「学习笔记」后缀数组
感谢 LB 学长的博文!
2023.7.13 做了一点知识的补充(height 数组)。
2023.8.24 做了一点关于应用的补充。
前置知识
后缀是指从某个位置 \(i\) 开始到整个串末尾结束的一个特殊子串,也就是 \(S[i : |S|-1]\)。字符串 \(S\) 的从 \(i\) 开头的后缀表示为 \(\textit{Suffix(S,i)}\),也就是 \(\textit{Suffix(S,i)}=S[i : |S|-1]\)。
变量
后缀数组最主要的两个数组是 sa 和 rk。
sa 表示将所有后缀排序后第 \(i\) 小的后缀的编号,即编号数组。
rk 表示后缀 \(i\) 的排名,即排名数组。
这两个数组满足一个重要性质: sa[rk[i]] = rk[sa[i]] = i。
示例:
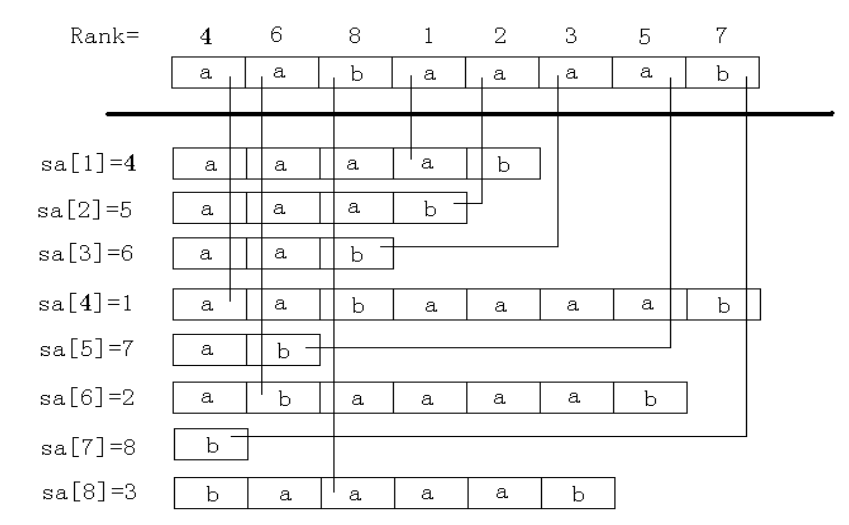
这个图很好理解。
做法
暴力的 \(O_{n^2 \log n}\) 做法
将所有的后缀数组都 sort 一遍,sort 复杂度为 \(O_{n \log n}\),字符串比较复杂度为 \(O_{n}\),总的复杂度 \(O_{n^2 \log n}\)。
/*
The code was written by yifan, and yifan is neutral!!!
*/
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
template<typename T>
inline T read() {
T x = 0;
bool fg = 0;
char ch = getchar();
while (ch < '0' || ch > '9') {
fg |= (ch == '-');
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = (x << 3) + (x << 1) + (ch ^ 48);
ch = getchar();
}
return fg ? ~x + 1 : x;
}
const int N = 1e6 + 5;
int n;
char s[N];
string h[N];
pair<string, int> ans[N];
int main() {
scanf("%s", s + 1);
n = strlen(s + 1);
for (int i = 1; i <= n; ++ i) {
for (int j = i; j <= n; ++ j) {
h[i] += s[j];
}
ans[i] = {h[i], i};
}
sort(ans + 1, ans + n + 1);
for (int i = 1; i <= n; ++ i) {
cout << ans[i].second << ' ';
}
return 0;
}
倍增优化的 \(O_{n \log^2 n}\) 做法
先对长度为 \(1\) 的所有子串,即每个字符排序,得到排序后的 sa1 和 rk1 数组。
之后倍增:
-
用两个长度为 \(1\) 的子串的排名,即
rk1[i]和rk1[i + 1],作为排序的第一关键词和第二关键词,这样就可以对每个长度为 \(2\) 的子串进行排序,得到sa2和rk2; -
之后用两个长度为 \(2\) 的子串的排名,即
rk2[i]和rk2[i + 2],来作为排序的第一关键词和第二关键词。(为什么是 \(i + 2\) 呢,因为rk2[i]和rk2[i + 1]重复了 \(S_{i + 1}\))这样就可以对每个长度为 \(4\) 的子串进行排序,得到sa4和rk4; -
重复上面的操作,用两个长度为 \(\dfrac{w}{2}\) 的子串的排名,即
rk[i]和rk[i + (w / 2)],来作为排序的第一关键词和第二关键词,直到 \(w \ge n\),最终得到的sa数组就是我们的答案数组。
示意图:

倍增的复杂度为 \(O_{\log n}\),sort 复杂度为 \(O_{n \log n}\),总的复杂度 \(O_{n \log ^ 2 n}\)。
排序优化的 \(O_{n \log n}\) 的做法
发现后缀数组值域即为 \(n\),又是多关键字排序,考虑基数排序。
上面已经给出一个用于比较的式子:(A[i] < A[j] or (A[i] = A[j] and B[i] < B[j])),倍增过程中 A[i], B[i] 大小关系已知,先将 B[i] 作为第二关键字排序,再将 A[i] 作为第一关键字排序,两次计数排序实现即可。
单次计数排序复杂度 \(O_{n+w}\)(\(w\) 为值域,显然最大与 \(n\) 同阶),总时间复杂度变为 \(O_{n \log n}\)。
//The code was written by yifan, and yifan is neutral!!!
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define bug puts("NOIP rp ++!");
