

使用Jmeter聚合报告生成对比图表
背景
最近在帮别的项目组执行性能测试,使用的工具是Jmeter。接口录制和参数化前一个人已经做好了,我主要的工作就是执行脚本,撰写测试报告。事情并不复杂,可做起来却极为耗时。
首先,由于有6组账号,分别对应6个不同的BU,而每个BU又需要执行1、10、20、30四种压力模式。如果使用GUI模式跑,就需要执行24次,还需要每次自己改参数,实在是费心费力。
其次,使用Jmeter插件生成聚合结果后,要根据结果出一份报告,。在我之前做的同事,由于是第一轮测试,也就无从比较,只是从接口、页面、错误率三个维度写了一份报告。而我则需要根据本次和上次的结果,生成图表,以便直观地展示结果。刚开始做这件事时,我是根据需求,找到对应的接口和页面,分别挪到Excel里,利用Excel生成图表。可是既容易错,还容易瞎,实在是折磨人。
解决方案
1
为了解决第一个问题,我的思路是找到Jmeter测试脚本的配置文件,复制多份,批量改成不同的配置,再利用bat脚本每次执行多个。
先将原来的测试脚本Jmx文件复制多份,按环境分成不同的文件夹,再按线程数整理进去,如下图:

因为Jmx文件其实都是xml格式,里面存储了脚本的配置,于是就使用VS Code打开文件夹,进行批量替换,这样很快就能完成配置工作。


之后再写bat脚本,以命令行模式执行jmx脚本,并生成测试报告。
注意在批处理文件中执行多条命令时,如果期望上一条执行完毕再继续执行下一条(也就是顺序调用),需要使用call方法。大致如下:
call %userprofile%\Desktop\apache-jmeter-3.3\bin\jmeter.bat -n -t 'CP BU.jmx' -l test_report.csv -e -o cp_test_report
call %userprofile%\Desktop\apache-jmeter-3.3\bin\jmeter.bat -n -t 'FA BU.jmx' -l test_report.csv -e -o fa_test_report
%userprofile%是系统变量,代表用户目录,形如C:\Users\xxx。这样调用可以提高复用性,之后用到的电脑只需要将jmeter放在桌面,即可运行。
-n non-gui 以非GUI模式运行
-t test-file 要执行的脚本文件
-l logfile 记录结果的文件,之后可以用来生成聚合报告
-o output html报告保存的路径
这样每次执行执行每种线程数的批处理文件,就可以自动执行并生成报表了。
其实还可以对生成报告的路径,再做参数化配置,按照一定规则整合在一起。而且还可以将多线程的bat文件,再一起执行,这样就更省事。这些都是可优化的地方
2
对比报告这部分就要麻烦些了。初步的思路是从新旧报告宏读取数据,再使用生成图表的库生成对比图。有了对比图,要说的话就会少很多了,毕竟一图胜千言嘛。
之前同事其实是直接从Jmeter中粘贴出来的报告,与脚本生成的html报告还有不一样的地方。况且,html文件不好读取数据,很难与excel中的数据对比。
最省脑子的方法自然是我按照原来的方式重新跑一遍,一一把数据粘贴出来,这样结果的格式就一样了,可是复用性太差,就不考虑了。之后想用笨方法,利用插件从打开的html报告中读出表格。试了一圈,Chrome的插件要么只能用于http开头的网页,要么就是不起作用。又试了下UI Path(RPA工具,最近跟过一些教程),提取是成功了,可是好像和页面上的行数不一致,大概是某些元素的没有被识别为表格元素。无奈之下,只能想想能不能利用现有的报告生成类似之前版本的报告。有查到用jemter命令将jtl(jmeter的测试结果)转换为聚合报告,可是脚本无法执行,说是缺插件,奈何jmeter上装插件总是失败,也没办法。只得自己在jemter界面上试试,在聚合报告插件中导入之前生成的csv文件。这下成功了,也稍微理解了这些报告的作用。这些插件其实就是将日志文件重新计算整理,展示出最关注的几点。
这样就保证数据格式一致了。接下来就是考虑读取数据了。我最先想到的是用pandas中的Dataframe格式存储数据。
写个读取的方法:
def read_reports_csv(folder): cp_df = pd.read_csv(os.path.join(folder, 'cp.csv')) mc_df = pd.read_csv(os.path.join(folder, 'mc.csv')) mcp113_df = pd.read_csv(os.path.join(folder, 'mcp113.csv')) mcproject_df = pd.read_csv(os.path.join(folder, 'mcproject.csv')) pa_df = pd.read_csv(os.path.join(folder, 'pa.csv')) fa_df = pd.read_csv(os.path.join(folder, 'fa.csv')) return cp_df, mc_df, mcp113_df, mcproject_df, pa_df, fa_df
至于生成图表,我想到的是pyecharts。
绘制图表的示例如下:
from pyecharts.charts import Bar from pyecharts import options as opts bar = ( Bar({"width": "800px", "height": "750px", }) # 初始化图表宽和高 .add_xaxis(list(last_label)) # x轴的数 .add_yaxis('Response Time Average This Time',list(this_average)) # 增加y轴,本次结果 .add_yaxis('Response Time Average Last TIme',list(last_average)) # 增加y轴,上次结果 .set_global_opts( # 设置全局设置 title_opts=opts.TitleOpts(title='接口平均相应时间对比图'), # 设置标题 xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=15)), # 设置x周,这里是将文字倾斜,便于显示较长的文字 legend_opts=opts.LegendOpts(is_show=True, pos_right=10) # 设置图例 ) )
