目标检测:介绍及传统方法
计算机视觉中关于图像识别有四大类任务:
- 分类-Classification:解决"是什么?"的问题,即给定一张图片或一段视频判断里面包含什么类别的目标。
- 定位-Location:解决"在哪里?"的问题,即定位出这个目标的的位置。
- 检测-Detection:解决"是什么?在哪里?"的问题,即定位出这个目标的的位置并且知道目标物是什么。
- 分割-Segmentation:分为实例的分割(Instance-level)和场景分割(Scene-level),解决"每一个像素属于哪个目标物或场景"的问题。
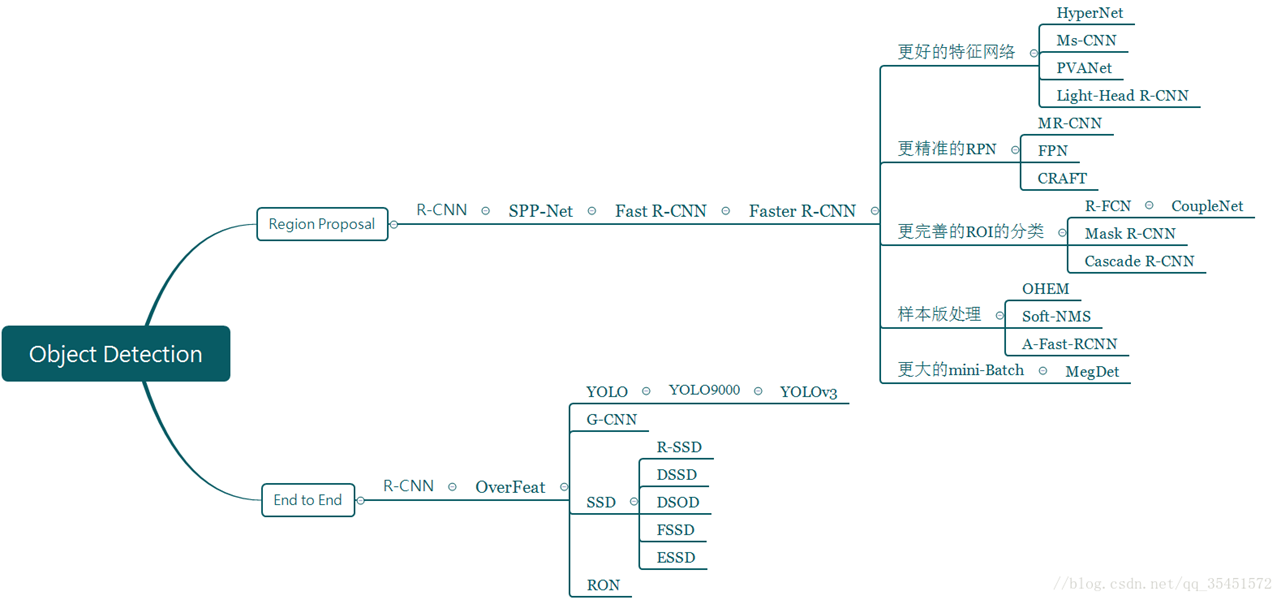
一、目标检测常见算法
除了图像分类之外,目标检测要解决的核心问题是:
1.目标可能出现在图像的任何位置。
2.目标有各种不同的大小。
3.目标可能有各种不同的形状。
如果用矩形框来定义目标,则矩形有不同的宽高比。由于目标的宽高比不同,因此采用经典的滑动窗口+图像缩放的方案解决通用目标检测问题的成本太高。
目前学术和工业界出现的目标检测算法分成3类:
1. 传统的目标检测算法:Cascade + HOG/DPM + Haar/SVM以及上述方法的诸多改进、优化;
2. 候选区域/窗 + 深度学习分类:通过提取候选区域,并对相应区域进行以深度学习方法为主的分类的方案,如:
R-CNN(Selective Search + CNN + SVM)
SPP-net(ROI Pooling)
Fast R-CNN(Selective Search + CNN + ROI)