#define rep(i, a, b, c) for (int i = (a); i <= (b); i += (c))
#define per(i, a, b, c) for (int i = (a); i >= (b); i -= (c))
template<typename T>
inline T read() {
T x = 0;
bool fg = 0;
char ch = getchar();
while (ch < '0' || ch > '9') {
fg |= (ch == '-');
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = (x << 3) + (x << 1) + (ch ^ 48);
ch = getchar();
}
return fg ? ~x + 1 : x;
}
const int N = 1e6 + 5;
int n, m;
int sa[N], tmpsa[N], rk[N << 1], tmprk[N << 1], cnt[N];
// rk 第 i 个后缀的排名,sa 第 i 小的后缀的编号
char s[N];
int main() {
scanf("%s", s + 1);
n = strlen(s + 1);
m = 127;
/*--------------------------------*/
// 计数排序
rep (i, 1, n, 1) {
++ cnt[rk[i] = s[i]];
}
rep (i, 1, m, 1) {
cnt[i] += cnt[i - 1];
}
per (i, n, 1, 1) {
sa[cnt[rk[i]] --] = i;
}
memcpy(tmprk + 1, rk + 1, n * sizeof(int));
/*--------------------------------*/
// 判重
for (int cur = 0, i = 1; i <= n; ++ i) {
if (tmprk[sa[i]] == tmprk[sa[i - 1]]) {
rk[sa[i]] = cur;
}
else {
rk[sa[i]] = ++ cur;
}
}
/*--------------------------------*/
for (int w = 1; w < n; w <<= 1, m = n) {
// 先按照第二关键词计数排序
memset(cnt, 0, sizeof cnt);
memcpy(tmpsa + 1, sa + 1, n * sizeof(int));
for (int i = 1; i <= n; ++ i) {
++ cnt[rk[tmpsa[i] + w]]; // rk[oldsa[i] + w] (第i小的编号 + w) 位置的排名
}
for (int i = 1; i <= m; ++ i) {
cnt[i] += cnt[i - 1];
}
for (int i = n; i >= 1; -- i) {
sa[cnt[rk[tmpsa[i] + w]] --] = tmpsa[i];
}
/*--------------------------------*/
// 再按照第一关键词计数排序
memset(cnt, 0, sizeof cnt);
memcpy(tmpsa + 1, sa + 1, n * sizeof(int));
for (int i = 1; i <= n; ++ i) {
++ cnt[rk[tmpsa[i]]];
}
for (int i = 1; i <= m; ++ i) {
cnt[i] += cnt[i - 1];
}
for (int i = n; i >= 1; -- i) {
sa[cnt[rk[tmpsa[i]]] --] = tmpsa[i];
}
/*--------------------------------*/
// 更新数组
memcpy(tmprk + 1, rk + 1, n * sizeof(int));
for (int cur = 0, i = 1; i <= n; ++ i) {
if (tmprk[sa[i]] == tmprk[sa[i - 1]] && tmprk[sa[i] + w] == tmprk[sa[i - 1] + w]) {
rk[sa[i]] = cur;
}
else {
rk[sa[i]] = ++ cur;
}
}
}
for (int i = 1; i <= n; ++ i) {
printf("%d ", sa[i]);
}
return 0;
}
给在第二关键词排序时,sa[i] 存储的是第二关键词第 \(i\) 小的后缀的编号,但是并没有修改 rk。之后再给第一关键词排序时,oldsa 存储的是 sa 的信息,rk 依旧没有变,只要 rk 没有变,计数排序就不会被影响。从后往前更新,是为了在第一关键词相等时,可以直接利用第二关键词的排序。
为什么先按第二关键词排序,而不是先按第一关键词排序呢?
