【NLP-2019-SA】翻译A Unified Model for Opinion Target Extraction and Target Sentiment Prediction(AAAI)
摘要
基于目标的情感分析包括意见目标提取和目标情感分类。然而,现有的研究大多是单独研究这两个子任务中的一个子任务,这阻碍了它们的实际应用。本文旨在以端到端的方式解决基于目标的情感分析的完整任务,提出了一种采用统一标注方案的统一模型。我们的框架包括两个叠层递归神经网络:上一个预测统一标签,产生基于主目标的情感分析的最终输出结果;下一个执行辅助目标边界预测,旨在指导上一个网络提高主任务的性能。为了探索任务间的依赖关系,我们提出了明确的模型,从目标边界到目标情感极性的约束过渡。我们还提出通过一个门机制来保持意见目标内的情感一致性,该门机制模拟当前词和之前词的特征之间的关系。我们在三个基准数据集上进行了广泛的实验,我们的框架取得了一致的优异结果。
Introduction
基于目标的情绪分析(Target-Based Sentiment Analysis (TBSA) )旨在检测句子中明确提到的意见目标,并预测意见目标的情绪极性(Liu 2012;Pontiki 2014)。例如,在"USB3外设的价格明显低于ThunderBolt外设"一句中,用户提到了两个意见目标,即"USB3外设"和"ThunderBolt外设",并对第一个表达了正面情绪,对第二个表达了负面情绪。传统上,该任务可以分为两个子任务,即意见目标提取和目标情感分类。意见目标提取的目的是检测文本中提到的意见目标,并且已经得到了广泛的研究(Qiu et al. 2011; Liu, Xu, and Zhao 2013;Liu, Xu, and Zhao 2014; Liu, Joty, and Meng 2015; Yin et al. 2016; Wang et al. 2016a; Wang et al. 2017; He et al. 2017; Li and Lam 2017; Li et al. 2018b; Xu et al. 2018). 。第二个子任务,即目标情绪分类,可以预测给定意见目标的情绪极性,从而提高提取的目标提及的有用性。这一子任务近年来也受到了很多关注(Dong et al. 2014; Tang, Qin, and Liu 2016; Wang et al. 2016b; Ma et al. 2017; Chen et al. 2017; Tay, Luu, and Hui 2017; Ma, Peng, and Cambria 2018; Hazarika et al. 2018; Li et al. 2018a; Wang et al. 2018; Xue and Li 2018; He et al. 2018; Li et al. 2019).。然而,现有的解决第二个子任务的方法大多假设目标提及是给定的,这限制了它们的实际应用。综上所述,以上工作只针对其中一个子任务进行求解。为了将现有的方法应用到实际环境中,即不仅提取目标,而且预测目标情绪,一种典型的方法是将两个子任务的方法串联起来。