Faster R-CNN(RPN + CNN + ROI)
R-FCN等系列方法;
3. 基于深度学习的回归方法:YOLO/SSD/DenseBox 等方法;以及最近出现的结合RNN算法的RRC detection;结合DPM的Deformable CNN等

传统目标检测流程:
1)区域选择(穷举策略:采用滑动窗口,且设置不同的大小,不同的长宽比对图像进行遍历,时间复杂度高)
2)特征提取(SIFT、HOG等;形态多样性、光照变化多样性、背景多样性使得特征鲁棒性差)
3)分类器分类(主要有SVM、Adaboost等)
二、传统的目标检测算法
2.1 图像识别的任务
这里有一个图像任务:既要把图中的物体识别出来,又要用方框框出它的位置。
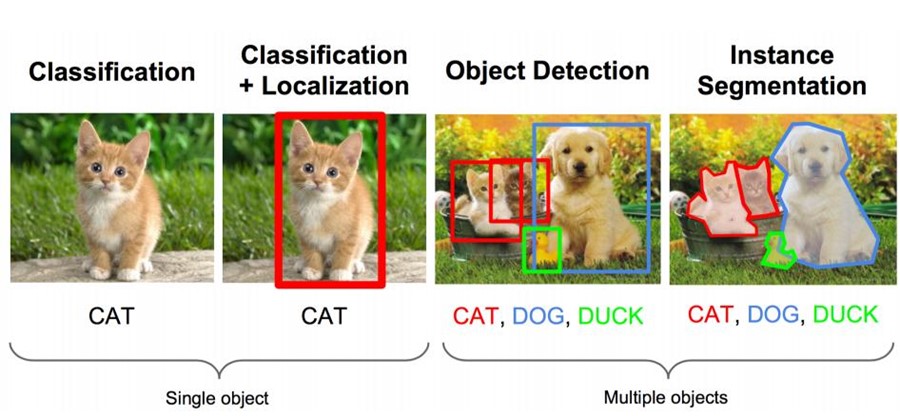
这个任务本质上就是这两个问题:一:图像识别,二:定位。
1)图像识别(classification):
输入:图片
输出:物体的类别
评估方法:准确率
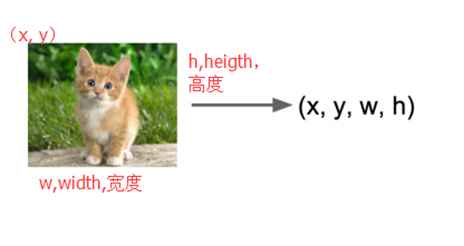
2)定位(localization):
输入:图片
输出:方框在图片中的位置(x,y,w,h)
评估方法:检测评价函数 intersection-over-union(简单来讲就是模型产生的目标窗口和原来标记窗口的交叠率)。
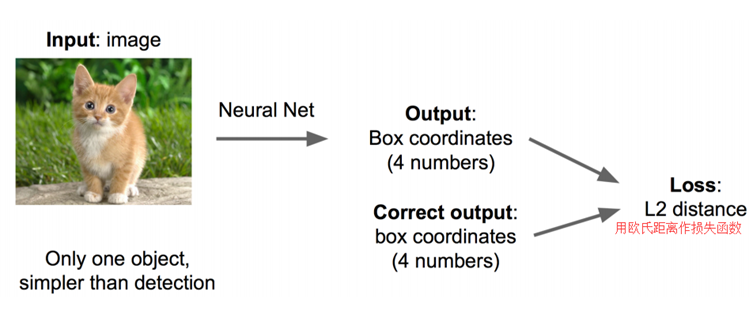
卷积神经网络CNN已经帮我们完成了图像识别(判定是猫还是狗)的任务,我们只需要添加一些额外的功能来完成定位任务即可。定位的问题的解决思路有哪些?