从代码里我们可以看到,先按照第二关键词排序,然后再给第一关键词排序时,是在第二关键词的基础上进行的,这样的用处是当第一关键词相同时,我们不用在处理第二关键词了,直接按照排序的顺序依次往下放。
假设先按第一关键词排序,某两个位置的第一关键词相同,那么接下来看第二关键词。
在按照第二关键词排序时,第一关键词变成了实际意义上的第二关键词了,即先按照第二关键词排序,第二关键词相同时,再按照第一关键词排序,与我们的目的不符。
各种常数优化
- 考虑我们按照第二关键词排序的实质,就是将超出 \(n\) 范围的空字符串放在
sa的最前面,在本次排序中,\(S[sa_i : sa_i+2^k−1]\) 是长度为 \(2^k\) 的子串 \(S[sai−2^k−1 : sai+2^k−1]\) 的后半截,sa[i]的排名将作为排序的关键字。
\(S[sa_i : sa_i+2^k−1]\) 的排名为 \(i\),则第一次计排后 \(S[sa_i−2^k−1 : sa_i+2^k−1]\) 的排名必为 \(i\),考虑直接赋值。
我们设 tmpsa 为处理完第二关键词排序的 sa 数组,即 tmpsa[i] 的含义是第二关键词排名为 \(i\) 的后缀,此时的 sa 还是上一轮倍增遗留的产物,可以直接被我们利用。
for (p = 0, i = n; i > n - w; -- i) {
tmpsa[++ p] = i;
}
for (int i = 1; i <= n; ++ i) {
if (sa[i] > w) { // 保证 sa[i] 是后半截的编号
tmpsa[++ p] = sa[i] - w; // sa[i] 一定是后半截的编号,而我们要存的是前半截的开始编号
}
}
-
减小值域,每次对
rk进行更新之后,我们都计算了一个 \(p\),这个 \(p\) 即是rk的值域,将值域改成它即可。 -
将
rk[tmpsa[i]]存下来,减少不连续内存访问。 -
用函数
cmp来计算是否重复。 -
若排名都不相同可直接生成后缀数组。
//The code was written by yifan, and yifan is neutral!!!
