【NLP-15】BERT模型(Bidirectional Encoder Representations from Transformers)
目录
- BERT简介
- BERT概述
- BERT解析
- GLUE语料集
- 模型比较
- 总结
一句话简介:2018年年底发掘的自编码模型,采用预训练和下游微调方式处理NLP任务;解决动态语义问题,word embedding 送入双向transformer(借用了ELMo的双向思路,GPT的transformer)中。Masked LM(MLM,借用了CBOW的上下预测中心的思虑,也是双向的)和Next Sentence Prediction(NSP,学习句子之间的关系)两种方法分别捕捉词语和句子级别的representation。并将模型深度从12提升到24。
一、BERT简介
BERT(Bidirectional Encoder Representations from Transformers),是Google2018年提出的预训练模型,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。模型的主要创新点都在pre-train方法上,即用了Masked LM(MLM)和Next Sentence Prediction(NSP)两种方法分别捕捉词语和句子级别的representation。
Bert网上的评价很高,是因为它有重大的理论或者模型创新吗?其实并没有,而是一个集大成者。
二、BERT概述
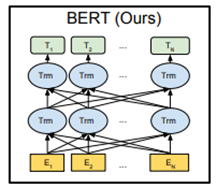
Bert采用和GPT完全相同的两阶段模型,首先是语言模型预训练;其次是使用Fine-Tuning模式解决下游任务。和GPT的最主要不同在于在预训练阶段采用了类似ELMO的双向语言模型,即双向的Transformer,当然另外一点是语言模型的数据规模要比GPT大。所以这里Bert的预训练过程不必多讲了。模型结构如下:
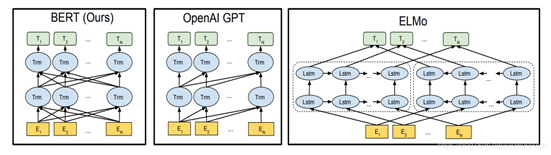
对比OpenAI GPT(Generative pre-trained transformer),BERT是双向的Transformer block连接;就像单向rnn和双向rnn的区别,直觉上来讲效果会好一些。
对比ELMo,虽然都是"双向",但目标函数其实是不同的。ELMo是
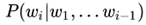

分别以和作为目标函数,独立训练处两个representation然后拼接,而BERT则是以作为目标函数训练LM。
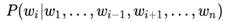
BERT预训练模型分为以下三个步骤:Embedding、Masked LM、Next Sentence Prediction
三、BERT结构解析
BERT提供了简单和复杂两个模型,对应的超参数分别如下:
BERT-base : L=12,H=768,A=12,参数总量110M;(与GPT持平)
BERT-large: L=24,H=1024,A=16,参数总量340M;
3.1 Embedding
这里的Embedding由三种Embedding求和而成:
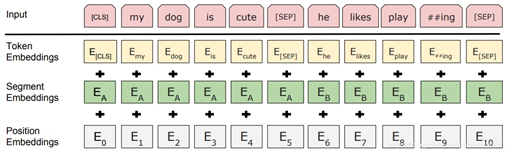
- Token Embeddings是词向量,第一个单词是CLS标志,可以用于之后的分类任务
- Segment Embeddings用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
- Position Embeddings和之前文章中的Transformer不一样,不是三角函数而是学习出来的
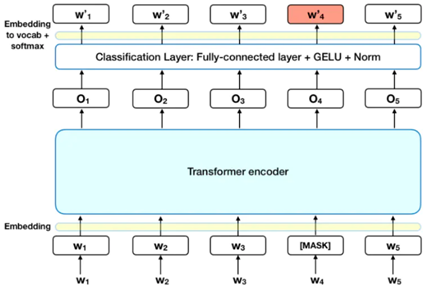
3.2 Masked LM
