【NLP-2017-SA】翻译-Recurrent Attention Network on Memory for Aspect Sentiment Analysis(2017emnlp)
Abstract
我们的框架采用多注意机制来捕获距离较远的情绪特征, 从而对不相关信息进行更强的鲁棒性。multiple attentions 的结果与递归神经网络的非线性结合,在处理更多的并发时增强了模型的表达能力。加权记忆机制不仅可以帮助我们避免劳动密集型的特征工程工作, 而且还为句子的不同观点目标提供了量身定做的记忆。我们在4个数据集上研究模型的优点: 两个来自 SemEval2014, 即对餐馆和笔记本电脑的评论;twitter 数据集, 用于测试其社交媒体数据的性能;和中文新闻评论数据集, 用于测试其语言敏感性。实验结果表明, 我们的模型在不同类型的数据上始终优于最先进的(state-of-the-art )方法。
Introduction
"方面情绪分析" 的目标是识别评论/评论中表达的特定意见目标的情绪极性 (即消极、中性或积极)。例如, 在 "我买了一部手机, 它的相机是精彩的, 但电池寿命很短", 有三的意见目标, "相机", "电池生活", 和 "手机"。这位评论家对 "相机" 有积极的情绪, 对 "电池寿命" 有负面情绪, 对 "手机" 也有一种混杂的情绪。以句子为导向的情绪分析方法 (Socher et al., 2011; Appel et al., 2016 ) 不能够捕捉到这种细微的情绪的意见目标。
为了确定独立的意见目标的情绪, 一项关键任务是在其原始句子中为目标建立适当的上下文特征。在简单的情况下, 一个目标的情绪是可识别的在一个语法上附近的意见词, 例如 "精彩" 的 "相机"。然而, 在许多情况下, 意见词被包含在更复杂的语境中。例如, "Its camera is not wonderful enough " 可能在 "相机" 上表达中性的情绪, 但不是负面的。这种并发通常会妨碍传统的方面情绪分析方法。
为了对上述 phrase-like 词序列的情绪进行建模 (i.e. "not wonderful enough" ), 提出了基于 LSTM 的方法, 如目标依赖 LSTM (TD-LSTM) (Tang et al., 2015)。TD-LSTM 可能会遭受这个问题, 在它捕捉到远离目标的情绪特征后, 它需要将特征一字不漏的传播到目标, 在这种情况下, 它很可能会丢失此功能, 如 "the phone " 的特征 "cost-effective "在""My overall feeling is that the
phone, after using it for three months and considering its price, is really cost-effective"之中。 注意机制, 已成功地用于机器翻译 (Bahdanau et al., 2014 ), 可以实施一个模型用来更多的关注句子的重要部分。在情绪分析中已经有一些作品利用了这种优势 (Wang et al., 2016; Tang et al., 2016). 。另一种观察是, 某些类型的句子结构对目标情绪分析特别具有挑战性。例如, "Except Patrick, all other actors don't play well ", 词"except " 和 短语"don't play well " 对 "Patrick " 产生积极的情绪。由 LSTM很难合成这些特征, 因为他们的位置是分散的。基于单一注意的方法 (例如, (Wang et al., 2016) ) 也不能克服这样的困难, 因为一个attention 集中在多个单词上可能隐藏每个被关注的词的特征。
