【NLP-2019】翻译BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Abstract
我们引入了一种新的语言表示模型,称为BERT(Bidirectional Encoder Representations from Transformers.)。不同于最近的语言表示模型【1】【2】(Peters et al., 2018a;Radford et al., 2018)。BERT通过在所有层中对左、右上下文进行联合条件作用,来预先训练来自未标记文本的深层双向表示。因此,只需一个额外的输出层,就可以对预先训练的BERT模型进行优化,从而为各种任务(如回答问题和语言推断)创建最先进的模型,而无需对特定于任务的体系结构进行大量修改。
BERT概念简单且强大的模型。它在11个自然语言处理任务上获得了新的最先进的结果,包括GLUE评分到 80.5%(提高7.7%个点),MultiNLI达到86.7%(提高4.6%),SQuAD v1.1问答系统Test F1 to 93.2 (提高1.5),SQuAD v2.0 Test F1 to 83.1 (提高5.1).
1 Introduction
语言模型预训练已被证明对提高许多自然语言处理任务是有效的 (【3】Dai and Le, 2015; 【1】Peters et al., 2018a;【2】 Radford et al., 2018; 【4】Howard and Ruder, 2018),这些任务包括句子级任务,如自然语言推理(Bowman et al., 2015; 【5】Williams et al., 2018),和改写(Dolan and Brockett, 2005),它的目标是通过整体分析来预测句子之间的关系,以及像命名实体识别和问题回答这样的符号级任务,模型需要在token级别生成细粒度的输出(Tjong Kim Sang and De Meulder, 2003; 【6】Rajpurkar et al., 2016).
有两种现有的策略可以将预先训练好的语言表示应用于下游任务:基于特性和微调。基于功能的方法,如【1】ELMo (Peters et al., 2018a), 使用特定于任务的体系结构,其中包括作为附加特性的预先训练的表示。微调方法,例如Generative Pre-trained Transformer (OpenAI GPT)【2】 (Radford et al., 2018),引入最小的特定于任务的参数,并通过简单地微调所有预先训练的参数对下游任务进行培训。这两种方法在训练前有相同的目标功能,即使用单向的语言模型来学习一般的语言表示。
我们认为,当前的技术限制了预先训练的表示的能力,特别是对于微调方法。主要的限制是标准语言模型是单向的,这限制了可以在培训前使用的体系结构的选择。例如,在OpenAI GPT中,作者使用了left-to right体系结构,其中每个token只能处理Transformer的self-attention层中的前一个token,(Vaswani et al., 2017). 这样的限制对于句子级任务来说是次优的,并且当应用基于细化的方法来处理诸如问题回答这样的token级任务时是非常有害的,在这些任务中,从两个方向结合上下文是非常重要的。
在本文中,我们通过提出BERT改进了基于微调的方法。BERT受完形填空任务的启发,通过使用"掩蔽语言模型"(MLM)的训练前目标,减轻了前面提到的单向性约束(Taylor, 1953)。蒙面语言模型随机地从输入中屏蔽一些标记,目标是预测蒙面的原始词汇表id。与左向右语言模型预训练不同,MLM目标允许表示融合左向和右向上下文,这允许我们预训练一个深层双向转换器。除了蒙面语言模型之外,我们还使用一个"next sentence prediction"("下一句话预测")任务来联合训练文本对表示。本文的贡献如下:
- 我们证明了语言表示的双向预训练的重要性。与【2】Radford et al. (2018)使用单向语言模型进行预训练不同,BERT使用掩蔽语言模型来实现预训练的深层双向表示。这也与【1】Peters et al. (2018a), 形成对比,他们使用了独立训练的从左到右和从右到左的LMs的浅连接。
- 我们表明,预先训练的表示减少了对许多经过大量工程设计的特定于任务的体系结构的需求。BERT是第一个基于fine-tuning的表示模型,它在大量语句级和token级任务上实现了最先进的性能,超过了许多特定于任务的体系结构。
- bert把最先进的技术提高到11个NLP的任务。代码和预先培训的模型可在 https://github.com/ google-research/bert.
2 Related Work
一般语言表示的培训有很长的历史,我们在本节中简要回顾了最广泛使用的方法。
2.1 Unsupervised Feature-based Approaches
数十年来,学习广泛适用的单词表示一直是一个活跃的研究领域,包括非神经领域, (Brown et al., 1992; Ando and Zhang, 2005; Blitzer et al., 2006) and neural (Mikolov et al., 2013; Pennington et al., 2014)。预先训练的词嵌入是现代NLP系统的一个组成部分,提供了重要的改进从嵌入式学习从零开始(Turian et al., 2010).为了预先训练单词嵌入向量,使用了从左到右的语言建模目标 (Mnih and Hinton, 2009)。以及在左右语境中区分正确和不正确的单词的目的(Mikolov et al., 2013).
这些方法已经被推广到更粗的粒度,例如句子嵌入(Kiros et al., 2015; Logeswaran and Lee, 2018)或段落嵌入(Le and Mikolov, 2014)。为了训练句子表达,之前的工作已经使用目标来对候选句子进行排序(Jernite et al., 2017; Logeswaran and Lee, 2018)。给出上一个句子的表示,从左到右生成下一个句子的单词 (Kiros et al., 2015)。或去噪自动编码器派生的目标(Hill et al., 2016).
ELMo和它的前身(Peters et al., 2017, 2018a)从不同的维度推广传统的词嵌入研究。它们从从左到右和从右到左的语言模型中提取上下文敏感的特性。每个标记的上下文表示是左到右和右到左表示的连接。每个标记的上下文表示是左到右和右到左表示的连接。 在将上下文相关的word嵌入与现有的特定于任务的体系结构集成时,ELMo为几个主要的NLP基准提高了技术水平【1】(Peters et al., 2018a),包括问题回答【6】(Rajpurkar et al., 2016)、情绪分析(Socher et al., 2013)和命名实体识别(Tjong Kim Sang和De Meulder, 2003)。Melamud et al. (2016) )提出通过使用LSTMs从左、右上下文预测单个单词的任务来学习上下文表示。与ELMo类似,他们的模型是基于特征的,而不是深度双向的。Fedus et al. (2018) 表明完形填空任务可以用来提高文本生成模型的鲁棒性。
2.2 Unsupervised Fine-tuning Approaches
与基于特征的方法一样,第一种方法只针对未标记文本预先训练的单词嵌入参数(Collobert and Weston, 2008)。最近,产生上下文token表示的句子或文档编码器已经从未标记的文本中进行了预先训练,并为受监督的后续任务进行了微调k(【3】Dai and Le, 2015; 【4】Howard and Ruder, 2018;【2】 Radford et al., 2018),这些方法的优点是不需要从头学习太多的参数。至少部分原因是这个优势。【2】OpenAI GPT(Radford et al., 2018)在the GLUE benchmark (Wang et al., 2018a)的许多句子级任务上取得了以前的最先进的结果,左到右和自编码的语言模型已用于此类模型的预培训(【4】Howard and Ruder, 2018; 【2】Radford et al., 2018; 【3】Dai and Le, 2015).
