【NLP-2019】解读BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
目录
- 研究背景
- 论文思路
- 实现方式细节
- 实验结果
- 附件
专业术语列表
一、研究背景
1.1 涉及领域,前人工作等
本文主要涉及NLP的一种语言模型,之前已经出现了【1】ELMo和【2】GPT这些较为强大的模型,ELMo 的特征提取器不是很先进,GPT没有使用双向,本文结合两者的思想或做法,大大提升了最终效果。
1.2 中心思想
本文在前人研究基础上,沿用了pre-train和fine-tuning结构。使用双向transformer结构(不同于ELMO的双向,而是"掩蔽语言模型"(MLM)),并加入Next Sentence Prediction(NSP),在11个自然语言处理任务上获得了新的最先进的结果。
二、论文思路
2.1 框架图和重要部分
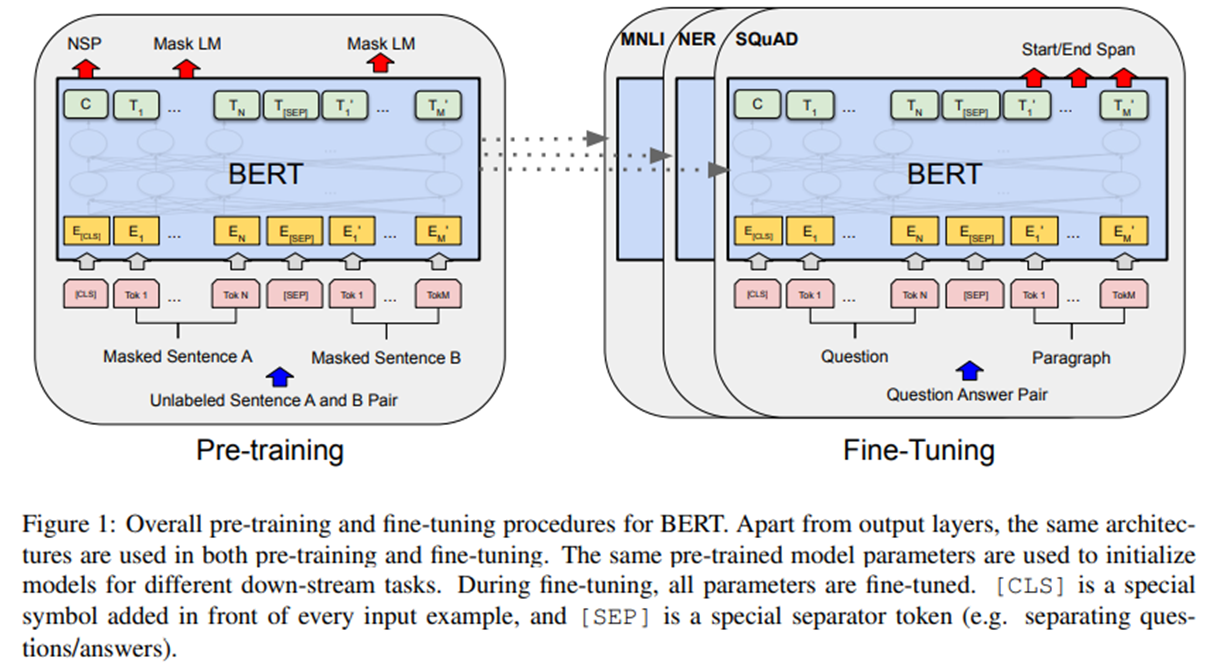
主要组成构建有:pre-training:Embedding、Masked LM、Next Sentence Prediction 和 fine-tuning
2.2 论文技术特点(对比文献)
创新点有:
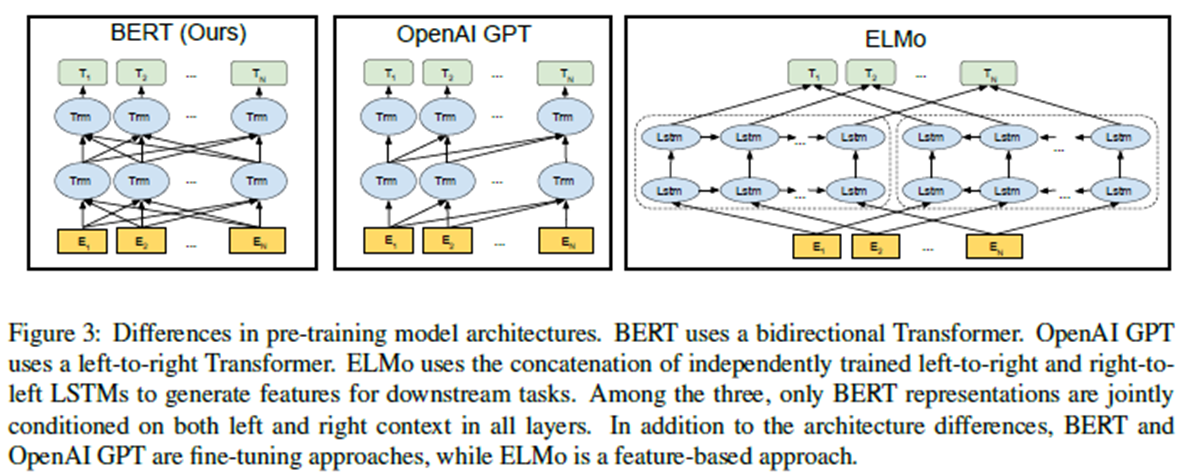
- 与GPT比较,使用了双向(GPT只用了单向结构)
- 与ELMo比较,使用了更强的提取器:transformer,而且由于它的双向——使用了独立训练的从左到右和从右到左的LMs的浅连接。
论文中做种与GPT进行了对比,BERT和GPT的培训方式还有其他一些不同之处:
- GPT在BooksCorpus上训练(800M单词);BERT被训练成书虫维基百科(2500万字)。
- GPT使用一个句子分隔符([SEP])和分类器标记([CLS]),它们只在微调时引入;BERT在在预处理时,学习[SEP], [CLS]和A/B嵌入。