如在其他任务中观察到的(Jing et al. 2003; Ng and Low 2004; Finkel and Manning 2009; Miwa and Sasaki 2014),,如果两个子任务具有强耦合(例如,NER和关系提取),则更集成的模型通常比管道解决方案更有效。对于TBSA任务,先前的研究人员尝试了两种方法来获得更为完整的解决方案 (Mitchell et al. 2013; Zhang, Zhang, and Vo 2015). 。一种方法是将两个子任务的模型联合训练,利用一组目标边界标记(如B,I,e,S和O)和一组情感标记(如POS,NEG,NEU)。表1的"joint"行给出了这种方法中的标记方案示例。另一种方法是完全消除这两个子任务的边界,它使用一组特殊设计的标记(我们称之为"统一标记方案"),即B-{POS,NEG,NEU},I-{POS,NEG,NEU},E-{POS,NEG,NEU},S-{POS,NEG,NEU},用正的、负的词表示观点目标的开始、内部、结束和单个词或者分别是中性情绪,O表示零情绪。表1中的"统一"行给出了一个示例。不幸的是,这些最初的尝试并没有产生一个比流水线方法更好的集成模型。

尽管解决完成任务的重要性仍然很重要,但现有的研究相对较少以及他们的发现(Mitchell等人。2013年;Zhang、Zhang和Vo2015),在某种程度上,阻碍了其他研究人员进行进一步的探索。然而,我们认为应该努力探索一种更完整的模式来解决这项任务,因为它的两个子任务高度耦合在一起,更完整的模式的潜力是有希望的。
本文研究了TBSA的完整任务,并设计了一个新的统一框架来端到端地处理TBSA。该框架包含两层递归神经网络(RNN)。上一个基于统一的标记方案生成TBSA任务的最终标记结果。下一层对目标边界进行辅助预测,目的是引导并向上一层RNN提供信息。这种设计基于这样的观察:在统一的标注方案下,跨度信息与边界标注方案下的跨度信息完全相同。参考表1中的例子,如果一个单词在边界方案下的目标提及的开始处,即具有标签B,那么它也应该在统一方案下的开始处,即具有标签B-POS。为了探索这种方案间的标签依赖性,我们建议用辅助任务的边界预测来指导完成TBSA任务的上RNN预测,与下RNN相对应。具体地说,我们设计了一个组件将依赖项编码成一个转换矩阵,并使用该矩阵将边界预测的概率分布映射到TBSA任务的统一标记空间。然后,我们确定所获得的基于边界的概率得分在标记决策中的比例,并将其与来自上RNN的概率得分合并以进行最终预测。
我们还提出了一个简单的门机制来保持同一目标提及中单个词的情感的一致性。门机制是为了显式地合并当前单词和先前单词的特征而设计的。由于这里的门和上面的转换矩阵都需要进行可靠的边界预测才能很好地执行,因此在较低的RNN中提高这种预测的可靠性对于完成TBSA任务是有用的。因此,我们引入另一个成分来估计一个词成为目标词的可能性。请注意,根据任务(Pontiki 2014;Pontiki 2015;Pontiki 2016)的定义,意见目标应始终与意见词同时出现,因此,接近意见词的词更可能是目标词,我们基于此假设获得了用于细化边界信息的额外监督信号
在实验中,我们的框架在多个基准数据集上都优于最先进的方法和最强的序列标记器。我们进行了详细的烧蚀研究,以定量地证明设计组件的有效性。通过一些案例分析,我们展示了我们的框架如何在设计组件的帮助下处理一些困难的案例。
Our Proposed Framework
任务定义我们将完整的基于目标的情感分析(TBSA)任务定义为一个序列标记问题,并采用统一的标记方案:YS={B-POS,I-POS,E-POS,S-POS,B-NEG,I-NEG,E-NEG,S-NEG,B-NEU,I-NEU,E-NEU,S-NEU,O}。除O外,每个标签包含两部分标签信息:目标提及的边界和目标情感。例如,B-POS表示正面目标提及的开始,S-NEG表示单个单词负面意见目标。对于给定的输入序列X={x1。,xT}使用长度T,我们的目标是预测标记序列 。