MLM可以理解为完形填空(作者是这么解释,也可能是借鉴CBOW模型),作者会随机mask每一个句子中15%的词,用其上下文来做预测,例如:my dog is hairy → my dog is [MASK]
此处将hairy进行了mask处理,然后采用非监督学习的方法预测mask位置的词是什么,但是该方法有一个问题,因为是mask15%的词,其数量已经很高了,这样就会导致某些词在fine-tuning阶段从未见过,为了解决这个问题,作者做了如下的处理:
- 80%是采用[mask],my dog is hairy → my dog is [MASK]
- 10%是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
- 10%保持不变,my dog is hairy -> my dog is hairy
注意:这里的10%是15%需要mask中的10%
那么为啥要以一定的概率使用随机词呢?这是因为transformer要保持对每个输入token分布式的表征,否则Transformer很可能会记住这个[MASK]就是"hairy"。至于使用随机词带来的负面影响,文章中解释说,所有其他的token(即非"hairy"的token)共享15%*10% = 1.5%的概率,其影响是可以忽略不计的。Transformer全局的可视,又增加了信息的获取,但是不让模型获取全量信息。
BERT 的损失函数只考虑了 mask 的预测值,忽略了没有掩蔽的字的预测。这样的话,模型要比单向模型收敛得慢,不过结果的情境意识增加了。
3.3 Next Sentence Prediction
Next Sentence Prediction(NSP)的任务是判断句子B是否是句子A的下文。如果是的话输出'IsNext',否则输出'NotNext'。训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。这个关系保存在图4中的[CLS]符号中。
为了预测第二个句子是否是第一个句子的后续句子,用下面3个步骤来预测:
- 整个输入序列输入给 Transformer 模型
- 用一个简单的分类层将 [CLS] 标记的输出变换为 2×1 形状的向量
- 用 softmax 计算 IsNextSequence 的概率
在训练 BERT 模型时,Masked LM 和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。
3.4 微调
在海量单预料上训练完BERT之后,便可以将其应用到NLP的各个任务中了:
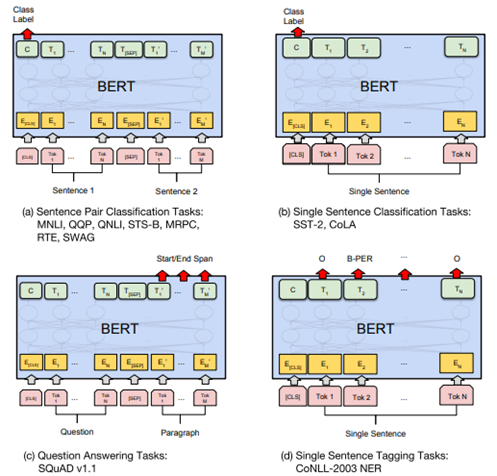
(a)基于句子对的分类任务:
- MNLI:给定一个前提 (Premise) ,根据这个前提去推断假设 (Hypothesis) 与前提的关系。该任务的关系分为三种,蕴含关系 (Entailment)、矛盾关系 (Contradiction) 以及中立关系 (Neutral)。所以这个问题本质上是一个分类问题,我们需要做的是去发掘前提和假设这两个句子对之间的交互信息。
- QQP:基于Quora,判断 Quora 上的两个问题句是否表示的是一样的意思。
- QNLI:用于判断文本是否包含问题的答案,类似于我们做阅读理解定位问题所在的段落。
- STS-B:预测两个句子的相似性,包括5个级别。
- MRPC:也是判断两个句子是否是等价的。
- RTE:类似于MNLI,但是只是对蕴含关系的二分类判断,而且数据集更小。
- SWAG:从四个句子中选择为可能为前句下文的那个
(b)基于单个句子的分类任务
- SST-2:电影评价的情感分析。
- CoLA:句子语义判断,是否是可接受的(Acceptable)。
对于GLUE数据集的分类任务(MNLI,QQP,QNLI,SST-B,MRPC,RTE,SST-2,CoLA),BERT的微调方法是根据[CLS]标志生成一组特征向量 C,并通过一层全连接进行微调。损失函数根据任务类型自行设计,例如多分类的softmax或者二分类的sigmoid。 SWAG的微调方法与GLUE数据集类似,只不过其输出是四个可能选项的softmax:
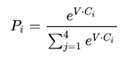
(c)问答任务
SQuAD v1.1:给定一个句子(通常是一个问题)和一段描述文本,输出这个问题的答案,类似于做阅读理解的简答题。如图表示的,SQuAD的输入是问题和描述文本的句子对。输出是特征向量,通过在描述文本上接一层激活函数为softmax的全连接来获得输出文本的条件概率,全连接的输出节点个数是语料中Token的个数。

(d)命名实体识别
CoNLL-2003 NER:判断一个句子中的单词是不是Person,Organization,Location,Miscellaneous或者other(无命名实体)系统需要接收文本序列,标记文本中的各种类型的实体(人员,组织,日期等)。 可以用 BERT 将每个 token 的输出向量送到预测 NER 标签的分类层。
四、GLUE语料集
GLUE(https://gluebenchmark.com/)是一个自然语言任务集合,它包括以下这些数据集:
MNLI Multi-Genre NLI 蕴含关系推断
QQP Quora Question Pairs 问题对是否等价
QNLI Question NLI 句子是否回答问句
SST-2 Stanford Sentiment Treebank 情感分析
CoLA Corpus of Linguistic Acceptability 句子语言性判断
STS-B Semantic Textual Similarity 语义相似
MRPC Microsoft Research Paraphrase Corpus 句子对是否语义等价
RTE Recognizing Texual Entailment 蕴含关系推断
WNLI Winograd NLI 蕴含关系推断
五、模型比较
ELMO,GPT和BERT的关系
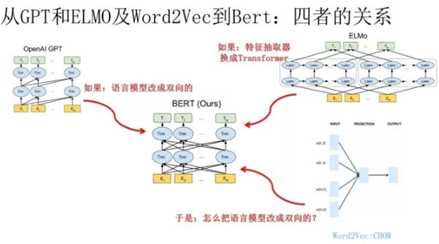
Bert 其实和 ELMO 及 GPT 存在千丝万缕的关系,
- 如果我们把 GPT 预训练阶段换成双向语言模型,那么就得到了 Bert;
- 如果我们把 ELMO 的特征抽取器换成 Transformer,那么我们也会得到 Bert。所以你可以看出:Bert 最关键两点,一点是特征抽取器采用 Transformer;第二点是预训练的时候采用双向语言模型。

再往前看,在NLP中有着举足轻重地位的模型和思想还有Word2vec、LSTM等。
Word2vec作为里程碑式的进步,对NLP的发展产生了巨大的影响,但Word2vec本身是一种浅层结构,而且其训练的词向量所"学习"到的语义信息受制于窗口大小,因此后续有学者提出利用可以获取长距离依赖的LSTM语言模型预训练词向量,而此种语言模型也有自身的缺陷,因为此种模型是根据句子的上文信息来预测下文的,或者根据下文来预测上文,直观上来说,我们理解语言都要考虑到左右两侧的上下文信息,但传统的LSTM模型只学习到了单向的信息。
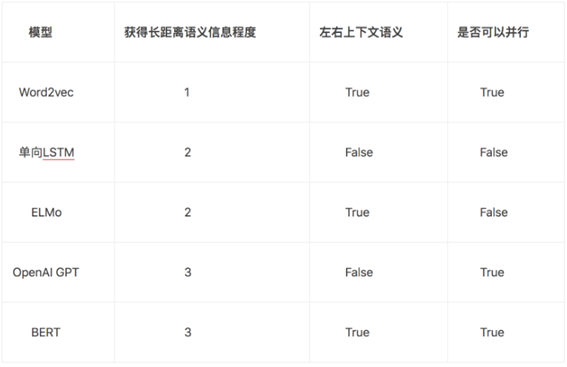
六、总结
6.1 评价
主要贡献:
- 引入了Masked LM,使用双向LM做模型预训练。
- 为预训练引入了新目标NSP,它可以学习句子与句子间的关系。
- 进一步验证了更大的模型效果更好: 12 –> 24 层。
- 为下游任务引入了很通用的求解框架,不再为任务做模型定制。
- 刷新了多项NLP任务的记录,引爆了NLP无监督预训练技术。
客观评价:
Bert是NLP里里程碑式的工作,对于后面NLP的研究和工业应用会产生长久的影响,这点毫无疑问。但是从上文介绍也可以看出,从模型或者方法角度看,Bert借鉴了ELMO,GPT及CBOW,主要提出了Masked 语言模型及Next Sentence Prediction,但是这里Next Sentence Prediction基本不影响大局,而Masked LM明显借鉴了CBOW的思想。所以说Bert的模型没什么大的创新,更像最近几年NLP重要进展的集大成者。