2.3 Transfer Learning from Supervised Data
也有研究表明,从监督任务与大数据集有效的转移,如自然语言推理(Conneau et al., 2017),机器翻译 (McCann et al., 2017).计算机视觉研究也证明了从大型预训练模型中转移学习的重要性,其中一个有效的方法是使用ImageNet对预训练模型进行微调 (Deng et al., 2009; Yosinski et al., 2014).
3 BERT
我们将在本节中介绍BERT及其详细实现。在我们的框架中有两个步骤:预训练和微调(pre-training and fine-tuning)。在预训练,对不同预训练任务的未标记数据进行训练。对于fine tuning,首先使用预先训练的参数初始化BERT模型,然后使用来自下游任务的标记数据对所有参数进行微调。每个下游任务都有单独的经过调优的模型,即使它们是用相同的预先训练的参数初始化的。图1中的问题回答示例将作为本节的运行示例。
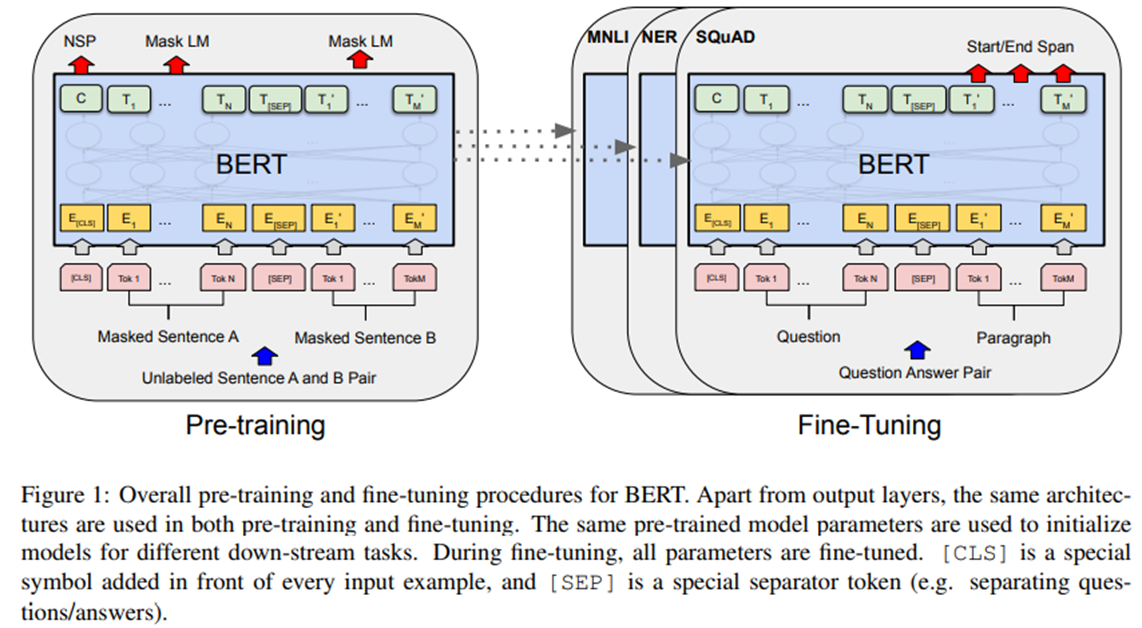
BERT的一个显著特征是它跨不同任务的统一架构。在预先训练的体系结构和最终的下游体系结构之间有细微差异。
Model Architecture
BERT的模型结构是一个多层双向transformer编码器,基于【7】Vaswani et al. (2017) 中描述的原始实现并在张量库中释放(1https://github.com/tensorflow/tensor2tensor)。由于transformer的使用已经变得很普遍,而且我们的实现几乎与原始实现完全相同,所以我们将省略对模型体系结构的详尽背景描述,并向读者提供参考【7】Vaswani et al. (2017)以及优秀的指南,如"注释的transformer"(http://nlp.seas.harvard.edu/2018/04/03/attention.html)
在这项工作中,我们表示层的数量(i.e., Transformer blocks)为L,隐藏尺寸为H,和自我关注头的数量A,我们主要报告两个模型大小的结果:
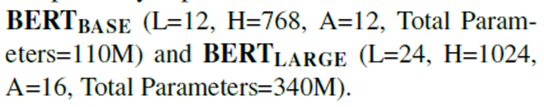

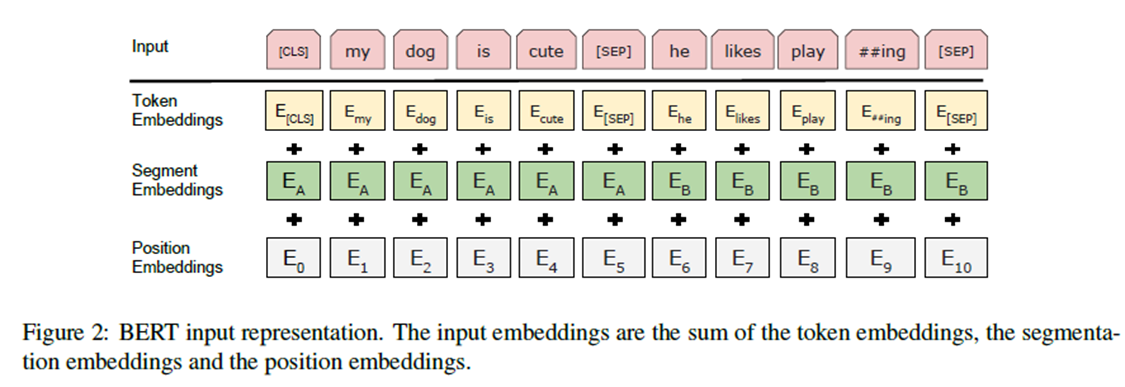
输入/输出表示Input/Output Representations
为了让BERT处理各种下游任务,我们的输入表示能够明确地表示单个句子和一对句子。(e.g., h Question, Answer i)在一个token序列中,在这部作品中,一个"句子"可以是任意一段连续的文本,而不是一个实际的语言句子。"序列"是指BERT的输入标记序列,它可以是一个句子,也可以是两个句子。
我们使用单词嵌入(Wu et al.,2016)拥有30,000个象征性词汇,每个序列的第一个标记总是一个特殊的分类标记([CLS])。与此标记对应的最终隐藏状态用作分类任务的聚合序列表示。句子对被组合成一个单独的序列。我们用两种方法区分这些句子:首先,我们用一个特殊的记号([SEP]).把它们分开。其次,我们在每个标记中添加了一个学习嵌入,表明它是属于句子a还是句子B。如图1所示,我们将输入嵌入表示为E,即特殊[CLS]token的最终隐藏向量
对于给定的token,它的输入表示是通过对相应的token、段和位置嵌入求和来构造的。图2显示了这种构造。
3.1 Pre-training BERT
不像【1】Peters et al. (2018a) and【2】 Radford et al.(2018),,我们没有使用传统的从左到右或从右到左的语言模型对BERT进行预训练。 相反,我们使用本节描述的两个非监督任务对BERT进行预训练。此步骤在图1的左侧部分中给出。
Task #1: Masked LM
