「解题报告」CSP - S 2019
总分:100 + 55 + 10 + 32 + 12 + 40 = 249。
[CSP-S2019] 格雷码#
题目描述#
通常,人们习惯将所有 位二进制串按照字典序排列,例如所有 2 位二进制串按字典序从小到大排列为:00,01,10,11。
格雷码(Gray Code)是一种特殊的 位二进制串排列法,它要求相邻的两个二进制串间恰好有一位不同,特别地,第一个串与最后一个串也算作相邻。
所有 2 位二进制串按格雷码排列的一个例子为:00,01,11,10。
位格雷码不止一种,下面给出其中一种格雷码的生成算法:
- 1 位格雷码由两个 1 位二进制串组成,顺序为:0,1。
- 位格雷码的前 个二进制串,可以由依此算法生成的 位格雷码(总共 个 位二进制串)按顺序排列,再在每个串前加一个前缀 0 构成。
- 位格雷码的后 个二进制串,可以由依此算法生成的 位格雷码(总共 个 位二进制串)按逆序排列,再在每个串前加一个前缀 1 构成。
综上, 位格雷码,由 位格雷码的 个二进制串按顺序排列再加前缀 0,和按逆序排列再加前缀 1 构成,共 个二进制串。另外,对于 位格雷码中的 个 二进制串,我们按上述算法得到的排列顺序将它们从 编号。
按该算法,2 位格雷码可以这样推出:
- 已知 1 位格雷码为 0,1。
- 前两个格雷码为 00,01。后两个格雷码为 11,10。合并得到 00,01,11,10,编号依次为 0 ~ 3。
同理,3 位格雷码可以这样推出:
- 已知 2 位格雷码为:00,01,11,10。
- 前四个格雷码为:000,001,011,010。后四个格雷码为:110,111,101,100。合并得到:000,001,011,010,110,111,101,100,编号依次为 0 ~ 7。
现在给出 ,,请你求出按上述算法生成的 位格雷码中的 号二进制串。
输入格式#
仅一行两个整数 ,,意义见题目描述。
输出格式#
仅一行一个 位二进制串表示答案。
样例 #1#
样例输入 #1#
2 3
样例输出 #1#
10
样例 #2#
样例输入 #2#
3 5
样例输出 #2#
111
样例 #3#
样例输入 #3#
44 1145141919810
样例输出 #3#
00011000111111010000001001001000000001100011
提示#
【样例 1 解释】
2 位格雷码为:00,01,11,10,编号从 0∼3,因此 3 号串是 10。
【样例 2 解释】
3 位格雷码为:000,001,011,010,110,111,101,100,编号从 0∼7,因此 5 号串是 111。
【数据范围】
对于 的数据:
对于 的数据:
对于 的数据:
对于 的数据:,
一个很简单的二分思想,判断位置是在前半段还是后半段,然后二分。
// The code was written by yifan, and yifan is neutral!!!
