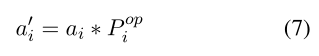【NLP-2019-SA】翻译-Exploiting BERT for End-to-End Aspect-based Sentiment Analysis-2019ACL
摘要
基于方面的情感分析产出:
1.自然语言句子的方面术语 2.及其对应一种情感。
传统的方式:任务以流水线方式完成,先进行方面术语的提取,再对提取的方面术语进行情感预测。
传统的方式的缺点:虽然更容易开发,但是这种方法没有充分利用来自两个子任务的联合信息,也没有使用可能有用的所有可用的培训信息来源,比如文档级标记的情感语料库。
本文方法:提出了一种交互式多任务学习网络(interactive multi-task learning network 后面简称 IMN),该网络能够在单词级别和文档级别同时学习多个任务。
区别于传统多任务学习方法:传统的多任务学习方法依赖于学习不同任务的共同特征,IMN引入了一种消息传递体系结构,其中信息通过一组共享的潜在变量迭代地传递给不同的任务。实验结果表明,该方法在三个基准数据集上具有良好的多基线性能。
1. 介绍
基于方面的情感分析(Aspect-based sentiment analysis ABSA)目的是确定人们对特定方面的态度。通过提取显式的方面描述,称为方面术语提取(aspect term Extraction AE),然后去检测每个提取的方面术语的情感极性,称为方面级别的情绪分类(aspect-level sentiment classification AS),例如:"Great food but the service is dreadful",方面术语是食物和服务,对它们的情感导向分别是积极地和消极的。
以前的工作之中,AE和AS是典型工作。两个子任务单独处理,流水线作业,不能充分利用两个子任务之间的联合信息。近期提出,(Wang et al., 2018; Liet al., 2019)两篇结果表明,集成模型可以获得与流水线方法相当的结果。两者都使用统一的标记方案将问题表述为单个序列标记任务。他们方法的缺点:
1.仅仅通过统一的标记连接两个任务,没有显式的建模它们之间的相关性。
2.这些方法只学习方面级别的实例,实例的大小通常很小,没有利用其它来源的可用信息,比如文档级别的标记的情感语料库.
本文中,我们提出:
1.IMN——同时解决两个任务,两个任务相互作用。
2.IMN允许AE和AS一起被训练。利用大型文档级语料库中的知识。IMN引入了一种新的消息传递机制,允许任务之间进行信息交互。
3.消息传递机制,任务之间进行信息交互(它将来自不同任务的有用信息发送回共享的潜在表示,然后将信息与共享的潜在表示相结合,在此基础上进一步处理任务,此操作迭代执行,允许随着迭代的次数增加而在多个连接之间修改和传播信息。与大多数通过学习共享信息的多任务学习方案同)。IMN不仅共享特征,而且通过消息传递机制显式地建模任务之间的交互,允许不同的任务更好地相互影响。
此外,IMN允许细粒度的记号级(token level)分类任务与文档级(document-level)分类任务一起训练。合并了两个文档级别的分类任务——情感分类(sentiment classification DS)和域分类(domain classification DD)——与AE和AS联合训练,允许方面级别的任务从文档级别的信息中受益,实验结果较好。实验结果表明,该方法在三个基准数据集上具有较好的性能