思路一:看做回归问题
看做回归问题,我们需要预测出(x,y,w,h)四个参数的值,从而得出方框的位置。
步骤1:
• 先解决简单问题, 搭一个识别图像的神经网络
• 在AlexNet VGG GoogleLenet上fine-tuning一下:

步骤2:
• 在上述神经网络的尾部展开(也就说CNN前面保持不变,我们对CNN的结尾处作出改进:加了两个头:"分类头"和"回归头")
• 成为classification + regression模式
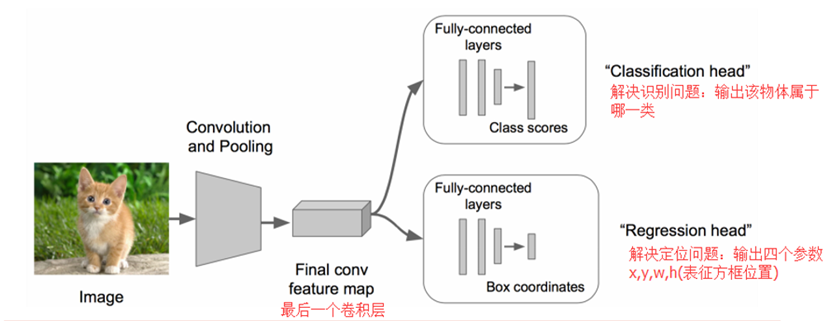
步骤3:
• Regression那个部分用欧氏距离损失
• 使用SGD训练
步骤4:
• 预测阶段把2个头部拼上
• 完成不同的功能
这里需要进行两次fine-tuning
第一次在ALexNet上做,第二次将头部改成regression head,前面不变,做一次fine-tuning
Regression的部分加在哪?
有两种处理方法:
• 加在最后一个卷积层后面(如VGG)
• 加在最后一个全连接层后面(如R-CNN)
regression太难做了,应想方设法转换为classification问题。
regression的训练参数收敛的时间要长得多,所以上面的网络采取了用classification的网络来计算出网络共同部分的连接权值。