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define bug puts("NOIP rp ++!");
#define rep(i, a, b, c) for (int i = (a); i <= (b); i += (c))
#define per(i, a, b, c) for (int i = (a); i >= (b); i -= (c))
using ull = unsigned long long;
template<typename T>
inline T read() {
T x = 0;
bool fg = 0;
char ch = getchar();
while (ch < '0' || ch > '9') {
fg |= (ch == '-');
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = (x << 3) + (x << 1) + (ch ^ 48);
ch = getchar();
}
return fg ? ~x + 1 : x;
}
ull k, n;
void solve(int dig, ull pos) {
if (dig == 0) {
return ;
}
if (pos >= (1ull << (dig - 1))) {
cout << "1";
solve(dig - 1, (1ull << (dig - 1)) - pos + (1ull << (dig - 1)) - 1);
} else {
cout << "0";
solve(dig - 1, pos);
}
}
int main() {
n = read<int>(), k = read<ull>();
solve(n, k);
return 0;
}
[CSP-S2019] 括号树#
题目背景#
本题中合法括号串的定义如下:
()是合法括号串。- 如果
A是合法括号串,则(A)是合法括号串。 - 如果
A,B是合法括号串,则AB是合法括号串。
本题中子串与不同的子串的定义如下:
- 字符串
S的子串是S中连续的任意个字符组成的字符串。S的子串可用起始位置 与终止位置 来表示,记为 (, 表示 S 的长度)。 S的两个子串视作不同当且仅当它们在S中的位置不同,即 不同或 不同。
题目描述#
一个大小为 的树包含 个结点和 条边,每条边连接两个结点,且任意两个结点间有且仅有一条简单路径互相可达。
小 Q 是一个充满好奇心的小朋友,有一天他在上学的路上碰见了一个大小为 的树,树上结点从 编号, 号结点为树的根。除 号结点外,每个结点有一个父亲结点,()号结点的父亲为 ()号结点。
小 Q 发现这个树的每个结点上恰有一个括号,可能是( 或)。小 Q 定义 为:将根结点到 号结点的简单路径上的括号,按结点经过顺序依次排列组成的字符串。
显然 是个括号串,但不一定是合法括号串,因此现在小 Q 想对所有的 ()求出, 中有多少个互不相同的子串是合法括号串。
这个问题难倒了小 Q,他只好向你求助。设 共有 个不同子串是合法括号串, 你只需要告诉小 Q 所有 的异或和,即:
其中 是位异或运算。
输入格式#
第一行一个整数 ,表示树的大小。
第二行一个长为 的由( 与) 组成的括号串,第 个括号表示 号结点上的括号。
第三行包含 个整数,第 ()个整数表示 号结点的父亲编号 。
输出格式#
仅一行一个整数表示答案。
样例 #1#
样例输入 #1#
5
(()()
1 1 2 2
样例输出 #1#
6
提示#
【样例解释1】
树的形态如下图:
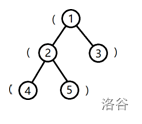
将根到 1 号结点的简单路径上的括号,按经过顺序排列所组成的字符串为 (,子串是合法括号串的个数为 。
将根到 2 号结点的字符串为 ((,子串是合法括号串的个数为 。
将根到 3 号结点的字符串为 (),子串是合法括号串的个数为 。
将根到 4 号结点的字符串为 (((,子串是合法括号串的个数为 。
将根到 5 号结点的字符串为 ((),子串是合法括号串的个数为 。
【数据范围】
说实话,我并不知道我打的啥 = =
好像是数组 + 指针 + dfs 回溯?但肯定打挂了……不然就过了,55分纯属走运了吧
// The code was written by yifan, and yifan is neutral!!!
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define bug puts("NOIP rp ++!");
#define rep(i, a, b, c) for (int i = (a); i <= (b); i += (c))