- GPT训练1M步,批处理32000字;BERT被训练1M步,批处理大小为12.8万字。
- GPT对所有微调实验使用5e-5相同的学习率;BERT选择特定于任务的微调学习率,该学习率在开发集上执行得最好。
为了分离这些差异的影响,我们在5.1节中进行了消融实验,实验表明大部分的改善实际上来自于两个训练前的任务和它们所带来的双向性。
三、实现方式细节
如上图所示:我们的框架中有两个步骤:预训练和微调(pre-training and fine-tuning)。在预训练,对不同预训练任务的未标记数据进行训练。对于fine tuning,首先使用预先训练的参数初始化BERT模型,然后使用来自下游任务的标记数据对所有参数进行微调。每个下游任务都有单独的经过调优的模型
Model Architecture
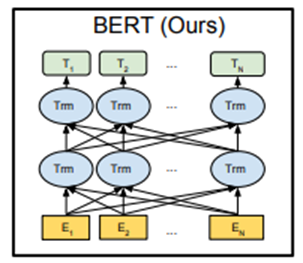
BERT提供了简单和复杂两个模型,对应的超参数分别如下(论文中也证明了large版本的作用):
BERT-base : L=12,H=768,A=12,参数总量110M;(与GPT持平)
BERT-large: L=24,H=1024,A=16,参数总量340M;
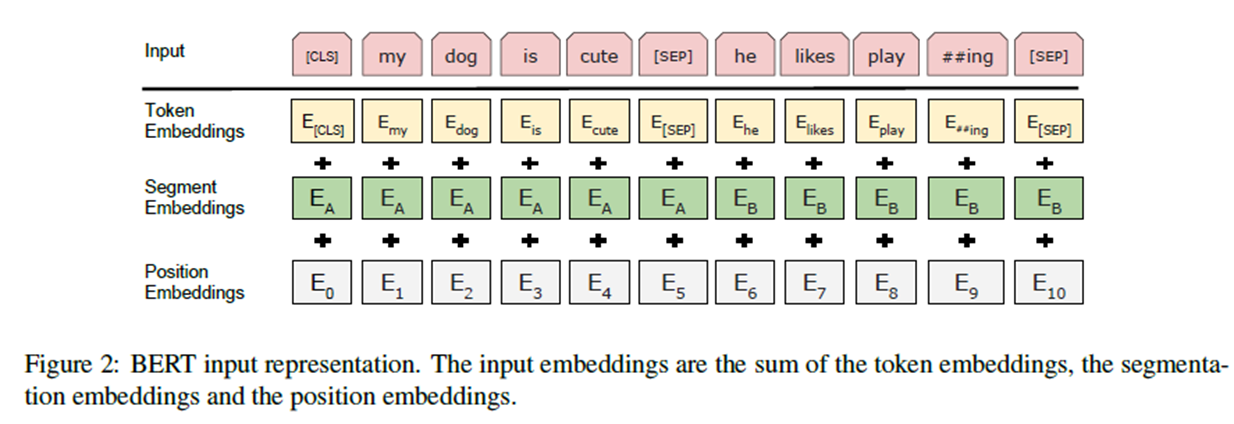
[CLS]:每个序列的第一个标记总是一个特殊的分类标记()。
[SEP] 把句子分开。
对于给定的token,它的输入表示是通过对相应的token、段和位置嵌入求和来构造的。图2显示了这种构造。
3.1 Pre-training BERT
Task #1: Masked LM
因为双向条件作用将允许每个单词间接地 "看自己",这个模型可以在多层次的语境中对目标词进行简单的预测。
为了训练一个深层的双向表示,我们简单地随机屏蔽一些输入标记的百分比,然后预测那些屏蔽的标记。我们把这个过程称
"maskedLM" (MLM), 类似完形填空。在这种情况下,掩码标记对应的最终隐藏向量通过词汇表被输入到输出softmax中,就像在标准LM中一样。在我们所有的实验中,我们在每个序列中随机屏蔽15%的单词标记。与去噪自动编码器相比【9】,我们只预测蒙面文字,而不是重建整个输入。
虽然这允许我们获得双向的预训练模型,但缺点是我们在预训练和微调之间产生了不匹配,因为在微调期间没有出现[MASK]token。为了缓和这种情况,我们并不总是用实际的词来代替"屏蔽"的词 (面具)token。训练数据生成器随机选择token位置的15%进行预测。
- 80%是采用[mask],my dog is hairy → my dog is [MASK]
- 10%是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
- 10%保持不变,my dog is hairy -> my dog is hairy
Task #2: Next Sentence Prediction (NSP)
许多重要的下游任务,如问题回答(QA)和自然语言推理(NLI)是基于对两个句子之间关系的理解,这不是语言建模直接捕捉的。为了训练一个理解句子关系的模型,我们对一个可以从任何单语语料库中生成的二值化下一个句子预测任务进行了预训练。具体来说,在为每个训练前示例选择句子A和B时,50%的时间B是A后面的实际下一个句子(标记为IsNext), 50%的时间它是从语料库中随机选择的句子(标记为NotNext).如图1所示,C用于下一个句子预测 (NSP)。尽管它很简单,但我们在5.1节中证明了针对这项任务的预培训对QA和NLI都是非常有益的。(如果不进行微调,向量C就不是一个有意义的句子表示,因为它是用NSP训练的。)
在以前的工作中,只有语句嵌入被传输到下游任务中,BERT传输所有参数来初始化最终任务模型参数。
论文第五章阐述了NSP的重要性,尤其是一些特定的任务。
3.2 Fine-tuning BERT