【重点】本文提出了在目标情绪分析中解决上述问题的新框架。具体来说, 我们的框架首先采用双向 LSTM (BLSTM) 从输入来产生memory (即由 LSTM 生成的时间步骤的状态), 因为双向递归神经网络 (RNNs) 在机器中被发现类似目的是有效的(Bahdanau et al., 2014). 。然后将memory 切片按其相对位置加权到目标, 使同一句子中的不同目标有自己的量身定做的memory 。在此之后, 我们对位置加权memory 进行了多重attention , 并将注意力结果用recurrent network (i.e. GRUs ) 进行了非线性的结合。最后, 对 GRU 网络的输出进行了 softmax, 以预测目标的情绪
我们的框架引入了一种新的应用多重注意机制的方法来合成难句结构中的重要特征。 这有点类似于一个人的认知过程, 在开始的时候可能首先注意到重要信息的一部分, 然后在阅读时注意到更多, 最后将信息从多重关注中结合起来得出结论。对于上述句子, 我们的模型可能会参加 "except " 一词, 然后参加 "don't play well " 这短语, 最后结合起来产生对于"Patrick "的一个积极的特征。Tang et al. (2016) 也采用了多重关注的思想, 但他们使用了previous attention 的结果来帮助下一次attention 更准确的信息。他们的向量提供给 softmax 用作分类的仅仅是最后的attention , 本质上是输入向量的线性组合 (they did not have a memory component )。因此, 基于单注意方法的上述局限性也适用于 (Tang et al., 2016) 。与此相反, 我们的模型将多重关注的结果与 GRU 网络相结合, 它从 RNNs 中继承了不同的行为, 如遗忘、维护和非线性变换, 从而使预测精度更高。
我们评估我们的方法在四个数据集: 前两个来自 SemEval 2014 (Pontiki et al., 2014) , 包含对餐厅领域和笔记本电脑领域的评论;第三个是一组推特, 收集由 (Dong et al., 2014) ;为了研究我们的框架是否是不区分语言的 (因为语言在表达感情的几个方面表现出差异), 我们准备了一个中国新闻评论的数据集, 人们把它作为意见目标。实验结果表明, 我们的模型对不同类型的数据都有较好的性能, 并且始终优于先进的方法。
2 Related Work
方面情绪分类的任务属于实体层面的情绪分析。之前方法有概率软逻辑,统计模型,SVM (Jiang et al., 2011) or MaxEnt-LDA (Zhaoet al., 2010)。这些方法既需要繁琐的特征工程工作,也需要大量的语言外资源
而神经网络能通过多个隐含层自动提取特征,然而,reco - nn需要依赖解析,这可能对新闻评论和推特等非标准文本无效。该方法假设一个观点词和它的目标词在同一个从句中。TD-LSTM (Tang et al., 2015)利用LSTM对目标的上下文信息进行建模,将目标放置在中间,将状态词从开始和尾部分别传播到目标,捕捉目标之前和之后的信息。当意见词离目标很远时,TD-LSTM可能不能很好地工作,因为所捕获的特性可能会丢失(
