315题
第一部分 Python基础篇(80题)
1、为什么学习Python?
# 因为python相对其他语言非常优雅简洁,有着丰富的第三方库,我感觉很强大、很方便; # 还有就是,我感觉python简单易学,生态圈庞大,例如:web开发、爬虫、人工智能等,而且未来发展趋势也很不错。
2、通过什么途径学习的Python?
# 在系里社团通过学长了解到python 根据个人情况而定…………
3、Python和Java、PHP、C、C#、C++等其他语言的对比?
# Python、PHP是解释型语言,代码运行期间逐行翻译成目标机器码,下次执行时逐行解释 # 而C、Java是编译型语言,编译后再执行。
4、简述解释型和编译型编程语言?
编译型
优点:编译器一般会有预编译的过程对代码进行优化。因为编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高。可以脱离语言环境独立运行。
缺点:编译之后如果需要修改就需要整个模块重新编译。编译的时候根据对应的运行环境生成机器码,不同的操作系统之间移植就会有问题,需要根据运行的操作系统环境编译不同的可执行文件。
解释型
优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。
缺点:每次运行的时候都要解释一遍,性能上不如编译型语言。
5、Python解释器种类以及特点?
# CPython:C语言开发的,官方推荐,最常用 # IPython:基于CPython之上的交互式解释器,只是在交互上有增强 # JPython:Java写的解释器 # Pypy:Python写的解释器,目前执行速度最快的解释器,采用JIT技术,对Python进行动态编译 # IronPython:C#写的解释器
6、位和字节的关系?
#1字节=8位 #1byte=8bit (数据存储以字节(Byte)为单位)
7、b、B、KB、MB、GB 的关系?
1B=8bit 1个字节(Byte,B)8个比特(bit) 1KB=1024B 1MB=1024KB 1G=1024MB 1T=1024G
8、请至少列举5个 PEP8 规范(越多越好)。

#1、空格使用 a 各种右括号前不要加空格。 b 逗号、冒号、分号前不要加空格。 c 函数的左括号前不要加空格。如Func(1)。 d 序列的左括号前不要加空格。如list[2]。 e 操作符左右各加一个空格,不要为了对齐增加空格。 f 函数默认参数使用的赋值符左右省略空格。 g 不要将多句语句写在同一行,尽管使用‘;’允许。 8 if/for/while语句中,即使执行语句只有一句,也必须另起一行。 #2、代码编排 a 缩进,4个空格,而不是tab键 b 每行长度79,换行可使用反斜杠,最好使用圆括号。 c 类与类之间空两行 d 方法之间空一行
9、通过代码实现如下转换:
二进制转换成十进制:v = “0b1111011” 十进制转换成二进制:v = 18 八进制转换成十进制:v = “011” 十进制转换成八进制:v = 30 十六进制转换成十进制:v = “0x12” 十进制转换成十六进制:v = 87 ################################ v = 0b1111011 print(int(v)) v = 18 print(bin(v)) v = '011' print(int(v)) v = 30 print(oct(v)) v = 0x12 print(int(v)) v = 87 print(hex(v))
10、请编写一个函数实现将IP地址转换成一个整数。
如 10.3.9.12 转换规则为: 10 00001010 3 00000011 9 00001001 12 00001100 再将以上二进制拼接起来计算十进制结果:00001010 00000011 00001001 00001100 = ?
num = bin(10),bin(3),bin(9),bin(12) def int1(): global num return num,int(bin(10),2) + int(bin(3),2) +int(bin(9),2) +int(bin(12),2) print(int1())
如 10.3.9.12 转换规则为: 10 00001010 3 00000011 9 00001001 12 00001100 再将以上二进制拼接起来计算十进制结果:00001010 00000011 00001001 00001100 = ?
num = bin(10),bin(3),bin(9),bin(12) count= 0 for i in num: count +=int(i,2) print(count)
11、python递归的最大层数?
def foo(n): print(n) n += 1 foo(n) foo(1) 测试完之后为最大998 到了999就超过了最大的递归程度
12、求结果:
v1 = 1 or 3 -- 1 v2 = 1 and 3 -- 3 v3 = 0 and 2 and 1 -- 0 v4 = 0 and 2 or 1 -- 1 v5 = 0 and 2 or 1 or 4 -- 1 v6 = 0 or Flase and 1 -- False ######################## 总结: # x or y 如果 x为真,则值为x, 否则为y # x and y 如果 x 为真,则值为 y,否则为 x #and:前后为真才为真 #or:有一为真就为真 #优先级:()>not>and>or #同等优先级下,从左向右 # 变态面试题:思考 # print(1 > 2 or 3 and 4 < 6) # print(2 or 3 and 4 < 6) #先按优先级算() not and or,第一题 3 and 4 < 6 ,3等于True , #4<6等于True ,所以这个and结果为True,最后的or,1 > 2 or True, #1>2是False ,False or True 就是True #第二题 3 and 4 < 6 3等于True ,4<6等于True,,所以这个and结果为True,最后的or,2 or True ,就等于x or y ,x为真,返回x,就是2.