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
#define bug puts("NOIP rp ++!");
#define rep(i, a, b, c) for (int i = (a); i <= (b); i += (c))
#define per(i, a, b, c) for (int i = (a); i >= (b); i -= (c))
template<typename T>
inline T read() {
T x = 0;
bool fg = 0;
char ch = getchar();
while (ch < '0' || ch > '9') {
fg |= (ch == '-');
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = (x << 3) + (x << 1) + (ch ^ 48);
ch = getchar();
}
return fg ? ~x + 1 : x;
}
const int N = 1e6 + 5;
int n, m;
int sa[N], rk[N << 1], tmpsa[N], tmprk[N << 1], cnt[N], key[N];
// todo sa[i]: 目前求的后缀数组排名为 i 的后缀,rk[i]: 目前求的后缀数组,后缀 i 的排名
// todo tmpsa[i]: 求的后缀数组第二关键字排名为 i 的后缀,tmpsa[i]: 替换作用
// todo key[i]: 当前这一轮第二关键字排名为 i 的第一关键字的排名
char s[N];
bool cmp(int x, int y, int w) {
return (tmprk[x] == tmprk[y]) && (tmprk[x + w] == tmprk[y + w]);
}
int main() {
scanf("%s", s + 1);
n = strlen(s + 1);
m = 127;
rep (i, 1, n, 1) {
++ cnt[rk[i] = s[i]];
}
rep (i, 1, m, 1) {
cnt[i] += cnt[i - 1];
}
per (i, n, 1, 1) {
sa[cnt[rk[i]] --] = i;
}
int p;
for (int w = 1; w <= n; w <<= 1, m = p) {
// todo m = p 减小值域,m 是用于给 rk 计数排序的,rk 的值域为 p,则 m 也为 p
// todo 优化 2
p = 0;
per (i, n, n - w + 1, 1) { // todo 优化 1
tmpsa[++ p] = i;
}
rep (i, 1, n, 1) {
if (sa[i] > w) {
tmpsa[++ p] = sa[i] - w;
}
}
memset(cnt, 0, sizeof cnt);
rep (i, 1, n, 1) { // todo 优化 3
++ cnt[key[i] = rk[tmpsa[i]]];
}
rep (i, 1, m, 1) { // todo 优化 2
cnt[i] += cnt[i - 1];
}
per (i, n, 1, 1) {
sa[cnt[key[i]] --] = tmpsa[i];
}
memcpy(tmprk + 1, rk + 1, n * sizeof(int));
p = 0;
rep (i, 1, n, 1) {
rk[sa[i]] = cmp(sa[i], sa[i - 1], w) ? p : ++ p;
// todo 优化 4
}
if (p == n) { // todo 优化 5
break ;
}
}
rep (i, 1, n, 1) {
cout << sa[i] << ' ';
}
return 0;
}
LCP 问题(最长公共前缀)
参考主要来自「笔记」后缀数组 - Luckyblock - 博客园 (cnblogs.com),感谢 LB 学长!
定义:
\(\operatorname{lcp}(S, T)\):定义为字符串 \(S\) 和 \(T\) 的最长公共前缀,即最大的 \(l \le \min\{|S|, |T|\}\),满足 \(S_i = T_i (1 \le i \le l)\),在这里 \(\operatorname{lcp}(i, j)\) 表示后缀 \(i, j\) 的最长公共前缀。
定义新数组 height 和 h。
\(\operatorname{height}_i\) 表示排名为 \(i - 1\) 和 \(i\) 的两个后缀的最长公共前缀,即 \(\operatorname{lcp}(sa_{i - 1}, sa_i)\)。
\(h_i\) 表示后缀 \(i\) 和排名在 \(i\) 之前一位的后缀的最长公共前缀,即 \(h_i= \operatorname{height}_{rk_i} = \operatorname{lcp}(sa_{rk_{i} - 1},sa_{rk_i}) = \operatorname{lcp} (sa_{rk_{i} - 1}, i)\)。
引理:LCP Lemma