生成图表这块,在网上查了很久,主要是参数配置不太理解。最后都是在官方文档中找到了最后答案。不得不说,还是官方文档靠谱,百度里搜索出来的结果有时能解燃眉之急,有时却是东拼西凑,质量不高。还是多用Google吧。不过pyechart本身是源自百度的库,估计国外用的人不多,资料大概也不多。
接下来是就往图表里塞数据了,这里也是问题最多的地方,主要有以下几点:
1.前后执行的接口并不是完全一致,没办法直接通过Label标签排序,将要比较的数据对齐。
2.有些接口请求的参数是动态变化的,没办法将接口名写死。
可见,数据清理将是重头,会决定之后生成的图表是否正确。我的解决思路是,将要比较的接口和页面分别参数化,再拿着要比较的数据,取其Label字段,分别在新旧数据中搜索,生成新旧待比较的数据集,再将数据排列对齐,保证顺序一致。Dataframe支持的操作其实已经很多了,就我目前了解的,没有找到现成方案,就自己写了些小方法,实现这些目标。具体代码如下:
def df_contains(df, partial_labels): ''' 这一步是为了找出要对比的数据 遍历列表,在Dataframe中匹配,凡是包含当前字符串的,都拿出来 ''' result_df = None for label in partial_labels: x = df[df['Label'].str.contains(label)] if result_df is None: result_df = x else: if not x.empty: result_df = result_df.append(x, ignore_index=True) return result_df.drop_duplicates(subset=['Label', 'Average','Median'], keep='first')
def replace_digits_in_df(df, label): ''' 这一步是为了取出label中的数字 Jmeter录制的脚本中,每次请求前面都会加上序号,影响排序,需要统一去掉 当然也许Jmeter中本身就可以设置,只是我不知道 ''' for row in df.iterrows(): _ = row[1].Label df.loc[row[0], label] = re.sub('\d+', '', _) return df
def draw_api(last_df, this_df, column): ''' last_df: 上一次结果,pd.Dataframe this_df: 本次结果,pd.Dataframe return: 柱状对比图,可在notebook中绘制,也可直接导出html ''' last_temp = replace_digits_in_df(last_df,'Label') last = df_contains(last_temp, api_labels).sort_values(by=['Label']) this_temp = replace_digits_in_df(this_df,'Label') this = df_contains(this_df,api_labels).sort_values(by=['Label']) print(this.Label) print('--------') print(last.Label) # 下面都是为了取出新旧待比较数据集中的交集,避免数据错位 this_del_index = this.append(last, sort=False).drop_duplicates(subset=['Label'], keep=False).index this = this.drop(this_del_index) last_del_index = last.append(this, sort=False).drop_duplicates(subset=['Label'], keep=False).index last = last.drop(last_del_index) this_average = this[column] this_label = this.Label last_average = last[column] last_label = last.Label bar = ( Bar({"width": "800px", "height": "750px", }) .add_xaxis(list(last_label)) .add_yaxis('Response Time Average This Time',list(this_average)) .add_yaxis('Response Time Average Last TIme',list(last_average)) .set_global_opts( title_opts=opts.TitleOpts(title='接口平均相应时间对比图'), xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=15)), legend_opts=opts.LegendOpts(is_show=True, pos_right=10) ) ) return bar
当然,这些方法也是前前后后尝试了很多次,慢慢写出来的规则。经过对比,执行的两轮中,没有数据错位的情况。其实这部分也是最费时间的。
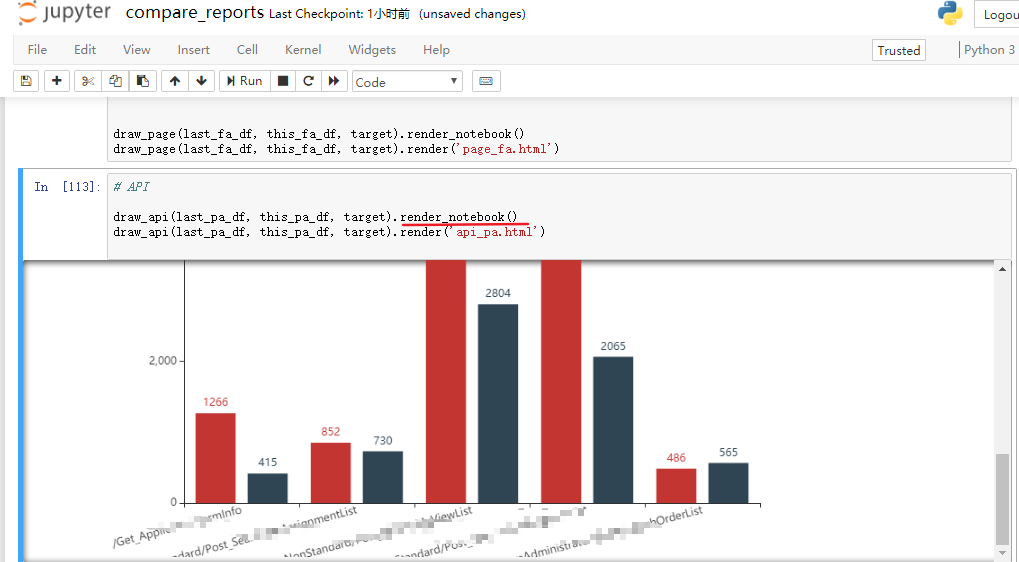
另外,在jupyter notebook中可以实时查看生成的图表,很是方便,推荐使用。只需要对最后生成的图表对象,调用render_notebook()方法即可。最后生成的对比图如下:
代码地址:
https://github.com/MRFF/Learning-Python/blob/master/compare_reports.py