1. 求结果:2 & 5 print(2 & 5) # 10 & 101 => 000 => 0 2. 求结果:2 ^ 5 print(2 ^ 5) # 10 ^ 101 => 111 => 1*2**0+1*2**1+1*2**2=1+2+4=7
13、ascii、unicode、utf-8、gbk 区别?
python2内容进行编码(默认ascii),而python3对内容进行编码的默认为utf-8。 ascii 最多只能用8位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。 unicode 万国码,任何一个字符==两个字节 utf-8 万国码的升级版 一个中文字符==三个字节 英文是一个字节 欧洲的是 2个字节 gbk 国内版本 一个中文字符==2个字节 英文是一个字节 gbk 转 utf-8 需通过媒介 unicode
14、字节码和机器码的区别?
机器码,学名机器语言指令,有时也被称为原生码,是电脑的CPU可直接解读的数据。
字节码是一种中间状态(中间码)的二进制代码(文件)。需要直译器转译后才能成为机器码。
#is 比较的是内存地址 #== 比较的是值 # int 具有范围:-5---256 #对于int 小数据池 范围:-5----256 创建的相间的数字,都指向同一个内存地址 #对于字符串 (面试) 1、小数据池 如果有空格,那指向两个内存地址, 2、长度不能超过 20 3、不能用特殊字符
15、三元运算规则以及应用场景?
# 三元运算符就是在赋值变量的时候,可以直接加判断,然后赋值 a = 1 b = 2 c = a if a > 1 else b # 如果a大于1的话,c=a,否则c=b
16、列举 Python2和Python3的区别?
字符编码
py2: unicode ->压缩(utf8) str=bytes
name = u'alex' name = 'alex'
type(name) type(name)
py3: str ->压缩(utf8) bytes
name = "alex" name = b'alex'
type(name) type(name)
'Print': py2--print; py3--print()函数 '编码': py2默认是ascii码; py3默认是utf-8 '字符串': py2中分ascii(8位)、unicode(16位); py3中所有字符串都是unicode字符串 'True和False': py2中是两个全局变量(1和0)可以重新赋值; py3中为两个关键字,不可重新赋值 '迭代': python2里,有两种方法获得一定范围内的数字:range(),返回一个列表,还有xrange(),返回一个迭代器。
python3 里,range()返回迭代器,xrange()不再存在。 'Nonlocal': py3专有的(声明为非局部变量) '经典类&新式类': py2:经典类和新式类并存; py3:新式类都默认继承object 'yield': py2:yield py3:yield/yield from '文件操作': py2:readliens()读取文件的所有行,返回一个列表,包含所有行的结束符 xreadliens()返回一个生成器,循环取值 py3: 只有readlines()
input不同 python2 :raw_input python3 :input 统一使用input函数
7:在包的知识点里 包:一群模块文件的集合 + __init__ 区别:py2 : 必须有__init__ py3:不是必须的了
8:不相等操作符"<>"被Python3废弃,统一使用"!=" 9:long整数类型被Python3废弃,统一使用int 10:迭代器iterator的next()函数被Python3废弃,统一使用next(iterator) 11:异常StandardError 被Python3废弃,统一使用Exception 12:字典变量的has_key函数被Python废弃,统一使用in关键词 13:file函数被Python3废弃,统一使用open来处理文件,可以通过io.IOBase检查文件类型
字典类方法HAS_KEY()
Python2中,字典对象has_key()方法测试字典是否包含指定的键。python3不再支持这个方法,需要使用in.