\(\forall 1 \le i < j < k \le n, \operatorname{lcp}(sa_i, sa_k) = \min\{\operatorname{lcp}(sa_i, sa_j), \operatorname{lcp}(sa_j, sa_k)\}\)
证明:
设 \(p = \min \{ \operatorname{lcp}(sa_i, sa_j), \operatorname{lcp}(sa_j, sa_k) \}\),则有
即 \(sa_i \left [1 : p \right ] = sa_j \left[ 1 : p \right] = s_k \left[ 1 : p \right ]\),由此可得 \(\operatorname{lcp}(sa_i, sa_k) \ge p\)。
再考虑反证法,设 \(\operatorname{lcp}(sa_i, sa_k) = q > p\),则 \(sa_i \left [1 : q \right ] = sa_k \left[1 : q \right]\),有 \(sa_{i} \left[ p + 1 \right ] = sa_{k} \left[ p + 1 \right ]\)。
对 \(p\) 的取值进行分类讨论:
-
\(p = \operatorname{lcp} (sa_i, sa_j) < \operatorname{lcp}(sa_j, sa_k)\) 时,则有 \(sa_i \left[p + 1 \right ] \ne sa_j \left [ p + 1 \right ], sa_j \left [ p + 1 \right ] = sa_k \left[ p + 1 \right ]\)。
-
\(p = \operatorname{lcp} (sa_j, sa_k) < \operatorname{lcp} (sa_i, sa_j)\) 时,则有 \(sa_k \left[ p + 1\right ] \ne sa_i \left [ p + 1 \right ], sa_i \left [ p + 1 \right ] = sa_j \left[ p + 1\right ]。\)
-
\(p = \operatorname{lcp} (sa_i, sa_j) = \operatorname{lcp} (sa_j, sa_k)\) 时,则有 \(sa_i \left[p + 1 \right ] \ne sa_j \left[ p + 1 \right ] \ne sa_k \left [p + 1 \right ]\)。
\(sa_i \left[p + 1 \right] \ne sa_k \left[p + 1 \right]\) 恒成立,与已知矛盾,则 \(\operatorname{lcp} (sa_i, sa_k) \le p\)。
引理:LCP Theorem
有 LCP Lemma 可知,显然成立。
根据这个式子,求任意两个后缀的 \(\operatorname{lcp}\) 问题就变为了求 \(\operatorname{height}\) 的区间最值问题。
通过 st 表预处理。
推论:LCP Corollary
表示排名不相邻的两个后缀的 \(\operatorname{lcp}\) 不超过它们之间任何相邻元素的 \(\operatorname{lcp}\)。
考虑反证法。设 \(\operatorname{lcp}(sa_i, sa_j) < \operatorname{lcp}(sa_i, sa_k)\),则由下图:

在字典序比较的过程中,若 \(sa_i < sa_j\),则有 \(sa_i \left[ \operatorname{lcp} (sa_i, sa_j) + 1 \right ] < sa_j \left [ \operatorname{lcp} (sa_i, sa_j) + 1 \right ]\),即图中的字符 \(x < y\)。
再考虑比较 \(sa_j\) 与 \(sa_k\) 的字典序,\(\operatorname{lcp} (sa_i,sa_k) > \operatorname{lcp}(sa_i,sa_j)\),则 \(sa_k \left[ \operatorname{lcp} (sa_j, sa_k) + 1 \right ] = x\)。
又因为 \(x < y\),可以得到 \(sa_k\) 的字典序小于 \(sa_j\),与已知矛盾,反正原结论成立。
引理
现在再看一遍定义:
height[i] 表示排名为 \(i - 1\) 和 \(i\) 的两个后缀的最长公共前缀,即 \(\operatorname{lcp}(sa_{i - 1}, sa_i)\)。
h[i] 表示后缀 \(i\) 和排名在 \(i\) 之前一位的后缀的最长公共前缀,即 \(h_i= \operatorname{height}_{rk_i} = \operatorname{lcp}(sa_{rk_{i} - 1},sa_{rk_i}) = \operatorname{lcp} (sa_{rk_{i} - 1}, i)\)。
证明:
考虑数学归纳。首先当 \(h_{i−1} \le 1\) 时,结论显然成立,因为 \(h_i \ge 0\)。