直观地说,我们有理由相信,深度双向模型比从左到右模型或从左到左模型的浅层连接更强大。不幸的是,标准条件语言模型只能训练从左到右或从右到左,因为双向条件作用将允许每个单词间接地 "看自己",这个模型可以在多层次的语境中对目标词进行简单的预测。
为了训练一个深层的双向表示,我们简单地随机屏蔽一些输入标记的百分比,然后预测那些屏蔽的标记。我们把这个过程称
"maskedLM" (MLM), 虽然它经常被称为 文学中的完形填空(Taylor, 1953).。在这种情况下,掩码标记对应的最终隐藏向量通过词汇表被输入到输出softmax中,就像在标准LM中一样。在我们所有的实验中,我们在每个序列中随机屏蔽15%的单词标记。与去噪自动编码器相比【9】 (Vincent et al., 2008),我们只预测蒙面文字,而不是重建整个输入。
虽然这允许我们获得双向的预训练模型,但缺点是我们在预训练和微调之间产生了不匹配,因为在微调期间没有出现[MASK]token。为了缓和这种情况,我们并不总是用实际的词来代替"屏蔽"的词 (面具)token。训练数据生成器随机选择token位置的15%进行预测。
- 80%是采用[mask],my dog is hairy → my dog is [MASK]
- 10%是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
- 10%保持不变,my dog is hairy -> my dog is hairy
Task #2: Next Sentence Prediction (NSP)
许多重要的下游任务,如问题回答(QA)和自然语言推理(NLI)是基于对两个句子之间关系的理解,这不是语言建模直接捕捉的。为了训练一个理解句子关系的模型,我们对一个可以从任何单语语料库中生成的二值化下一个句子预测任务进行了预训练。具体来说,在为每个训练前示例选择句子A和B时,50%的时间B是A后面的实际下一个句子(标记为IsNext), 50%的时间它是从语料库中随机选择的句子(标记为NotNext).如图1所示,C用于下一个句子预测 (NSP)。尽管它很简单,但我们在5.1节中证明了针对这项任务的预培训对QA和NLI都是非常有益的。(如果不进行微调,向量C就不是一个有意义的句子表示,因为它是用NSP训练的。)
NSP任务与在Jernite et al. (2017) andLogeswaran and Lee (2018).)用到的学习目标密切相关。但是,在以前的工作中,只有语句嵌入被传输到下游任务中,BERT传输所有参数来初始化最终任务模型参数。
Pre-training data 训练前的程序很大程度上遵循了已有的语言模型训练的文献。对于训练前的语料库,我们使用了BooksCorpus (800M words) (Zhu等人, 和英文维基百科(2500万字)。 对于Wikipedia,我们只提取文本段落,而忽略列表、表格和标题。关键是要使用文档级的语料库,而不是句子级的语料库,比如十亿为了提取长连续序列,单词基准测试(Chelba et al., 2013)。
3.2 Fine-tuning BERT
微调是直接了当的,因为自关注机制在transformer允许 BERT通过交换出适当的输入和输出,为许多下游任务建模——不管它们是单个文本还是文本对。 对于涉及文本对的应用程序,一个常见的模式是在应用双向交叉注意之前对文本对进行独立编码,例如:Parikh et al. (2016); Seo et al. (2017).BERT使用了self-attention机制来统一这两个阶段,因为self-attention编码一个连接的文本对有效地包含了两个句子之间的双向交叉注意。