注释:{B, I}-{POS, NEG, NEU}分别表示一个方面词的开头和里面有积极的消极的或中性的感情,O表示背景词。
2. 相关工作
基于情感分析,现有方法(Qiu et al., 2011; Yin et al., 2016; Wang et al., 2016a, 2017; Li and Lam, 2017; He et al.,2017; Li et al., 2018b; Angelidis and Lapata,2018) and AS (Dong et al., 2014; Nguyen and Shirai,2015; Vo and Zhang, 2015; Tang et al., 2016a;Wang et al., 2016b; Zhang et al., 2016; Liu and Zhang, 2017; Chen et al., 2017; Cheng et al., 2017; Tay et al., 2018; Ma et al., 2018; He et al., 2018a,b;Li et al., 2018a) :将ABSA分解为两个子任务,并在管道中(两个子任务不相关的流水线)解决。
单独处理的缺点:
1.第一步的错误传向第二步,导致向整体性能下降
2.这种方法不能利用任务之间的共性和关联,这可能有助于减少训练两个任务所需的训练数据量
以前尝试开发集成的解决方案:(Wang et al., 2018; Liet al., 2019)在这个方向上,通过更复杂的网络结构,已经显示出一些有希望的结果。然而,在他们的模型中,这两个子任务仍然只通过一个统一的标记方案进行链接。提出将问题建模为具有统一标注方案的序列标注任务,且任务间没有交互
为了解决这个问题,需要一个更好的网络结构来允许更多的任务交互。
多任务学习:同时执行AE和AS的一个直接方法是多任务学习,其中一个传统的框架是使用一个共享网络和两个特定于任务的网络来派生一个共享的特征空间和两个特定于任务的特征空间。多任务学习框架已成功地应用于各种自然语言处理中(NLP)任务。多任务学习通过使用一个共享的表示来并行学习语义相关的任务,可以捕获任务之间的相关性,并在某些情况下提高模型的泛化能力。(2018b)结果表明,通过与文献层次的情感分类相结合的训练,可以显著提高方面层次的情感分类。然而,传统的多任务学习仍然没有明确地对任务之间的交互进行建模——这两个任务只是通过错误的反向传播相互作用,从而对学习的特征作出贡献,而这种隐含的交互作用是不可控制的。
本文IMN不仅允许共享表示,而且通过使用迭代消息传递模式显式地对任务之间的交互进行建模。传播的信息有助于学习和推理,从而提高ABSA的整体性能。
消息传递体系结构
计算机视觉中的用于消息传递的图模型推理算法网络结构。将消息传递算法的执行建模为一个网络,可以得到递归神经网络结构。(区别于循环神经网络和递归神经网络,一个是时间上的,一个是空间上的)
我们在网络中传播信息并学习更新,但是该体系结构是为解决多任务学习问题而设计的。我们的算法可以看作是一个递归神经网络,因为每次迭代都使用相同的网络来更新共享的潜在表示变量。
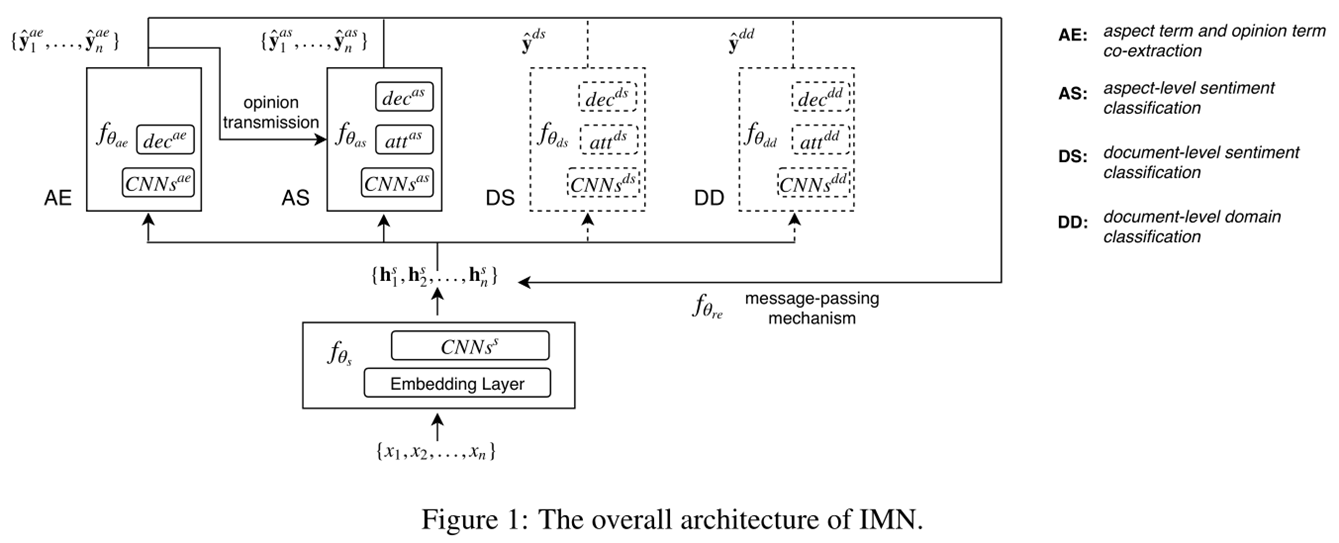
3. 提出的方法
![]()


