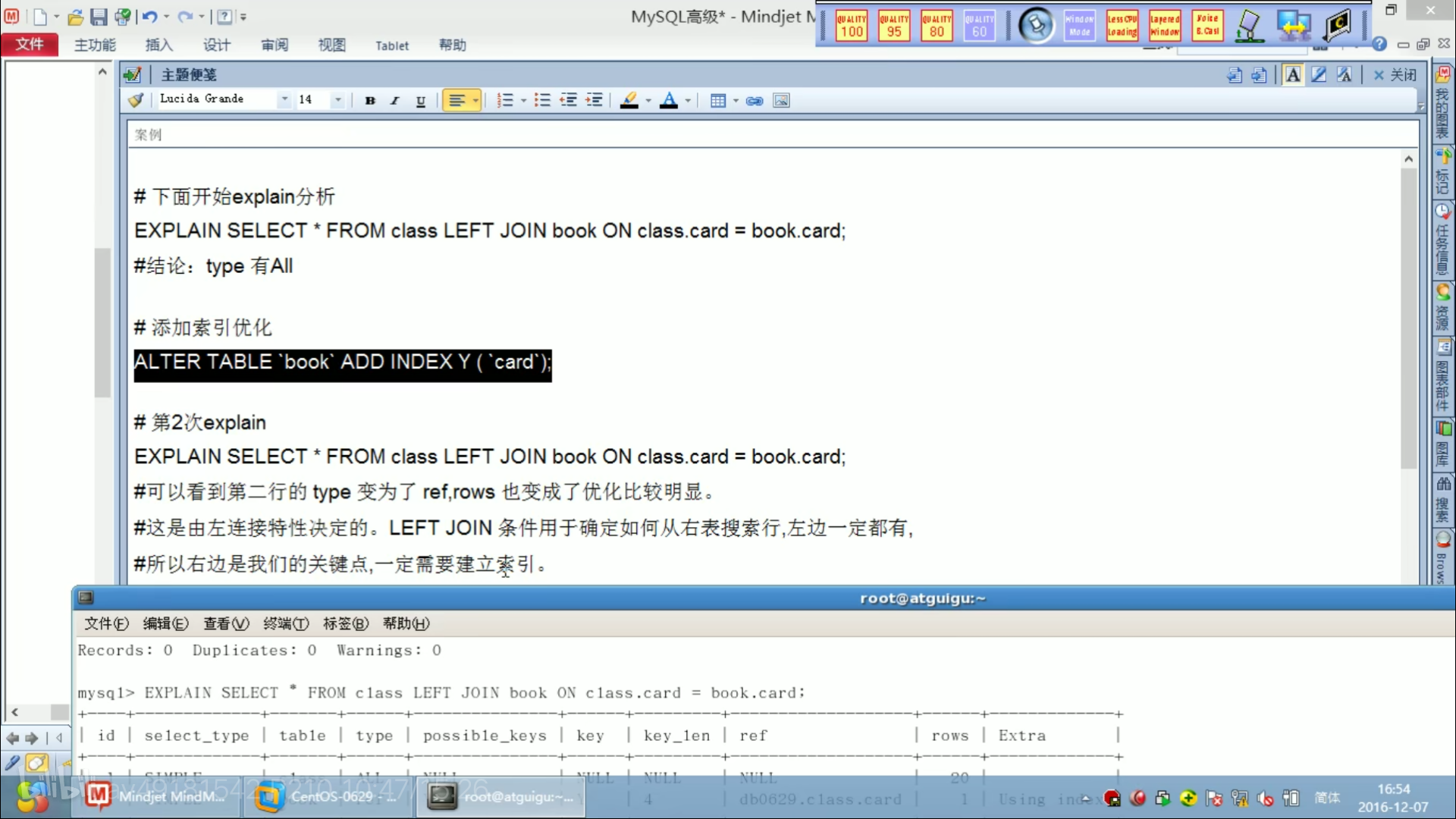
三表 :记住:永远用小表驱动大表。

索引失效的情况
第8条:like要是必须得有%,则必须使用覆盖索引。即select字段必须存在索引。