对于每个任务,我们只需将特定于任务的输入和输出插入BERT并对所有端到端参数进行finetune。在输入处,训练前的句子A和句子B类似于(1)释义中的句子对, (2)隐含的假设-前提对,(3)回答问题时的问题-短文对,(4)一个退化的文本在文本分类或序列标记中配对。在输出端,token表示被输入到一个输出层,用于token级任务,例如序列标记或问题回答,而[CLS]表示被输入到一个输出层,用于分类,例entailment或sentiment analysis。
与培训前相比,微调成本相对较低。论文中的所有结果可以在最多1小时内在一个云TPU,或者GPU上的几个小时,从完全相同的预训练模型开始。我们将在第4节的相应小节中描述特定于任务的细节。更多细节可以在附录A.5中找到
4 Experiments
在本节中,我们将介绍BERT在11个NLP任务上的微调结果。
4.1 GLUE


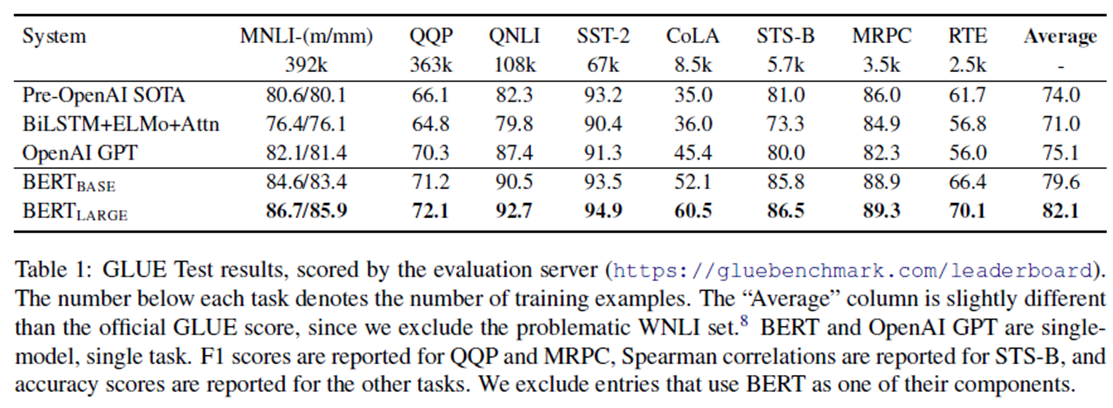
结果见表1。我们发现,BERT_LARGE的表现明显优于其他公司BERT_BASE遍历所有任务,特别是那些训练数据很少的任务。模型大小的影响在5.2节中进行了更深入的探讨。
4.2 SQuAD v1.1

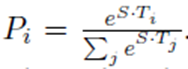
对于答案张成的空间的末端也使用类似的公式。一个候选范围从位置i张成到位置j的得分定义为
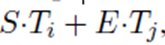
训练目标是正确开始和结束位置的对数概率的总和。我们对3个epoch进行微调,学习率为5e-5,批处理大小为32。
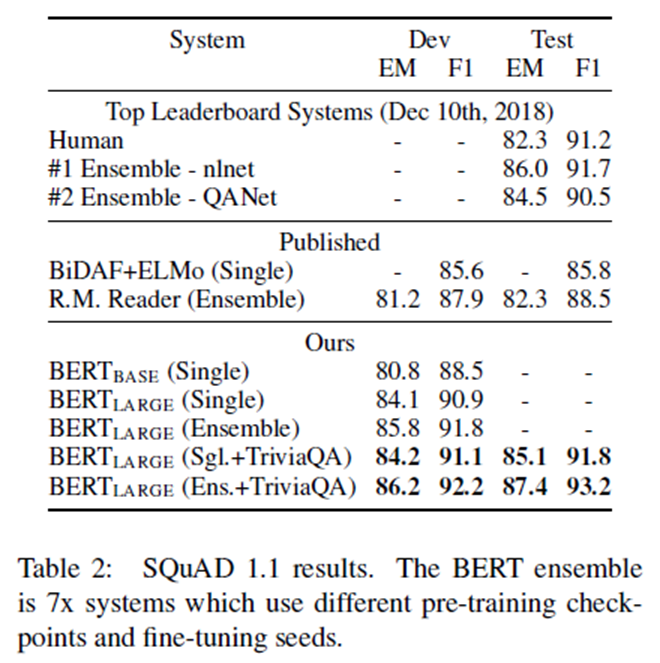
表2显示了顶级排行榜条目以及来自顶级发布系统的结果(Seo et al.,2017; Clark and Gardner, 2018;【1】 Peters et al.,2018a; Hu et al., 2018).上面的结果来自SQuAD leaderboard 没有最新的公共系统描述,并且当训练他们的系统时被允许使用任何公共数据。 因此,在对SQuAD.进行微调之前,我们首先对TriviaQA (Joshiet al., 2017)进行微调。
我们最好的表现系统表现超过顶级排行榜系统+1.5 F1在集成和 +1.3 F1作为一个单一的系统。事实上,我们的单一BERT模型在F1得分上优于顶级集成系统。除了TriviaQA我们只损失了0.1-0.4 F1,仍然远远超过了所有现有的系统。
4.3 SQuAD v2.0
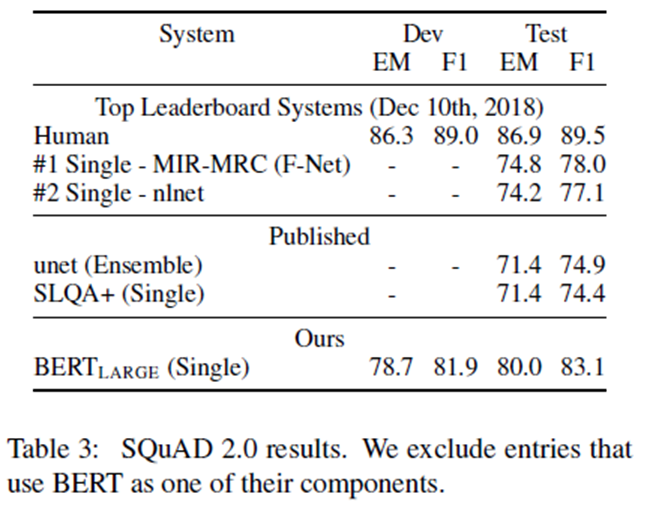
SQuAD2.0任务扩展SQuAD1.1问题定义,允许在提供的段落中不存在简短的答案,从而使问题更加实际。
结果与之前的排行榜条目和顶级出版作品相比较(Sun et al., 2018;Wang et al., 2018b)在表3,不包括使用BERT作为组件之一的系统。 我们观察到a +5.1 F1优于之前的最佳系统。
4.4 SWAG
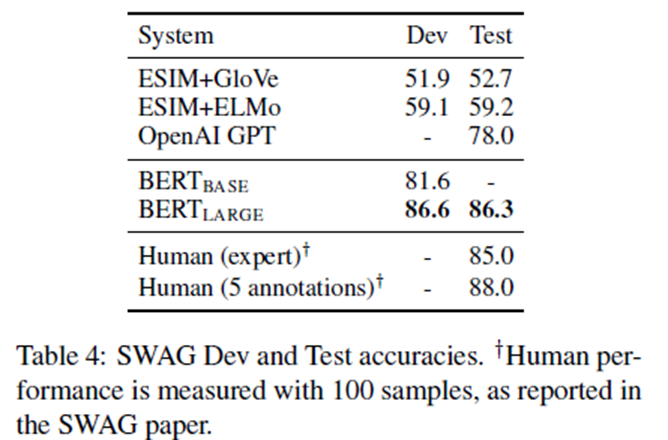
The Situations With Adversarial Generations (SWAG) dataset 包含113k个评价基于常识推理的句子对完成示例(Zellers et al., 2018).给出一个句子,任务是在四个选项中选择最合理的继续。在对SWAG数据集进行微调时,我们构造四个输入序列,每个输入序列包含给定句子的连接(句子) 唯一引入的特定于任务的参数是一个向量,它与[CLS]令牌表示的点积 C表示用softmax层规范化的每个选择的得分。
我们以2e-5的学习率和16的批处理大小对模型进行了3个epoch的微调。结果见表4
5 Ablation Studies
在本节中,我们将对BERT的多个方面进行消融实验,以更好地了解它们的相对重要性
消融研究可在附录C中找到。
5.1 Effect of Pre-training Tasks