模型描述概述如图1所示,在带有LSTM单元的两个堆叠rnn的顶部,我们的框架设计了三个tailormade组件,用标注详细描述,以探索TBSA任务中的三个重要直觉。具体地说,对于完成的TBSA任务,上面的lstm^s预测统一标签作为输出,下面的LSTM^T预测辅助任务,并预测目标提及的边界标签。lstmt的边界预测用于指导lstms通过统一的标签对完成的任务进行更好的预测。这三个关键组件分别是边界引导(BG)组件、情感一致性(SC)组件和观点增强(OE)目标词检测组件。BG组件利用辅助任务提供的边界信息,指导lstms更准确地预测统一标签。SC组件被赋予一个门机制,将前一个词的特征显式地集成到当前预测中,目的是在多个词的意见目标中保持情感的一致性。为了提供更高质量的边界信息,OE组件遵循"意见目标和意见词总是同时出现"的原则,执行另一个辅助的二进制分类任务,以确定当前词是否为目标词。
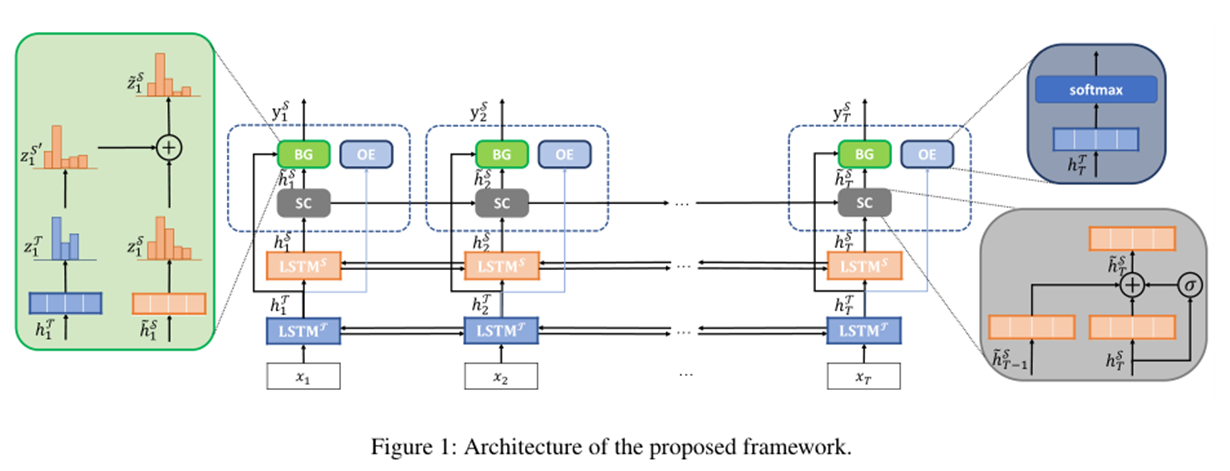
目标边界引导TBSA采用带软max解码层的LSTMS对标签序列进行预测。结果表明,边界标记可以为统一的标记预测提供重要线索。例如,如果当前边界标记是B,表示意见目标的开始,则对应的统一标记只能是B-POS、B-NEG或B-NEU。因此,我们为目标边界预测引入了一个额外的网络LSTM^T,其中有效的标记集Y^T是{B,I,E,S,O}。我们将这两个LSTM层连接起来,使得LSTM^T生成的隐藏表示可以直接作为指导信息输入LSTM^S。具体地说,它们的隐藏表示

的第t时间步(t∈[1,t])计算如下:

如前所述,边界信息被认为有助于提高LSTMS的性能。(Zhang, Zhang, and Vo 2015)通过在CRF模型的解码步骤中添加硬边界约束,将这些边界信息合并。然而,他们的预测结果并不乐观。一个原因是他们的模型采用了一个硬约束,该约束容易传播边界检测任务标记器的错误,从而降低了TBSA标记器的性能。与施加硬约束的方式不同,我们提出的BG组件可以通过边界引导转换来自动吸收边界信息根据目标边界标记器的置信度确定其在最终标记决策中的比例。首先,BG分量将约束编码成转换矩阵Wtr∈R | YT |×| YS |。由于我们事先不知道边界标记和统一标记之间的转移概率,因此我们最初将它们设置为相等,如下所示:
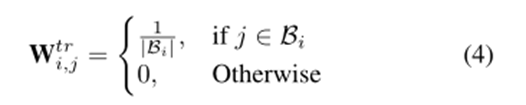

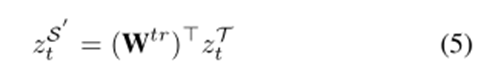
其中,转换操作等效于转换矩阵Wtr中的行向量的线性组合。假设zT=[1,0,0,0,0](即,取标记B),转换的结果正好是行向量Wtr B,:。由于统一标记可以部分地从边界标记中导出,因此一个自然的问题是如何确定基于转换的统一标记分数zS 0 t的比例。直观地说,如果目标边界分数zT接近一致,表明边界标记对它的预测没有信心,则获得的分布在统一的标签,即zS 0 t,也将接近于一个统一的分布,并且对于情绪预测没有什么有意义的信息。为了避免这种非信息性的边界转换,我们基于目标边界的置信度cto计算了比例分数αt∈R-

超参数在哪里?表示基于边界的分数zS 0 t在标记决策中所占的最大比例。显然,如果边界分数是均匀分布的,则CTT将被向下加权。如果zT是一个热向量,则达到最大置信值。最终得分是通过结合基于边界和基于模型的统一标记得分得出的
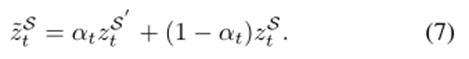
在传统的目标情感分类任务中,为了保持情感的一致性,假设多词观点目标对不同词的情感是相同的。然而,在完整的TBSA任务中,由于任务被描述为序列标记/标签问题,因此这种情绪一致性没有得到保证。以表1中的句子为例,由于LSTMs作出的独立标记决策,"处理器"一词仍有可能被标记为E-NEG标记。为了保持同一意见目标内的情感一致性,我们建议使用当前和之前时间步的特征来预测当前的统一标签。具体地说,我们设计了一个情感一致性(SC)组件和一个门机制来组合这两个特征向量