查询优化
小表驱动大表
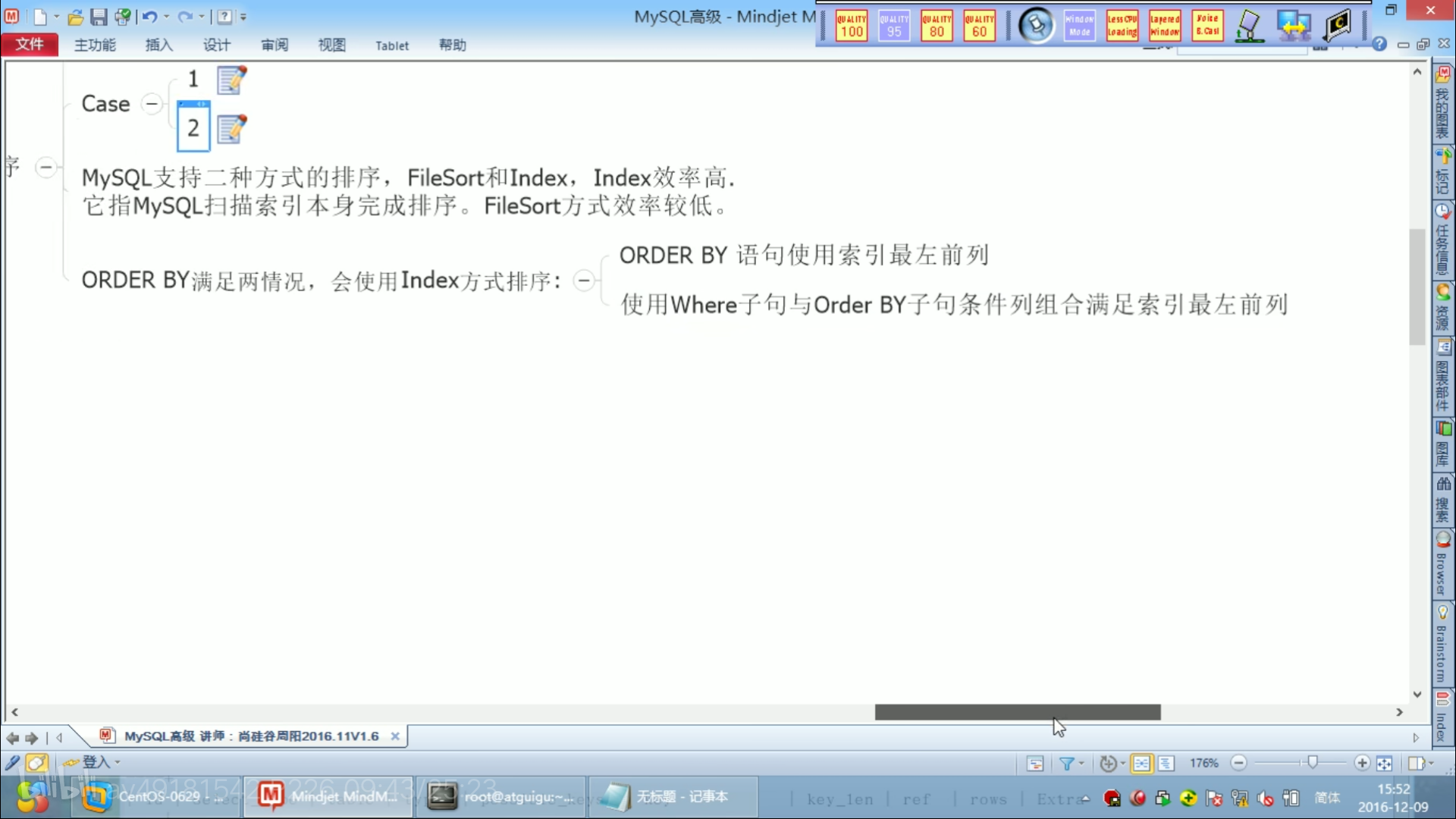
order by排序优化
使用最左前缀原则