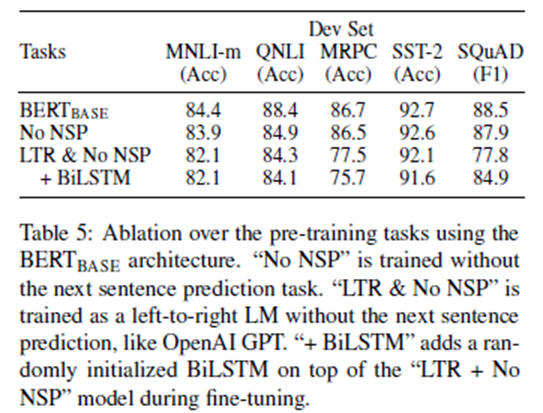
我们通过使用与BERT_BASE完全相同的训练前数据、微调方案和超参数来评估两个训练前目标,从而证明BERT的深度双向性的重要性
没有NSP:一个双向模型,训练使用"masked LM" (MLM),但没有 "下一句话预测"(NSP)任务。
LTR&No NSP:使用标准的从左到右(LTR)训练的只考虑左上下文的模型 LM,而不是一个MLM。left-only的约束也适用于微调,因为取消它会引入列车前/微调不匹配,从而降低下游性能。另外,这个模型在没有NSP任务的情况下进行了预训练。这可以直接与OpenAI GPT进行比较,但是要使用更大的训练数据集、输入表示和微调方案。
我们首先检查NSP任务带来的影响。在表5中,我们表明移除NSP会显著影响QNLI、MNLI和SQuAD 1.1的性能。接下来,我们通过比较来评估训练双向表现的影响"No NSP"至"LTR & No NSP".。LTR模型在所有任务上的表现都比MLM模型差,在MRPC and SQuAD.上有较大的下降。
对于SQuAD来说,很明显,LTR模型在token预测方面表现不佳,因为token级隐藏状态没有右侧上下文。为了增强LTR系统的可靠性,我们在其上增加了一个随机初始化的BiLSTM。这明显提高了SQuAD的成绩。但结果仍然比那些预先训练的双向模型差得多。BiLSTM会影响GLUE任务的性能
我们认识到,也可以训练单独的LTR和RTL模型,并将每个token表示为两个模型的连接,就像ELMo所做的那样。但是:
(a)这比单一的双向模型贵一倍;
(b)对于像QA这样的任务来说,这是不直观的,因为RTL模型不能够限定问题的答案;
(c)这比深层双向模型的功能要弱,因为它可以在每一层同时使用左上下文和右上下文。
5.2 Effect of Model Size
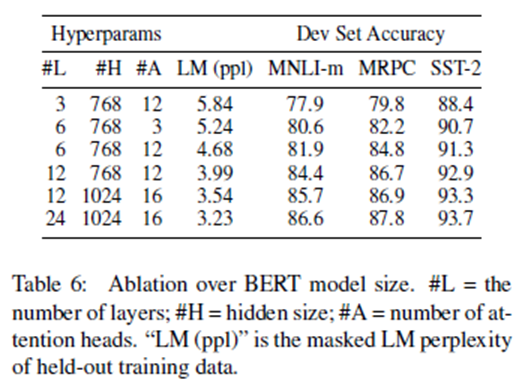
在本节中,我们将探讨模型大小对微调任务准确性的影响。我们使用不同的层数、隐藏单元和注意头训练了许多BERT模型,而其他情况下使用与前面描述的相同的超参数和训练过程。
所GLUE任务的结果显示在表6所示。在这个表中,我们报告了平均设置精度从5随机重新启动微调。 我们可以看到,更大的模型可以在所有四个数据集上实现严格的准确性改进,甚至对于只有3600个标记的训练示例的MRPC来说也是如此,这与训练前的任务有很大的不同。同样令人惊讶的是,我们能够在现有模型的基础上实现如此显著的改进,这些模型相对于现有文献来说已经相当大了 。例如,最大的transformer 【7】 Vaswani et al. (2017),编码器的100M参数,以及我们在文献中发现的最大的transformer 235M(Al-Rfou et al., 2018).相比之下,BERT_BASE包含110M参数,BERT_LARGE包含340的参数。
人们早就知道,增加模型大小将导致大规模任务的持续改进,如机器翻译和语言建模,这是由表6所示的训练数据的LM复杂性所证明的。
然而,我们相信,这是第一个令人信服地证明,在模型得到充分预训练的前提下,向极端模型尺寸的缩放也会在非常小的任务中带来巨大的改进的工作。Peters et al. (2018b) 将预训练的bi-LM大小从2层增加到4层,会对下游任务产生复杂的影响。Melamud et al. (2016)中提到,将隐藏维度大小从200增加到600会有所帮助,但是进一步增加到1000不会带来进一步的改进。这两个作品使用featurebased方法之前,我们假设当模型调整直接在下游任务和只使用少量的随机初始化其他参数,taskspecific模型可以受益于更大、更富有表现力的pre-trained表示即使下游任务数据非常小。
5.3 Feature-based Approach with BERT
