【ML-15】主成分分析(PCA)
目录
- PCA的思想
- 算法推导
- PCA算法流程
- 核主成分分析KPCA介绍
- PCA算法总结
主成分分析(Principal components analysis,以下简称PCA)是最重要的降维方法之一。在数据压缩消除冗余和数据噪音消除等领域都有广泛的应用。
一、PCA的思想
PCA顾名思义,就是找出数据里最主要的方面,用数据里最主要的方面来代替原始数据。也可以换句话说:尽量保留最多的信息量。
举个例子:假如我们的数据集是n维的,共有m个数据(x(1),x(2),...,x(m))。我们希望将这m个数据的维度从n维降到n'维,希望这m个n'维的数据集尽可能的代表原始数据集。我们知道数据从n维降到n'维肯定会有损失,但是我们希望损失尽可能的小。那么如何让这n'维的数据尽可能表示原来的数据呢?
我们先看看最简单的情况,也就是n=2,n'=1,也就是将数据从二维降维到一维。数据如下图。我们希望找到某一个维度方向,它可以代表这两个维度的数据。图中列了两个向量方向,u1和u2,那么哪个向量可以更好的代表原始数据集呢?从直观上也可以看出,u1比u2好。

为什么u1比u2好呢?可以有两种解释,第一种解释是样本点到这个直线的距离足够近,第二种解释是样本点在这个直线上的投影能尽可能的分开,也就是方差尽量大。
假如我们把n'从1维推广到任意维,则我们的希望降维的标准为:样本点到这个超平面的距离足够近,或者说样本点在这个超平面上的投影能尽可能的分开。
基于上面的两种标准,我们可以得到PCA的两种等价推导。
二、算法推导
两种思路来推导出一个同样的表达式。首先是最小化投影后的损失(投影产生的损失最小),其次最大化投影后的方差是。
2.1 PCA的推导:基于最小投影距离
我们首先看第一种解释的推导,即样本点到这个超平面的距离足够近。

将这个式子进行整理,可以得到:
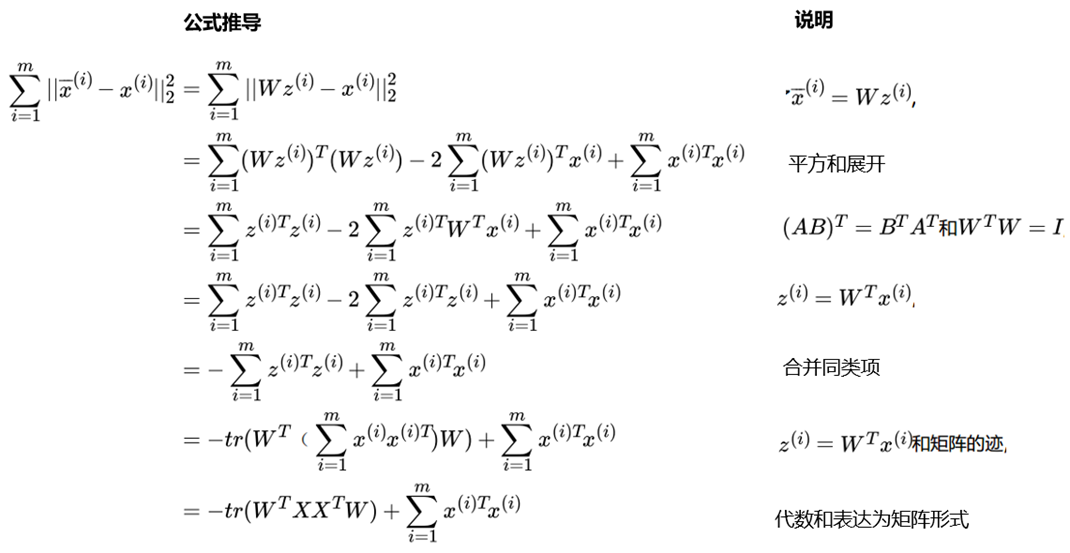

这样可以更清楚的看出,W为XX的n'个特征向量组成的矩阵,而λ为XX的若干特征值组成的矩阵,特征值在主对角线上,其余位置为0。当我们将数据集从n维降到n'维时,需要找到最大的n'个特征值对应的特征向量。这n'个特征向量组成的矩阵W即为我们需要的矩阵。对于原始数据集,我们只需要用z(i)=WTx(i),就可以把原始数据集降维到最小投影距离的n'维数据集。
备注:谱聚类的优化过程,就会发现和PCA的非常类似,只不过谱聚类是求前k个最小的特征值对应的特征向量,而PCA是求前k个最大的特征值对应的特征向量。
2.2基于最大投影方差

很容易发现,这个和2.1基本是完全一致的。
三、PCA算法流程

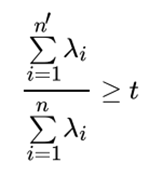
四、核主成分分析KPCA介绍
在上面的PCA算法中,我们假设存在一个线性的超平面,可以让我们对数据进行投影。但是有些时候,数据不是线性的,不能直接进行PCA降维。这里就需要用到和支持向量机一样的核函数的思想:称之为核主成分分析(Kernelized PCA, 以下简称KPCA。假设高维空间的数据是由n维空间的数据通过映射ϕ产生。则对于n维空间的特征变形:
![]()
五、PCA算法总结
这里对PCA算法做一个总结。作为一个非监督学习的降维方法,它只需要特征值分解,就可以对数据进行压缩,去噪。因此在实际场景应用很广泛。为了克服PCA的一些缺点,出现了很多PCA的变种,比如第六节的为解决非线性降维的KPCA,还有解决内存限制的增量PCA方法Incremental PCA,以及解决稀疏数据降维的PCA方法Sparse PCA等。
优点:
1)仅仅需要以方差衡量信息量,不受数据集以外的因素影响。
2)各主成分之间正交,可消除原始数据成分间的相互影响的因素。
3)计算方法简单,主要运算是特征值分解,易于实现。
缺点:
1)主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强。
2)方差小的非主成分也可能含有对样本差异的重要信息,因降维丢弃可能对后续数据处理有影响。
以上主要来自: <https://www.cnblogs.com/pinard/p/6239403.html>
附件一:手写练习