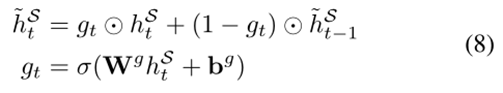
wg和bg是SC组件的可学习参数,以及?表示按元素进行的乘法运算。σ是乙状结肠的函数。通过选通,在当前的预测中考虑了先前的特征,这种间接的双元依赖有助于降低同一目标内的词持有不同情感的概率。
辅助目标词检测 一个好的意见目标边界标记器是产生高质量边界信息的关键。在这里,我们引入了OE组件,从另一个训练数据的角度学习更健壮的边界标记。如(Pontiki 2014;Pontiki 2015;Pontiki 2016)所定义,意见目标总是与意见词搭配在一起。受此启发,如果在固定大小的上下文窗口中至少有一个意见词,则我们将该词视为目标词。然后,我们训练了一个辅助的令牌级分类器,用于识别目标词和非目标词,该分类器基于远程监督的标签和边界表示,并用这些监督信号进一步细化。运行经验组件的计算过程如下
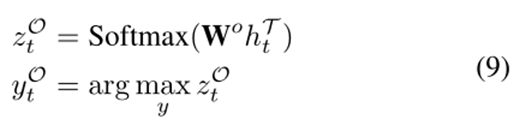
其中wo是模型参数
模型训练
框架中的所有组件都是可微的,因此可以使用基于梯度的方法对整个框架进行有效的训练。采用字/令牌级交叉熵误差作为损失函数:

其中I是任务指示符的符号,其可能值为T、S和O。I(y)表示y分量为1的一个热向量,yI,g T是任务I在时间步骤T时的金标准标记,将主任务和两个辅助任务的损失相加,形成框架的训练目标J(θ):
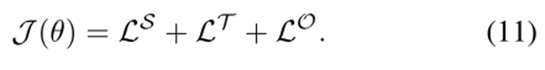
Experiments
Dataset
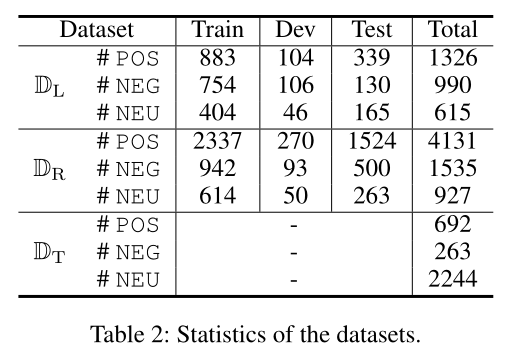
我们的模型基于SemEval ABSA challenges(Pontiki 2014;Pontiki 2015;Pontiki 2016)和Twitter数据集的两个产品评论数据集进行评估。表2给出了这些基准数据集的统计数据。DL(SemEval 2014)包含来自笔记本电脑领域的评论,列车测试拆分与原始数据集相同。DRis 2014、2015和2016年SemEval ABSA challenge餐厅数据集的联合集。通过合并三年的训练数据集,得到新的训练数据集,并用同样的方法建立新的测试集。dt由(Mitchell等人。2013年)。这些数据集提供了意见目标提及的基本事实及其观点。对于DLand-DR,我们以10%随机提供的训练数据作为开发集。对于DT,我们报告十倍交叉验证结果,如中所述(Mitchell et al. 2013; Zhang, Zhang, and V o 2015),因为该数据集没有标准的列车测试划分。金标准边界标注可用于辅助目标边界预测任务。对于另一个辅助任务,即基于意见的目标词检测,我们使用现有的意见词汇1来提供意见词

评估指标基于精确匹配来衡量标准精度(P)、召回率(R)和F1分数,这意味着只有当输出段与目标提及的黄金标准跨度和相应的情绪完全匹配时,才认为输出段是正确的。
比较模型
我们将我们的框架与以下方法进行比较:
•CRF-{管道,连接,统一}(Mitchell等人。2013):基于条件随机字段(CRF)的序列标记2。"管道"表示管道方法。"联合"和"统一"是分别遵循联合标记方案和统一标记方案的模型。
•NN-CRF-{管道、接头、统一}(Zhang、Zhang和V o 2015):增强型CRF模型3,配备字嵌入和神经网络特征提取器。
•HAST TNet:HAST(Li等人。2018b)和TNet(Li等人。2018a)分别是目标边界检测和目标情感分类任务的最新模型。HAST-TNet是这两种模型的管道方法。我们使用官方发布的代码4来生成结果。