全局函数FILTER()
在python2里,filter()方法返回一个列表,这个列表是通过一个返回值为True或False的函数来检测序列里的每一项的道德。在python3中,filter()函数返回一个迭代器,不再是列表
MAP()
跟filter()的改变一样,map()函数现在返回一个迭代器,python2中返回一个列表。
APPLY()
python2有一个叫做apply()的全局函数,它使用一个函数f和一个列表[a,b,c]作为参数,返回值是f(a,b,c).可以直接调用这个函数,在列表前添加一个星号作为参数传递给它来完成同样的事情。在python3里记,apply()函数不再存在;必须使用星号标。
EXEC
就像print语句在python3里变成了一个函数一样,exec语句也是这样的。exec()函数使用一个包含任意python代码的字符串作为参数,然后像执行语句或表达式一样执行它。exec()跟eval()是相似,但exec()更加强大并具有挑战性。eval()函数只能执行单独一条表达式,但是exec()能够执行多条语句,导入(import), 函数声明-实际上整个python程序的字符串表示也可以
execfile
python2中的execfile语句可以像执行python代码那样使用字符串。不同的是exec使用字符串,而execfile使用文件。在python3,execfile语句被去掉了
python2中,文件对象有一个xreadlines()方法,返回一个迭代器,一次读取文件的一行。这在for循环中尤其实用。python3中,xreadlines()方法不再可用。
python2,如果需要编写一个遍历元组的列表解析,不需要在元组值周围加上括号。在python3里,这些括号是必需的。
在python2里,可以通过在类的声明中定义metaclass参数,或者定义一个特殊的类级别(class-level)__metaclass__属性,来创建元类。python3中,__metaclass__属性被取消了
17、用一行代码实现数值交换:
a = 1 b = 2 ########### a, b = b, a print(a, b)
18、Python3和Python2中 int 和 long的区别?
py3中没有long整型,统一使用int,大小和py2的long类似。
py2中int最大不能超过sys.maxint,根据不同平台大小不同;
在int类型数字后加L定义成长整型,范围比int更大。
19、xrange和range的区别?
python2里,有两种方法获得一定范围内的数字:range(),返回一个列表,还有xrange(),返回一个迭代器。
python3 里,range()返回迭代器,xrange()不再存在。
20、文件操作时:xreadlines和readlines的区别?
# Readlines:读取文件的所有行,返回一个列表,包含所有行的结束符 # Xreadlines:返回一个生成器,循环使用和readlines基本一致 。(py2有,py3没有)
21、列举布尔值为False的常见值?
# []、{}、None、’’、()、0、False
22、字符串、列表、元组、字典每个常用的5个方法?
#Str: Split:分割 Strip:去掉两边的空格 Startwith:以什么开头 Endwith:以什么结尾 Lower:小写 Upper:大写 find通过元素找索引,可切片,找不到返回-1 index,找不到报错。 title,每个单词的首字母大写。 format格式化输出 #format的三种玩法 格式化输出 res='{} {} {}'.format('egon',18,'male') ==> egon 18 male res='{1} {0} {1}'.format('egon',18,'male') ==> 18 egon 18 res='{name} {age} {sex}'.format(sex='male',name='egon',age=18) count查找元素的个数,可以切片,若没有返回0 replace(old,new,次数) swapcase 大小写翻转 #List: Append:追加 Insert:按照索引添加, Reverse:反转 Index:索引 Copy:拷贝 Pop:删除指定索引处的值,不指定索引默认删除最后一个。 expend:迭代着添加。 list.extend(seq) - 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) clear 清空列表 del 1、可以按照索引去删除 2、切片 3、步长(隔着删) remove 可以按照元素去删 注意:List中的元素是可以改变的。 #Tuple: Count:查看某个元素出现的次数 Index:索引 1、cmp(tuple1, tuple2):比较两个元组元素。 2、len(tuple):计算元组元素个数。 3、max(tuple):返回元组中元素最大值。 4、min(tuple):返回元组中元素最小值。 5、tuple(seq):将列表转换为元组。 注意 1、与字符串一样,元组的元素不能修改。 2、元组也可以被索引和切片,方法一样。 3、注意构造包含0或1个元素的元组的特殊语法规则。 4、元组也可以使用+操作符进行拼接。 #Dict: #字典的键必须是可哈希的 不可变类型。 #在同一个字典中,键(key)必须是唯一的。 Get:根据key取value Items:用于循环,取出所有key和value Keys:取出所有key Values:取出所有的value Clear:清空字典 Pop:删除指定键对应的值,有返回值; Set(集合) :集合(set)是一个无序不重复元素的序列。 可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
23、lambda表达式格式以及应用场景?
匿名函数:为了解决那些功能很简单的需求而设计的一句话函数 函数名 = lambda 参数 :返回值 #参数可以有多个,用逗号隔开 #匿名函数不管逻辑多复杂,只能写一行,且逻辑执行结束后的内容就是返回值 #返回值和正常的函数一样可以是任意数据类型 lambda 表达式 temp = lambda x,y:x+y print(temp(4,10)) # 14 可替代: def foo(x,y): return x+y print(foo(4,10)) # 14
24、pass的作用?
