【pandas-08】Excel文件的拆分和合并
一、文件夹下的多个表格合并
1,把文件夹下面所有的文件都遍历出来
2、循环读取每个文件
(1)第一次读取的文件放入一个空的表中,起名叫合并表
(2)从第二次开始每次都与这个合并表进行合并
3、写入Excel
4、所有表表头行数要一至,通过header=1进行设置
伪代码
路径 = 'c:/pandas/课件025/'
合并表 = pd.DataFrame()
for 文件名 in os.listdir(路径):
表格 = pd.read_excel(路径 + 文件名)
合并表 =pd.concat([合并表,表格])
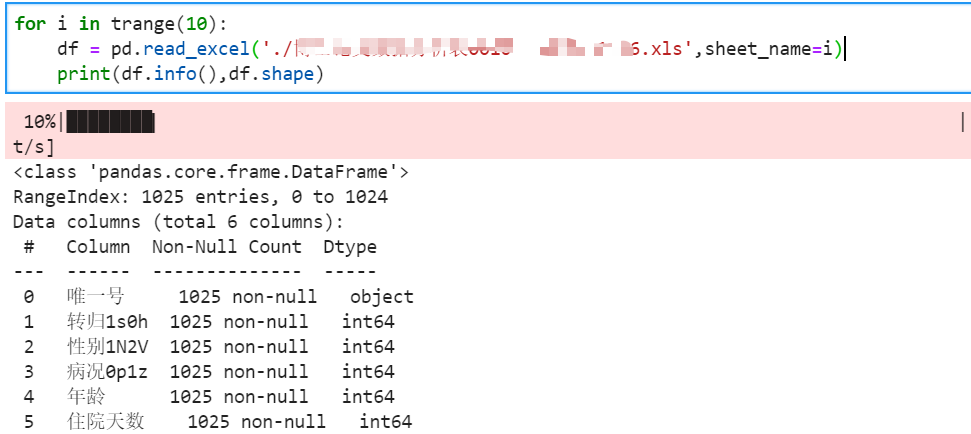
二、同一工作簿中多个Sheet合并
1、方法一
合并表 = pd.DataFrame()
字段名 = list(数据.keys())
for 列标签 in 字段名:
新数据 = 数据[列标签]
合并表 = pd.concat([合并表,新数据])
简单举例:每个keys都能读出:

2、方法二
可以使用conca或merge进行合并,具体方式可见《拼接数据》章节
三、一个工作表拆分成多个工作表
import pandas as pd
路径 = 'c:/pandas/拆分.xlsx'
数据 = pd.read_excel(路径)
分割列 = list(数据['部门'].drop_duplicates()) # 返回:['办公室', '销售部', '保洁部'],笔记13.1
新数据 = pd.ExcelWriter('c:/多个Sheet.xlsx')
for i in 分割列:
数据1 = 数据[数据['部门'] == i]
数据1.to_excel(新数据,sheet_name=i)
新数据.save()
新数据.close()
四、一个工作表拆分成多个工作簿
import pandas as pd
路径 = 'c:/pandas/拆分.xlsx'
数据 = pd.read_excel(路径)
分割列 = list(数据['部门'].drop_duplicates()) # 返回:['办公室', '销售部', '保洁部']
for i in 分割列:
数据1 = 数据[数据['部门'] == i]
数据1.to_excel('c:/'+ i + '.xlsx')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号