【pandas-06】拼接数据

concat:可以沿一条轴将多个对象连接到一起
merge:可以根据一个或多个键将不同的DataFrame中的行连接起来。
join:inner是交集,outer是并集。
建议使用:concat和merge
一、 concat
1.1 语法格式:
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True)
1.2 参数说明:
objs:series,dataframe或者是panel对象构成的序列lsit
axis:指明连接的轴向, {0/'index'(行), 1/'columns'(列)},默认为0
join:指明连接方式 , {'inner'(交集), 'outer(并集)'},默认为outer
join_axes:自定义的索引。指明用其他n-1条轴的索引进行拼接, 而非默认join =' inner'或'outer'方式拼接
keys:创建层次化索引。可以是任意值的列表或数组、元组数组、数组列表(如果将levels设置成多级数组的话)
ignore_index=True:重建索引
1.3 核心功能:
两个DataFrame通过pd.concat(),既可实现行拼接又可实现列拼接,默认axis=0,join='outer'。表df1和df2的行索引(index)和列索引(columns)均可以重复。
1、设置join='outer',只是沿着一条轴,单纯将多个对象拼接到一起,类似数据库中的全连接(union all)。
a. 当axis=0(行拼接)时,使用pd.concat([df1,df2]),拼接表的index=index(df1) + index(df2),拼接表的columns=columns(df1) ∪ columns(df2),缺失值填充NaN。
b. 当axis=1(列拼接)时,使用pd.concat([df1,df2],axis=1),拼接表的index=index(df1) ∪ index(df2),拼接表的columns=columns(df1) + columns(df2),缺失值填充NaN。
备注: index(df1) + index(df2) 表示:直接在df1的index之后 直接累加 df2的index;columns(df1) ∪columns(df2)表示:df1的columns和df2的columns 累加去重 ,下同。
a. 当axis=0时,pd.concat([obj1, obj2])与obj1.append(obj2)的效果是相同的,使用参数key可以为每个数据集(bj1, obj2)指定块标记;
b. 当axis=1时,pd.concat([obj1, obj2], axis=1)与pd.merge(obj1, obj2, left_index=True, right_index=True, how='outer') 的效果是相同的。
2、设置join='inner',拼接方式为"交联",即:行拼接时,仅保留df1和df2列索引重复的列;列拼接时,仅保留df1和df2行索引重复的行。
a. 当axis=0(行拼接)时,使用pd.concat([df1,df4],join='inner'),拼接表的index=index(df1) + index(df2),拼接表的columns=columns(df1) ∩ columns(df2);
b. 当axis=1(列拼接)时,pd.concat([df1,df4],axis=1,join='inner'),拼接表的index=index(df1) ∩ index(df2),拼接表的columns=columns(df1) + columns(df2);
备注: columns(df1) ∩columns(df2)表示:df1的columns和df2的columns 重复相同 ,下同。
1.4 实例
数据