BERT算法还有很大的优化空间,例如我们在Transformer中讲的如何让模型有捕捉Token序列关系的能力,而不是简单依靠位置嵌入。BERT的训练在目前的计算资源下很难完成,论文中说BERT的训练需要在64块TPU芯片上训练4天完成,而一块TPU的速度约是目前主流GPU的7-8倍。非常幸运的是谷歌开源了各种语言的模型,免去了我们自己训练的工作。
主要特点:
首先是两阶段模型,第一阶段双向语言模型预训练,这里注意要用双向而不是单向,第二阶段采用具体任务Fine-tuning或者做特征集成;
第二是特征抽取要用Transformer作为特征提取器而不是RNN或者CNN;
第三,双向语言模型可以采取CBOW的方法去做(当然我觉得这个是个细节问题,不算太关键,前两个因素比较关键)。
Bert最大的亮点在于效果好及普适性强,几乎所有NLP任务都可以套用Bert这种两阶段解决思路,而且效果应该会有明显提升。可以预见的是,未来一段时间在NLP应用领域,Transformer将占据主导地位,而且这种两阶段预训练方法也会主导各种应用。
6.2 BERT优点
- BERT是截止至2018年10月的最新的的state of the art模型,通过预训练和精调可以解决11项NLP的任务。使用的是Transformer,相对于rnn而言更加高效、能捕捉更长距离的依赖。与之前的预训练模型相比,它捕捉到的是真正意义上的bidirectional context信息
- Transformer Encoder因为有Self-attention机制,因此BERT自带双向功能
- 因为双向功能以及多层Self-attention机制的影响,使得BERT必须使用Cloze版的语言模型Masked-LM来完成token级别的预训练
- 为了获取比词更高级别的句子级别的语义表征,BERT加入了Next Sentence Prediction来和Masked-LM一起做联合训练
- 微调成本小
6.3 BERT缺点
- 每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)
- BERT 假设要预测的词之间是相互独立的,即 Mask 之间相互不影响。但实际是有关联的(XLNet中提到)
- BERT属于自编码语言模型,在预训练过程中会使用 MASK 符号,但在下游 NLP 任务中并不会使用,因此这也会造成一定的误差(XLNet中提到)
- BERT对硬件资源的消耗巨大(大模型需要16个tpu,历时四天;更大的模型需要64个tpu,历时四天。
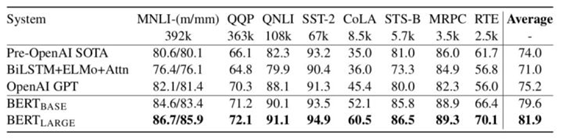
附件一:结果展示
句子关系判断及分类任务
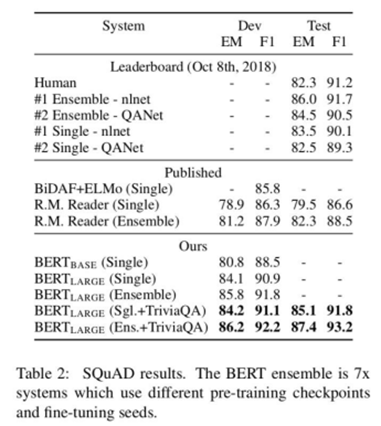
抽取式任务:SQuAD
序列标注:命名实体识别

分类任务:SWAG

附件二:BERT适用范围
来自张俊林的解读https://zhuanlan.zhihu.com/p/68446772
第一,如果NLP任务偏向在语言本身中就包含答案,而不特别依赖文本外的其它特征,往往应用Bert能够极大提升应用效果。典型的任务比如QA和阅读理解,正确答案更偏向对语言的理解程度,理解能力越强,解决得越好,不太依赖语言之外的一些判断因素,所以效果提升就特别明显。反过来说,对于某些任务,除了文本类特征外,其它特征也很关键,比如搜索的用户行为/链接分析/内容质量等也非常重要,所以Bert的优势可能就不太容易发挥出来。再比如,推荐系统也是类似的道理,Bert可能只能对于文本内容编码有帮助,其它的用户行为类特征,不太容易融入Bert中。