3.1 Aspect-Level任务



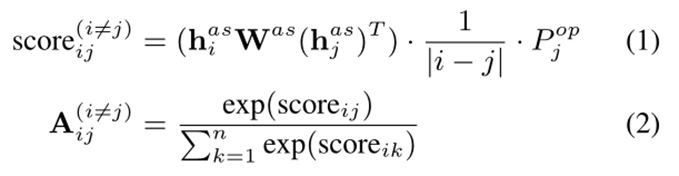

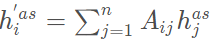
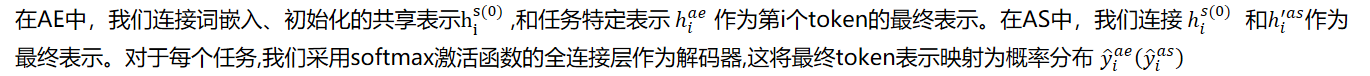
3.2 Document-Level任务

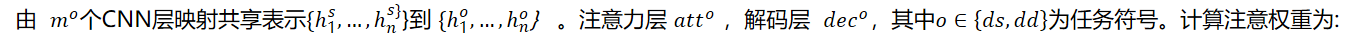
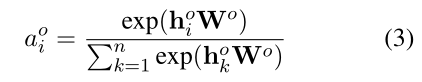

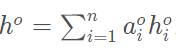

3.3 Message Passing Mechanism(消息传递机制)

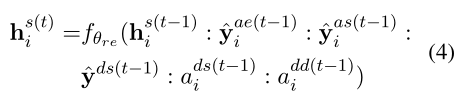

3.4 Learning
方面级问题的实例只有方面级标签,文档级问题的实例只有文档标签。IMN交替在方面级和文档级实例上进行训练。在aspect级实例中,这个函数如下:
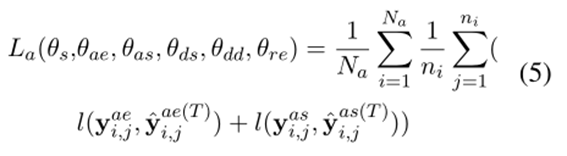

在文档级样本上进行训练时,我们将以下损失最小化:
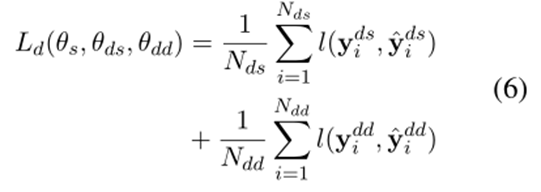
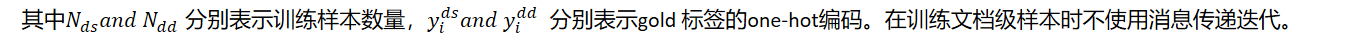


4. 实验
4.1 Experimental Settings
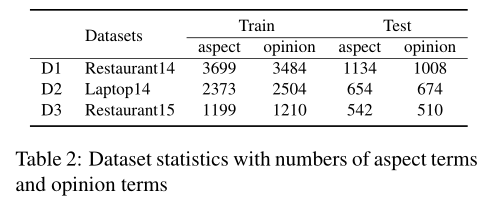
数据集

网络的细节
我们提出的网络采用(Xu et al., 2018)的多层CNN结构作为基于CNN的编码器。实现细节见附录A。对于词嵌入的初始化,我们将一个通用的嵌入矩阵和一个特定领域的嵌入矩阵连接起来(Xuetal.,2018)。我们采用了他们发布的餐馆和笔记本电脑领域的100维特定领域词嵌入,这些词嵌入是在使用fastText的大型特定领域语料库上训练的。通用词嵌入是预训练好的300维Glove 向量。