1、默认的参数
axis=0、join=outer、ignore_index=False

2、ignore_index=True可以忽略原来的索引

3、join=inner过滤掉不匹配的列
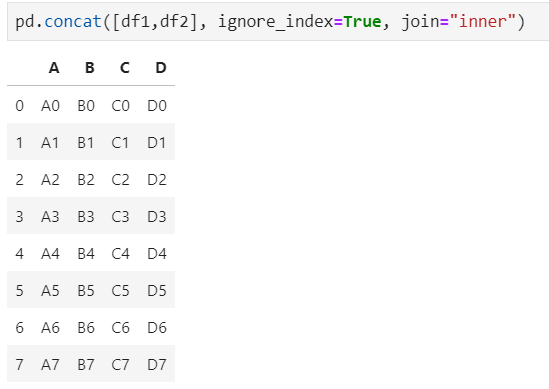
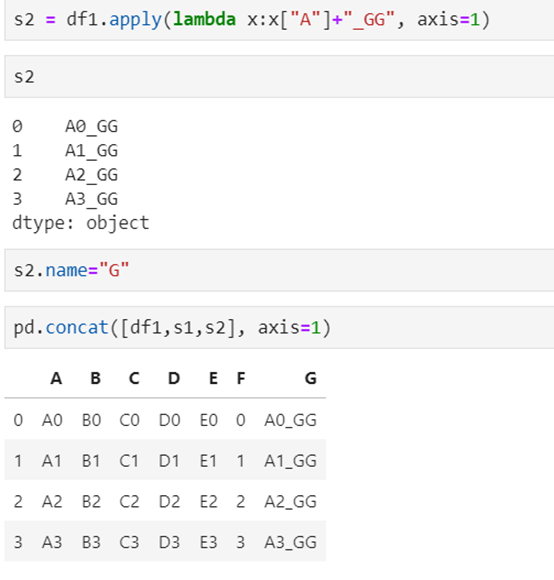
4、axis=1相当于添加新列
A:添加一列Series

B:添加多列Series

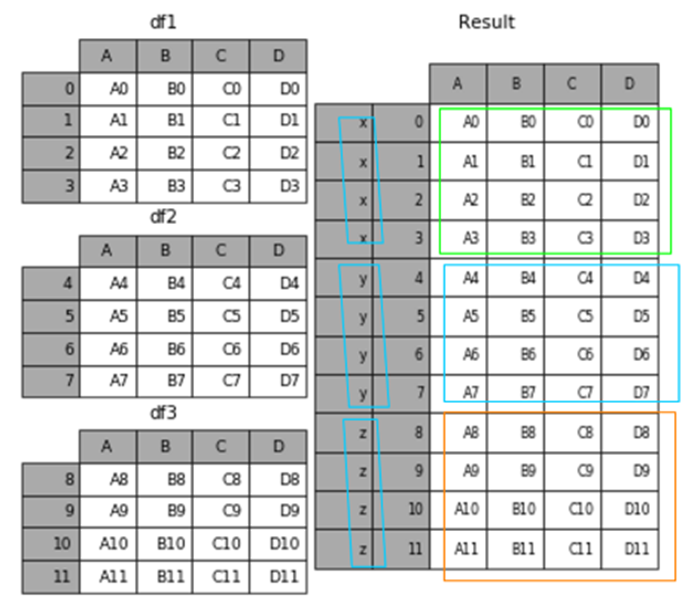
5、keys参数作用
可以用来给合并后的表增加key来区分不同的表数据来源
result = pd.concat(frames, keys=['x', 'y', 'z'])
1.5 常见的一个报错信息
TypeError: first argument must be an iterable of pandas objects, you passed an object of type "DataFrame"
出错原因就是,在使用pandas.concat(a,b)进行合并的时候,需要是list的形式。因此改成pandas.concat([a,b]),就可以成功合并。
二、merge
2.1 语法格式:
DataFrame.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
2.2 参数说明:
left和right:两个不同的DataFrame或Series
how:连接方式,有inner、left、right、outer,默认为inner
on:用于连接的列索引名称,必须同时存在于左、右两个DataFrame中,默认是以两个DataFrame列名的交集作为连接键,若要实现多键连接,'on'参数后传入多键列表即可
left_on:左侧DataFrame中用于连接键的列名,这个参数在左右列名不同但代表的含义相同时非常有用;
right_on:右侧DataFrame中用于连接键的列名
left_index:使用左侧DataFrame中的行索引作为连接键( 但是这种情况下最好用JOIN)
right_index:使用右侧DataFrame中的行索引作为连接键( 但是这种情况下最好用JOIN)
sort:默认为False,将合并的数据进行排序,设置为False可以提高性能
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为('_x', '_y')
copy:默认为True,总是将数据复制到数据结构中,设置为False可以提高性能
indicator:显示合并数据中数据的来源情况
2.3 核心功能:
类似于关系型数据库的连接方式,可以根据一个或多个键将两张不同的DatFrame连接起来,由于默认how='inner',故合并表仅保留key重名的行,不重名的行将被丢弃。( 备注: merge()只能完成两张表的连接,若有三个及以上表,需不断两两合并来实现)