•LSTM统一:采用统一标签方案的标准LSTM模型。•LSTM-CRF-1(Lample等人。2016):LSTM模型,带CRF解码层,不需要特征工程。我们运行officelyreleasedcode5并使用统一的标记集来重现结果。
•LSTM-CRF-2(Ma和Hovy 2016):LSTM-CRF-2类似于LSTM-CRF-1。区别在于LSTMCRF-2使用CNN而不是LSTM来学习字符级的单词表示。我们运行发布的代码6来重现结果。
•LM-LSTM-CRF(Liu等人。2018):语言模型增强LSTM-CRF模型。这是一个竞争模型在几个序列标记任务。我们重新运行他们的代码7并报告基于统一标记方案的标记结果
结果与分析
主要结果表3给出了我们与完成TBSA任务的其他方法的比较。为了使比较公平,我们使用GloVe.840B.300d作为所有需要在所有数据集上嵌入单词的基线的预训练单词嵌入。此外,我们对所有方法的train/dev/test配置进行了调整。实验结果表明,我们提出的框架在所有数据集上都给出了最佳的F1分数,并且在大多数情况下显著优于最强的基线。与现有两种模型的流水线HAST-TNet相比,我们提出的框架在DL、dra和dt上分别获得了2.6%、2.4%和0.40%的绝对增益,表明精心设计的集成模型比流水线方法在TBSA任务上更有效。比较研究中还引入了三个竞争性的统一序列标签(见表3中的第三块)。同样,我们的框架在基准数据集上的性能比最好的分别高出1.7%、3.4%和0.5%。我们注意到,与统一的基线相比,我们在Twitter数据集上的框架改进是微不足道的。这个小差距是合理的,因为这些模型使用了额外的组件(例如,LSTM或CNN)来学习字符级的单词表示,其表示词汇外单词的能力已在(Santos和Zadrozny 2014;Kim et al。2016),而我们的框架只使用了预先训练的单词嵌入提供的单词级特性。在与HAST-TNet的比较中也获得了类似的观察结果。我们将此归因于CNN在TNet中处理不符合语法的句子(如tweets和microblog)时的卓越建模能力,如(Li et al。2018a)。我们还注意到基于CRF的模型的性能,特别是召回率(R)得分,非常差。采用预训练的词嵌入和神经网络特征提取技术,对模型进行了改进,但分数仍不理想。
为了考察所设计部件的有效性,我们对所提出的框架进行了烧蚀研究,结果见表3的最后一个部分。让我们从基本模型开始讨论,即堆叠的LSTMs。我们发现,与LSTM统一模型相比,基本模型总是具有更好的性能。这一结果表明,辅助LSTM预测的边界信息确实提高了TBSA任务的F1分。在BG组件的帮助下,性能得到了更显著的改善,并且我们施加边界约束的方法被证明是有效的,可以产生更多的真正数。另一个有趣的发现是,将组件SC或OE单独引入"基础模型+BG"在F1测量上并没有带来太多的收益,甚至损害了DR的预测性能,但将它们组合在一起,即"完整模型",会产生最新的最新结果。这一结果说明了边界引导TBSA中SC和OE分量的必要性。考虑到"基模型+BG+SC",如果没有OE分量的线索,边界信息的质量可能不准确,因此SC分量往往会错误地对齐目标词和非目标词的情感。对于"基模型+BG+OE",lstmt得到的边界信息的质量有所提高,但同一目标内的词的情感与SC分量的"全模型"并不完全一致。综上所述,SC组件和OE组件添加到边界引导的"基本模型+BG"中,在一定程度上是互补的。
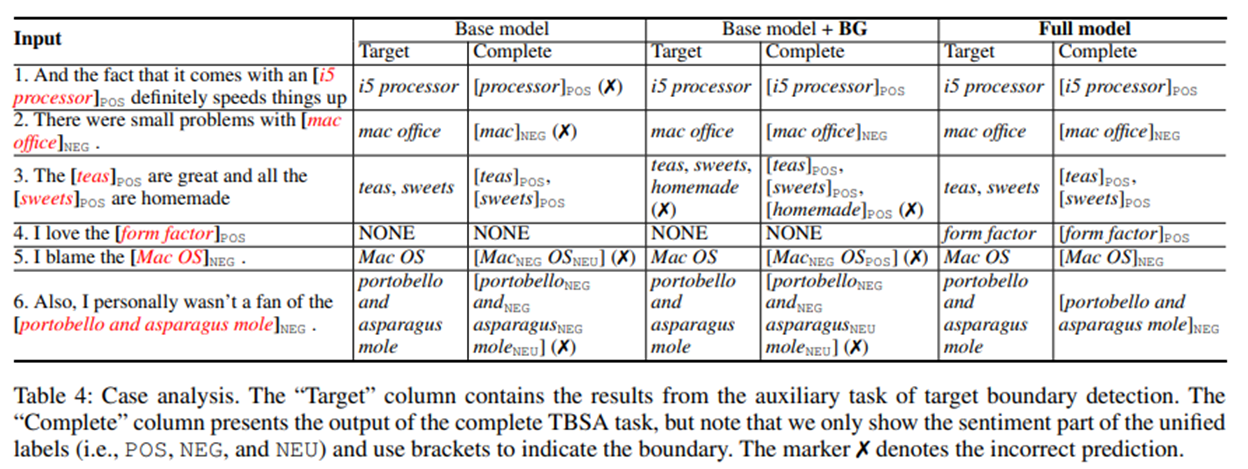