当 \(h_{i - 1} > 1\) 时,设 \(u = i, v = sa_{rk_{i} - 1}\),有 \(h_i = \operatorname{lcp}(u, v)\)。
同时,设 \(u' = i - 1, v' = sa_{rk_{i - 1} - 1}\),有 \(h_{i - 1} = \operatorname{lcp} (u', v')\)。
由 \(h_{i - 1} = \operatorname{lcp} (u', v') > 1\),则 \(u', v'\) 必有公共前缀。
考虑删去 \(u', v'\) 的第一个字符,设其分别变成 \(x, y\)。显然 \(\operatorname{lcp} (x, y) = h_{i - 1} - 1\),且仍满足字典序 \(y < x\)。
\(u' = i - 1\),则删去第一个字符后,\(x\) 等于后缀 \(i\)。
则对于他们在 sa 中的排名,有 \(y < x = i = u\)。
在 sa 中,\(v\) 在 \(u\) 的前一位置,即 \(v < u\) 是不变的,且 \(y \le v\),结合一下,就有 \(y \le v < u\),根据 LCP Corollary (排名不相邻的两个后缀的 \(\operatorname{lcp}\) 不超过它们之间任何相邻元素的 \(\operatorname{lcp}\)),有:
得证。
求 height
根据定义 \(h_i = \operatorname{height}_{rk_i}\),只需快速求出 \(h\),便可 \(O\left(n \right)\) 地获得 \(\operatorname{height}\)。
通过引理我们得到 \(\forall 1 \le i \le n, h_i \ge h_{i - 1} - 1\)。
\(h_i = \operatorname{lcp}(i, sa_{rk_i - 1})\) 不具有完全单调性,考虑正序枚举 \(i\) 进行递推。
-
当 \(rk_i = 1\) 时,\(sa_{rk_{i} - 1}\) 不存在,特判 \(h_i = 0\);
-
当 \(i = 1\) 时,暴力比较出 \(\operatorname{lcp}(i, sa_{rk_i - 1})\),比较次数 \(< n\);
-
若上述情况都不满足,由引理可知,\(h_i = \operatorname{lcp} (i, sa_{rk_i - 1}) \ge h_{i - 1} - 1\),两个前缀前 \(h_{i - 1} - 1\) 位相同,可从第 \(h_{i - 1}\) 位开始比较两个后缀,计算出 \(h_i\),比较次数 \(h_i - h_{i - 1} + 2\)。
在代码中并没有专门开 \(h\) 数组,只是为了方便理解,代码中 \(h_i = k\)。
for (i = 1, k = 0; i <= n; height[rk[i ++]] = k) {
if (rk[i] == 1) {
k = 0;
continue ;
}
k ? -- k : k;
while (s[i + k] == s[sa[rk[i] - 1] + k]) ++ k;
}
height 数组的应用
-
两子串的最长公共前缀
\(\operatorname{lcp}(sa_i, sa_j) = \min \{ \operatorname{height}[i + 1 : j] \}\)
可以转化成 RMQ 问题。
-
比较两个子串大小关系
比较 \(A = s[a:b], B = s[c:d]\) 两个子串的大小。
如果 \(\operatorname{lcp}(A, B) < \min \{ \left |A \right |, \left | B \right | \}\),则直接比较 \(rk_a\) 和 \(rk_b\) 的大小即可。
否则,\(A < B \Longleftrightarrow \left | A \right | < \left | B \right |\)。
-
寻找不同子串的个数
子串就是后缀的前缀,可以枚举后缀,计算前缀总数,减去重复的前缀。
\(sa_i\) 和 \(sa_{i + 1}\) 相同的前缀总数为 \(\operatorname{height[i + 1]}\),字串的总个数为 \(\dfrac{n(n + 1)}{2}\)。
计算公式:\(\dfrac{n(n + 1)}{2} - \sum_{i = 2}^{n} \operatorname{height[i]}\)
-
出现至少 k 次的子串的最大长度
求出相邻 \(k - 1\) 个 \(\operatorname{height}\) 的最小值,在对最小值求最大值即可。
参考资料
后缀数组简介 - OI Wiki (oi-wiki.org)
「笔记」后缀数组 - Luckyblock - 博客园 (cnblogs.com)
后记
字符串一类的算法,本蒟蒻一直都有点绕不过来,后缀数组,从最开始的暴力、sort,到计数排序、基数排序优化,再到常数优化,再到 height 数组,前后花了近两天的时间,但是,自己能通过各种方式把这个东西给啃下来,还是感觉很有成就感的!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号