#define per(i, a, b, c) for (int i = (a); i >= (b); i -= (c))
template<typename T>
inline T read() {
T x = 0;
bool fg = 0;
char ch = getchar();
while (ch < '0' || ch > '9') {
fg |= (ch == '-');
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = (x << 3) + (x << 1) + (ch ^ 48);
ch = getchar();
}
return fg ? ~x + 1 : x;
}
const int N = 5e5 + 5;
int pos0, n;
ll res;
int fa[N], cnt[N];
char s[N];
ll ans[N];
vector<int> e[N];
void dfs(int u) {
ll tmp = res, tmp2;
if (s[u] == '(') {
ans[u] = u * res;
++ cnt[pos0 ++];
} else {
if (pos0 != 0) {
res += cnt[pos0 - 1];
}
ans[u] = u * res;
if (pos0) {
tmp2 = cnt[pos0];
cnt[pos0 --] = 0;
} else {
res = 0;
}
}
for (int v : e[u]) {
dfs(v);
}
if (s[u] == '(') {
cnt[-- pos0] --;
} else {
if (res) {
cnt[++ pos0] = tmp2;
}
}
res = tmp;
}
int main() {
n = read<int>();
scanf("%s", s + 1);
rep (i, 2, n, 1) {
fa[i] = read<int>();
e[fa[i]].emplace_back(i);
}
dfs(1);
ll Ans = 0;
rep (i, 1, n, 1) {
Ans ^= ans[i];
}
cout << Ans << '\n';
return 0;
}
[CSP-S2019] 树上的数#
题目描述#
给定一个大小为 的树,它共有 个结点与 条边,结点从 编号。初始时每个结点上都有一个 的数字,且每个 的数字都只在恰好一个结点上出现。
接下来你需要进行恰好 次删边操作,每次操作你需要选一条未被删去的边,此时这条边所连接的两个结点上的数字将会交换,然后这条边将被删去。
次操作过后,所有的边都将被删去。此时,按数字从小到大的顺序,将数字 所在的结点编号依次排列,就得到一个结点编号的排列 。现在请你求出,在最优操作方案下能得到的字典序最小的 。

如上图,蓝圈中的数字 一开始分别在结点②、①、③、⑤、④。按照 (1)(4)(3)(2) 的顺序删去所有边,树变为下图。按数字顺序得到的结点编号排列为①③④②⑤,该排列是所有可能的结果中字典序最小的。

输入格式#
本题输入包含多组测试数据。
第一行一个正整数 ,表示数据组数。
对于每组测试数据:
第一行一个整数 ,表示树的大小。
第二行 个整数,第 个整数表示数字 初始时所在的结点编号。
接下来 行每行两个整数 , ,表示一条连接 号结点与 号结点的边。
输出格式#
对于每组测试数据,输出一行共 个用空格隔开的整数,表示最优操作方案下所能得到的字典序最小的 。
样例 #1#
样例输入 #1#
4
5
2 1 3 5 4
1 3
1 4
2 4
4 5
5
3 4 2 1 5
1 2
2 3
3 4
4 5
5
1 2 5 3 4
1 2
1 3
1 4
1 5
10
1 2 3 4 5 7 8 9 10 6
1 2
1 3
1 4
1 5
5 6
6 7
7 8
8 9
9 10
样例输出 #1#
1 3 4 2 5
1 3 5 2 4
2 3 1 4 5
2 3 4 5 6 1 7 8 9 10
提示#
【数据范围】
| 测试点编号 | 特殊性质 | |
|---|---|---|
| 10 | 无 | |
| 160 | 树的形态是一条链 | |
| 2000 | 同上 | |
| 160 | 存在度数为 的结点 | |
| 2000 | 同上 | |
| 160 | 无 | |
| 2000 | 无 |
对于所有测试点:,保证给出的是一个树。
一道黑……
最纯粹的暴力,枚举删边的顺序即可,有 分的好成绩……
// The code was written by yifan, and yifan is neutral!!!