# Pass一般用于站位语句,保持代码的完整性,不会做任何操作。
25、*arg和**kwarg作用
# 他们是一种动态传参,一般不确定需要传入几个参数时,可以使用其定义参数,然后从中取参 '*args':按照位置传参,将传入参数打包成一个‘元组’(打印参数为元组-- tuple) '**kwargs':按照关键字传参,将传入参数打包成一个‘字典’(打印参数为字典-- dict)
def exmaple2(required_arg, *arg, **kwarg): if arg: print "arg: ", arg if kwarg: print "kwarg: ", kwarg exmaple2("Hi", 1, 2, 3, keyword1 = "bar", keyword2 = "foo") >> arg: (1, 2, 3) >> kwarg: {'keyword2': 'foo', 'keyword1': 'bar'}
def sum(a, b, c): return a + b + c a = [1, 2, 3] # the * unpack list a print sum(*a) >> 6
26、is和==的区别
==:判断某些值是否一样,比较的是值 is:比较的是内存地址(引用的内存地址不一样,唯一标识:id)
27、简述Python的深浅拷贝以及应用场景?
#浅拷贝: 不管多么复杂的数据结构,只copy对象最外层本身,并且在其他内存中重新创建了数据,第二层数据与源数据共享内存。 #深拷贝: 完全复制原变量的所有数据,内存中生成一套完全一样的内容;只是值一样,内存地址不一样,一方修改另一方不受影响
# 完全独立的copy一份数据,与原数据没有关系,深copy
# 如果一份数据(列表)第二层时,你想与原数据进行公用,浅copy。
一层的情况:
import copy # 浅拷贝 li1 = [1, 2, 3] li2 = li1.copy() li1.append(4) print(li1, li2) # [1, 2, 3, 4] [1, 2, 3] # 深拷贝 li1 = [1, 2, 3] li2 = copy.deepcopy(li1) li1.append(4) print(li1, li2) # [1, 2, 3, 4] [1, 2, 3]
# 切片属于浅copy
l1 = [1,2,3,[22,33]]
l2 = l1[:]
# print(id(l1),id(l2))
# l1.append(666)
l1[-1].append(666)
print(l1,id(l1))
print(l2,id(l2))
应用场景:
在django开发的crm中,例如分页之后,选择数据进行编辑,编辑保存之后,需要跳转回原页面。
本质:request.GET 进行拷贝,不影响后续其他组件使用request.GET
28、Python垃圾回收机制?


# Python垃圾回收机制 Python垃圾回收机制,主要使用'引用计数'来跟踪和回收垃圾。 在'引用计数'的基础上,通过'标记-清除'(mark and sweep)解决容器对象可能产生的循环引用问题. 通过'分代回收'以空间换时间的方法提高垃圾回收效率。 '引用计数' PyObject是每个对象必有的内容,其中ob_refcnt就是做为引用计数。 当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除, 它的ob_refcnt就会减少.引用计数为0时,该对象生命就结束了。 \优点:1.简单 2.实时性 \缺点:1.维护引用计数消耗资源 2.循环引用 '标记-清楚机制' 基本思路是先按需分配,等到没有空闲内存的时候从寄存器和程序栈上的引用出发, 遍历以对象为节点、以引用为边构成的图,把所有可以访问到的对象打上标记, 然后清扫一遍内存空间,把所有没标记的对象释放。 '分代技术' 分代回收的整体思想是: 将系统中的所有内存块根据其存活时间划分为不同的集合,每个集合就成为一个“代”, 垃圾收集频率随着“代”的存活时间的增大而减小,存活时间通常利用经过几次垃圾回收来度量。
29、Python的可变类型和不可变类型?
# 可变类型:列表、字典、集合 # 不可变类型:数字、字符串、元祖 (可变与否指内存中那块内容value)
30、求结果:
v = dict.fromkeys(['k1', 'k2'], []) # 内存中k1和k2都指向同一个[](内存地址相同),只要指向的[]发生变化,k1和k2都要改变(保持一致) v['k1'].append(666) print(v) # {'k1': [666], 'k2': [666]} v['k1'] = 777 print(v) # {'k1': 777, 'k2': [666]}
31、求结果: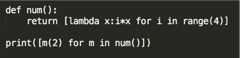
def num(): return [lambda x: i * x for i in range(4)] #返回一个列表,里面是四个函数对象 i=3 print([m(2) for m in num()])# 6 6 6 6
等同于:
def num1():
li =[]
for i in range(4):
def func(x):
return i*x
li.append(func)
return li
print([i(2) for i in num1()])
i就是在闭包作用域(enclousing),而Python的闭包是 迟绑定 , 这意味着闭包中用到的变量的值,是在内部函数被调用时查询得到的
32、列举常见的内置函数?
