【Pandas-01】简介、数据结构、读取,查询和与SQL对比
一、简介
什么是Pandas?
一个开源的Python类库:用于数据分析、数据处理、数据可视化
- 高性能
- 容易使用的数据结构
- 容易使用的数据分析工具
很方便和其它类库一起使用:
- numpy:用于数学计算
- scikit-learn:用于机器学习
二、Pandas数据结构
2.1 Series
Series是一种类似于一维数组的对象,它由一组数据(不同数据类型)以及一组与之相关的数据标签(即索引)组成。
1) 仅有数据列表即可产生最简单的Series
2) 创建一个具有标签索引的Series
3) 使用Python字典创建Series
4) 根据标签索引查询数据
类似Python的字典dict
5)常用方法
数据.index #查看索引
数据.values #查看数值
数据.isnull() #查看为空的,返回布尔型
数据.notnull()
数据.sort_index() #按索引排序
数据.sort_values() #按数值排序
2.2 DataFrame
--DataFrame是一个表格型的数据结构
- 每列可以是不同的值类型(数值、字符串、布尔值等)
- 既有行索引index,也有列索引columns
- 可以被看做由Series组成的字典
--pandas中的DataFrame可以使用以下构造函数创建 -pandas.DataFrame( data, index, columns, dtype, copy)
编号 参数 描述
1 data 数据采取各种形式,如:ndarray,series,map,lists,dict,constant和另一个DataFrame。
2 index 对于行标签,要用于结果帧的索引是可选缺省值np.arrange(n),如果没有传递索引值。
3 columns 对于列标签,可选的默认语法是 - np.arange(n)。 这只有在没有索引传递的情况下才是这样。
4 dtype 每列的数据类型。
5 copy 如果默认值为False,则此命令(或任何它)用于复制数据。
--loc就根据这个index来索引对应的行。iloc并不是根据index来索引,而是根据行号来索引,行号从0开始,逐次加1。
- 数据.loc方法:根据行,列的标签值查询
- 数据.iloc方法:根据行,列的数字位置查询
1)创建一个空的DataFrame
2) 字典序列创建
示例一:序列字典
实例二:列表字典
2)列表创建dataframe
2.3 从DataFrame中查询出Series
- 如果只查询一行、一列,返回的是pd.Series
- 如果查询多行、多列,返回的是pd.DataFrame
1)查询一列,结果是一个pd.Series
2)查询多列,结果是一个pd.DataFrame
3)查询一行,结果是一个pd.Series
4)查询多行,结果是一个pd.DataFrame
三、读取数据
数据类型 | 说明 | 读取方法 |
csv、tsv、txt | 默认逗号分隔 | pd.read_csv |
csv、tsv、txt | 默认\t分隔 | pd.read_table |
excel | xls或xlsx | pd.read_excel |
mysql | 关系数据库表 | pd.read_sql |
3.1 pandas读取纯文本文件
1)读取csv文件
使用默认的标题行、逗号分隔符
切记:如果分隔符不止一种,使用正则表达式sep='\s+'
参数 | 描述 |
sep | 分隔符或正则表达式 sep='\s+' |
header | 列名的行号,默认0(第一行),如果没有列名应该为None,意思就是没有表头,后面你自己写表头 |
names | 列名,与header=None一起使用,也就是上面写的自己定义表头 |
index_col | 指定某列为索引,可以是一个单一的名称或数字,也可以是一个分层索引,若是要设定,建议读取时设置 |
skiprows | 从文件开始处,需要跳过的行数或行号列表 |
encoding | 文本编码,例如utf-8 |
nrows | 从文件开头处读入的行数 nrows=3 |
自定义索引读取
跳过指定的行:skiprows
2)读取txt文件
自己指定分隔符、列名
3.2 pandas读取xlsx格式excel文件
具体可见官网:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_excel.html?highlight=read_excel
也可参考:https://zhuanlan.zhihu.com/p/142972462
3.3 andas读取mysql数据表
1 2 3 4 5 6 7 8 9 | import pymysql conn = pymysql.connect( host='127.0.0.1', user='root', password='12345678', database='test', charset='utf8' ) mysql_page = pd.read_sql("select * from crazyant_pvuv", con=conn) |
四、查询数据
本次的数据集形态:
4.1 列变成index
4.2 基本信息查看
1)类型查询:df.dtypes
看更加详细的信息
2)查看DataFrame的头尾(head()和tail())
使用head可以查看前几行的数据,默认的是前5行,不过也可以自己设置。
使用tail可以查看后几行的数据,默认也是5行,参数可以自己设置。
3)查看行名与列名(.index和.columns)
4)describe 数据值列汇总
5)其它
编号 属性或方法 描述
1 axes 返回行轴标签列表。
2 values 将系列作为ndarray返回。
3 empty 如果系列为空,则返回True。
4 ndim 返回底层数据的维数,默认定义:1。
5 size 返回基础数据中的元素数。
6 shape 大小
4.3 Pandas查询数据的几种方法
- df.loc方法,根据行、列的标签值查询
- df.iloc方法,根据行、列的数字位置查询
- df.where方法
- df.query方法
.loc既能查询,又能覆盖写入,强烈推荐!
4.4 Pandas使用df.loc查询数据的方法
df.loc[A,B] :A表示行的序号,B表示列的序号集
1) 使用单个label值查询数据
行或者列,都可以只传入单个值,实现精确匹配
2) 使用值列表批量查询
3) 使用数值区间进行范围查询
注意:区间既包含开始,也包含结束
4)使用条件表达式查询
bool列表的长度得等于行数或者列数
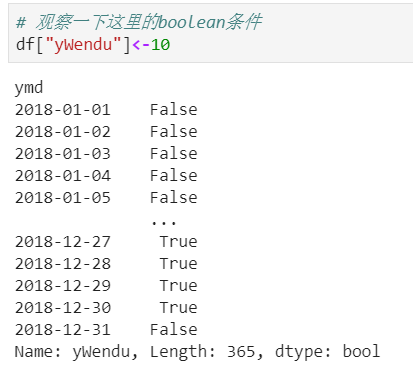
①简单条件查询,最低温度低于-10度的列表
df.loc[df["yWendu"]<-10, :]
理解:
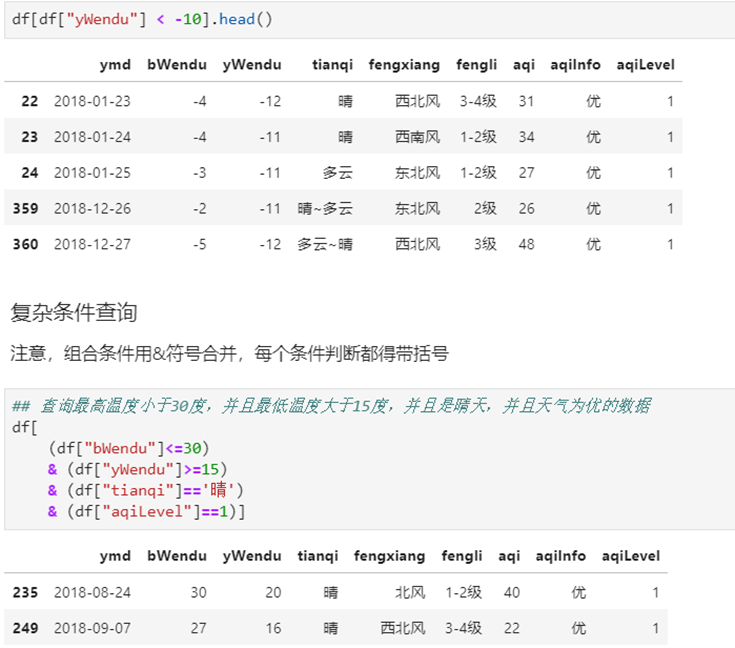
②复杂条件查询,查一下我心中的完美天气
注意,组合条件用&符号合并,每个条件判断都得带括号