((Cho et al.,2014)报道了lstm模型在机器翻译中的类似问题)。在以往的一些研究中,将单一注意或多个注意应用于方面情绪分类(Wang et al.,2016; Tang et al., 2016).本文与(Wang et al.,2016; Tang et al., 2016)文章不同点:其一,我们在输入和attention 层加入了memory module。因此我们能识别语句的合成特征(比如:"not wonderful enough")),其二(更重要的):我们用一种非线性的方法把注意的结果结合起来,(Wang et al.,2016; Tang et al., 2016)用的是单层,我们用过的是多层。(Kumar et al., 2015)也使用了多层,但是它将注意力分数独立地分配到记忆片上,其注意力处理更加复杂,而我们产生了一个标准化的注意分配来关注来自记忆的信息。
3 Our Model
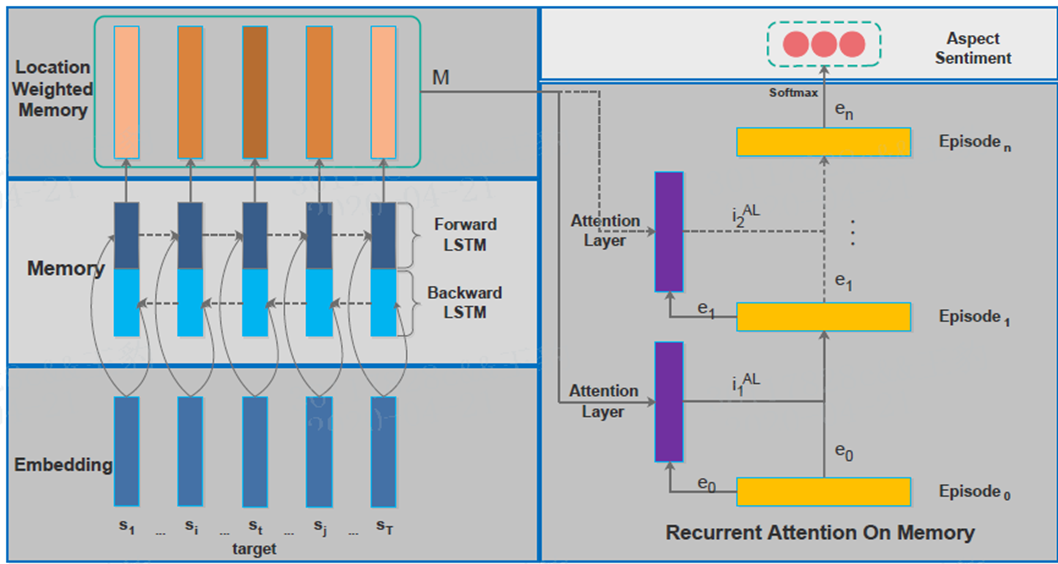
模型分为五部分,输入部分,memory部分,循环attention部分,输出部分,位置权重memory部分。
我们假设输入句子是一个序列 s={s1,s2,...,sτ−1,sτ,sτ+1,...,sT}本文的目标是预测target word sτ的情感。为了简单起见,本文是手工标注了一个目标,必要时,我们将阐述如何处理短语模板目标。
3.1 Input Embedding

d是单词的维度,V是词向量大小。
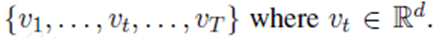
L可能被模型调整如果不进行调整,该模型可以利用原始嵌入空间中显示的单词相似性。如果它被调优,我们预计模型将捕获一些对情绪分析任务有用的内在信息。
3.2 BLSTM for Memory Building
MemNet (Tang et al., 2016)简单地使用单词向量序列作为记忆,无法合成原句中类似短语的特征。利用RNN族模型可以很容易地实现这一目标。在本文中,我们使用深度双向LSTM (DBLSTM),用于建立memory,其中记录所有要在后续模块中读取的信息
前向的LSTM定义如下:

i,f,o分别表示是否更新当前输入数据,是否在memory cell中忘记这些信息,再memory cell中的信息是否传递到输出。
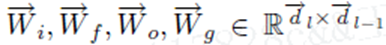
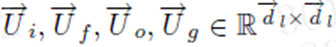
dl表示前向LSTM中第l层的隐藏cells。 反向的LSTM做同样的事情,除了输入时反向的。最终的memory生成的为下式,表示两者的结合。

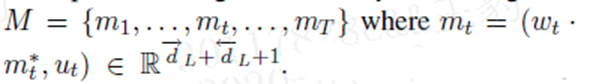
3.3 Position-Weighted Memory
上述模块中生成的内存对于一个注释中的多个目标是相同的,这对于预测这些目标的各自情绪来说不够灵活。为了解决这个问题,我们采用一种直观的方法来编辑内存,为每个目标生成一个定制的输入内存。具体来说,一个单词离目标越近,其记忆的权重就越高。我们将距离定义为单词与目标之间的单词数。人们可能希望使用依赖关系树中从特定单词到目标的路径长度作为距离,这是一个值得在以后的工作中尝试的选项,前提是依赖关系解析对输入文本足够有效。