案例分析表4给出了一些基本模型(即堆叠的LSTMs)和模型的预测示例。正如在第一次输入和第二次输入中观察到的,"基本模型"正确地预测了目标边界,但未能产生正确的目标情绪,这表明将两个用于目标边界预测的LSTMs与TBSA任务相连接仍然不足以利用边界信息来提高目标边界预测的性能完整的TBSA。"基本模型+BG"和"完整模型"通过BG组件适当地施加边界约束,可以正确地处理这两种情况。虽然边界信息可以指导模型更准确地预测情绪,但有可能仅使用BG组件(即"基本模型+BG")继承来自下边界检测任务(例如第三和第四输入)的错误。因此,高质量的边界信息对于改进上TBSA任务至关重要,我们的OE组件可以作为一个简单而有效的解决方案。此外,我们发现,在同一目标提及范围内保持情绪一致性,尤其是在最后一个输入中有几个词的人(如"portobello and asparagus mole"),对于"基本模型"和"基本模型+BG"来说是困难的,而我们的"完整模型"通过使用SC组件根据当前和上一个时间步的特征进行预测来缓解这个问题影响?在这里,我们调查最大比例的影响?基于边界的分数和窗口大小对预测性能的影响。具体来说,实验是在最大的基准数据集DR的开发集上进行的。我们各不相同?从0.3增加到0.7,增加0.1,还包括两个极值0.0和1.0。窗口大小的范围是1到5。根据图2给出的结果,我们观察到最佳结果是在?=0.5。这个?在最终的标注决策中,值基本上影响了来自BG分量的情感得分的重要性,0.5是吸收边界信息和消除噪声之间的一个很好的折衷。我们还观察到,对于TBSA任务来说,中等的s值(即s=3)是最好的,这可能是因为太大的s可能会强制模型去处理较大的
Related Works
如引言所述,基于目标的情感分析通常分为两个子任务,即意见目标提取任务(OTE)和目标情感分类任务(TSC)。尽管这两个子任务被视为单独的任务,并且在大多数情况下是单独解决的,但是对于更实际的应用,它们应该在一个框架中解决。给定一个输入语句,一个方法的输出不仅要包含提取的意见目标,还要包含对其的情绪预测。以往的一些工作试图发现这两个子任务之间的关系,并为解决完整的TBSA任务提供了一个更加完整的解决方案。具体来说,(Mitchell et al. 2013)使用条件随机场(CRF)和手工制作的语言特征来检测目标提及的边界并预测情感极性。(Zhang,Zhang,and Vo 2015)通过引入一个完全连接层来巩固语言特征和单词嵌入,进一步改进了基于CRF的方法的性能。然而,他们发现,在没有联合训练和统一模型的情况下,pipeline方法可以超越模型。在本文中,我们重新检查了该任务,并提出了一个新的统一解决方案,该解决方案执行了所有以前报告的方法。
Conclusions
本文研究了基于目标的情感分析(TBSA)的完整任务,它是一个序列标注问题,具有统一的标注方案。该框架的基本结构包括两个堆叠的LSTMs,分别用于执行辅助目标边界检测和完成TBSA任务。在基本模型的基础上,我们设计了两个组件,利用辅助任务中的目标边界信息,保持同一目标内词的情感一致性。以确保在边界信息的质量方面,我们采用了一个基于辅助意见的目标词检测组件来细化预测的目标边界。实验结果和案例分析都很好地说明了本文提出的框架的有效性,并取得了新的研究成果。我们在https://github.com/lixin4ever/E2E-TBSA。
参考文献:
【1】论文下载: https://arxiv.org/abs/1811.05082?context=cs
【2】论文的github地址 :https://github.com/lixin4ever/E2E-TBSA

 浙公网安备 33010602011771号
浙公网安备 33010602011771号