基础1-元组/列表/字符串/字典/集合/文件/字符串编码转变
一:列表:
names=["4ZhangYang","Guyun","xXiangPeng",["alex","jack"],"ChenRonghua","XuLiangchen"]
print(names[1:3])#切片顾手不顾尾,取出第二/三个
print(names[3])#切片取第四个
print(names[-2:])#切片取最后两个
#增加:
names.append("LeiHaidong") #最后加入
names.insert(1,"ChenRonghua") #插到guyun前面
#delete 删除三种方式
names.remove("ChenRonghua")
del names[1]=names.pop(1)
names.pop(1)
#修改
names[2] = "向鹏" #修改
print(names.count("ChenRonghua")) #计算chenronghua出现的次数
names.clear() #清空
names.reverse() # 反转倒序
names.sort() #排序,按照字母顺序
print(names)
names2=[1,2,3,4]
names
names.extend(names2) #合并元组
Del names2
print(names,names2)
三种打印方式:
print(names[0:-1:2])
print(names[::2]) #0可以省略
print(names[:])
二:元组:
和列表基本相同,差一点:
1.不能增删改
2.使用小括弧代替中括弧
3.但是可以使用统计和查看:count和index
补充:取出列表下标
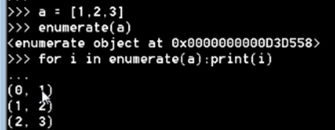
三:字符串
不能修改。
name = "my \tname is {name} and i am {year} old"
常见字符串函数的应用:
print(name.capitalize()) #首字母大写
print(name.count("a")) #统计出现的次数
print(name.center(50,"-")) #50个空格,不足的- 补齐
print(name.endswith("ex")) #以什么结尾
print(name.expandtabs(tabsize=30)) # \t 转成30个空格
print(name[name.find("name"):]) #find("name") 返回的是4,字符串也可以切片
print(name.format(name='alex',year=23)) #格式化
print(name.format_map( {'name':'alex','year':12} )) #字典
print('ab23'.isalnum()) #判断是否为阿拉伯数字
print('abA'.isalpha()) #是否为纯英文字符
print('1A'.isdecimal()) #是否为十进制
print('1A'.isdigit()) #是否为整数
print('a 1A'.isidentifier()) #判读是不是一个合法的标识符
print('33A'.isnumeric()) #是否是一个数字
print('My Name Is '.istitle()) #是否是标题,每个首字母大写
print('My Name Is '.isprintable()) #tty file ,drive file是不能打印的
print('My Name Is '.isupper()) #是不是大写
print('+'.join( ['1','2','3']) ) #表示1+2+3;经常使用
print( name.ljust(50,'*') ) #长50,不足用*补上,补的在最后(last)
print( name.rjust(50,'-') ) #长50,不足用-补上
print( 'Alex'.lower() ) #全部小写
print( 'Alex'.upper() )
print( '\nAlex'.lstrip() ) #去左边的空格和换行
print( 'Alex\n'.rstrip() )
print( ' Alex\n'.strip() )
p = str.maketrans("abcdefli",'123$@456') #替换,例如a换成1,可用作密码
print("alex li".translate(p) )
print('alex li'.replace('l','L',1)) #更换1个l为L
print('alex lil'.rfind('l')) #返回5,从左边开始,找到最大的下标序号
print('1+2+3+4'.split('+')) #根据什么来切分
print('1+2\n+3+4'.splitlines())
print('Alex Li'.swapcase()) #大小写转化
print('lex li'.title()) #首字母大写
print('lex li'.zfill(50)) # 补位
四:字典
注意:Key尽量不要写中文:
info = {
'stu1101': "TengLan Wu",
'stu1102': "LongZe Luola",
'stu1103': "XiaoZe Maliya",
}
查:
info['stu1104'] #不存在会报错
print(info.get('stu1103')) #不存在会返回null
修改:
info["stu1101"] ="武藤兰"
增加:
info["stu1104"] ="CangJing"
删除:
#del
#del info["stu1101"]
info.pop("stu1101")
info.popitem() #随机删除一个
更新:
b ={
'stu1101': "Alex",
1:3,
2:5
}
info.update(b) #两个字典合并,取并集
print(info.items() ) #把字典转换成列表
字典的两种循环:
for i in info:
print(i,info[i])
for k,v in info.items():
print(k,v)
区别:第一个更加高效,第二个要先变成列表转换。
多级字典嵌套和操作
av_catalog = {
"欧美":{
"www.youporn.com": ["很多免费的,世界最大的","质量一般"],
"www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"],
"letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"],
"x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"]
},
"日韩":{
"tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"]
},
"大陆":{
"1024":["全部免费,真好,好人一生平安","服务器在国外,慢"]
}
}
#修改:
av_catalog["大陆"]["1024"][1] = "可以在国内做镜像"
av_catalog.setdefault("大陆",{"www.baidu.com":[1,2]}) #能取到,就返回,取不到,就重新设置
三级菜单实例:
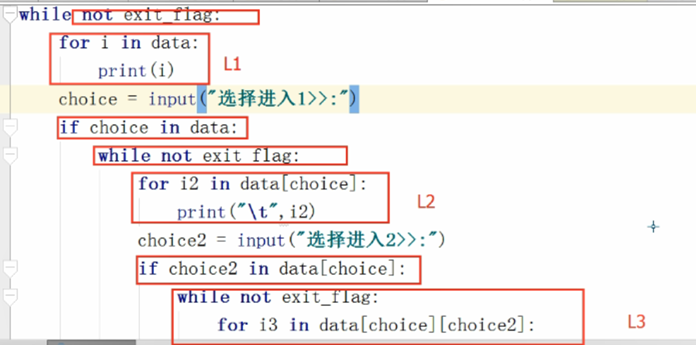
五:集合
集合是一个无序的,不重复的数据组合,他的作用如下:
去重:
list_1 = [1,4,5,7,3,6,7,9]
list_1 = set(list_1)
list_2 =set([2,6,0,66,22,8,4])
print(list_1,list_2)
#交集
print( list_1.intersection(list_2) )
#并集
print(list_1.union(list_2))
#差集 in list_1 but not in list_2
print(list_1.difference(list_2)) #结合1减公共部分
#子集
list_3 = set([1,3,7])
print(list_3.issubset(list_1)) #3是否为1的子集
print(list_1.issuperset(list_3)) #1是否为3的父集
#对称差集
print(list_1.symmetric_difference(list_2)) #并集减去交集
list_4 = set([5,6,7,8])
print(list_3.isdisjoint(list_4)) # Return True if two sets have a null intersection.两者无交际(false)
#交集
print(list_1 & list_2)
#并集
print(list_2 | list_1)
#差集
print(list_1 - list_2) # in list 1 but not in list 2
#对称差集
print(list_1 ^ list_2)
list_1.add(999) #增加
list_1.update([888,777,555]) #修改
list_1.remove(999) #删除一个,不存在会报错
print( list_1.discard(888) ) #指定一个值,若存在就删除,若不存在则无操作
print(list_1.pop()) #删除任意一个
六:文件
#data = open("yesterday",encoding="utf-8").read()
f = open("yesterday2",'a',encoding="utf-8") #文件句柄
#a = append 追加
f.write("\nwhen i was young i listen to the radio\n")
data = f.read()
print('--read',data)
f.close()
print(f.encoding) #打印类型,本文为 utf-8
print(dir(f.buffer) ) #
f=open("yesterday2",'r',encoding="utf-8")#文件句柄
#high bige
count = 0
for line in f:
if count == 9:
print('----我是分割线----------')
count += 1
continue
print(line)
count +=1
#low loop
for index,line in enumerate(f.readlines()):
if index == 9:
print('----我是分割线----------')
continue
print(line.strip())
#for i in range(5):
# print(f.readline())
'''
f=open("yesterday2",'r',encoding="utf-8")#文件句柄
print(f.tell()) #字母所在位置
print(f.readline(20)) #取多少位的字符
print(f.tell())
f.seek(9) #从第几个开始
print('2------',f.readline())
print(f.writable()) #是否可写
f.flush() #强制刷新到硬盘上,不是满了再刷新
实例1:及时刷新出来
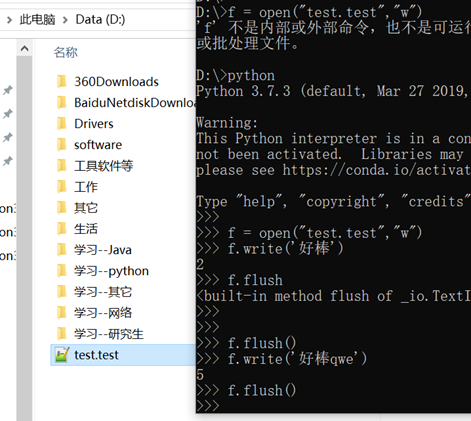
实例2:进度条的制作;
Import sys,time
For I in range(20):
sys.stdout.write("#")
sys.stdout.flush()
time.sleep(0.1)
f=open("yesterday2",'a',encoding="utf-8")#文件句柄
f.seek(10) # 从第几个开始
f.truncate(20) #截断保留20个,后面的删除
f = open("yesterday2",'r+',encoding="utf-8") #读写,打开,继续写内容。用的最多
f = open("yesterday2",'w+',encoding="utf-8") #文件句柄 写读,没什么大用
f = open("yesterday2",'a+',encoding="utf-8") #文件句柄 追加读写
f = open("yesterday2",'rb') #二进制读,用于网络传输
f = open("yesterday2",'wb') #二进制写,不能读
f.write("hello binary\n".encode())
f.close()
备注:Open : r w a r+ w+ a+ rb wb ab
#实例:将yesterday2拷贝到新建的yesterday2bak中,并修改部分
import sys
f = open("yesterday2","r",encoding="utf-8")
f_new = open("yesterday2bak","w",encoding="utf-8")
for line in f:
if "我的双眼却视而不见" in line:
line=line.replace("我的双眼却视而不见","wangbao的双眼却视而不见")
f_new.write(line)
f.close()
f_new.close()
实例:打开多个文件,且不用关心文件关闭问题,这种自动关闭
import sys
#可以打开多个文件
with open("yesterday2","r",encoding="utf-8") as f ,\
open("yesterday2", "r", encoding="utf-8") as f2:
for line in f:
print(line)
七:字符串编码转换
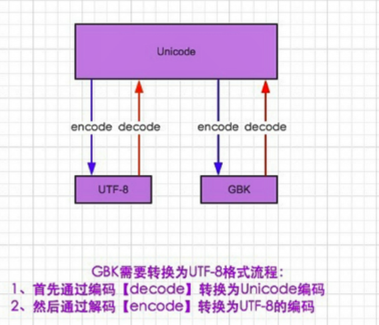
7.1 在python2中:默认utf-8
Utf-8转成Unicode,再转成GBK

GBK转UTF-8也要先转成Unicode

7.2 在python3中:默认unicode(都是两个字节)
#-*-coding:gbk-*- #文件中申明为gbk
import sys
print(sys.getdefaultencoding())
__author__ = "Alex Li"
s = "你哈" #本python中还是使用Unicode
print(s.encode("gbk"))
print(s.encode("utf-8"))
print(s.encode("utf-8").decode("utf-8").encode("gb2312").decode("gb2312"))

