【NLP-01】词嵌入的发展过程(Word Embedding)
目录
- 什么是词嵌入(Word Embedding)
- 离散表示
- 分布式表示
- 神经网络
一、什么是词嵌入(Word Embedding)
词是自然语言表义的基本单元。我们之所以认识词语,是因为我们大脑中建立了很多映射连接。那计算机怎么去识别呢?这也是词嵌入引出的原因:把词映射为实数域向量的技术也叫词嵌入(word embedding),核心思想就是见每个词映射成低维空间(通常K=50-300维)上的一个稠密向量(Dense Vector)。
在NLP(自然语言处理)领域,文本表示是第一步,也是很重要的一步,通俗来说就是把人类的语言符号转化为机器能够进行计算的数字,因为普通的文本语言机器是看不懂的,必须通过转化来表征对应文本。早期是基于规则的方法进行转化,而现代的方法是基于统计机器学习的方法。
弄懂文本表示的发展历程,对于NLP学习者来说是必不可少的。接下来开始我们的发展历程。文本表示分为离散表示和分布式表示:
二、离散表示
2.1 One-hot表示
One-hot简称读热向量编码,也是特征工程中最常用的方法。其步骤如下:
- 构造文本分词后的字典,每个分词是一个比特值,比特值为0或者1。
- 每个分词的文本表示为该分词的比特位为1,其余位为0的矩阵表示。
每个词典索引对应着比特位。那么利用One-hot表示为:
One-hot表示文本信息的缺点(主要是不能稠密表示,具体表现如下):
- 比较起来很困难,英文相对还好(2000个单词),中文(1W多个词)
- 随着语料库的增加,数据特征的维度会越来越大,产生一个维度很高,又很稀疏的矩阵。
- 这种表示方法的分词顺序和在句子中的顺序是无关的,不能保留词与词之间的关系信息。
2.2 词袋模型
词袋模型(Bag-of-words model),像是句子或是文件这样的文字可以用一个袋子装着这些词的方式表现,这种表现方式不考虑文法以及词的顺序。
文档的向量表示可以直接将各词的词向量表示加和。例如:
|
1 |
John likes to watch movies. Mary likes too John also likes to watch football games. |
以上两句可以构造一个词典:
|
1 |
{"John": 1, "likes": 2, "to": 3, "watch": 4, "movies": 5, "also": 6, "football": 7, "games": 8, "Mary": 9, "too": 10} |
那么第一句的向量表示为:[1,2,1,1,1,0,0,0,1,1],其中的2表示likes在该句中出现了2次,依次类推。
词袋模型同样有一下缺点:
- 词向量化后,词与词之间是有大小关系的,不一定词出现的越多,权重越大。
- 词与词之间是没有顺序关系的。
2.3 TF-IDF
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF意思是词频(Term Frequency),IDF意思是逆文本频率指数(Inverse Document Frequency)。
字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。一个词语在一篇文章中出现次数越多, 同时在所有文档中出现次数越少, 越能够代表该文章。
![]()

分母之所以加1,是为了避免分母为0。
那么,TF−IDF=TF*IDF,从这个公式可以看出,当w在文档中出现的次数增大时,而TF-IDF的值是减小的,所以也就体现了以上所说的了。
缺点:依然是词与词之间是没有顺序关系的。
2.4 n-gram模型
n-gram模型为了保持词的顺序,做了一个滑窗的操作,这里的n表示的就是滑窗的大小,例如2-gram模型,也就是把2个词当做一组来处理,然后向后移动一个词的长度,再次组成另一组词,把这些生成一个字典,按照词袋模型的方式进行编码得到结果。改模型考虑了词的顺序。
例如:
|
1
|
John likes to watch movies. Mary likes too John also likes to watch football games. |
以上两句可以构造一个词典:
|
1 |
{"John likes": 1, "likes to": 2, "to watch": 3, "watch movies": 4, "Mary likes": 5, "likes too": 6, "John also": 7, "also likes": 8, "watch football": 9, "football games": 10} |
那么第一句的向量表示为:[1, 1, 1, 1, 1, 1, 0, 0, 0, 0],其中第一个1表示John likes在该句中出现了1次,依次类推。
缺点:维度灾难,随着n的大小增加,词表会成指数型膨胀,会越来越大。
2.5 离散表示存在的问题
- 无法衡量词向量之间的关系。
- 词表的维度随着语料库的增长而膨胀。
- n-gram词序列随语料库增长呈指数型膨胀,更加快。
- 离散数据来表示文本会带来数据稀疏问题,导致丢失了信息,与我们生活中理解的信息是不一样的。
三、分布式表示
为了提高模型的精度,又发明出了分布式的表示文本信息的方法,这就是这一节需要介绍的。
用一个词附近的其它词来表示该词,这是现代统计自然语言处理中最有创见的想法之一。当初科学家发明这种方法是基于人的语言表达,认为一个词是由这个词的周边词汇一起来构成精确的语义信息。就好比,物以类聚人以群分,如果你想了解一个人,可以通过他周围的人进行了解,因为周围人都有一些共同点才能聚集起来。
3.1 共现矩阵
共现矩阵顾名思义就是共同出现的意思,词文档的共现矩阵主要用于发现主题(topic),用于主题模型,如LSA。
局域窗中的word-word共现矩阵可以挖掘语法和语义信息,例如:
I like deep learning.
I like NLP.
I enjoy flying
有以上三句话,设置滑窗为2,可以得到一个词典:
{"I like","like deep","deep learning","like NLP","I enjoy","enjoy flying","I like"}
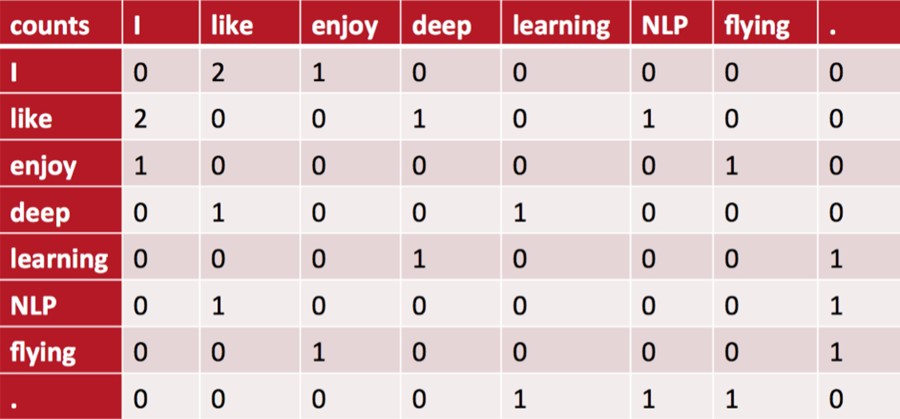
中间的每个格子表示的是行和列组成的词组在词典中共同出现的次数,也就体现了共现的特性。
存在的问题:
向量维数随着词典大小线性增长。
存储整个词典的空间消耗非常大。
一些模型如文本分类模型会面临稀疏性问题。
模型会欠稳定,每新增一份语料进来,稳定性就会变化。
四、神经网络
上面的模型都有很多弊端,最大的就是体现每个词或者词组需要一个维度向量来表示,可能会产生维度在灾难。有几种改进形式:
4.1 NNLM(Neural Network Language model)
首先可以考虑GAN对抗生成形式来机器学习,另一种就是NNLM,