思路二:取图像窗口
• 还是刚才的classification + regression思路
• 咱们取不同的大小的"框"
• 让框出现在不同的位置,得出这个框的判定得分
• 取得分最高的那个框

根据得分的高低,我们选择了右下角的黑框作为目标位置的预测。
注:有的时候也会选择得分最高的两个框,然后取两框的交集作为最终的位置预测。
疑惑:框要取多大?
取不同的框,依次从左上角扫到右下角。非常粗暴啊。
总结一下思路:
对一张图片,用各种大小的框(遍历整张图片)将图片截取出来,输入到CNN,然后CNN会输出这个框的得分(classification)以及这个框图片对应的x,y,h,w(regression)。
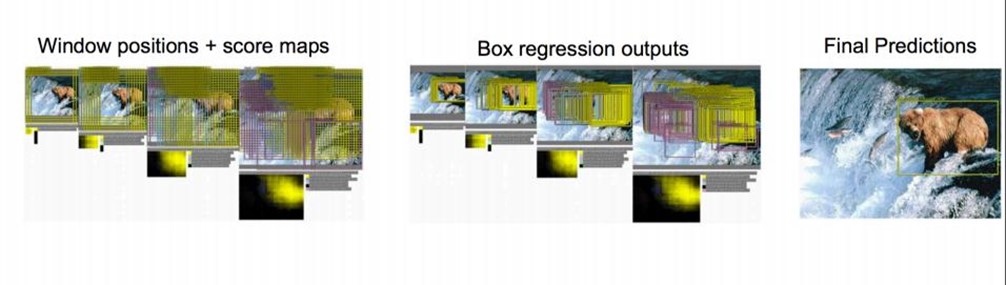
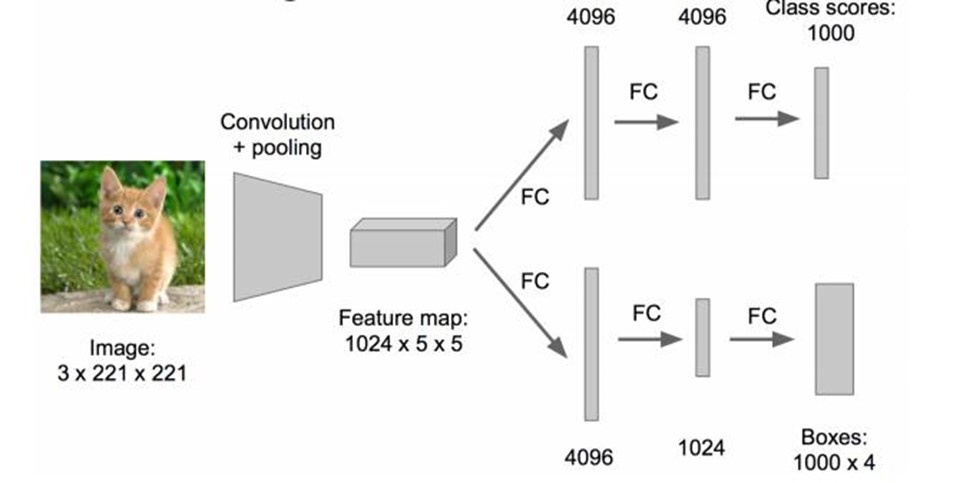
这方法实在太耗时间了,做个优化。原来网络是这样的:
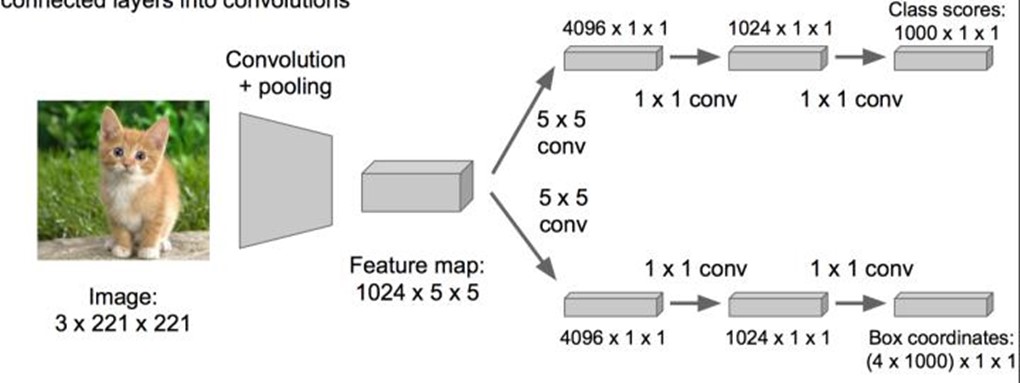
优化成这样:把全连接层改为卷积层,这样可以提提速。
2.2 物体检测(Object Detection)
当图像有很多物体怎么办的?那任务就变成了:多物体识别+定位多个物体。那把这个任务看做分类问题?

看成分类问题有何不妥?