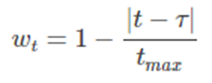
其中 tmax 为输入句子的最大长度
加权记忆的目的是提高近距离的感叹词的权重,而recurrent attention module(下面将讨论)则用于处理远距离的感叹词。因此,他们一起工作,期望更好的预测精度
3.4 Recurrent Attention on Memory
要准确预测一个目标的情绪,关键是:
- 正确地从它的位置加权存储器中提取相关信息;--采取多层attention解决
- 适当制作情感分类等信息输入:采用GRU(有更少的参数)与attention结果非线性结合
达到好处举一个例子来说,"Except Patrick, all other actors don't play well" 这样的句子,就需要综合"except"和"don't play well"这两个信息,从而得出针对"Patrick"的情感是正向的。
公式如下:
每次attention后,用GRU更新episode e,初始的e0都是0向量
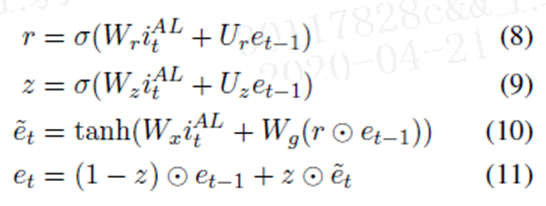
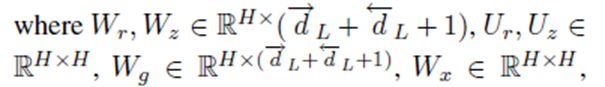
H是隐藏层的大小,e由上一个e(t-1)和候选的et帽构成。我们首次计算每层记忆片的得分为:vt是目标向量,因为不同的产品对意见词有不同的偏好,当目标是人,则不必要这么做,当是单词时,vt取词嵌入的平均值。我们利用前episode来获得当前的注意力,因为它可以引导模型关注不同的有用信息。(Tang et al., 2016)也采用了多重关注,但没有将不同关注的结果结合起来
然后我们计算每个记忆片的归一化注意分数为:
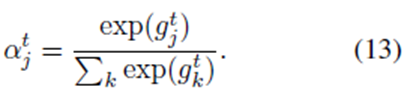
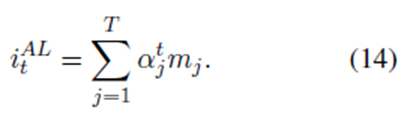
再将以上结果送到式子8-11,进行运算。
3.5 Output and Model Training
在memory经过N次attention后,将最后的en输入到softmax中进行分类。
损失函数为交叉熵损失和正二则化得方式:
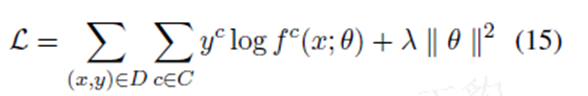
C是分类的数量,D是训练的数据集,y是ont-hot编码的向量,f是模型预测情感分析的类。
4 Experiments
4.1 Experimental Setting
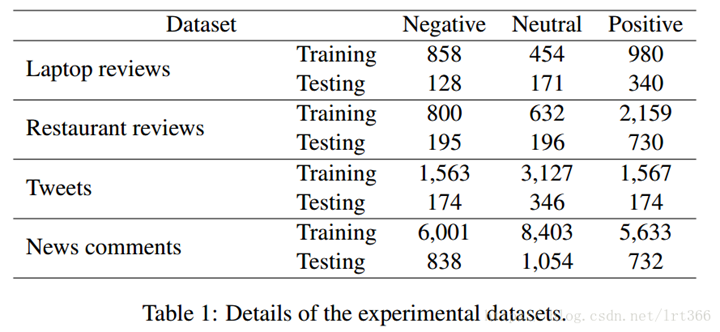
在表1中,前两个来自最近广泛使用的SemEval 2014 (Pontiki et al., 2014),包含餐馆和笔记本领域 。我们为了增加挑战性故意添加了更多的否定,对比,和询问的评论。每个评论都至少被两个审阅者标注,并且只有当两个审阅者都同意才能加入我们的数据集。此外, 我们用占位符替换每个意见目标 (i.e. word/phrase of pronoun or person name) , 如在(Dong et al., 2014) 中所做的那样。对于前两个数据集, 我们删除了几个有 "冲突标签"的例子, 例如,"Certainly not the best sushi in New York, however, it is always fresh" (Pontiki et al., 2014).
