【NLP-02】NNLM
目录
- 研究背景
- 离散表示
- 分布式表示
- 神经网络
NNLM (Neural Network Language model),神经网络语言模型是03年提出来的,通过训练得到中间产物–词向量矩阵,这就是我们要得到的文本表示向量矩阵。
1、研究背景
维数灾难(curse of dimensionality)是语言模型和其他一些学习问题的基础问题。进一步的,当我们对连续变量进行建模时,通过根据目标函数的局部光滑特性进行学习,可以相对容易的对目标函数进行泛化;但在离散空间中,待学习的结构通常不明确,任何一个离散变量的改变都可能对待估函数的取值产生重大影响,而且,当每一个离散变量的取值范围都很大时,大多数观察对象之间的海明距离都变得很远。这说明了维度约减的重要性。
n-gram模型的单词序列长度,即n通常小于3(基于计算效率的考虑),并且没有考虑单词之间的语义信息。这是Neural Probabilistic Language Model的动机。
2、神经网络模型
学习目标:得到模型f,使得

该模型可分为特征映射和计算条件概率分布两部分:
- 特征映射:一个从词汇表V(V 是所有单词的集合,即词典)到实数向量空间的映射C。通过这个映射得到每个单词的向量表示。因此C实际上是一个|V|×m的矩阵(m是单词向量的维数);

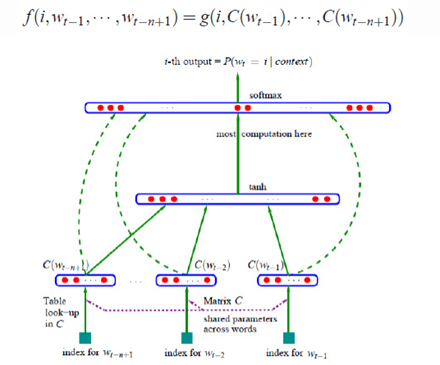
下面重点介绍神经网络的结构,网络输出层采用的是softmax函数,如下式所示:
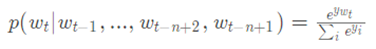


三、模型训练
模型的训练目标是最大化以下似然函数:
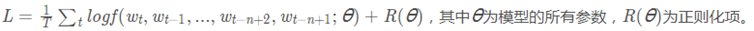
使用梯度下降算法更新参数的过程如下:
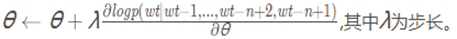
上述过程可以归结为三步:
- 将单词映射到m维的特征空间中;
- 使用单词序列的对应向量集合作为输入表达单词序列的联合概率方程;
- 同步学习单词的特征向量和概率函数。
注意:在本文中作者仍然是以学习语言生成模型为主要目标的,但在word2vec中,作者以获得理想的单词向量为目标。
四、总结
由于NNLM模型使用了低维紧凑的词向量对上文进行表示,这解决了词袋模型带来的数据稀疏、语义鸿沟等问题。显然nnlm是一种更好的n元语言模型;另一方面在相似的上下文语境中,nnlm模型可以预测出相似的目标词,而传统模型无法做到这一点。其优势可见下面一个例子(因为神经网络是一个向量模型):

参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号