评价指标

我们使用五个度量来进行评估,其中两个度量AE性能,两个度量AS性能,一个度量总体性能。AE现有工作(Wang et al., 2017;(Xu et al., 2018),我们使用F1来衡量方面术语提取和观点术语提取的性能,分别表示为F1-a和F1-o。AS现有工作(Chen et al., 2017;He et al., 2018b),我们采用准确性和宏观F1值来衡量AS的性能。我们称它们为acc-s和F1-s。由于我们在解决集成任务时没有假设提供了gold方面术语,所以这两个度量是基于从AE中正确提取的方面术语计算的。我们计算集成任务的F1值(记为F1- I)来度量总体性能。为了计算F1-I,只有当跨度和情感都被正确识别时,提取的方面术语才被认为是正确的。在计算F1-a时,我们考虑了所有方面的术语,而在计算acc-s、F1-s和F1-I时,我们忽略了带有冲突情绪标签的方面术语。
4.2 比较模型
管道的方法
我们为每个AE和AS从之前的工作中选择两个最优模型,构建2×2的管道基线。对于AE,我们使用CMLA (Wang et al., 2017)和DECNN (Xu et al., 2018)。CMLA提出了通过建模方面和观点术语之间的相互依赖关系来实现方面和观点术语的协同提取。DECNN是AE最先进的模型。它利用了多层CNN结构,具有通用和特定领域的嵌入。我们在IMN中使用与编码器相同的结构。对于AS,我们使用ATAELSTM(简称ALSTM) (Wang et al., 2016b)和来自(He et al., 2018b)的模型,我们称之为dTrans。ALSTM是一种基于注意力的LSTM结构的代表作品。我们将其与dTrans进行了比较,因为dTrans也利用了文档语料库中的知识来提高性能,从而达到了最先进的结果。因此,我们比较了以下管道方法:CMLA-ALSTM、CMLA-dTrans、DECNN-ALSTM和DECNN-dTrans。我们还比较了管道设置的IMN,其中训练AE和AS独立(例如,没有参数共享、信息传递和文档级语料库)。我们称它为管道。管道中AE的网络结构与DECNN的相同。在测试所有方法的过程中,我们首先执行AE,然后生成正确提取的方面术语作为预测。
集成的方法