到目前为止,所有BERT结果都使用了微调方法,即在预先训练的模型中添加一个简单的分类层,并在下游任务中联合微调所有参数。然而,基于特征的方法,即从预先训练的模型中提取固定的特征,具有一定的优势:
- 首先,并不是所有任务都可以很容易地用转换器编码器体系结构表示,因此需要添加特定于任务的模型体系结构。
- 其次,预先计算一次训练数据的昂贵表示,然后在此表示之上使用更便宜的模型运行许多实验,这在计算上有很大的好处。
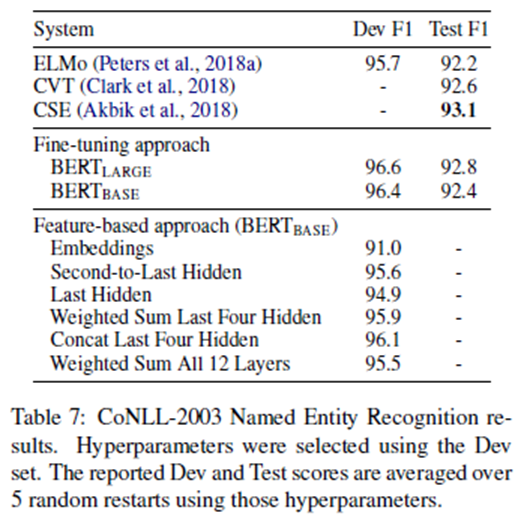
在本节中,我们通过将BERT应用到名为CoNLL-2003的方法来比较这两种方法实体识别(NER)任务(Tjong Kim Sang和De Meulder, 2003)。在BERT的输入中,我们使用了一个保留大小写的单词模型,并包含了数据提供的最大文档上下文。按照标准实践,我们将此作为标记任务来制定,但不使用CRF层作为输出。我们使用第一个子标记的表示作为在NER标签集上的标记级分类器的输入。
为了简化微调方法,我们应用基于特性的方法,从一个或多个层提取激活,而不微调BERT的任何参数。这些上下文嵌入被用作分类层之前的随机初始化的两层768维BiLSTM的输入。
结果见表7。BERT_LARGE用最先进的方法进行有竞争力的表现。 性能最好的方法是将来自预训练的Transformer的前四个隐藏层的token表示连接起来,这是微调整个模型惟一落后的--0.3 F1。这表明BERT对于finetuning和基于特征的方法都是有效的。
6 Conclusion
最近由语言模型转移学习带来的经验改进表明,丰富的、无监督的预先训练是许多语言理解系统的一个组成部分。特别是,这些结果使得即使是低资源的任务也可以从深度单向架构中获益。我们的主要贡献是进一步将这些发现推广到深层的双向架构,允许相同的预先训练的模型成功地处理广泛的NLP任务。
附录 Additional Details for BERT
A.1 Illustration of the Pre-training Tasks
我们在下面提供了一些训练前任务的例子。
Masked LM and the Masking Procedure:这里主要对3.1 做了解释:
- 80%是采用[mask],my dog is hairy → my dog is [MASK]
- 10%是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
- 10%保持不变,my dog is hairy -> my dog is hairy
这个程序的优点是 编码器不知道哪些单词将被请求预测,或者哪些单词已经被随机单词替换,因此它被迫保留每个输入标记的分布式上下文表示。另外,因为随机替换只发生在所有token的1.5%上 (即。,这似乎不会损害模型的语言理解能力。在第C.2节,我们评估这一程序的影响。在C.1节中,我们将对此进行说明MLM确实略慢收敛左向右模型(预测每一个标记),但经验的改进MLM模型远远超过增加的培训成本。
下一个句子预测任务可以在下面的例子中进行说明。

A.2 Pre-training Procedure
为了生成每个训练输入序列,我们从语料库中抽取两段文本作为样本,我们称之为"句子",尽管它们通常比单个句子长得多(但也可能更短).第一个句子接收A嵌入,第二个句子接收B嵌入。 50%的时间B是A后面的下一个句子,50%的时间是一个随机的句子,这是为"下一个句子预测"任务而做的。LM掩码是经过掩码率为15%的字元标记后应用的,对部分字元不作特别考虑。
我们使用256个序列(256序列* 512令牌= 128,000令牌/批处理)的批大小进行训练,执行1,000,000步,在超过33亿词的语料库大概40 epochs.我们使用gelu激活(Hendrycks and Gimpel, 2016), 而不是标准的relu,遵循OpenAI GPT。训练损失是平均掩蔽LM似然和平均下一句话预测似然的和。