我们使用的300维字向量预先训练by GloVe (Pennington et al., 2014) (其词汇量是 1.9M2), 我们的实验在英语数据集, 正如以前的作品做 (Tang et al.,
2016) 。为了获得更好的性能一些作品使用领域特定的培训语料库学习向量 , 如 TD-LSTM (Tang et al., 2015) 的tweet 数据集。相比之下, 我们更倾向于使用一般的向量 (Pennington et al.,2014) 中的所有数据集, 这样实验结果就能更好地揭示模型的能力, 而数据可以在不同的论文中直接比较。中文实验的嵌入训练与14亿个标记的语料库在 CBOW上。
4.2 Compared Methods
对于每种方法, 训练迭代的最大次数为 100, 使用最小训练误差的模型进行测试。稍后我们将讨论 Recurrent Attention on Memory (RAM) 的不同设置。
4.3 Main Results
第一个评价标是Accuracy , 用于(Tang et al., 2016) 。因为数据集的类不平衡, 如表1所示, 因此也报告了宏平均的 F-measure , 如 (Dong et al., 2014; Tang et al., 2015) 。如表2中的结果所示, 我们的 RAM 在这四数据集上始终优于所有比较方法。ac 和 ac 的表现不佳, 因为平均上下文等同于对每个单词都给予相同的注意, 这将隐藏真实的情绪词。Rec-NN比 TDLSTM 好, 但不如我们的方法。它的优点是利用依赖分析的结果, 可以缩短观点目标与相关意见词之间的距离。但是, 依赖关系分析不能保证在不规则的文本 (如tweets) 上很好地工作, 这可能仍然导致意见词和目标之间的长路径, 因此在传播时, 意见特征也会丢失。TD-LSTM 在所有数据集上的竞争能力比我们的方法低, 特别是在推特数据集上, 因为在这个数据集中, 情感词通常远离人名, 在这种情况下, 多注意机制是为工作而设计的。LSTM 的表现也比我们的方法差, 因为它的两个注意事项, 即一个人在目标之前的文本, 另一个是后, 不能解决一些情况下, 有超过一项功能是在同一一侧的目标。
我们的方法比 MemNet 在所有四数据集上的性能都好, 特别是在新闻评论数据集上, 其改进超过了10%。MemNet 采取多注意, 以提高注意力的结果, 假设在后面的跳跃的结果应该是更好的, 在开始时。MemNet 不结合多重关注的结果, softmax 的向量是最后的关注的结果, 本质上是词嵌入的线性组合。正如我们之前所描述的, 在同一时间参加太多的单词可能会隐藏每个单词的特征, 而且, 情绪转换通常会以非线性的方式组合特征。我们的模型克服了这个缺点与 GRU 网络结合的结果多关注。基于特征的 SVM, 它需要劳动密集型的功能工程和大量的额外语言资源, 不显示其优势, 因为方面情绪分析的特点不能像句子或文档那样容易提取水平情绪分析。
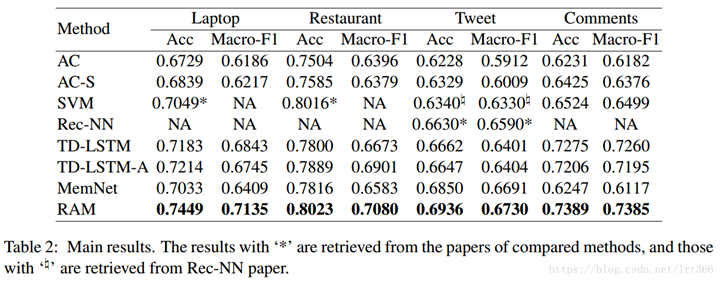
4.4 Effects of Attention Layers
影响我们模型性能的一个主要设置是注意层数。我们用1到5个注意层来评估我们的框架, 结果在表3中给出, 在这里, NAL 表示使用 N 个关注。一般情况下, 我们的模型用2或3注意层工作得更好, 但这个优势并不总是适合于不同的数据集。例如, 对于餐厅数据集, 我们的模型具有4个注意层的性能最好。使用1的注意力总是不如使用更多, 这表明一次性注意可能不足以捕捉复杂情况下的情绪特征。另一方面, 在关注的数量上, 性能并不单调地增加。RAM- 4AL 一般不如 RAM-3AL, 这是因为随着模型的复杂性增加, 模型变得更难训练, 更少推广
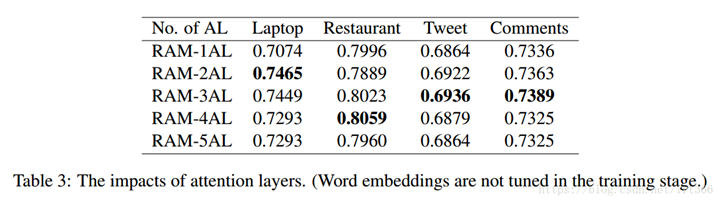
4.5 Effects of Embedding Tuning
比较的嵌入优化策略有:
· RAM-3AL-T-R: 它不预先训练单词嵌入, 而是随机初始化嵌入, 然后在受监督的训练阶段对其进行微调。
· RAM-3AL-T: 最初使用预训练的嵌入, 并且在训练中也进行了调整。
· RAM-3AL-NT: 训练中未调整预训练的嵌入。
在表4中, 我们可以看到 RAM-3AL-TR 执行得非常差, 尤其是当训练数据的大小较小时。原因可能是三重的: (1) 四实验数据集中的标签样本量太小, 无法从零开始调整可靠的嵌入词汇 (即训练数据中存在);(2) 大量的out-of-vocabulary(OOV) 词, 即缺席训练数据, 但存在于测试数据中;(3) 在将嵌入参数添加到解决方案空间后, 增加了 过拟合的风险 (它不仅要求嵌入适应模型参数, 还需要捕获单词之间的相似性)。在训练过程中, 我们确实注意到训练错误在 RAM-3AL-T-R 中收敛得太快。在训练开始时, RAM-3AL-T 可以利用单词之间的嵌入相似性, 但是微调会在训练过程中破坏这种相似性。另一方面, 初始嵌入OOV 词在测试数据中的不调整, 使其与词汇词的相似性也被破坏。此外, RAM-3AL-T 也遭受 过拟合的风险。RAM-3AL-NT 在所有四数据集上执行最佳, 我们还观察到, 当模型参数与输出层中的错误信号一起更新时, 训练误差逐渐收敛
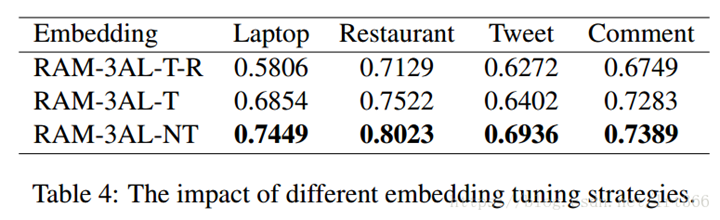
4.6 Case Study
我们从数据集中选择一些测试示例, 并可视化它们的注意结果。为了使可视化结果易于理解, 我们删除 BLSTM 内存模块, 使注意力模块直接工作在单词嵌入上, 从而可以检查注意结果是否符合我们的直觉。图2和3显示了可视化结果。
图2a 和2b 显示了使用两个注意和使用一个注意力之间的差异, 这表明选择正确的特征上多项关注是有用的,。如图2a 所示, 为了识别 "windows " 的情绪, 该模型首先注意到 "welcomed " 和第二个通告 "compared " 前的方面目标 "windows "。最后, 它将它们与 GRU 网络结合在一起, 产生一种负面情绪, 因为在一个积极的情绪词 (即 "welcomed ") 之后, 比较的项目 (即 "windows ") 不太可取。而只有一个注意的模型的注意结果, 如图2a 所示, 是一种均匀分布, 交融太多的词向量, 从而破坏了每个词的特征

图3a 和3b 提出了一个在评论中有多个意见,目标句子层次情绪分析方法不能正确地分析句的案例 。具体来说, 这是一个比较句, 评论者对第一个被评论的人有积极的情绪, 但对第二个人有负面情绪, 我们的模型对二者的预测都是正确的。虽然所有有用的信息 (例如 "than " 和 "stronger ") 在两种情况下出席, 他们的注意过程显示一些有趣的区别。在他们在第一注意层 AL1获得主要关注目标 $T $ 的重要信息后, 图3b 在 AL2 中将详细了解更多信息在 $T 元之前。由于图3a 和3b 中相同的单词有不同的内存切片, 这是由于位置加权和增强偏移特性, 如3.3 节所述, 我们的模型预测了两个人的相反情绪。例如在图3b 中, 模型首先参加一个积极的词 "stronger ", 然后参加 "than " 在目标之前, 因此它逆转情绪并且最后预测消极情绪
5 Conclusions and Future Work
本文提出了一种确定舆论目标情绪的框架。模型首先通过输入来生成内存, 在这个过程中, 它可以合成单词序列特征。然后, 通过将不同关注的特征与非线性相结合, 对记忆中的重要信息进行多项关注, 以预测最终情绪。我们在四数据集上展示了我们的模型的有效性, 结果表明, 它能胜过最先进的方法。
虽然多注意机制有可能综合复杂句子中的特征, 但强制模型对内存的固定数的注意是不自然的, 甚至有些情况下是不合理的。因此, 如果无法从内存中读取更多有用的信息, 我们需要一个机制来自动停止注意过程。我们也可以尝试其他内存加权策略, 以区分多个目标在一个评论更清楚