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define bug puts("NOIP rp ++!");
#define rep(i, a, b, c) for (int i = (a); i <= (b); i += (c))
#define per(i, a, b, c) for (int i = (a); i >= (b); i -= (c))
template<typename T>
inline T read() {
T x = 0;
bool fg = 0;
char ch = getchar();
while (ch < '0' || ch > '9') {
fg |= (ch == '-');
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = (x << 3) + (x << 1) + (ch ^ 48);
ch = getchar();
}
return fg ? ~x + 1 : x;
}
const int N = 2010;
using tii = tuple<int, int>;
int T, n;
int val[N], tmp[N], ans[N];
bool vis[N];
tii e[N];
void work() {
sort(tmp + 1, tmp + n + 1, [](int x, int y) {
return val[x] < val[y];
});
rep (i, 1, n, 1) {
if (ans[i] > tmp[i]) {
rep (j, 1, n, 1) {
ans[j] = tmp[j];
}
return ;
}
if (ans[i] < tmp[i]) {
return ;
}
}
}
void dfs(int x) {
if (x == n) {
work();
return ;
}
int u, v;
rep (i, 1, n - 1, 1) {
if (vis[i]) continue ;
vis[i] = 1;
tie(u, v) = e[i];
swap(val[u], val[v]);
dfs(x + 1);
swap(val[u], val[v]);
vis[i] = 0;
}
}
void solve() {
n = read<int>();
rep (i, 1, n, 1) {
int x = read<int>();
tmp[i] = val[x] = i;
ans[i] = n;
}
int x, y;
rep (i, 1, n - 1, 1) {
x = read<int>(), y = read<int>();
e[i] = make_tuple(x, y);
vis[i] = 0;
}
dfs(1);
rep (i, 1, n, 1) {
cout << ans[i] << ' ';
}
putchar('\n');
}
int main() {
T = read<int>();
while (T --) {
solve();
}
return 0;
}
[CSP-S2019] Emiya 家今天的饭#
题目描述#
Emiya 是个擅长做菜的高中生,他共掌握 种烹饪方法,且会使用 种主要食材做菜。为了方便叙述,我们对烹饪方法从 编号,对主要食材从 编号。
Emiya 做的每道菜都将使用恰好一种烹饪方法与恰好一种主要食材。更具体地,Emiya 会做 道不同的使用烹饪方法 和主要食材 的菜(、),这也意味着 Emiya 总共会做 道不同的菜。
Emiya 今天要准备一桌饭招待 Yazid 和 Rin 这对好朋友,然而三个人对菜的搭配有不同的要求,更具体地,对于一种包含 道菜的搭配方案而言:
- Emiya 不会让大家饿肚子,所以将做至少一道菜,即
- Rin 希望品尝不同烹饪方法做出的菜,因此她要求每道菜的烹饪方法互不相同
- Yazid 不希望品尝太多同一食材做出的菜,因此他要求每种主要食材至多在一半的菜(即 道菜)中被使用
这里的 为下取整函数,表示不超过 的最大整数。
这些要求难不倒 Emiya,但他想知道共有多少种不同的符合要求的搭配方案。两种方案不同,当且仅当存在至少一道菜在一种方案中出现,而不在另一种方案中出现。
Emiya 找到了你,请你帮他计算,你只需要告诉他符合所有要求的搭配方案数对质数 取模的结果。
输入格式#
第 1 行两个用单个空格隔开的整数 。
第 2 行至第 行,每行 个用单个空格隔开的整数,其中第 行的 个数依次为 。
输出格式#
仅一行一个整数,表示所求方案数对 取模的结果。
样例 #1#
样例输入 #1#
2 3
1 0 1
0 1 1
样例输出 #1#
3
样例 #2#
样例输入 #2#
3 3
1 2 3
4 5 0
6 0 0
样例输出 #2#
190
样例 #3#
样例输入 #3#
5 5
1 0 0 1 1
0 1 0 1 0
1 1 1 1 0
1 0 1 0 1
0 1 1 0 1
样例输出 #3#
742
提示#
【样例 1 解释】
由于在这个样例中,对于每组 ,Emiya 都最多只会做一道菜,因此我们直接通过给出烹饪方法、主要食材的编号来描述一道菜。
符合要求的方案包括:
- 做一道用烹饪方法 1、主要食材 1 的菜和一道用烹饪方法 2、主要食材 2 的菜
- 做一道用烹饪方法 1、主要食材 1 的菜和一道用烹饪方法 2、主要食材 3 的菜
- 做一道用烹饪方法 1、主要食材 3 的菜和一道用烹饪方法 2、主要食材 2 的菜
因此输出结果为 。 需要注意的是,所有只包含一道菜的方案都是不符合要求的,因为唯一的主要食材在超过一半的菜中出现,这不满足 Yazid 的要求。
【样例 2 解释】
Emiya 必须至少做 2 道菜。
做 2 道菜的符合要求的方案数为 100。
做 3 道菜的符合要求的方案数为 90。
因此符合要求的方案数为 100 + 90 = 190。
【数据范围】
| 测试点编号 | 测试点编号 | ||||||
|---|---|---|---|---|---|---|---|
对于所有测试点,保证 ,,。
dfs 搜索,很纯粹的暴力,由于题目给的限制条件很多,所以搜索的时候复杂度就被剪下来了,能拿到 分的好成绩。
// The code was written by yifan, and yifan is neutral!!!