自关注机制在transformer允许 BERT通过交换出适当的输入和输出,为许多下游任务建模。 对于涉及文本对的应用程序,一个常见的模式是在应用双向交叉注意之前对文本对进行独立编码,例如:Parikh et al. (2016); Seo et al. (2017).BERT使用了self-attention机制来统一这两个阶段,因为self-attention编码包含了两个句子之间的双向交叉注意。
与培训前相比,微调成本相对较低。论文中的所有结果可以在最多1小时内在一个云TPU,或者GPU上的几个小时,从完全相同的预训练模型开始 。
四、实验结果
4.1 GLUE
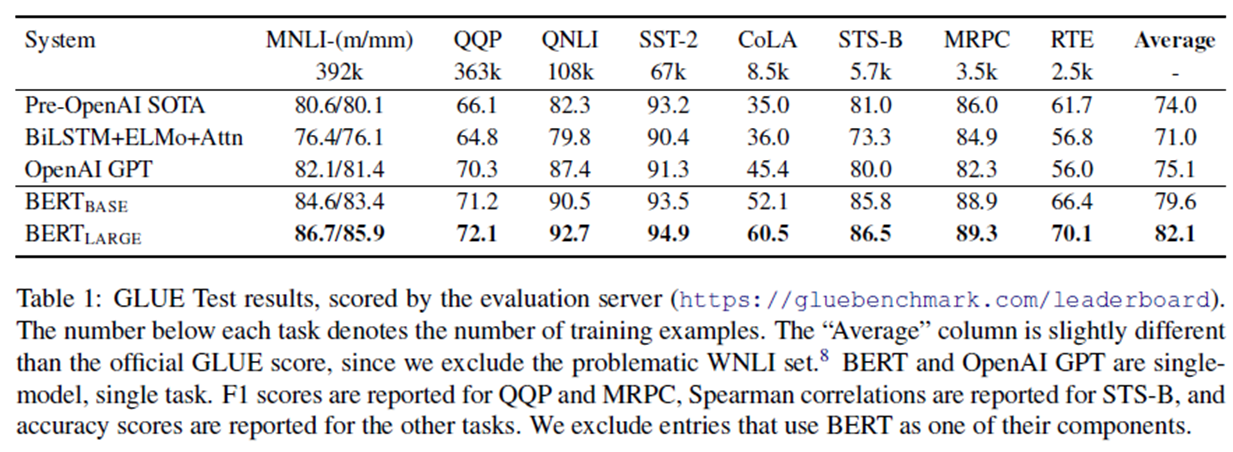
结果见表1。我们发现,BERT_LARGE的表现明显优于其他公司BERT_BASE遍历所有任务,特别是那些训练数据很少的任务。模型大小的影响在5.2节中进行了更深入的探讨。
4.2 SQuAD v1.1
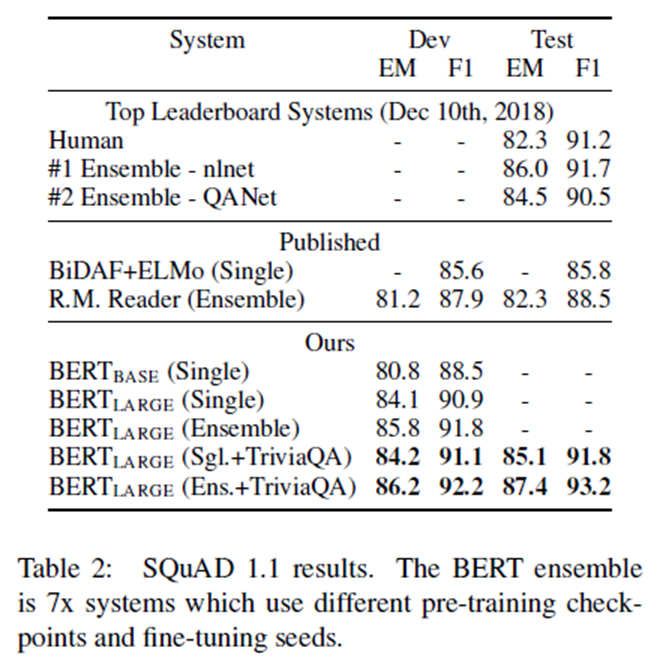
表2显示了顶级排行榜条目以及来自顶级发布系统的结果(Seo et al.,2017; Clark and Gardner, 2018;【1】 Peters et al.,2018a; Hu et al., 2018).我们最好的表现系统表现超过顶级排行榜系统+1.5 F1在集成和 +1.3 F1作为一个单一的系统。事实上,我们的单一BERT模型在F1得分上优于顶级集成系统。除了TriviaQA我们只损失了0.1-0.4 F1,仍然远远超过了所有现有的系统。
SQuAD v2.0、SWAG都有较好表现。
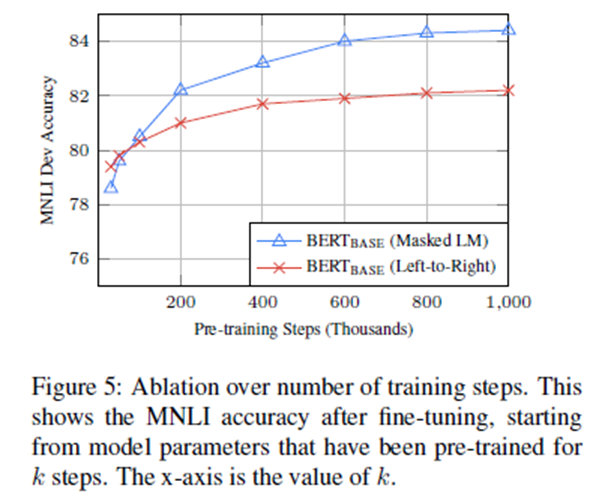
图5展示了MNLI开发在经过k步预训练的检查点进行微调后的准确性。这使我们能够回答以下问题:
1. 问:BERT真的需要如此大量的预训练(128,000 words/batch * 1,000,000 steps)来达到很高的微调精度吗?