4.3 Results and Analysis
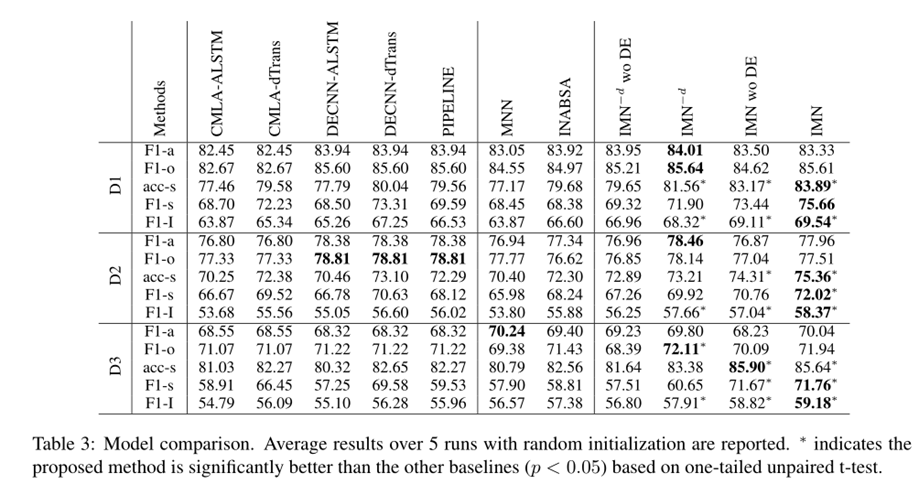

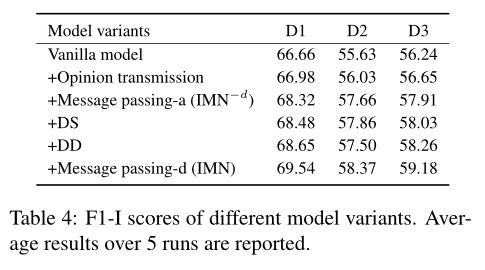

Impact of T 我们已经证明了消息传递机制的有效性。在这里,我们研究了最大迭代次数T的影响。表6显示了随着T的增加,F1-I对测试集的变化。我们发现在两到三次迭代中可以很快地实现收敛,而进一步的迭代并不能提供可观的性能改进。案例研究。为了更好地理解所提出的方法在什么情况下有用,我们检查了被管道和INABSA错误分类但被IMN正确分类的实例。对于方面提取,我们发现消息传递机制在两个场景中特别有用。首先,它有助于更好地利用来自观点上下文的信息来识别不寻常方面的术语。如表5中的例1所示,管道和INABSA无法识别"build",因为它在训练集中是一个不常见的方面术语,而IMN能够正确识别它。我们发现,当不执行消息传递迭代时,IMN也不能识别"build"。但是,当我们分析句子中每个token上的预测情感分布时,我们发现除了"durability"外,只有"build"具有较强的积极情感,而其他token上的情感分布更为均匀。这表明"build"也是一个方面术语。IMN能够通过消息传递机制聚合这些知识,从而能够在以后的迭代中正确识别"build"。由于相同的原因,消息传递机制也有助于避免提取没有表达观点的术语。如例2所示,管道和INABSA都提取"Pizza"。但是,由于在给出的句子中没有表达观点,所以"Pizza"不应该被认为是一个方面级术语。IMN通过将意见观点预测和情感预测中的知识聚合在一起来避免提取这类术语。
对于方面级情感,因为IMN训练大文档级标注语料库与平衡情感类,一般来说它更好地体现特定域的观点词的意思(例3),更好地捕捉情感复杂的表达式,比如否定(例4),和更好的认识到小情感类方面级别数据集(负面和中性在我们的情况下)。此外,我们发现文档级任务通过消息传递传播的知识是有帮助的。例如,与情感相关的注意权重有助于识别不常见的观点词,进而有助于正确预测方面词的情感。如例5所示,PIPELINE和INABSA无法将"划痕"识别为观点术语,并对方面术语"aluminum铝"做出了错误的情感预测。IMN通过之前的消息传递迭代所累积的与情感相关的注意力权值,通过知识得知"划痕"与情感相关,因此能够轻松提取"划痕"。由于AE的观点预测被发送到AS组件的self-attention层,正确的观点预测进一步帮助推断出对"aluminum"的正确情感。
5. 总结
提出了一种交互式多任务学习网络IMN,用于联合学习方面和观点术语的共同提取,以及方面层次的情感分类。提出的IMN引入了一种新的消息传递机制,允许任务之间进行信息交互,从而更好地利用相关性。此外,IMN能够从多个训练数据源中学习,允许细粒度的token级任务从文档级标记的语料库中受益。该体系结构可能适用于类似的任务,如关系提取、语义角色标注等。
附录
A Implementation Details
CNN-based Encoder
我们采用(Xu et al., 2018)提出的多层CNN结构作为基于CNN的编码器,用于共享CNN和特定于任务的CNN。每个CNN层有许多一维卷积过滤器,和每个过滤器都有一个固定的内核大小k = 2c + 1,这样每个过滤器执行卷积操作的窗口 k 字表示,和计算第 i 个词的表示以及四周 2c 语言的上下文。
按照原文的设置,共享编码器的第一层CNN有128个过滤器,内核大小k = 3, 128个过滤器,内核大小k = 5。共享编码器中的其他CNN层和每个特定于任务的编码器中的CNN层有256个过滤器,每个层的内核大小k = 5。ReLu是每个CNN层的激活函数。在嵌入层和每个CNN层之后使用p = 0.5的Dropout。
舆论传播

B Model Comparison Details
对于CMLA8、ALSTM9、dTrans10和INABSA11,我们使用官方发布的源代码进行实验。对于MNN,由于源代码不可用,我们按照本文中的描述重新实现了模型。我们使用随机初始化多次运行每个基线,并保存它们的预测结果。我们使用一个统一的评估脚本来度量来自不同baseline的输出以及所提出的方法。该方法在模型训练过程中利用附加的观点术语标签,实现了观点术语和观点术语的共提取。在baseline中,MNN和INABSA两种集成方法和DECNN作为AE组件的管道方法在训练过程中不获取意见信息。为了进行公平的比较,我们在MNN、INABSA和DECNN的原始标签集上添加了标签{BP, IP},表示观点术语的开始和内部。我们在训练集上用方面和观点术语标签训练这些模型来执行共提取。此外,对于流水线方法,我们还在训练期间为AS模型(ALSTM和dTrans)提供了gold opinion术语。为了使ALSTM和dTrans利用观点标签信息,我们修改了它们的注意力层,为更可能成为观点术语一部分的标记分配更高的权重。这是合理的,因为在AS模型中注意力机制的目标是找到相关的观点语境。将第i个token在输入语句中应用softmax归一化之前的注意权值修改为: