距离度量--熵,KL散度,JS散度,GAN相关应用
目录
- 香农信息量、信息熵、交叉熵
- KL散度(Kullback–Leibler divergence)
- JS散度(Jensen-Shannon divergence )
- Wasserstein距离
- 几种距离对比
- GAN相关应用
一、香农信息量、信息熵、交叉熵
香农信息量
设p为随机变量X的概率分布,即p(x)为随机变量X在X=x处的概率密度函数值,随机变量X在x处的香农信息量定义为:
其中对数以2为底,这时香农信息量的单位为比特。香农信息量用于刻画消除随机变量X在x处的不确定性所需的信息量的大小。如随机事件"中国足球进不了世界杯"不需要多少信息量(比如要不要多观察几场球赛的表现)就可以消除不确定性,因此该随机事件的香农信息量就少。再比如"抛一个硬币出现正面",要消除它的不确定性,通过简单计算,需要1比特信息量,这意味着随机试验完成后才能消除不确定性。
信息熵H(p)
越有序,信息熵越低。衡量随机变量X(或整个样本空间)的总体香农信息量。信息熵H(p)是香农信息量-logp(x)的数学期望,即所有X=x处的香农信息量的和,即用p(x)加权求和。因此信息熵是用于刻画消除随机变量X的不确定性所需要的总体信息量的大小。其数学定义如下:

交叉熵
假设q(x)为拟合概念,p(x)为真实分布。q是用来拟合p的概率分布,x属于p的样本空间,交叉熵用于衡量q在拟合p的过程中,用于消除不确定性而充分使用的信息量大小(理解为衡量q为了拟合p所付出的努力,另外注意交叉熵定义里的"充分使用"和信息熵定义里的"所需"的区别,"充分使用"不一定能达到全部,"所需"是指全部)。由于在每一个点X=x处q的香农信息量为-logq(x),也就是在点X=x处,q消除不确定性而充分使用的信息量为-logq(x)(理解为衡量q在X=x处为了拟合p所作的努力。越小越准确,实例可见本文最后),那么就可以计算出在整个样本空间上q消除不确定性而充分使用的总体信息量,即-logq(x)的数学期望,由于每个x的权重为p(x),因此交叉熵H(p,q)为:

二、KL散度(Kullback–Leibler divergence)
两个概率分布p和q的KL散度也称为相对熵,信息增益,用于刻画概率分布q拟合概率分布p的程度。在生成对抗网络里,p为真实数据的概率分布,q为随机噪声生成数据的概率分布,对抗的目的是让q充分拟合p。在q拟合概率分布p的过程中,如果q完全拟合p,自然有H(p)=H(p,q),如果q拟合p不充分,自然产生信息损耗H(p)-H(p,q),整个信息损耗就是p和q的KL散度。其实衡量两种概率分布的相似程度,其越小,表示两种概率分布越接近。因此p和q的KL散度的定义如下:

因此散度D(p||q)为信息熵H(p)与交叉熵H(p,q)的差,衡量q拟合p的过程中产生的信息损耗,损耗越少,q拟合p也就越好。很明显散度是不对称的,并不是p和q的距离。性质:
描述两个概率分布P,Q之间的差异
因为对数函数是凸函数,所以KL散度的值为非负数。
相对熵 = 交叉熵 – 信息熵: D(p||q) = H(p,q) – H(p)
有时会将KL散度称为KL距离,但它并不满足距离的性质:
1. KL散度不是对称的:KL(A,B) ≠ KL(B,A)
2. KL散度不满足三角不等式: KL(A,B) > KL(A,C)+KL(C,B)
三、JS散度(Jensen-Shannon divergence )
KL散度的缺点:不是距离、不对称。因此引进JS散度的概念,其取值是0到1之间。JS散度的定义如下:

由定义可以看出,JS散度是对称的,可以用于衡量两种不同分布之间的差异。JS散度用于生成对抗网络的数学推导上。
JS散度和KL散度联系和差异:
1、相同点:
但p和q相同时,这个两个都值为0
2、不同点:随着两个分布差异越来越大,他们的JS散度的值会逐渐增大。但是当他们足够大(极端一点考虑当一个为1一个为0的时候),他们的值就收敛到1了,也就是说他们差异足够大的时候,JS散度会收敛到一个常数。这个时候应该对梯度下降就没有指导意义了。
四、 Wasserstein距离
Wasserstein距离又叫Earth-Mover(EM)距离,定义如下:

先要知道的是wasserstein-1 距离是人为定义的对于两个分布Pr和Pg间差异的测量。再来看式子,∏(Pr, Pg)为Pr和Pg的联合分布的集合。我们从这个集合里面任选一个联合分布r,对应这个r联合分布,求出(x,y)服从r这个分布时x,y两个点对于||x-y||的期望值。对于联合分布集合里面所有的联合分布,我们都能求出这样一个期望值,其中最小的那个期望值就是我们要求的wasserstein-1 距离了。
直观上可以把E(x,y)∼γ[||x−y||]理解为在γ这个路径规划下把土堆Pr挪到土堆Pg所需要的消耗。而Wasserstein距离就是在最优路径规划下的最小消耗。所以Wesserstein距离又叫Earth-Mover距离。
Wessertein距离相比KL散度和JS散度的优势在于:
Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。而JS散度在此情况下是常量2log2,KL散度可能无意义。
五、几种距离对比



KL散度和JS散度是突变的,要么最大要么最小,Wasserstein距离却是平滑的,如果我们要用梯度下降法优化Θ这个参数,前两者根本提供不了梯度,Wasserstein距离却可以。类似地,在高维空间中如果两个分布不重叠或者重叠部分可忽略,则KL和JS既反映不了远近,也提供不了梯度,但是Wasserstein却可以提供有意义的梯度。
六、 GAN相关应用
GAN:Gennerator和Discriminator的KL散度和JS散度解释
Generator中θ的极大似然估计(是求真实分布和生成器分布的KL散度的最小值):
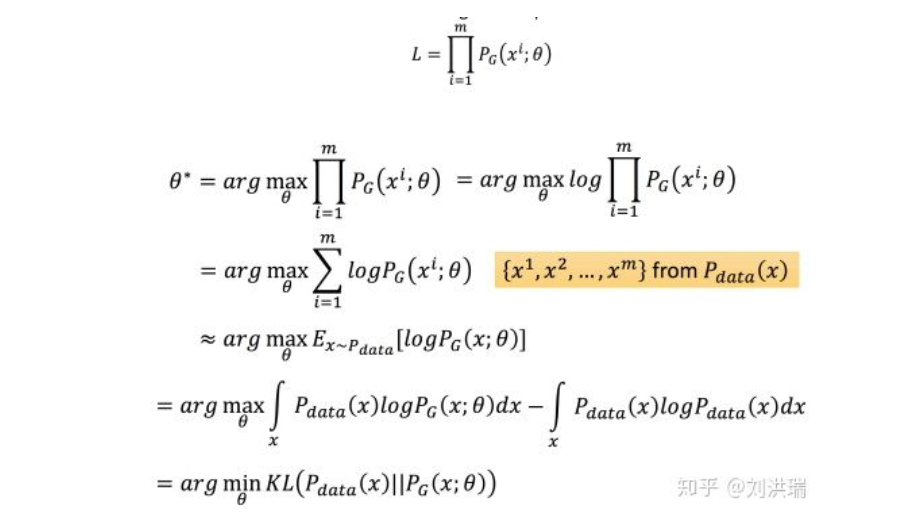

实际应用:
1、交叉熵损失函数的例子解释:损失函数越低越准确