# 查询最高温度小于30度,并且最低温度大于15度,并且是晴天,并且天气为优的数据(注意每个都要小括号)
df.loc[(df["bWendu"]<=30) & (df["yWendu"]>=15) & (df["tianqi"]=='晴') & (df["aqiLevel"]==1), :]

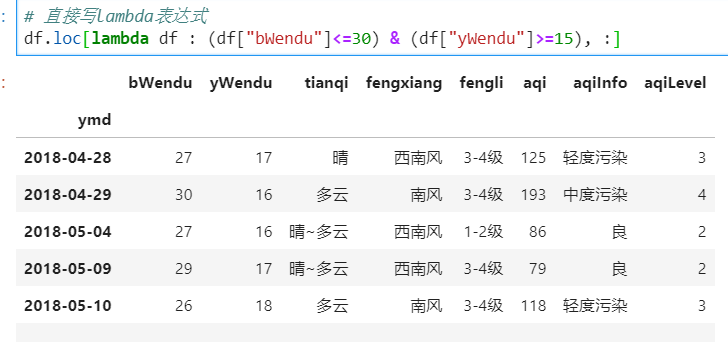
5)调用函数查询
# 直接写lambda表达式
df.loc[lambda df : (df["bWendu"]<=30) & (df["yWendu"]>=15), :]
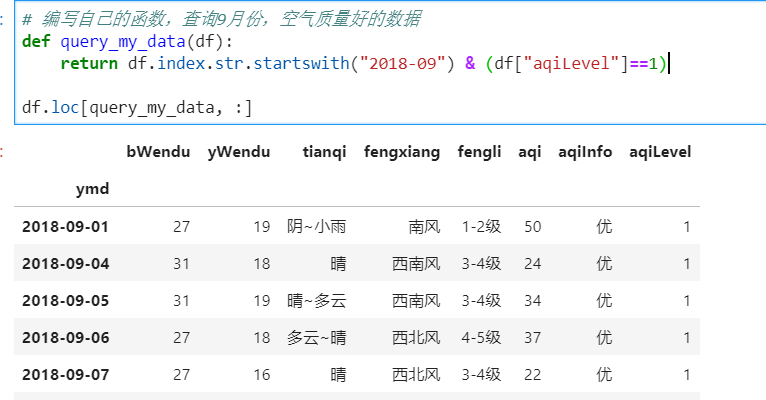
# 编写自己的函数,查询9月份,空气质量好的数据
def query_my_data(df):
return df.index.str.startswith("2018-09") & (df["aqiLevel"]==1)
df.loc[query_my_data, :]
注意
- 以上查询方法,既适用于行,也适用于列
- 注意观察降维dataFrame>Series>值
4.5 df.query
怎样进行复杂组合条件对数据查询:
- 方式1. 使用df[(df["a"] > 3) & (df["b"]<5)]的方式;
- 方式2. 使用df.query("a>3 & b<5")的方式;
方法2的语法更加简洁
性能对比:
- 当数据量小时,方法1更快;
- 当数据量大时,因为方法2直接用C语言实现,节省方法1临时数组的多次复制,方法2更快;
1)使用dataframe条件表达式查询
2)使用df.query可以简化查询
形式:DataFrame.query(expr, inplace=False, **kwargs)
其中expr为要返回boolean结果的字符串表达式形如:
- df.query('a<100')
- df.query('a < b & b < c'),或者df.query('(a<b)&(b<c)')
df.query可支持的表达式语法:
- 逻辑操作符: &, |, ~
- 比较操作符: <, <=, ==, !=, >=, >
- 单变量操作符: -
- 多变量操作符: +, -, *, /, %
df.query中可以使用@var的方式传入外部变量
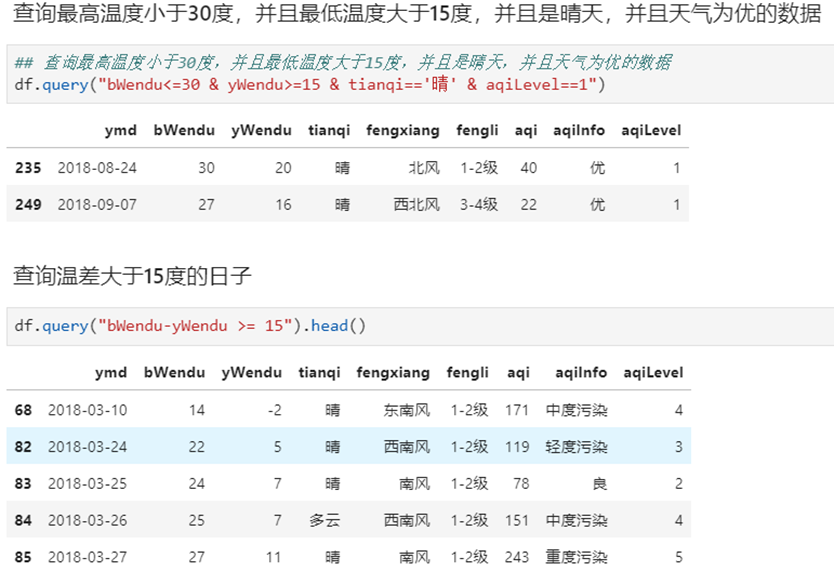
可以使用外部的变量
df.query支持的语法来自NumExpr,地址:
https://numexpr.readthedocs.io/projects/NumExpr3/en/latest/index.html
4.6 按行遍历的三种方式