时长:4日对BERTBASE进行训练Pod配置的云TPUs(共16个TPU芯片)。在16个云TPUs(共64个TPU芯片)上进行13次BERTLARGE训练。每次培训都需要4天的时间。
较长的序列代价过高,因为注意力是序列长度的2倍。为了加快预处理速度,我们对序列长度为的模型进行了预处理 128为90%的步骤。然后,我们训练剩下的人 按序列的10%学习512步的位置嵌入。
A.3 Fine-tuning Procedure
对于微调,除了批处理大小、学习率和训练时间外,大多数模型超参数与训练前相同。退出概率始终保持在0.1。最佳超参数值是特定于任务的,但是我们发现以下可能的值范围可以很好地跨所有任务工作:
Batch size: 16, 32
Learning rate (Adam): 5e-5, 3e-5, 2e-5
Number of epochs: 2, 3, 4
我们也观察到大的数据集(例如, 与小数据集相比,100k+标记的训练示例)对超参数选择的敏感性要低得多。微调通常是非常快的,所以对上面的参数进行彻底的搜索并选择在开发集上执行得最好的模型是合理的。
A.4 Comparison of BERT, ELMo ,and OpenAI GPT
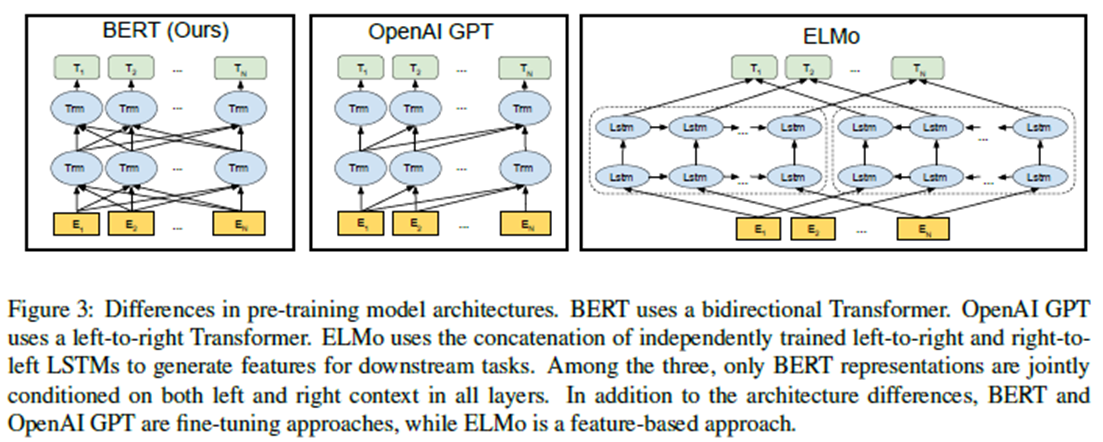
在这里,我们研究了最近流行的表征学习模型的差异,包括ELMo,OpenAI GPT和BERT。模型架构之间的比较如图3所示。注意,除了架构上的差异之外,BERT和OpenAI GPT都是很好的方法,而ELMo是基于功能的方法。
与BERT最相似的现有预培训方法是OpenAI GPT,它在大型文本语料库上培训从左到右的Transformer LM。事实上,BERT的许多设计决策都是有意让它接近 尽可能采用GPT,以便两种方法可以进行最低限度的比较。这项工作的核心论点是,在3.1节中提出的双向性和两个培训前任务占了大部分的经验改进,但我们确实注意到,BERT和GPT的培训方式还有其他一些不同之处:
- GPT在BooksCorpus上训练(800M单词);BERT被训练成书虫维基百科(2500万字)。
- GPT使用一个句子分隔符([SEP])和分类器标记([CLS]),它们只在微调时引入;BERT在在预处理时,学习[SEP], [CLS]和A/B嵌入。
- GPT训练1M步,批处理32000字;BERT被训练1M步,批处理大小为12.8万字。
- GPT对所有微调实验使用5e-5相同的学习率;BERT选择特定于任务的微调学习率,该学习率在开发集上执行得最好。
为了分离这些差异的影响,我们在5.1节中进行了消融实验,实验表明大部分的改善实际上来自于两个训练前的任务和它们所带来的双向性。
A.5 Illustrations of Fine-tuning on Different Tasks
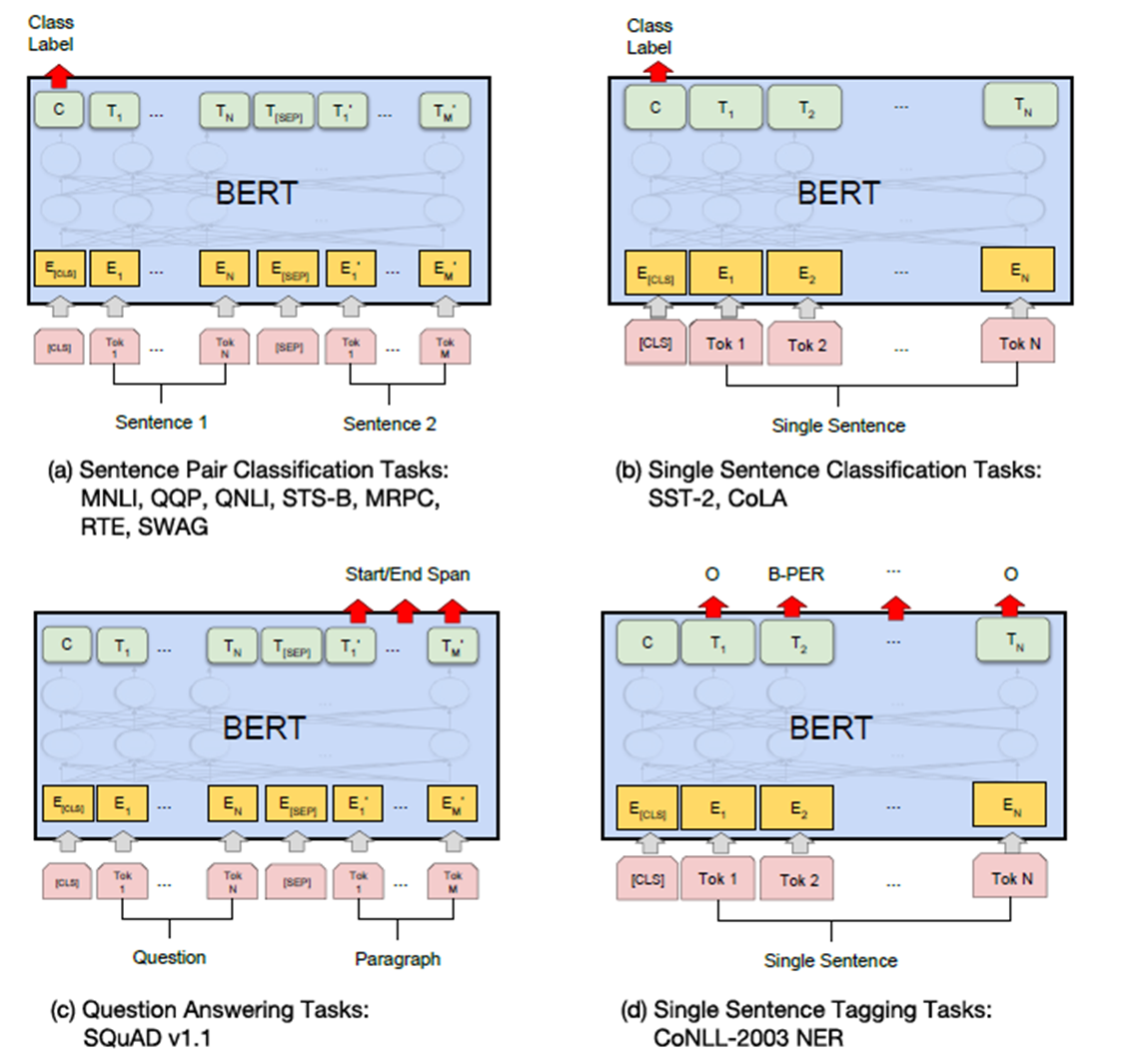
在图4中可以看到对不同任务的BERT进行微调的示例。我们的特定于任务的模型是通过合并BERT和一个额外的输出层形成的,因此需要从头开始学习参数的最小数量。在这些任务中,(a)和(b)是顺序级任务,(c)和(d)是标记级任务。图中,E表示输入嵌入,Ti表示token i的上下文表示, [CLS]是分类输出的特殊符号,[SEP]是分离非连续token序列的特殊符号。
B Detailed Experimental Setup
B.1 Detailed Descriptions for the GLUE Benchmark Experiments.
我们在表1中得到的GLUE结果来自
https://gluebenchmark.com/leaderboard and https://blog.openai.com/language-unsupervised.
