【ML-9-4】支持向量机--SVM回归模型(SVR)
目录
- SVM回归模型的损失函数度量
- SVM回归模型的目标函数的原始形式
- SVM回归模型的目标函数的对偶形式
- SVM 算法小结
一、SVM回归模型的损失函数度量
SVM和决策树一样,可以将模型直接应用到回归问题中;在SVM的分类模型(SVC)中,目标函数和限制条件如下
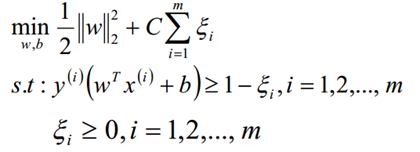
在SVR中,目的是为了尽量拟合一个线性模型y=wx+b;从而我们可以定义常量eps>0,对于任意一点(x,y),如果|y-wx-b|≤eps,那么认为没有损失,从而我们可以得到目标函数和限制条件如下:
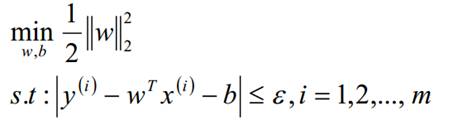
二、SVM回归模型的目标函数的原始形式
加入松弛因子ξ>0,从而我们的目标函数和限制条件变成:
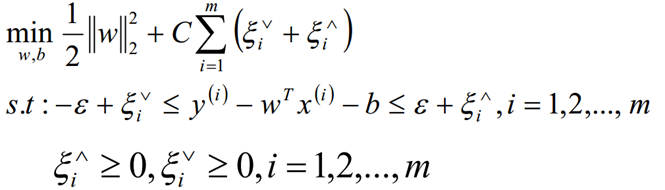
构造拉格朗日函数:
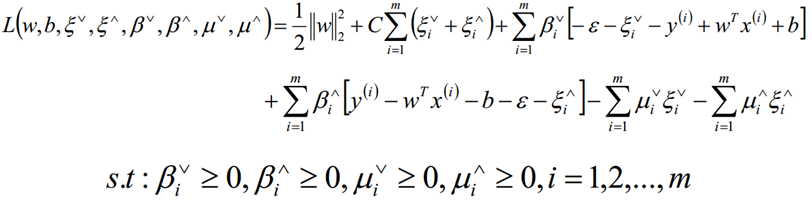
三、SVM回归模型的目标函数的对偶形式
拉格朗日函数对偶化:
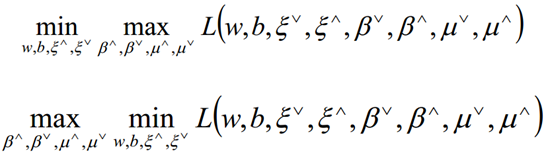
首先来求优化函数对于w、b、ξ的极小值,通过求导可得:

将w、b、ξ的值带入函数L中,就可以将L转换为只包含β的函数,从而我们可以得到最终的优化目标函数为(备注:对于β的求解照样可以使用SMO算法来求解):

四、SVM 算法小结
SVM算法是一个很优秀的算法,在集成学习和神经网络之类的算法没有表现出优越性能前,SVM基本占据了分类模型的统治地位。目前则是在大数据时代的大样本背景下,SVM由于其在大样本时超级大的计算量,热度有所下降,但是仍然是一个常用的机器学习算法。
SVM算法的主要优点:
1) 解决高维特征的分类问题和回归问题很有效,在特征维度大于样本数时依然有很好的效果。
2) 仅仅使用一部分支持向量来做超平面的决策,无需依赖全部数据。
3) 有大量的核函数可以使用,从而可以很灵活的来解决各种非线性的分类回归问题。
4)样本量不是海量数据的时候,分类准确率高,泛化能力强。
SVM算法的主要缺点:
1) 如果特征维度远远大于样本数,则SVM表现一般。
2) SVM在样本量非常大,核函数映射维度非常高时,计算量过大,不太适合使用。
3)非线性问题的核函数的选择没有通用标准,难以选择一个合适的核函数。
4)SVM对缺失数据敏感。