1. df.iterrows()
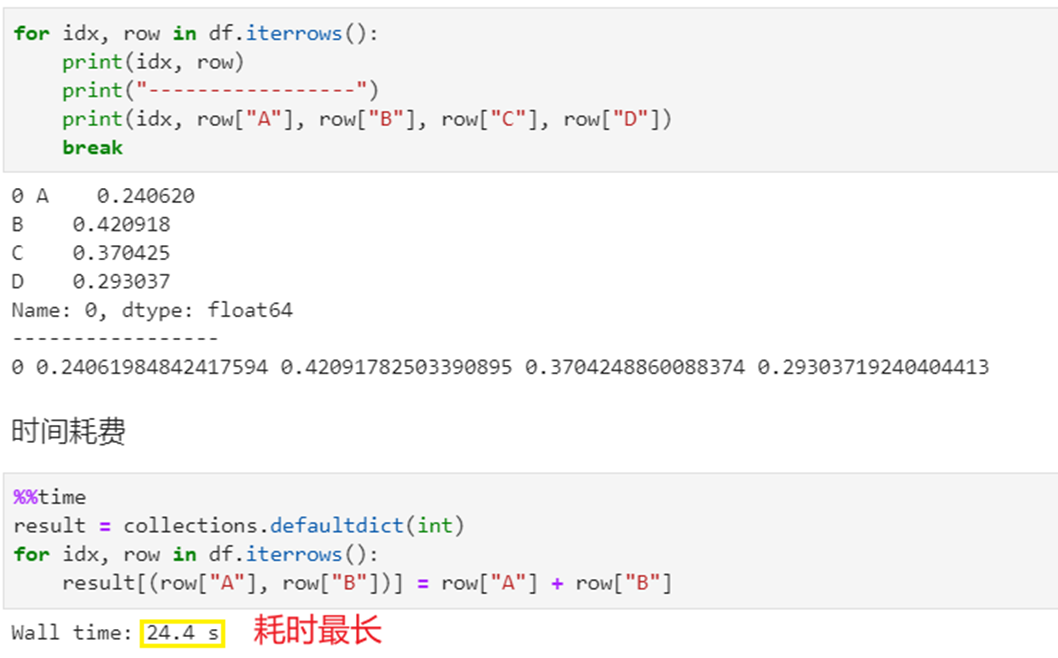
时间花费在类型检查
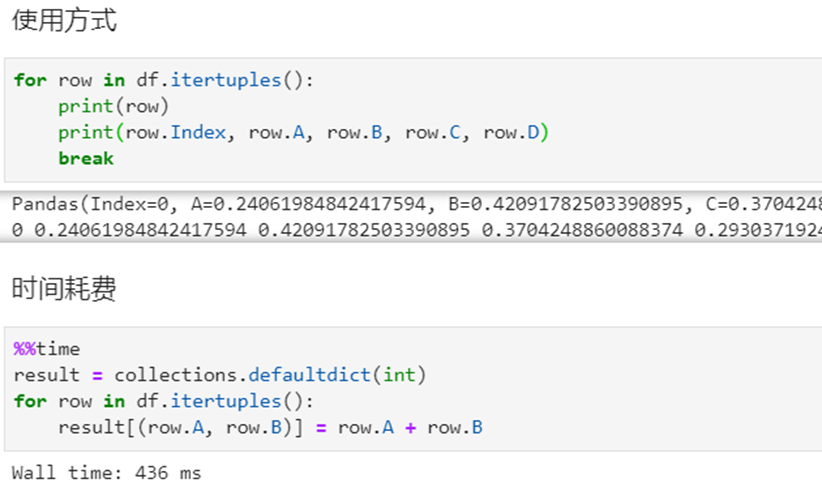
2. df.itertuples()
3. for+zip

三个的结果均如下,第三种方式最快。

五、Pandas和数据库查询语言SQL的对比
两者都是对"表格型"数据的操作和查询,所以很多语法都能对应起来
数据
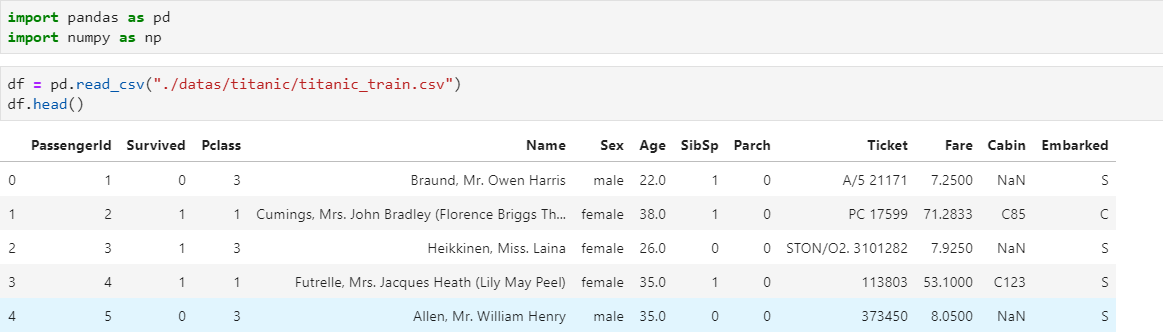
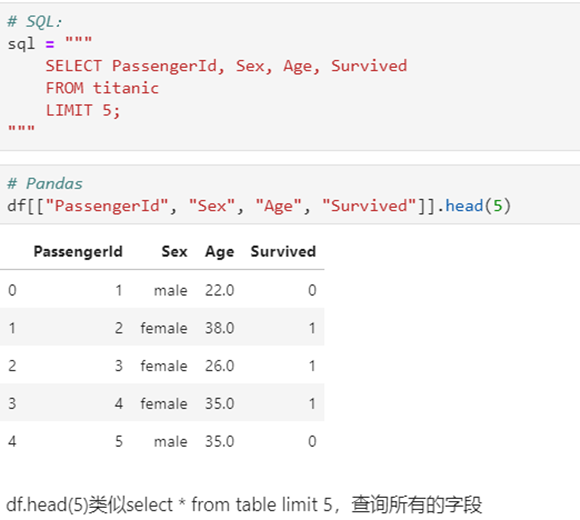
5.1 SELECT数据查询
5.2 WHERE按条件查询

5.3 in和not in的条件查询

5.4 groupby分组统计
1 单个列的聚合
