【ML-6-4-1】xgboost参数说明
目录
- 常规参数
- Tree Booster的参数
- Linear Booster的参数(booster=gblinear)
- 学习任务参数
- 代码主要函数
- 参数调整注意事项
在运行XGBoost之前,我们必须设置三种类型的参数:常规参数,增强器参数和任务参数。
常规参数与我们用来进行增强的助推器有关,通常是树形模型或线性模型
增压器参数取决于您选择的增压器
学习任务参数决定学习场景。例如,回归任务可以对排名任务使用不同的参数。
命令行参数与XGBoost的CLI版本的行为有关。
基本和官网一致,只是部分翻译了,便于以后快捷地搜索。
本文对较为重要的参数做底色标示
一、常规参数
booster[默认= gbtree]
使用哪个助推器。可以gbtree,gblinear或者dart; gbtree并dart使用基于树的模型,同时gblinear使用线性函数。
verbosity [默认值= 1]
打印消息的详细程度。有效值为0(静默),1(警告),2(信息),3(调试)。有时,XGBoost会尝试根据启发式来更改配置,该显示为警告消息。如果出现意外行为,请尝试增加详细程度。
validate_parameters [默认为false,Python,R和CLI界面除外]
设置为True时,XGBoost将执行输入参数的验证,以检查是否使用了参数。该功能仍处于试验阶段。预期会有一些误报。
nthread [如果未设置,默认为最大可用线程数]
用于运行XGBoost的并行线程数。选择它时,请记住线程争用和超线程。
disable_default_eval_metric [默认=``false'']
标记以禁用默认指标。设置为1或true禁用。
num_pbuffer [由XGBoost自动设置,无需由用户设置]
预测缓冲区的大小,通常设置为训练实例数。缓冲区用于保存上一个增强步骤的预测结果。
num_feature [由XGBoost自动设置,无需由用户设置]
用于增强的特征尺寸,设置为特征的最大尺寸
二、Tree Booster的参数
eta[默认= 0.3,别名:learning_rate]
在更新中使用步长收缩以防止过度拟合。在每个增强步骤之后,我们都可以直接获得新特征的权重,并eta缩小特征权重以使增强过程更加保守。
范围:[0,1]
gamma[默认= 0,别名:min_split_loss]
在树的叶节点上进行进一步分区所需的最小损失减少。越大gamma,算法将越保守。
范围:[0,∞]
max_depth [默认= 6]
一棵树的最大深度。增加此值将使模型更复杂,并且更可能过度拟合。仅lossguided当tree_method设置为hist且表示深度没有限制时,才在增长策略中接受0 。注意,训练一棵深树时,XGBoost会大量消耗内存。
范围:[0,∞](仅lossguided当tree_method设置为时,增长策略才接受0 hist)
min_child_weight [默认值= 1]
子级中实例重量的最小总和(hessian)。如果树划分步骤导致叶节点的实例权重之和小于min_child_weight,则构建过程将放弃进一步的划分。在线性回归任务中,这仅对应于每个节点中需要的最少实例数。越大min_child_weight,算法将越保守。
范围:[0,∞]
max_delta_step [默认= 0]
我们允许每个叶子输出的最大增量步长。如果将该值设置为0,则表示没有约束。如果将其设置为正值,则可以帮助使更新步骤更加保守。通常不需要此参数,但是当类极度不平衡时,它可能有助于逻辑回归。将其设置为1-10的值可能有助于控制更新。
范围:[0,∞]
subsample [默认值= 1]
训练实例的子样本比率。将其设置为0.5意味着XGBoost将在树木生长之前随机采样一半的训练数据。这样可以防止过度拟合。二次采样将在每个增强迭代中进行一次。
范围:(0,1]
sampling_method[默认= uniform]
用于对训练实例进行采样的方法。
uniform:每个训练实例的选择概率均等。通常将subsample> = 0.5设置 为良好的效果。
gradient_based:每个训练实例的选择概率与规则化的梯度绝对值成正比 (更具体地说,
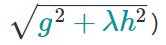
subsample可以设置为低至0.1,而不会损失模型精度。请注意,只有tree_method将设置为时,才支持此采样方法gpu_hist。其他树方法仅支持uniform采样。