本模型主要发明之初用于训练从上文推到下文信息,后来发现能用于embedding训练。
4.2 word2Vec
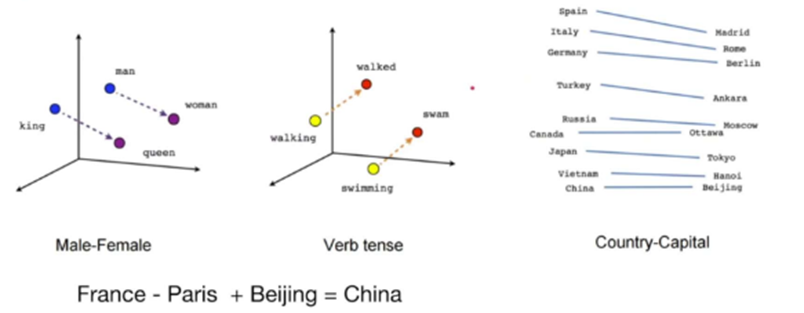
该模型在2013年被发现,有两种形式:一种CBOW(由上下文推测中间单词,效果较好,为后面算法提供思路),一种skip-Gram(由中间词推测上下文词语)

为了减少计算,提出了两种优化方法:
层次Softmax:至此还没有结束,因为如果单单只是接一个softmax激活函数,计算量还是很大的,有多少词就会有多少维的权重矩阵,所以这里就提出层次Softmax(Hierarchical Softmax),使用Huffman Tree来编码输出层的词典,相当于平铺到各个叶子节点上,瞬间把维度降低到了树的深度,可以看如下图所示。这课Tree把出现频率高的词放到靠近根节点的叶子节点处,每一次只要做二分类计算,计算路径上所有非叶子节点词向量的贡献即可。
负例采样(Negative Sampling):这种优化方式做的事情是,在正确单词以外的负样本中进行采样,最终目的是为了减少负样本的数量,达到减少计算量效果。将词典中的每一个词对应一条线段,所有词组成了[0,1]间的剖分,然后每次随机生成一个[1, M-1]间的整数,看落在哪个词对应的剖分上就选择哪个词,最后会得到一个负样本集合。
Word2Vec存在的问题
- 对每个local context window单独训练,没有利用包含在global co-currence矩阵中的统计信息。
- 对多义词无法很好的表示和处理,因为使用了唯一的词向量
4.3 GloVe
GloVe的全称叫Global Vectors for Word Representation,它是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具,它可以把一个单词表达成一个由实数组成的向量,这些向量捕捉到了单词之间一些语义特性,比如相似性(similarity)、类比性(analogy)等。我们通过对向量的运算,比如欧几里得距离或者cosine相似度,可以计算出两个单词之间的语义相似性。
word2vec最大的缺点则是没有充分利用所有的语料,但GloVe和word2vec实际表现其实差不多。(也有说实际性能要优于word2vec)
4.4 ELMo
是2018年年初发明的模型,在一词多义方面取得了很大发展,使用了双向LSTM。大体如下图所示。

4.5 BERT
2018年年底发明的模型,结合了CBOW的思想,ELMo的结构,借鉴GPT模型的Transformer部件,使得模型效果刷新NLP的多项记录。

本节的模型较多,此处只是简单介绍,计划后续单独进行展开