• 你需要找很多位置, 给很多个不同大小的框
• 你还需要对框内的图像分类
• 当然, 如果你的GPU很强大, 恩, 那加油做吧…
三、传统目标检测的主要问题
1)基于滑动窗口的区域选择策略没有针对性,时间复杂度高,窗口冗余
2)手工设计的特征对于多样性的变化没有很好的鲁棒性
以下是各种选定候选框的方法的性能对比。

四、评价指标
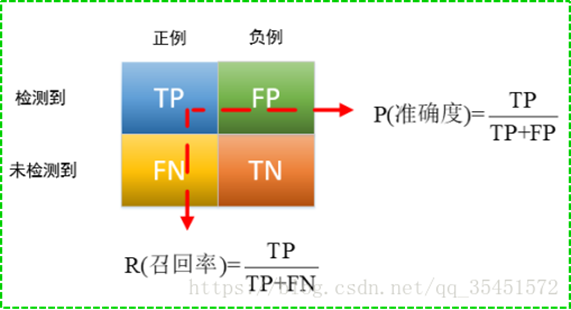
AP、mAP、P-R曲线
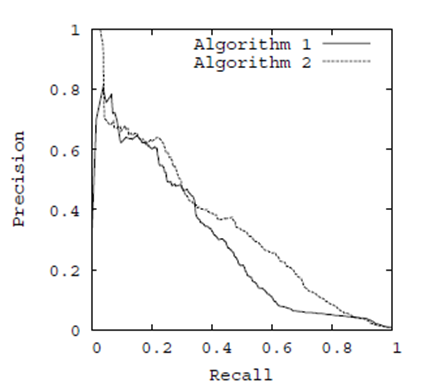
准确率-召回率曲线(P-R曲线):以召回率为横坐标,精确率为纵坐标,用不同的阀值,统计出一组不同阀值下的精确率和召回率。
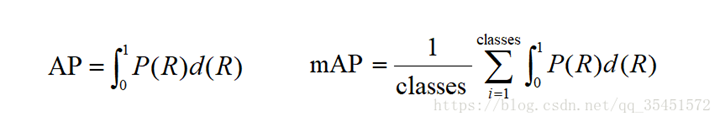
AP(average precision)——P-R曲线下的面积;
mAP(mean average precision)——多个类别AP的平均值。
ROC曲线、AUC
ROC曲线:用不同的阀值,统计出一组不同阀值下的TPR(真阳率)和FPR(假阳率)的关系。
AUC(Area Under Curve):ROC曲线下的面积。
ROC曲线优点:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
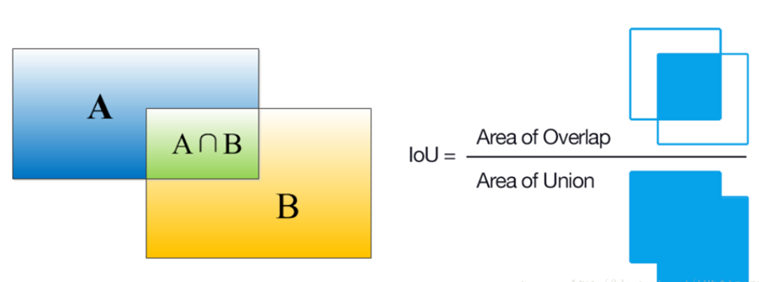
IOU(Intersection over Union):是一种测量在特定数据集中检测相应物体准确度的一个标准,一般来说,这个score > 0.5 就可以被认为一个不错的结果了。
Fps (Frames Per Second):每秒处理图像的帧数
FLOPS:每秒浮点运算次数、每秒峰值速度
主要来自:https://blog.csdn.net/v_JULY_v/article/details/80170182
附件:
最新情况,建议看我的后续文章,或者逛逛:https://github.com/hoya012/deep_learning_object_detection#2014


【推荐】还在用 ECharts 开发大屏?试试这款永久免费的开源 BI 工具!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET制作智能桌面机器人:结合BotSharp智能体框架开发语音交互
· 软件产品开发中常见的10个问题及处理方法
· .NET 原生驾驭 AI 新基建实战系列:向量数据库的应用与畅想
· 从问题排查到源码分析:ActiveMQ消费端频繁日志刷屏的秘密
· 一次Java后端服务间歇性响应慢的问题排查记录
· 互联网不景气了那就玩玩嵌入式吧,用纯.NET开发并制作一个智能桌面机器人(四):结合BotSharp
· Vite CVE-2025-30208 安全漏洞
· 《HelloGitHub》第 108 期
· MQ 如何保证数据一致性?
· 一个基于 .NET 开源免费的异地组网和内网穿透工具