colsample_bytree,colsample_bylevel,colsample_bynode[默认= 1]
这是用于列二次采样的一组参数。
所有colsample_by*参数的范围为(0,1],默认值为1,并指定要进行二次采样的列的分数。
colsample_bytree是构造每棵树时列的子样本比率。对每一个构造的树进行一次二次采样。
colsample_bylevel是每个级别的列的子采样率。对于树中达到的每个新深度级别,二次采样都会发生一次。从为当前树选择的一组列中对列进行子采样。
colsample_bynode是每个节点(拆分)的列的子样本比率。每次评估新的分割时,都会进行一次二次采样。列是从为当前级别选择的一组列中进行子采样的。
colsample_by*参数累积工作。例如,具有64个功能的组合将在每个拆分中留下8个功能供您选择。{'colsample_bytree':0.5, 'colsample_bylevel':0.5, 'colsample_bynode':0.5}
在Python界面上,可以设置feature_weightsfor DMatrix来定义使用列采样时选择每个功能的概率。fitsklearn界面中的方法有一个类似的参数。
lambda[默认= 1,别名:reg_lambda]
L2正则化权重项。增加此值将使模型更加保守。
alpha[默认= 0,别名:reg_alpha]
权重的L1正则化项。增加此值将使模型更加保守。
tree_method字符串[default = auto]
XGBoost中使用的树构建算法。请参阅参考文件中的描述。
XGBoost支持 approx,hist并gpu_hist用于分布式训练。外部存储器实验支持可用于approx和gpu_hist。
选择:auto,exact,approx,hist,gpu_hist,这是常用的更新程序的组合。对于其他更新程序,例如refresh,updater直接设置参数。
auto:使用启发式选择最快的方法。
- 对于小型数据集,exact将使用精确贪婪()。
- 对于较大的数据集,approx将选择近似算法()。它建议尝试hist,并gpu_hist用大量的数据可能更高的性能。(gpu_hist)支持。external memory
- 由于旧行为总是在单个计算机上使用完全贪婪,因此,当选择近似算法来通知该选择时,用户将收到一条消息。
exact:精确的贪婪算法。枚举所有拆分的候选人。
approx:使用分位数草图和梯度直方图的近似贪婪算法。
hist:更快的直方图优化的近似贪婪算法。
gpu_hist:GPUhist算法的实现。
sketch_eps [默认值= 0.03]
仅用于tree_method=approx。
这大致转化为箱数。与直接选择垃圾箱数量相比,这具有草图准确性的理论保证。O(1 / sketch_eps)
通常,用户不必对此进行调整。但是,请考虑设置较低的数字,以更精确地枚举拆分的候选人。
范围:(0,1)
scale_pos_weight [默认值= 1]
控制正负权重的平衡,对于不平衡的班级很有用。需要考虑的典型值:。有关更多讨论,请参见参数调整。另外,请参见Higgs Kaggle竞赛演示,例如:R,py1,py2,py3。sum(negative instances) / sum(positive instances)
updater[默认= grow_colmaker,prune]
逗号分隔的字符串定义要运行的树更新程序的顺序,从而提供了一种构造和修改树的模块化方法。这是一个高级参数,通常会根据其他一些参数自动设置。但是,它也可以由用户显式设置。存在以下更新程序:
updater[默认= grow_colmaker,prune]
逗号分隔的字符串定义要运行的树更新程序的顺序,从而提供了一种构造和修改树的模块化方法。这是一个高级参数,通常会根据其他一些参数自动设置。但是,它也可以由用户显式设置。存在以下更新程序:
- grow_colmaker:基于树的非分布式列结构。
- grow_histmaker:基于直方图计数的全局提议,基于行的数据拆分的分布式树结构。
- grow_local_histmaker:基于本地直方图计数。
- grow_quantile_histmaker:使用量化直方图来生长树。
- grow_gpu_hist:使用GPU种植树。
- sync:同步所有分布式节点中的树。