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define bug puts("NOIP rp ++!");
#define rep(i, a, b, c) for (int i = (a); i <= (b); i += (c))
#define per(i, a, b, c) for (int i = (a); i >= (b); i -= (c))
template<typename T>
inline T read() {
T x = 0;
bool fg = 0;
char ch = getchar();
while (ch < '0' || ch > '9') {
fg |= (ch == '-');
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = (x << 3) + (x << 1) + (ch ^ 48);
ch = getchar();
}
return fg ? ~x + 1 : x;
}
const int N = 110;
const int M = 2e3 + 5;
const int mod = 998244353;
int n, m, limt;
ll ans;
ll a[N][M], cnt[M];
bool used[N];
vector<ll> food;
void dfs(int rest, int beg) {
if (rest == 0) {
ll res = 1;
for (ll v : food) {
res = res * v % mod;
}
ans = (ans + res) % mod;
return ;
}
if (beg > n) return ;
rep (i, beg, n, 1) {
rep (j, 1, m, 1) {
if (cnt[j] >= limt) continue ;
food.emplace_back(a[i][j]);
++ cnt[j];
dfs(rest - 1, i + 1);
food.pop_back();
-- cnt[j];
}
}
}
int main() {
n = read<int>(), m = read<int>();
rep (i, 1, n, 1) {
rep (j, 1, m, 1) {
a[i][j] = read<int>();
}
}
rep (i, 1, n, 1) {
limt = (i >> 1);
dfs(i, 1);
}
cout << ans << '\n';
return 0;
}
[CSP-S2019] 划分#
题目描述#
2048 年,第三十届 CSP 认证的考场上,作为选手的小明打开了第一题。这个题的样例有 组数据,数据从 编号, 号数据的规模为 。
小明对该题设计出了一个暴力程序,对于一组规模为 的数据,该程序的运行时间为 。然而这个程序运行完一组规模为 的数据之后,它将在任何一组规模小于 的数据上运行错误。样例中的 不一定递增,但小明又想在不修改程序的情况下正确运行样例,于是小明决定使用一种非常原始的解决方案:将所有数据划分成若干个数据段,段内数据编号连续,接着将同一段内的数据合并成新数据,其规模等于段内原数据的规模之和,小明将让新数据的规模能够递增。
也就是说,小明需要找到一些分界点 ,使得
注意 可以为 且此时 ,也就是小明可以将所有数据合并在一起运行。
小明希望他的程序在正确运行样例情况下,运行时间也能尽量小,也就是最小化
小明觉得这个问题非常有趣,并向你请教:给定 和 ,请你求出最优划分方案下,小明的程序的最小运行时间。
输入格式#
由于本题的数据范围较大,部分测试点的 将在程序内生成。
第一行两个整数 。 的意义见题目描述, 表示输入方式。
- 若 ,则该测试点的 直接给出。输入文件接下来:第二行 个以空格分隔的整数 ,表示每组数据的规模。
- 若 ,则该测试点的 将特殊生成,生成方式见后文。输入文件接下来:第二行六个以空格分隔的整数 。接下来 行中,第 行包含三个以空格分隔的正整数 。
对于 的 23~25 号测试点, 的生成方式如下:
给定整数 ,以及 个三元组 。
保证 。若 ,则 。
保证 。令 ,则 还满足 有 。
对于所有 ,若下标值 满足 ,则有
上述数据生成方式仅是为了减少输入量大小,标准算法不依赖于该生成方式。
输出格式#
输出一行一个整数,表示答案。
样例 #1#
样例输入 #1#
5 0
5 1 7 9 9
样例输出 #1#
247
样例 #2#
样例输入 #2#
10 0
5 6 7 7 4 6 2 13 19 9
样例输出 #2#
1256
样例 #3#
样例输入 #3#
10000000 1
123 456 789 12345 6789 3
2000000 123456789 987654321
7000000 234567891 876543219
10000000 456789123 567891234
样例输出 #3#