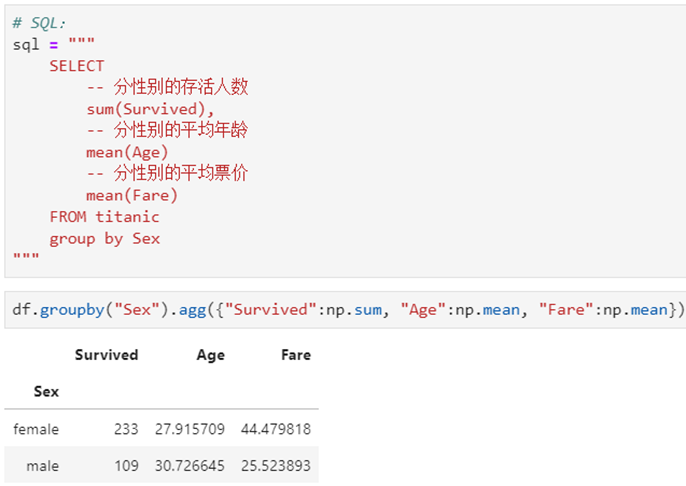
2 多个列的聚合
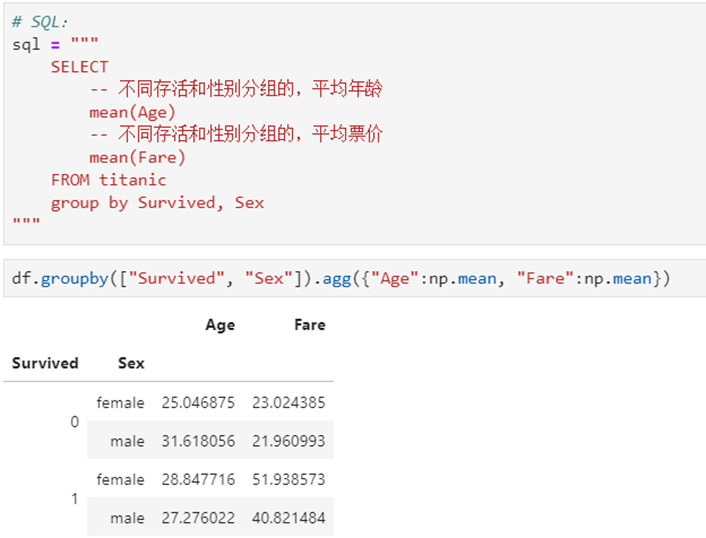
5.5 JOIN数据关联

5.6 UNION数据合并
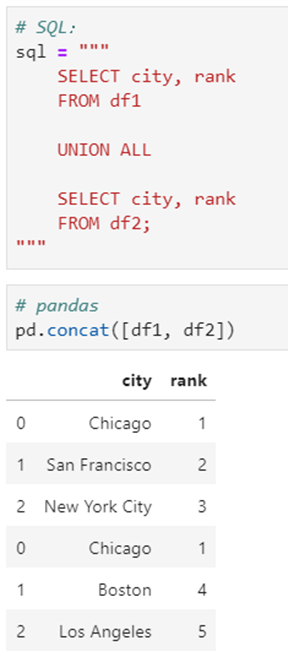
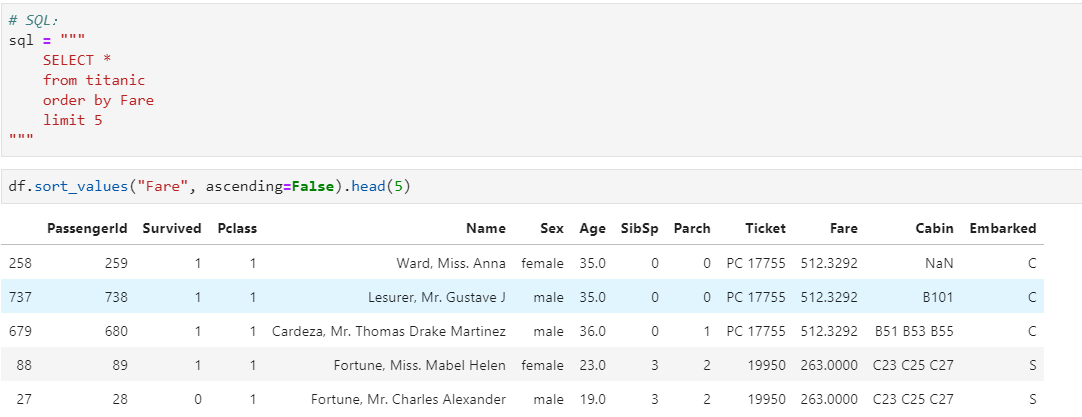
5.7 Order Limit先排序后分页
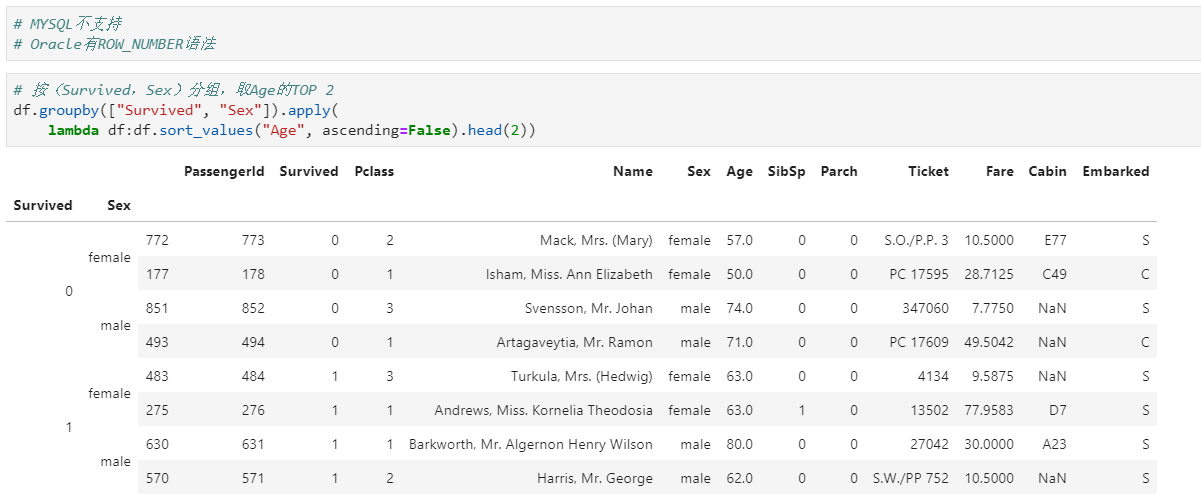
5.8 取每个分组group的top n
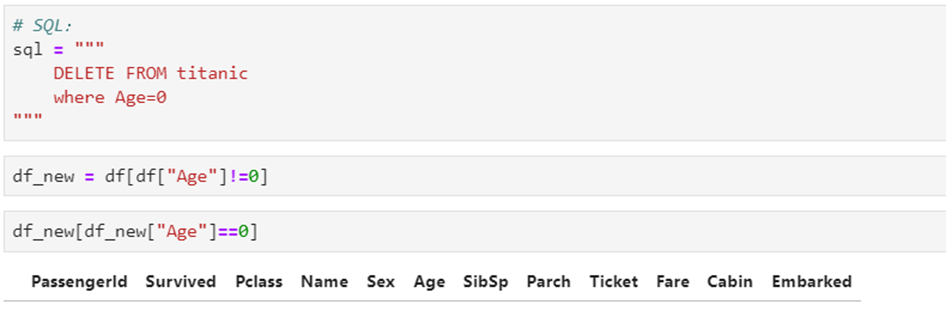
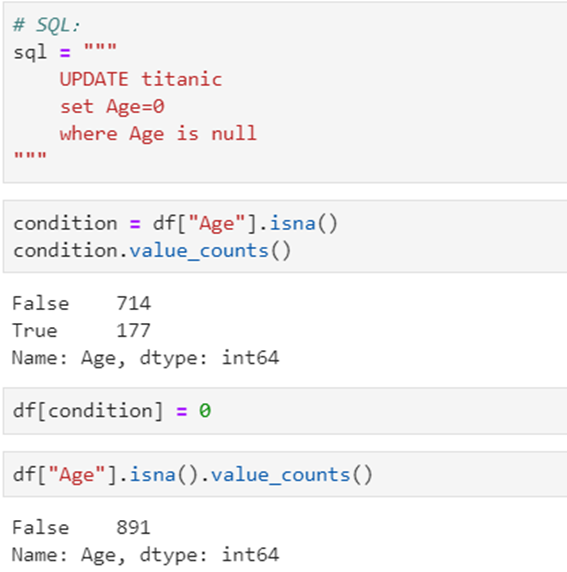
5.9 UPDATE数据更新
5.10 DELETE删除数据