答:是的,BERT_BASE几乎做到了与500k步训练相比,MNLI在1M步训练时的准确度提高了1.0%。
2 问:MLM预训是否比LTR预训收敛慢,因为每批预训中只有15%的单词是预测的,而不是每个单词?
答:MLM模式确实比LTR模式收敛稍微慢一些。然而,在绝对准确性方面,MLM模式几乎立即开始超越LTR模式。
五、附件
5.1 Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of
deep bidirectional transformers for language understanding. In NAACL, pages 4171–4186.
5.2 Github 地址: https://github.com/google-research/bert
5.3 GLUE基准包括以下数据集,这些数据集的描述最初在【8】Wang et al. (2018a):
MNLI多流派自然语言推断是一项大规模、众包的隐含分类任务(【5】Williams et al., 2018)。给定一对句子,目标是预测第二个句子相对于第一个句子是暗含的、矛盾的还是中性的。
QQP Quora问题对是一个二元分类任务,目标是确定两个问题在Quora上是语义上等价的(Chen et al., 2018)。
QNLI问题自然语言推理是斯坦福大学问题回答的一个版本数据集【6】(Rajpurkar et al., 2016)已经转换为一个二元分类任务(Wang et al., 2018a)。积极的例子是(问题,句子)对包含正确的答案,和消极的例子是(问题,句子)从同一段不包含答案。
SST-2斯坦福情绪树形库是一个二元单句分类任务,由从电影评论中提取的句子和人类对其情绪的注释组成(Socher et al., 2013)。
CoLA:语言可接受性语料库是一个二元单句分类任务,其目标是预测一个英语句子在语言上是否"可接受"(Warstadt et al., 2018)。
STS-B语义文本相似性基准是一组从新闻标题和其他来源(Cer et al.,2017)。他们用1到5的分数来标注这两个句子在语义上的相似程度。
MRPC微软研究释义语料库(MRPC Microsoft Research ase Corpus)由自动从在线新闻源提取的句子对组成,并通过人工注释判断句子在语义上是否相同(Dolan and Brockett, 2005)。
RTE识别文本蕴涵是一个与MNLI类似的二元隐含任务,但是使用的训练数据要少得多(Bentivogli et al., 2009)。
WNLI:Winograd NLI是一个小型的自然语言推理数据集(Levesque et al., 2011)。GLUE页面注意到这个数据集的构造存在一些问题,每一个被提交到GLUE的训练过的系统都比预测多数类的65.1基线准确度要差。因此,我们排除这个集合以保证OpenAI GPT的公平性。为我们的GLUE提交,
参考文献
【0-1】本英文地址:https://arxiv.org/abs/1810.04805
【1】Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018a. Deep contextualized word representations. In NAACL. --ELMo
【2】Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding with unsupervised learning. Technical report, OpenAI. (Improving Language Understanding by Generative Pre-Training 大部分上面是这个标题) --GPT
【3】Andrew M Dai and Quoc V Le. 2015. Semi-supervised sequence learning. In Advances in neural information processing systems, pages 3079–3087.
【4】Jeremy Howard and Sebastian Ruder. 2018. Universal language model fine-tuning for text classification. In ACL. Association for Computational Linguistics.
【5】Adina Williams, Nikita Nangia, and Samuel R Bowman. 2018. A broad-coverage challenge corpus for sentence understanding through inference. In NAACL.
【6】Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392. --4次
【7】Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, pages 6000–6010. --transformer
【8】Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018a.Glue: A multi-task benchmark and analysis platform
【9】Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol. 2008. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th international conference on Machine learning, pages 1096–1103. ACM

