【NLP-2017】解读Transformer--Attention is All You Need
目录
- 研究背景
- 论文思路
- 实现方式细节
- 实验结果
- 附件
专业术语列表
一、研究背景
1.1 涉及领域,前人工作等
本文主要处理语言模型任务,将Attention机制性能发挥出来,对比RNN,LSTM,GRU,Gated Recurrent Neural Networks 在序列建模和转换任务上的应用,摈弃这些计算串行的缺点,另外针对一些研究中长依赖不足的问题;
例如:端到端的记忆网络使用循环attention机制替代序列对齐的循环,在简单的语言问答和语言建模任务中表现良好。
1.2 中心思想
总的来说该模型主要解决并行和长依赖两个当前没有融合的问题。在attention基础上创新,加入self-attention,Multi-Head Attention,FFN层,位置编码层。
- 靠attention机制,不使用rnn和cnn,并行度高
- 通过attention,抓长距离依赖关系比rnn强
Position-wise Feed-Forward Networks(基于位置的前馈神经网络)和 Positional Encoding(位置编码)等技术。最后在实验效果上达到当时最好。
二、论文思路
2.1 框架图和重要部分
文章主要框架图
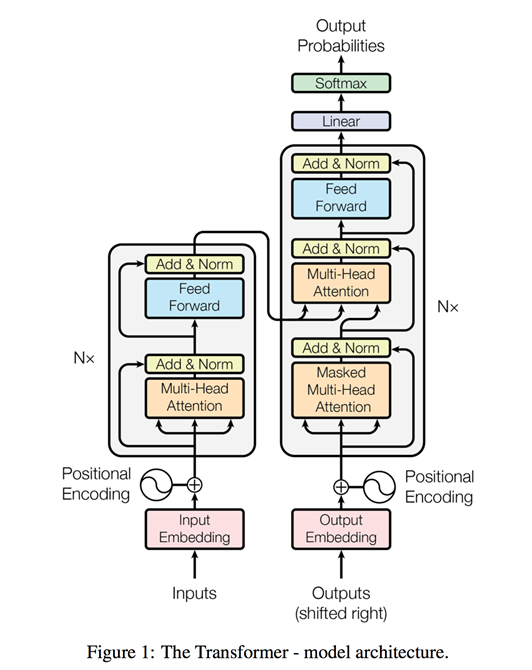
主要组成构建有:
堆叠的self-attention层、point-wise和全连接层,分别用于encoder和decoder
2.2 论文技术特点(对比文献)
创新点有:
- Extended Neural GPU [16],ByteNet[18],和ConvS2S[9]:使用卷积神经网络,无长语句获取能力;
- 因子分解技巧[21]和条件计算[32]:在计算效率方面取得了显著的提高,同时也提高了后者的模型性能。然而,顺序计算的基本约束仍然存在。也就是并行计算无法实现,再计算和模型搭建时间上是很大瓶颈;
- [27] 注意机制与一个递归网络结合使用,依然是并行计算问题;
通过self-attention,自己和自己做attention,使得每个词都有全局的语义信息(长依赖由于 Self-Attention 是每个词和所有词都要计算 Attention,所以不管他们中间有多长距离,最大的路径长度也都只是 1。可以捕获长距离依赖关系
提出multi-head attention,可以看成attention的ensemble版本,不同head学习不同的子空间语义。
不过觉得:encoder-decoder attention: 模仿seq2seq模型的注意力机制
三、实现方式细节
3.1 Encoder and Decoder Stacks(编码器栈和解码器栈)
Encoder:encoder由N(N=6)个完全相同的layer堆叠而成.每层有两个子层:
第一层是multi-head self-attention机制;

Decoder: decoder也由N(N=6)个完全相同的layer堆叠而成.除了每个编码器层中的两个子层之外,解码器还插入第三个子层,该子层对编码器堆栈的输出执行multi-head attention操作,与encoder相似,我们在每个子层的后面使用了残差连接,之后采用了layer normalization。
3.2 Attention(注意力机制)
Attention机制可以描述为将一个query和一组key-value对映射到一个输出,其中query,keys,values和输出均是向量。输出是values的加权求和,其中每个value的权重 通过query与相应key的兼容函数来计算。本节将介绍各种变形的attention。
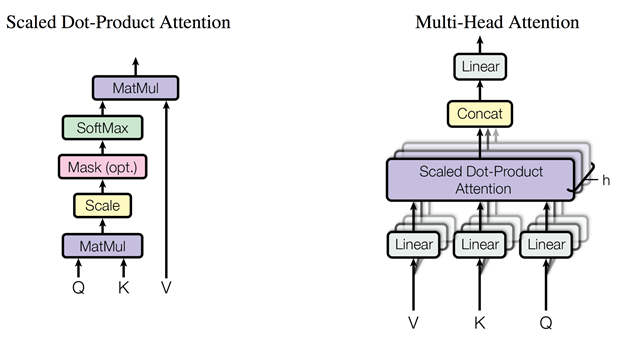
Figure 2: (left) Scaled Dot-Product Attention. (right) Multi-Head Attention consists of several attention layers running in parallel.
3.2.1 Scaled Dot-Product Attention(缩放的点积注意力机制)