4972194419293431240859891640
提示#
【样例 1 解释】
最优的划分方案为 。由 知该方案合法。
答案为 。
虽然划分方案 对应的运行时间比 小,但它不是一组合法方案,因为 。
虽然划分方案 合法,但该方案对应的运行时间为 ,比 大。
【样例 2 解释】
最优的划分方案为 。
【数据范围】
| 测试点编号 | |||
|---|---|---|---|
| 0 | |||
| 0 | |||
| 0 | |||
| 0 | |||
| 0 | |||
| 1 |
对于的所有测试点,保证最后输出的答案
所有测试点满足:,,,,,。
还是 dfs 暴力枚举划分位置。
// The code was written by yifan, and yifan is neutral!!!
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define bug puts("NOIP rp ++!");
#define rep(i, a, b, c) for (int i = (a); i <= (b); i += (c))
#define per(i, a, b, c) for (int i = (a); i >= (b); i -= (c))
template<typename T>
inline T read() {
T x = 0;
bool fg = 0;
char ch = getchar();
while (ch < '0' || ch > '9') {
fg |= (ch == '-');
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = (x << 3) + (x << 1) + (ch ^ 48);
ch = getchar();
}
return fg ? ~x + 1 : x;
}
const int N = 5e5 + 5;
int n, type;
ll ans = 1e18;
ll a[N], sum[N];
vector<ll> val;
void work() {
ll res = 0, las = 0;
for (ll v : val) {
if (v < las) return ;
res += v * v;
las = v;
}
if (res < ans) {
ans = res;
}
}
void dfs(int las) {
if (las > n) return ;
rep (i, las + 1, n, 1) {
if (sum[i] - sum[las] > sum[n] - sum[i]) {
val.emplace_back(sum[n] - sum[las]);
work();
val.pop_back();
return ;
} else {
val.emplace_back(sum[i] - sum[las]);
dfs(i);
val.pop_back();
}
}
}
int main() {
n = read<int>(), type = read<int>();
rep (i, 1, n, 1) {
a[i] = read<int>();
sum[i] = sum[i - 1] + a[i];
}
dfs(0);
cout << ans << '\n';
return 0;
}
[CSP-S2019] 树的重心#
题目描述#
小简单正在学习离散数学,今天的内容是图论基础,在课上他做了如下两条笔记:
- 一个大小为 的树由 个结点与 条无向边构成,且满足任意两个结点间有且仅有一条简单路径。在树中删去一个结点及与它关联的边,树将分裂为若干个子树;而在树中删去一条边(保留关联结点,下同),树将分裂为恰好两个子树。
- 对于一个大小为 的树与任意一个树中结点 ,称 是该树的重心当且仅当在树中删去 及与它关联的边后,分裂出的所有子树的大小均不超过 (其中 是下取整函数)。对于包含至少一个结点的树,它的重心只可能有 1 或 2 个。
课后老师给出了一个大小为 的树 ,树中结点从 编号。小简单的课后作业是求出 单独删去每条边后,分裂出的两个子树的重心编号和之和。即:
上式中, 表示树 的边集, 表示一条连接 号点和 号点的边。 与 分别表示树 删去边 后, 号点与 号点所在的被分裂出的子树。
小简单觉得作业并不简单,只好向你求助,请你教教他。
输入格式#
本题包含多组测试数据
第一行一个整数 表示数据组数。
接下来依次给出每组输入数据,对于每组数据:
第一行一个整数 表示树 的大小。
接下来 行,每行两个以空格分隔的整数 ,,表示树中的一条边 。
输出格式#
共 行,每行一个整数,第 行的整数表示:第 组数据给出的树单独删去每条边后,分裂出的两个子树的重心编号和之和。
样例 #1#
样例输入 #1#
2
5
1 2
2 3
2 4
3 5
7
1 2
1 3
1 4
3 5
3 6
6 7
样例输出 #1#
32
56
提示#
【样例 1 解释】
对于第一组数据:
删去边 ,1 号点所在子树重心编号为 ,2 号点所在子树重心编号为 。
删去边 ,2 号点所在子树重心编号为 ,3 号点所在子树重心编号为 。
删去边 ,2 号点所在子树重心编号为 ,4 号点所在子树重心编号为 。
删去边 ,3 号点所在子树重心编号为 ,5 号点所在子树重心编号为 。
因此答案为 。
【数据范围】
| 测试点编号 | 特殊性质 | |
|---|---|---|
| 无 | ||
| 无 | ||
| 无 | ||
| A | ||
| B | ||
| 无 | ||
| 无 | ||
| 无 |
表中特殊性质一栏,两个变量的含义为存在一个 的排列 ,使得:
- A:树的形态是一条链。即 ,存在一条边 。
- B:树的形态是一个完美二叉树。即 ,存在两条边 与 。
对于所有测试点:。保证给出的图是一个树。
比较暴力了。
枚举删边,进行 dfs 和 dp 来找树的重心。
// The code was written by yifan, and yifan is neutral!!!
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define bug puts("NOIP rp ++!");
#define rep(i, a, b, c) for (int i = (a); i <= (b); i += (c))
#define per(i, a, b, c) for (int i = (a); i >= (b); i -= (c))
template<typename T>
inline T read() {
T x = 0;
bool fg = 0;
char ch = getchar();
while (ch < '0' || ch > '9') {
fg |= (ch == '-');
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = (x << 3) + (x << 1) + (ch ^ 48);
ch = getchar();
}
return fg ? ~x + 1 : x;
}
const int N = 3e5 + 5;
using tii = tuple<int, int>;
int T, n, limx, limy;
ll ans;
int siz[N], dp[N];
vector<int> e[N];
vector<tii> E;
void init() {
ans = 0;
E.clear();
rep (i, 1, n, 1) {
e[i].clear();
}
memset(dp, 0, sizeof dp);
}
void dfs(int u, int fat) {
siz[u] = 1;
for (int v : e[u]) {
if (v == fat || ((u == limx) && (v == limy)) || ((u == limy) && (v == limx))) continue ;
dfs(v, u);
siz[u] += siz[v];
}
}
void Dp(int u, int fat, int tp) {
dp[u] = 0;
for (int v : e[u]) {
if (v == fat || ((u == limx) && (v == limy)) || ((u == limy) && (v == limx))) continue ;
Dp(v, u, tp);
dp[u] = max(dp[u], siz[v]);
}
dp[u] = max(siz[tp] - siz[u], dp[u]);
if (dp[u] <= (siz[tp] / 2)) {
ans += u;
}
}
void solve() {
n = read<int>();
int x, y;
rep (i, 1, n - 1, 1) {
x = read<int>(), y = read<int>();
e[x].emplace_back(y);
e[y].emplace_back(x);
E.emplace_back(x, y);
}
for (tii it : E) {
tie(limx, limy) = it;
dfs(limx, 0);
dfs(limy, 0);
Dp(limx, 0, limx);
Dp(limy, 0, limy);
}
cout << ans << '\n';
}
int main() {
T = read<int>();
while (T --) {
init();
solve();
}
return 0;
}
作者:yifan0305
出处:https://www.cnblogs.com/yifan0305/p/17723312.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
转载时还请标明出处哟!




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】