第二,Bert特别适合解决句子或者段落的匹配类任务。就是说,Bert特别适合用来解决判断句子关系类问题,这是相对单文本分类任务和序列标注等其它典型NLP任务来说的,很多实验结果表明了这一点。而其中的原因,我觉得很可能主要有两个,一个原因是:很可能是因为Bert在预训练阶段增加了Next Sentence Prediction任务,所以能够在预训练阶段学会一些句间关系的知识;第二个可能的原因是:因为Self Attention机制自带句子A中单词和句子B中任意单词的Attention效果,而这种细粒度的匹配对于句子匹配类的任务尤其重要,所以Transformer的本质特性也决定了它特别适合解决这类任务。
从上面这个Bert的擅长处理句间关系类任务的特性,我们可以继续推理出以下观点:既然预训练阶段增加了Next Sentence Prediction任务,就能对下游类似性质任务有较好促进作用,那么是否可以继续在预训练阶段加入其它的新的辅助任务?而这个辅助任务如果具备一定通用性,可能会对一类的下游任务效果有直接促进作用。这也是一个很有意思的探索方向。
第三,Bert的适用场景,与NLP任务对深层语义特征的需求程度有关。感觉越是需要深层语义特征的任务,越适合利用Bert来解决;而对有些NLP任务来说,浅层的特征即可解决问题,典型的浅层特征性任务比如分词,POS词性标注,NER,文本分类等任务,这种类型的任务,只需要较短的上下文,以及浅层的非语义的特征,貌似就可以较好地解决问题,所以Bert能够发挥作用的余地就不太大,有点杀鸡用牛刀,有力使不出来的感觉。这很可能是因为Transformer层深比较深,所以可以逐层捕获不同层级不同深度的特征。于是,对于需要语义特征的问题和任务,Bert这种深度捕获各种特征的能力越容易发挥出来,而浅层的任务,比如分词/文本分类这种任务,也许传统方法就能解决得比较好,因为任务特性决定了,要解决好它,不太需要深层特征。
第四,Bert比较适合解决输入长度不太长的NLP任务,而输入比较长的任务,典型的比如文档级别的任务,Bert解决起来可能就不太好。主要原因在于:Transformer的self attention机制因为要对任意两个单词做attention计算,所以时间复杂度是n平方,n是输入的长度。如果输入长度比较长,Transformer的训练和推理速度掉得比较厉害,于是,这点约束了Bert的输入长度不能太长。所以对于输入长一些的文档级别的任务,Bert就不容易解决好。结论是:Bert更适合解决句子级别或者段落级别的NLP任务。
也许还有其它因素,不过貌似不如上面四条表现得这么明显,所以,我先归纳这四项基本原则吧。
附件三、问答
1、bert构建双向语言模型不是很简单吗?不也可以直接像elmo拼接Transformer decoder吗?
BERT 的作者认为,这种拼接式的bi-directional 仍然不能完整地理解整个语句的语义。更好的办法是用上下文全向来预测[mask],也就是用 "能/实现/语言/表征/../的/模型",来预测[mask]。BERT 作者把上下文全向的预测方法,称之为 deep bi-directional。
参考文献
【0】原论文 https://arxiv.org/abs/1810.04805
【1】NLP各种模型,主要BERT: https://blog.csdn.net/sunhua93/article/details/102764783
【2】BERT相关论文、文章和代码资源汇总 https://zhuanlan.zhihu.com/p/50717786
【3】BERT使用详解(实战) : https://www.jianshu.com/p/bfd0148b292e
【4】Bert时代的创新(应用篇)Bert在NLP各领域的应用进展: https://zhuanlan.zhihu.com/p/68446772
【5】英文版解读: https://www.lyrn.ai/2018/11/07/explained-bert-state-of-the-art-language-model-for-nlp/