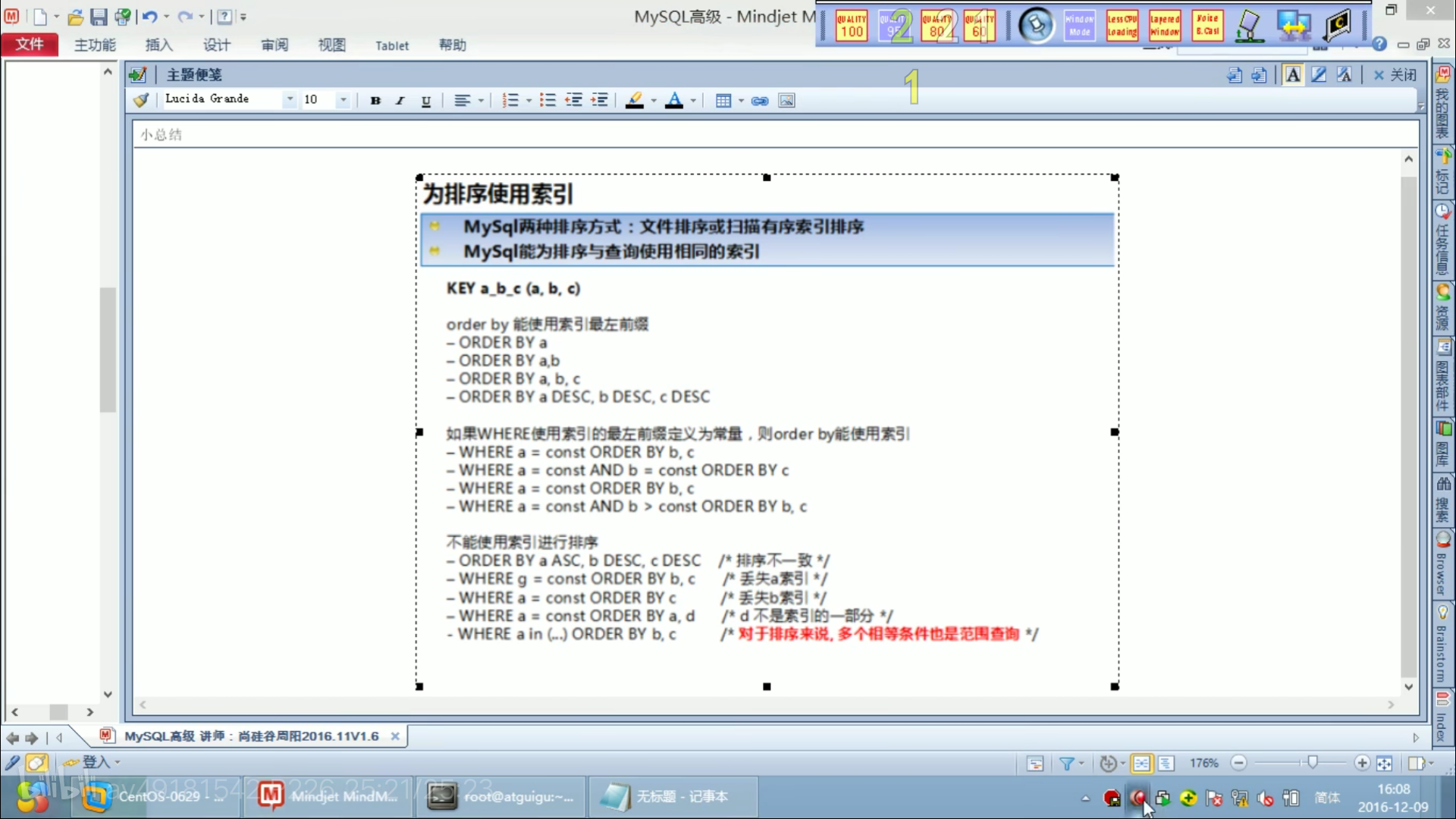
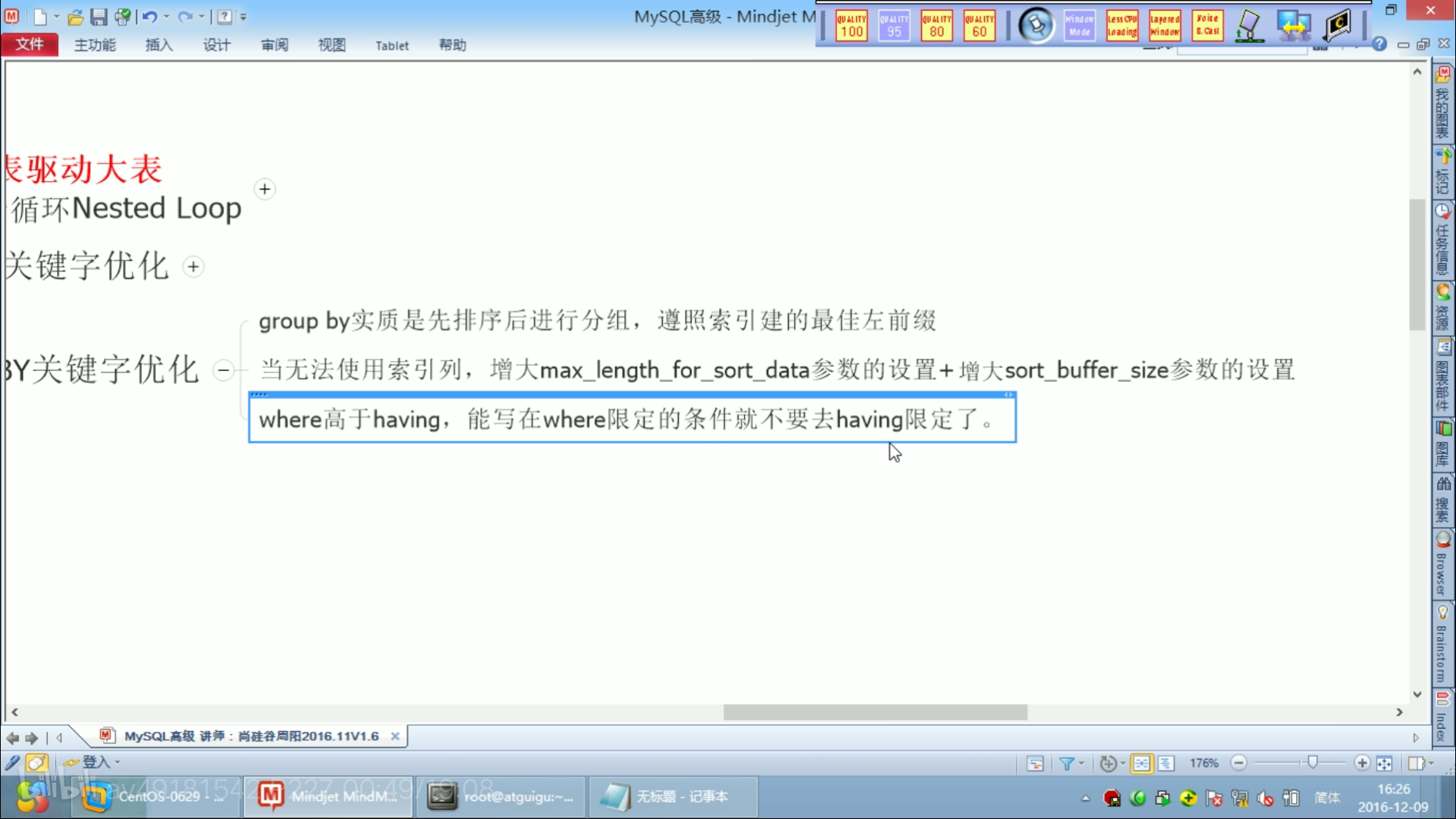
group by 查询优化
和order by一样