本文attention公式如上所示,和dot-product attention除了没有使用缩放因子,其他和这个一样。
additive attention和dot-product(multi-plicative) attention是最常用的两个attention 函数。为何选择上面的呢?主要为了提升效率,兼顾性能。
效率:在实践中dot-product attention要快得多,而且空间效率更高。这是因为它可以使用高度优化的矩阵乘法代码来实现。
性能:较小时,这两种方法性能表现的相近,当比较大时,addtitive attention表现优于 dot-product attention(点积在数量级上增长的幅度大,将softmax函数推向具有极小梯度的区域 )。所以加上因子拉平性能。
3.2.2 Multi-Head Attention(多头注意力机制)
用multi-headed self-attention取代了encoder-decoder架构中最常用的recurrent layers。这是非常重大的创新点。如 Figure 2 中所示。Multi-head attention允许模型把不同位置子序列的表示都整合到一个信息中。如果只有一个attention head,它的平均值会削弱这个信息。
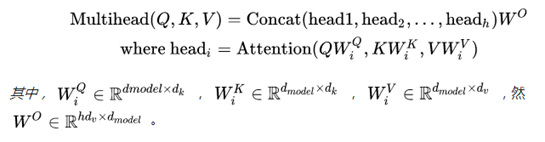
在这项工作中,我们采用h=8 个并行attention层或head。
3.2.3 Applications of Attention in our Model(注意力机制在我们模型中的应用)
multi-head attention在Transformer中有三种不同的使用方式:
- encoder-decoder attention: 模仿seq2seq模型的注意力机制
- encoder 的 self-attention layer
- decoder 的self-attention layer:和上面的区别就是加了masking
3.2.4 self- attention
激励我们使用self-attention的原因,主要是以下三个:
- 一个是每层的总计算复杂度。
- 另一个是可以并行化的计算,通过所需的最小顺序操作数来衡量。
- 第三个是网络中远程依赖之间的路径长度。学习远程依赖性是许多序列转换任务中的关键挑战。影响学习这种依赖性的能力的一个关键因素是前向和后向信号必须在网络中传播的路径的长度。输入和输出序列中任何位置组合之间的这些路径越短,学习远程依赖性就越容易。因此,我们还比较了由不同类型层组成的网络中任意两个输入和输出位置之间的最大路径长度。
注意:这一节对应论文的第4章。
3.3 位置前馈网络
除了attention子层之外,编码器和解码器中的每个层都包含一个完全连接的前馈网络,该网络分别相同地应用于每个位置。 该前馈网络包括两个线性变换,并在第一个的最后使用ReLU激活函数。
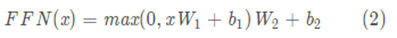
不同position的FFN是一样的,但是不同层是不同的。

3.4 词嵌入和softmax

3.5 位置编码

在这项工作中,我们使用不同频率的正弦和余弦函数:
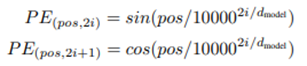
其中pos是指当前词在句子中的位置,i是指向量中每个值的维度,位置编码的每个维度对应于正弦曲线。我们选择了这个函数,因为我们假设它允许模型容易地学习相对位置。
作者测试用学习的方法来得到PE,最终发现效果差不多,所以最后用的是fixed的,而且sinusoidal的可以处理更长的sequence的情况。用sinusoidal函数的另一个好处是可以用前面位置的值线性表示后面的位置。

四、实验结果
4.1 Machine Translation(机器翻译)
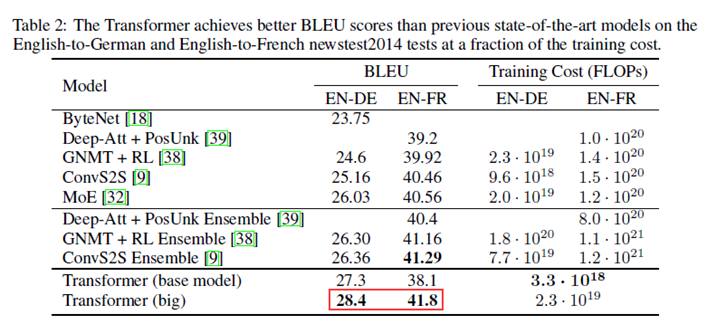
在WMT 2014英语-德语翻译任务中,大型Transformer模型(表2中的Transformer (big))比以前报道的最佳模型(包括整合模型)高出2个以上的BLEU评分,以28.4分建立了一个全新的SOTA BLEU分数。
4.2 English Constituency Parsing(英文选区分析)

表4中我们的结果表明,尽管缺少特定任务的调优,我们的模型表现得非常好,得到的结果比之前报告的Recurrent Neural Network Grammar [8]之外的所有模型都好。
五、附件
5.1 论文引用地址:Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin:Attention is All you Need. NIPS 2017: 5998-6008
5.2 官网代码:https://github.com/tensorflow/tensor2tensor
参考文献
【1】英文论文:https://arxiv.org/abs/1706.03762
【2】中文译文: https://blog.csdn.net/nocml/article/details/103082600
【3】带注释的transformer: http://nlp.seas.harvard.edu/2018/04/03/attention.html
【4】论文中用到的参考文献(编号未变)
[9] Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, and Yann N. Dauphin. Convolutional
sequence to sequence learning. arXiv preprint arXiv:1705.03122v2, 2017.
[16] Łukasz Kaiser and Samy Bengio. Can active memory replace attention? In Advances in Neural
Information Processing Systems, (NIPS), 2016.
[18] Nal Kalchbrenner, Lasse Espeholt, Karen Simonyan, Aaron van den Oord, Alex Graves, and Koray
Kavukcuoglu. Neural machine translation in linear time. arXiv preprint arXiv:1610.10099v2,
2017.
[21] Oleksii Kuchaiev and Boris Ginsburg. Factorization tricks for LSTM networks. arXiv preprint
arXiv:1703.10722, 2017.
[27] Ankur Parikh, Oscar Täckström, Dipanjan Das, and Jakob Uszkoreit. A decomposable attention
model. In Empirical Methods in Natural Language Processing, 2016.
[32] Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton,
and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts
layer. arXiv preprint arXiv:1701.06538, 2017.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号