- refresh:根据当前数据刷新树的统计信息和/或叶值。注意,不对数据行进行随机子采样。
- prune:修剪损失<min_split_loss(或gamma)的分割。
在分布式设置中,grow_histmaker,prune默认情况下会将隐式更新程序序列值调整为,您可以将其设置tree_method为hist使用grow_histmaker。
refresh_leaf [默认值= 1]
这是refresh更新程序的参数。当此标志为1时,将更新树叶和树节点的统计信息。当它为0时,仅更新节点统计信息。
process_type[默认= default]
一种运行的加速过程。
选择:default,update
- default:创建新树的正常增强过程。
- update:从现有模型开始,仅更新其树。在每次增强迭代中,都会从初始模型中提取一棵树,为该树运行指定的更新程序序列,然后将修改后的树添加到新模型中。新模型将具有相同或更少数量的树,具体取决于执行的增强迭代次数。当前,以下内置更新程序可与此进程类型有意义地使用:refresh,prune。使用时process_type=update,不能使用创建新树的更新程序。
grow_policy[默认= depthwise]
控制将新节点添加到树的方式。
当前仅在tree_method设置为时受支持hist。
选择:depthwise,lossguide
- depthwise:在最靠近根的节点处拆分。
- lossguide:在损耗变化最大的节点处拆分。
max_leaves [默认= 0]
要添加的最大节点数。仅在grow_policy=lossguide设置时相关。
max_bin,[默认值= 256]
仅在tree_method设置为时使用hist。
用于存储连续特征的最大不连续回收箱数。
增加此数目可提高拆分的最佳性,但需要更长的计算时间。
predictor,[default =`ʻʻauto``]
要使用的预测器算法的类型。提供相同的结果,但允许使用GPU或CPU。
- auto:基于启发式配置预测变量。
- cpu_predictor:多核CPU预测算法。
- gpu_predictor:使用GPU进行预测。在tree_methodis时使用gpu_hist。当predictor设置为默认值时auto,gpu_histtree方法能够提供基于GPU的预测,而无需将训练数据复制到GPU内存中。如果gpu_predictor明确指定,则将所有数据复制到GPU中,仅建议用于执行预测任务。
num_parallel_tree,[default = 1]
-每次迭代期间构造的并行树的数量。此选项用于支持增强型随机森林。
monotone_constraints
可变单调性的约束。
interaction_constraints
交互约束表示允许的交互。约束必须以嵌套列表的形式指定,例如,其中每个内部列表是一组允许彼此交互的要素索引。有关更多信息,请参见教程[[0, 1], [2, 3, 4]]
三、Linear Booster的参数(booster=gblinear)
lambda[默认= 0,别名:reg_lambda]
L2正则化权重项。增加此值将使模型更加保守。归一化为训练示例数。
alpha[默认= 0,别名:reg_alpha]
权重的L1正则化项。增加此值将使模型更加保守。归一化为训练示例数。
updater[默认= shotgun]
选择适合线性模型的算法
- shotgun:基于shot弹枪算法的平行坐标下降算法。使用" hogwild"并行性,因此每次运行都会产生不确定的解决方案。
- coord_descent:普通坐标下降算法。同样是多线程的,但仍然可以产生确定性的解决方案。
feature_selector[默认= cyclic]
特征选择和排序方法
- cyclic:通过一次循环浏览功能来进行确定性选择。
- shuffle:类似于,cyclic但在每次更新之前随机进行改组。
- random:随机(带替换)坐标选择器。
- greedy:选择梯度最大的坐标。它具有O(num_feature^2)复杂性。这是完全确定性的。top_k通过设置top_k参数,它允许将选择限制为每组具有最大单变量权重变化的特征。这样做将降低复杂度O(num_feature*top_k)。
- thrifty:节俭的近似贪婪的特征选择器。在循环更新之前,对特征的重排序以其单变量权重变化的降序进行。此操作是多线程的,是二次贪婪选择的线性复杂度近似值。top_k通过设置top_k参数,它允许将选择限制为每组具有最大单变量权重变化的特征。
top_k [默认= 0]
要选择的最重要特征数greedy和thrifty特征选择器。值0表示使用所有功能。
四、学习任务参数
objective [默认= reg:squarederror]
reg:squarederror:损失平方回归。
reg:squaredlogerror:对数损失平方回归
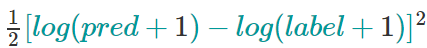
所有输入标签都必须大于-1。另外,请参阅指标rmsle以了解此目标可能存在的问题。
reg:logistic:逻辑回归
reg:pseudohubererror:使用伪Huber损失进行回归,这是绝对损失的两倍可微选择。
binary:logistic:二元分类的逻辑回归,输出概率
binary:logitraw:用于二进制分类的逻辑回归,逻辑转换之前的输出得分
binary:hinge:二进制分类的铰链损失。这使预测为0或1,而不是产生概率。
count:poisson –计数数据的泊松回归,泊松分布的输出平均值
max_delta_step 在泊松回归中默认设置为0.7(用于维护优化)
survival:cox:针对正确的生存时间数据进行Cox回归(负值被视为正确的生存时间)。请注意,预测是按危险比等级返回的(即,比例危险函数中的HR = exp(marginal_prediction))。h(t) = h0(t) * HR
survival:aft:用于检查生存时间数据的加速故障时间模型。有关详细信息,请参见具有加速故障时间的生存分析。
aft_loss_distribution:survival:aft目标和aft-nloglik度量使用的概率密度函数。
multi:softmax:设置XGBoost以使用softmax目标进行多类分类,还需要设置num_class(类数)
multi:softprob:与softmax相同,但输出向量,可以进一步将其整形为矩阵。结果包含属于每个类别的每个数据点的预测概率。ndata * nclassndata * nclass
rank:pairwise:使用LambdaMART进行成对排名,从而使成对损失最小化
rank:ndcg:使用LambdaMART进行列表式排名,使标准化折让累积收益(NDCG)最大化
rank:map:使用LambdaMART进行列表平均排名,使平均平均精度(MAP)最大化
reg:gamma:使用对数链接进行伽马回归。输出是伽马分布的平均值。例如,对于建模保险索赔的严重性或对可能是伽马分布的任何结果,它可能很有用。
reg:tweedie:使用对数链接进行Tweedie回归。它可能有用,例如,用于建模保险的总损失,或用于可能是Tweedie分布的任何结果。
base_score [默认值= 0.5]
所有实例的初始预测得分,全局偏差
对于足够的迭代次数,更改此值不会有太大影响。
eval_metric [根据目标默认]
验证数据的评估指标,将根据目标分配默认指标(用于回归的均方根值,用于分类的对数损失,用于排名的平均平均精度)
用户可以添加多个评估指标。Python用户:记住将指标作为参数对的列表而不是映射进行传递,以使后者eval_metric不会覆盖前一个
下面列出了这些选择:
- rmse:均方根误差
-
rmsle:均方根对数误差

reg:squaredlogerror目标的默认指标。此指标可减少数据集中异常值所产生的错误。但是由于log采用功能,rmsle可能nan在预测值小于-1时输出。有关reg:squaredlogerror其他要求,请参见。
- mae:平均绝对误差
- mape:平均绝对百分比误差
- mphe:平均伪Huber错误。reg:pseudohubererror目标的默认指标。
- logloss:负对数似然
- error:二进制分类错误率。计算公式为。对于预测,评估会将预测值大于0.5的实例视为肯定实例,而将其他实例视为否定实例。#(wrong cases)/#(all cases)
- error@t:可以通过提供't'的数值来指定不同于0.5的二进制分类阈值。
- merror:多类分类错误率。计算公式为。#(wrong cases)/#(all cases)
- mlogloss:多类logloss。
- auc:曲线下面积
- aucpr:PR曲线下的面积
- ndcg:归一化累计折扣
- map:平均平均精度
- ndcg@n,map@n:'n'可以被指定为整数,以切断列表中的最高位置以进行评估。
- ndcg-,map-,ndcg@n-,map@n-:在XGBoost,NDCG和MAP将评估清单的比分没有任何阳性样品为1加入-在评价指标XGBoost将评估这些得分为0,是在一定条件下一致""。
- poisson-nloglik:泊松回归的负对数似然
- gamma-nloglik:伽马回归的对数似然比为负
- cox-nloglik:Cox比例风险回归的负对数似然率
- gamma-deviance:伽马回归的剩余偏差
- tweedie-nloglik:Tweedie回归的负对数似然(在tweedie_variance_power参数的指定值处)
- aft-nloglik:加速故障时间模型的负对数可能性。有关详细信息,请参见具有加速故障时间的生存分析。
-
interval-regression-accuracy:其预测标签位于间隔检查的标签中的数据点的分数。仅适用于间隔检查的数据。有关详细信息,请参见具有加速故障时间的生存分析。
五、命令行参数
以下参数仅在XGBoost的控制台版本中使用
num_round
提升轮数
data
训练数据的路径
test:data
测试数据进行预测的路径
save_period [默认= 0]
保存模型的时间段。设置save_period=10意味着XGBoost每10轮将保存一个模型。将其设置为0意味着在训练期间不保存任何模型。
task[默认= train]选项:train,pred,eval,dump
- train:使用数据进行训练
- pred:预测测试:数据
- eval:用于评估指定的统计信息 eval[name]=filename
- dump:用于将学习到的模型转储为文本格式
model_in [默认值= NULL]
路径输入模型,需要的test,eval,dump任务。如果在训练中指定了XGBoost,它将从输入模型继续训练。
model_out [默认值= NULL]
训练完成后输出模型的路径。如果未指定,则XGBoost将输出名称为0003.model ,其中0003
model_dir[默认= models/]
训练期间保存的模型的输出目录
fmap
特征图,用于转储模型
dump_format[default = text]选项:text,json
模型转储文件的格式
name_dump[默认= dump.txt]
模型转储文件的名称
name_pred[默认= pred.txt]
预测文件的名称,在pred模式下使用
pred_margin [默认= 0]
预测margin 而不是转换概率
六、代码主要函数:
载入数据:load_digits()
数据拆分:train_test_split()
建立模型:XGBClassifier()
模型训练:fit()
模型预测:predict()
性能度量:accuracy_score()
特征重要性:plot_importance()
七、参数调整注意事项
控制过度拟合:
当您观察到较高的训练准确度但较低的测试准确度时,很可能遇到了过拟合问题。
通常,您可以通过两种方法控制XGBoost中的过拟合:
第一种方法是直接控制模型的复杂性。
这包括max_depth,min_child_weight和gamma。
第二种方法是增加随机性,以使训练对噪声具有鲁棒性。
这包括subsample和colsample_bytree。
您还可以减小学习率 eta,同时增加num_round。
更快的训练表现
有一个名为的参数tree_method,请将其设置为hist或gpu_hist以加快计算速度。
处理不平衡的数据集
对于广告点击日志等常见情况,数据集极不平衡。这可能会影响XGBoost模型的训练,有两种方法可以对其进行改进。
如果您只关心预测的整体效果指标(AUC)
- 通过 scale_pos_weight调整正例和负例的比例
- 使用AUC进行评估
如果您关心预测正确的可能性
- 在这种情况下,您无法重新平衡数据集
- 将参数设置max_delta_step为有限数(例如1)以帮助收敛
更多信息,强烈推荐:
https://xgboost.readthedocs.io/en/latest/python/python_api.html#module-xgboost.training

 浙公网安备 33010602011771号
浙公网安备 33010602011771号