GLUE基准包括以下数据集,这些数据集的描述最初在【8】Wang et al. (2018a):
MNLI多流派自然语言推断是一项大规模、众包的隐含分类任务(【5】Williams et al., 2018)。给定一对句子,目标是预测第二个句子相对于第一个句子是暗含的、矛盾的还是中性的。
QQP Quora问题对是一个二元分类任务,目标是确定两个问题在Quora上是语义上等价的(Chen et al., 2018)。
QNLI问题自然语言推理是斯坦福大学问题回答的一个版本数据集【6】(Rajpurkar et al., 2016)已经转换为一个二元分类任务(Wang et al., 2018a)。积极的例子是(问题,句子)对包含正确的答案,和消极的例子是(问题,句子)从同一段不包含答案。
SST-2斯坦福情绪树形库是一个二元单句分类任务,由从电影评论中提取的句子和人类对其情绪的注释组成(Socher et al., 2013)。
CoLA:语言可接受性语料库是一个二元单句分类任务,其目标是预测一个英语句子在语言上是否"可接受"(Warstadt et al., 2018)。
STS-B语义文本相似性基准是一组从新闻标题和其他来源(Cer et al.,2017)。他们用1到5的分数来标注这两个句子在语义上的相似程度。
MRPC微软研究释义语料库(MRPC Microsoft Research ase Corpus)由自动从在线新闻源提取的句子对组成,并通过人工注释判断句子在语义上是否相同(Dolan and Brockett, 2005)。
RTE识别文本蕴涵是一个与MNLI类似的二元隐含任务,但是使用的训练数据要少得多(Bentivogli et al., 2009)。
WNLI:Winograd NLI是一个小型的自然语言推理数据集(Levesque et al., 2011)。GLUE页面注意到这个数据集的构造存在一些问题,每一个被提交到GLUE的训练过的系统都比预测多数类的65.1基线准确度要差。因此,我们排除这个集合以保证OpenAI GPT的公平性。为我们的GLUE提交,
C Additional Ablation Studies
C.1 Effect of Number of Training Steps
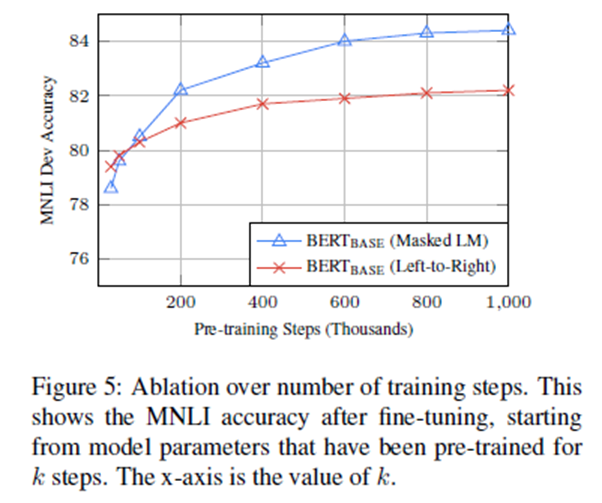
图5展示了MNLI开发在经过k步预训练的检查点进行微调后的准确性。这使我们能够回答以下问题:
1. 问:BERT真的需要如此大量的预训练(128,000 words/batch * 1,000,000 steps)来达到很高的微调精度吗?
答:是的,BERT_BASE几乎做到了与500k步训练相比,MNLI在1M步训练时的准确度提高了1.0%。
2 问:MLM预训是否比LTR预训收敛慢,因为每批预训中只有15%的单词是预测的,而不是每个单词?
答:MLM模式确实比LTR模式收敛稍微慢一些。然而,在绝对准确性方面,MLM模式几乎立即开始超越LTR模式。
C.2 Ablation for Different Masking Procedures
在3.1节中,我们提到BERT在使用掩蔽语言模型进行预训练时使用混合策略来掩蔽目标标记(MLM)的目标。以下是一项消融研究,以评估不同掩蔽策略的效果。
注意,屏蔽策略的目的是减少预训练和微调之间的不匹配,因为[MASK]符号在微调阶段从未出现。我们报告的开发结果为MNLI和NER。对于NER,我们报告了微调和基于特征的方法,因为我们预期基于特征的方法的不匹配将被放大,因为模型将没有机会调整表示。
结果见表8。在表中, MASK意味着我们用MLM的[蒙版]符号替换目标令牌;这意味着我们保持目标令牌不变;RND意味着我们用另一个随机令牌替换目标令牌。
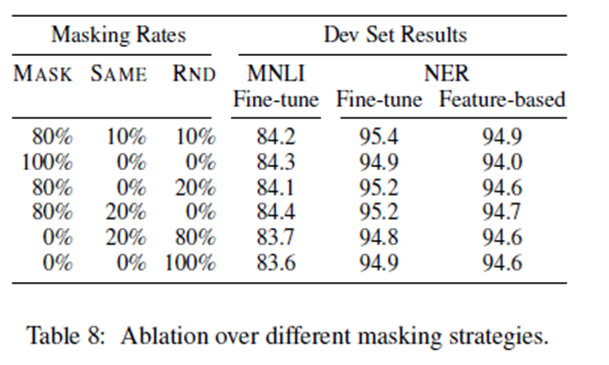
表格左边的数字代表了在传销培训前使用的特定策略的概率(伯特使用80%,10%,10%)。论文的右边部分代表了Dev设置结果。对于基于特性的方法,我们将BERT的最后4层连接起来作为特性,这在第5.3节中被证明是最好的方法。
参考文献
【0-1】本英文地址:https://arxiv.org/abs/1810.04805
【0-2】Github 地址: https://github.com/ google-research/bert.
【1】Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018a. Deep contextualized word representations. In NAACL. --ELMo
【2】Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding with unsupervised learning. Technical report, OpenAI. (Improving Language Understanding by Generative Pre-Training 大部分上面是这个标题) --GPT
【3】Andrew M Dai and Quoc V Le. 2015. Semi-supervised sequence learning. In Advances in neural information processing systems, pages 3079–3087.
【4】Jeremy Howard and Sebastian Ruder. 2018. Universal language model fine-tuning for text classification. In ACL. Association for Computational Linguistics.
【5】Adina Williams, Nikita Nangia, and Samuel R Bowman. 2018. A broad-coverage challenge corpus for sentence understanding through inference. In NAACL.
【6】Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. Squad: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392. --4次
【7】Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Processing Systems, pages 6000–6010. --transformer
【8】Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. 2018a.Glue: A multi-task benchmark and analysis platform
【9】Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol. 2008. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th international conference on Machine learning, pages 1096–1103. ACM
说明:因为BERT作为非常火的LM,所以将论文全部翻译了下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号