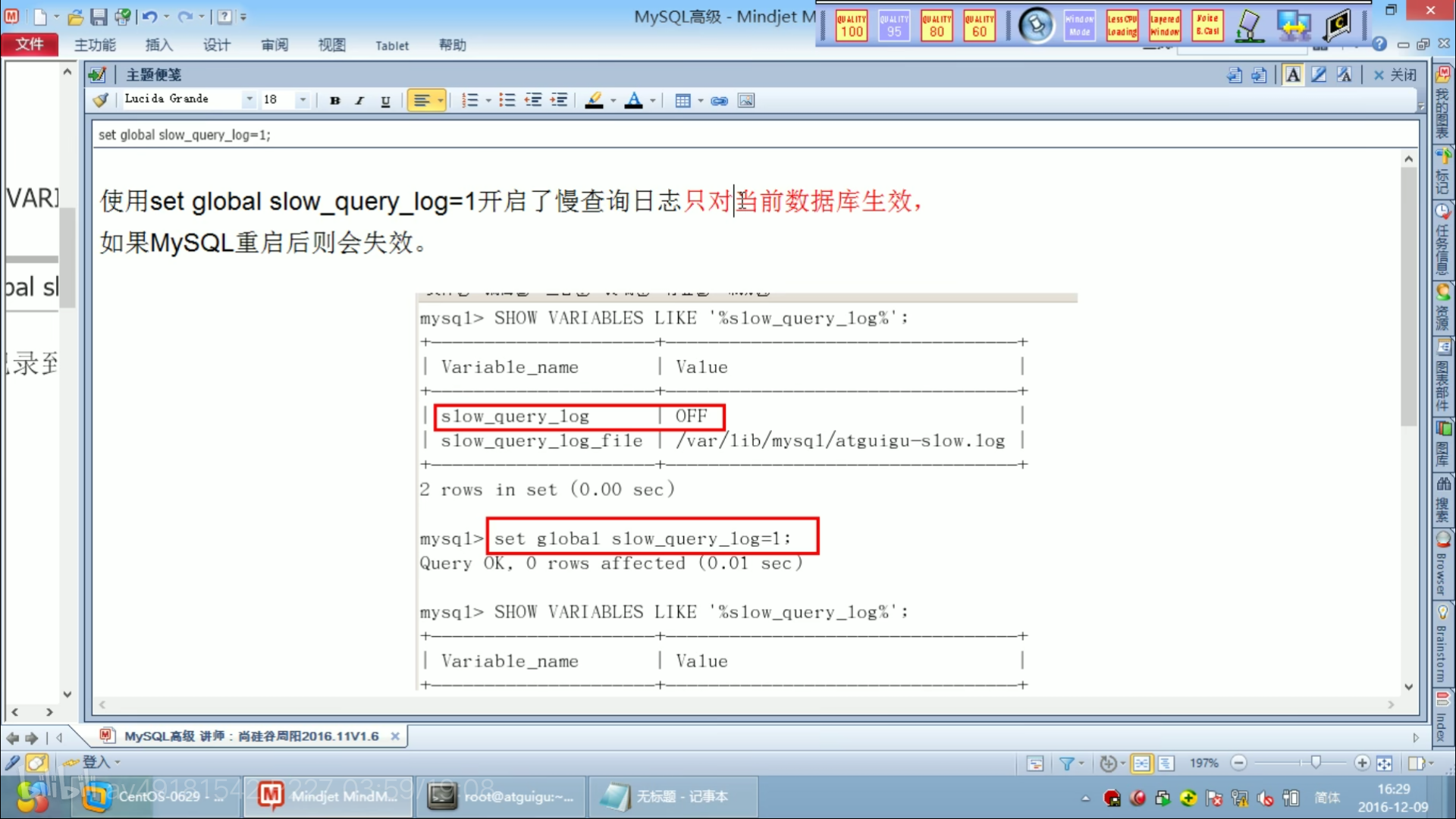
慢查询日志
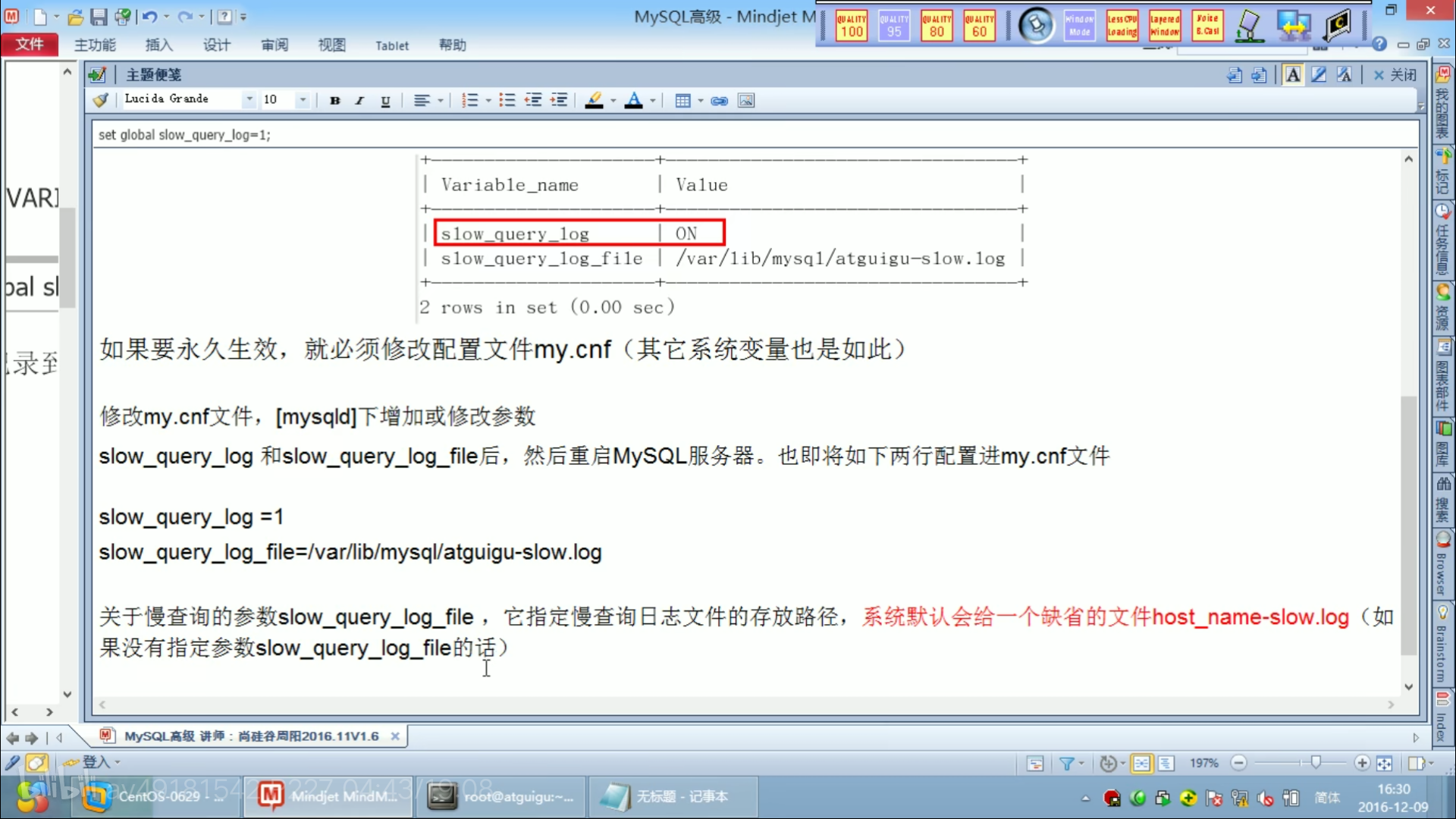
批量插入数据
主从复制
修改my.ini文件


一主一从常见配置
停止从服务复制功能:`stop slave;`
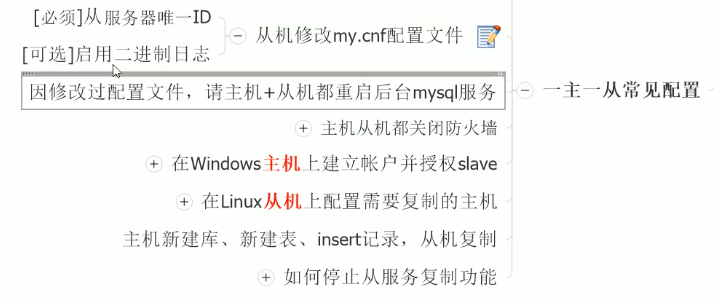
- 主机建立账户并授权slave

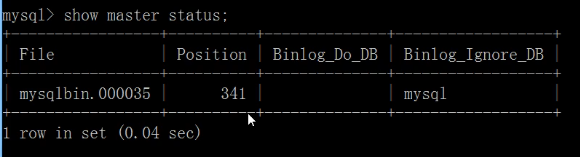
- 从机配置需要复制的主机


 浙公网安备 33010602011771号
浙公网安备 33010602011771号