该函数的典型应用场景: 两张表有相同内容的某一列(类似SQL中的主键),欲根据主键将两张表进行列拼接整合到一张表中,合并表的列数等于两个原数据表的列数和减去连接键的数量。
1)df1和df2的列索引(columns)仅有一项重复(即:col_1(df1)=col_1(df2))时,存在如下三种类型的数据合并:一对一、多对一、多对多,其拼接规则如下:
1. 一对一:若df1(左表)和df2(右表)的重名列col_1(df1)和col_1(df2)中,各列的值均不重复,通过pd.merge()方法能够自动识别相同的行作为主键,进行列拼接(拼接原理类似基因配对);
备注: 共同列中的元素位置可以不一致,pd.merge()能够自动选取相同的行进行拼接。另外,pd.merge()默认会丢弃原来的索引,重新生成索引。
2.多对一:若df1(左表)和df2(右表)的重名列col_1(df1)和col_1(df2),有一列的值有重复,通过多对一合并获得的连接表将会保留重复值。
3. 多对多:若df1(左表)和df2(右表)的重名列col_1(df1)和col_1(df2)都包含重复值,那么通过多对多合并获得的连接表将会保留所有重复值。
备注: 若重名列col_1(df1)有m行重名和col_1(df2)有n行重名,则合并表将有m×n行数据。
2)df1和df2的列索引(columns)有两项及以上重复(即:col_1(df1)=col_1(df2),col_2(df1)=col_2(df2),…)时,即:实现多键连接,仅需在'on'参数后传入多键列表即可。
对于inner、left、right、outer的解释:
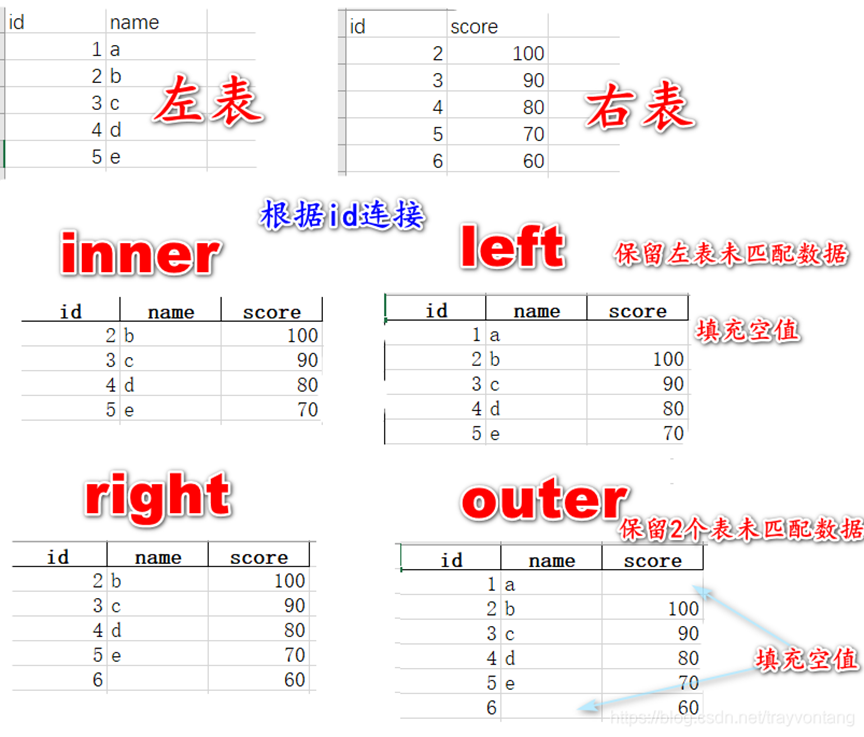
参考:https://blog.csdn.net/trayvontang/article/details/103787648
常见报错信息:
就是合并之后为空
a=pd.DataFrame({'a':[1,2,3],'b':[2,3,4]})
b=pd.DataFrame({'a':[11,22,33],'c':[22,33,44]})
c=pd.merge(a,b)
print(a)
print(b)
print(c)
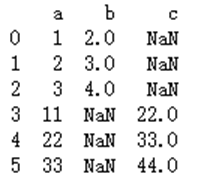
输出结果为:

通过验证发现,a和b的同名列表被合并,但是都是空说明默认连接形式是内连接,及二者默认把相同列名作为查找的条件,若是查找不到相同的值返回空。因此需要加入连接条件
c=pd.merge(a,b,how='outer',on='a')
print(c)
输出结果为:
参考:https://blog.csdn.net/youyoujbd/article/details/88930961
也可以关联两列

数据3= pd.merge(数据1,数据2,on=['姓名','班级']) # 内连接(交集)的结果
数据4= pd.merge(数据1,数据2,on=['姓名','班级'],how='outer') # 外连接(并集)的结果
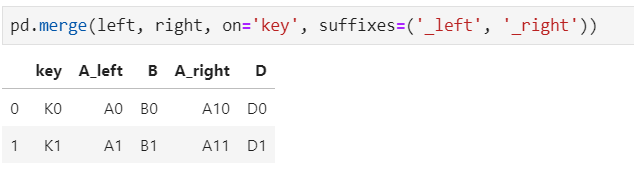
2.4 如果出现非Key的字段重名怎么办

三、join函数
DataFrame自身具有一个函数join,可以实现一定的连接功能。
3.1 语法格式:
df.join(other, on=None, how='left' , lsuffix=", rsuffix=", sort=False)
3.2 参数说明:
参数的意义与merge方法基本相同,只是join方法默认为左外连接how='left'
3.3 核心功能:
该函数的典型应用场景:无重复列名的两个表df1和df2 基于行索引进行列拼接,直接使用df1.join(df2)即可,无需添加任何参数,合并表的行数与left表相同,列数为left表+right表的列数之和,结果仅保留left表和right表中行索引相同的行,对列不做任何处理。如果两个表有重复的列名,需指定lsuffix, rsuffix参数。
利用join也可 基于列索引进行列拼接,需借助参数'on'。常见的基于列索引的列拼接方式有3种:
(Ⅰ)列名不同,列内容有相同:需要用到 l.join(r.set_index(key of r), on='key of l')
(Ⅱ)列名和列内容均有相同:需要用到l.join(r.set_index(key), on='key')
(Ⅲ)列名不同,列内容也不同:这种情况是典型的基于行索引进行列拼接,不能用JOIN的ON参数。
JOIN 拼接列,主要用于基于行索引上的合并。
3.4 常见范例:
例:1:
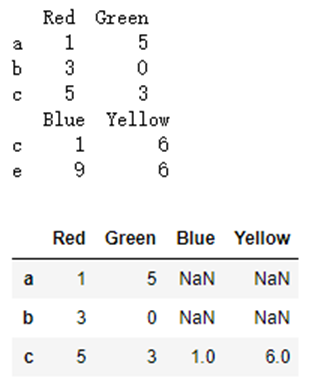
df3=pd.DataFrame({'Red':[1,3,5],'Green':[5,0,3]},index=list('abc'))
print(df3)
df4=pd.DataFrame({'Blue':[1,9],'Yellow':[6,6]},index=list('ce'))
print(df4)
df3.join(df4)
输出结果:默认是left连接
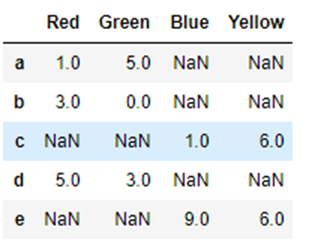
例2:使用参考how="outer"
df3.join(df4,how='outer')
输出结果:
例3:合并多个对象
df3=pd.DataFrame({'Red':[1,3,5],'Green':[5,0,3]},index=list('abd'))
print(df3)
df4=pd.DataFrame({'Blue':[1,9],'Yellow':[6,6]},index=list('ce'))
print(df4)
df5=pd.DataFrame({'Brown':[3,4,5],'White':[1,1,2]},index=list('aed'))
print(df5)
print(df3.join([df4,df5]))
结果:
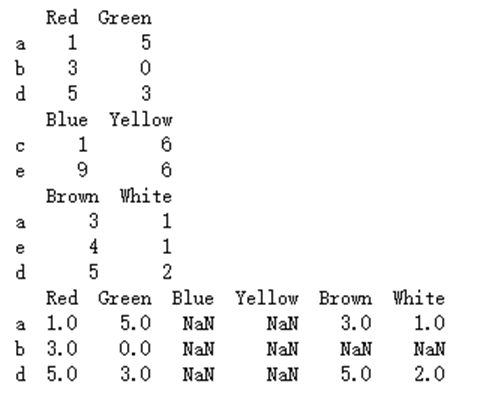
例4:合并多个对象
print(df3.join([df4,df5],how='outer'))
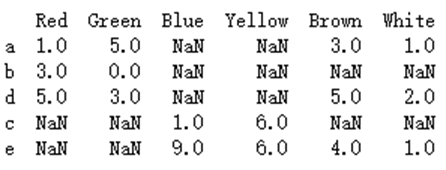
四、append
4.1 语法格式:
DataFrame.append(other, ignore_index=False, verify_integrity=False, sort=None)
4.2 参数说明:
other: DataFrame or Series/dict-like object, or list of these
The data to append.
ignore_index : boolean, default False
If True, do not use the index labels.
verify_integrity : boolean, default False
If True, raise ValueError on creating index with duplicates.
sort: boolean, default None
只是join方法默认为左外连接how='left'
4.3 核心功能:
append是concat的简略形式,只不过只能在axis=0上进行合并
df1.append(df2),df1.append(df2,ignore_index=True)
DataFrame和Series进行合并的时候需要使用参数ignore_index=True或者含有属性name,因为Series是只有一维索引的(备注:如果不添加参数ignore_index=True,那么会出错的。)。
转自:https://blog.csdn.net/weixin_42782150/article/details/89546357
4.4 实例
append是series和dataframe的方法,使用它就是默认沿着列进行凭借(axis = 0,列对齐)
result = df1.append(df2)
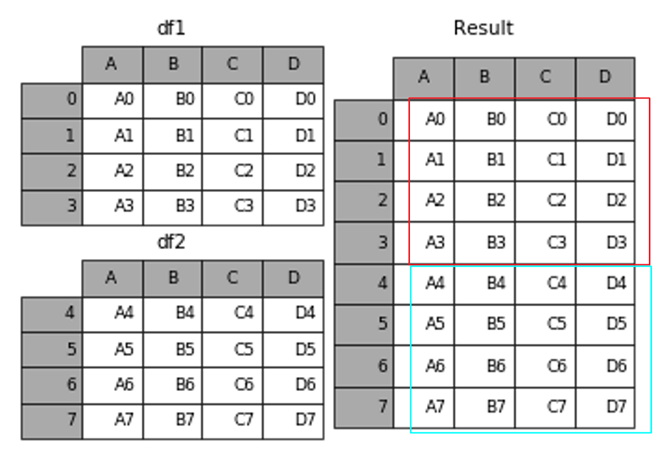
参考文献
* pandas.concat的api文档:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.concat.html
* pandas.concat的教程:https://pandas.pydata.org/pandas-docs/stable/user_guide/merging.html
* pandas.append的api文档:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.append.html