abs() 返回数字的绝对值 map 根据函数对指定序列做映射 map()函数接收两个参数,一个是函数,一个是可迭代对象,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回。 返回值: Python2 返回列表 Python3 返回迭代器 例子1: def mul(x): return x*x n=[1,2,3,4,5] res=list(map(mul,n)) print(res) #[1, 4, 9, 16, 25] 例子2:abs() 返回数字的绝对值 ret = map(abs,[-1,-5,6,-7]) print(list(ret)) # [1, 5, 6, 7] filter filter()函数接收一个函数 f(函数)和一个list(可迭代对象),这个函数 f的作用是对每个元素进行判断,返回 True或 False, filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list。 def is_odd(x): return x % 2 == 1 v=list(filter(is_odd, [1, 4, 6, 7, 9, 12, 17])) print(v) #[1, 7, 9, 17] map与filter总结 # filter 与 map 总结 # 参数: 都是一个函数名 + 可迭代对象 # 返回值: 都是返回可迭代对象 # 区别: # filter 是做筛选的,结果还是原来就在可迭代对象中的项 # map 是对可迭代对象中每一项做操作的,结果不一定是原来就在可迭代对象中的项 isinstance\type isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。 isinstance() 与 type() 区别: type() 不会认为子类是一种父类类型,不考虑继承关系。 isinstance() 会认为子类是一种父类类型,考虑继承关系。 如果要判断两个类型是否相同推荐使用 isinstance()。 # 例一 a = 2 print(isinstance(a,int)) # True print(isinstance(a,str)) # False # type() 与 isinstance() 区别 class A: pass class B(A): pass print("isinstance",isinstance(A(),A)) # isinstance True print("type",type(A()) == A) # type True print('isinstance',isinstance(B(),A) ) # isinstance True print('type',type(B()) == A) # type False zip 拉链函数 # zip 拉链函数, # 将对象中对应的元素打包成一个个元组, # 然后返回由这些元组组成的列表迭代器。 # 如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同。 print(list(zip([0,1,3],[5,6,7],['a','b']))) # [(0, 5, 'a'), (1, 6, 'b')] zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。 >>>a = [1,2,3] >>> b = [4,5,6] >>> c = [4,5,6,7,8] >>> zipped = zip(a,b) # 打包为元组的列表 [(1, 4), (2, 5), (3, 6)] >>> zip(a,c) # 元素个数与最短的列表一致 [(1, 4), (2, 5), (3, 6)] >>> zip(*zipped) # 与 zip 相反,可理解为解压,返回二维矩阵式 [(1, 2, 3), (4, 5, 6)] reduce ''' reduce() 函数 reduce() 函数会对参数序列中元素进行累积 函数将一个数据集合(链表、元组等)中的所有数据进行下列操作 ''' 注意: Python3已经将reduce() 函数从全局名字空间里移除了,它现在被放置在 fucntools 模块里,如果想要使用它,则需要通过引入 functools 模块来调用 reduce() 函数: from functools import reduce def add(x,y): return x + y print(reduce(add,[1,2,3,4,5])) # 15 print(reduce(lambda x, y: x+y, [1,2,3,4,5])) # 15 print(reduce(add,range(1,101))) # 5050
33、filter、map、reduce的作用?
# map:遍历序列,为每一个序列进行操作,获取一个新的序列 # reduce:对于序列里面的所有内容进行累计操作 # filter:对序列里面的元素进行筛选,最终获取符合条件的序列。
34、一行代码实现9*9乘法表
print('\n'.join([' '.join(['%s*%s=%2s' % (j, i, i * j) for j in range(1, i + 1)]) for i in range(1, 10)]))
35、如何安装第三方模块?以及用过哪些第三方模块?
# a、可以在pycharm的settings里面手动下载添加第三方模块 # b、可以在cmd终端下用pip insatll 安装 # 用过的第三方模块:
requests
bs4
sqlalchemy
mysql
redis
常见内置模块
json
time
datetime
re
os/sys
logging
36、至少列举8个常用模块都有那些?
re:正则
os:提供了一种方便的使用操作系统函数的方法。
sys:可供访问由解释器使用或维护的变量和与解释器进行交互的函数。
random:随机数
json:序列化
time:时间
37、re的match和search区别?
# match:从字符串起始位置开始匹配,如果没有就返回None # serch:从字符串的起始位置开始匹配,匹配到第一个符合的就不会再去匹配了
38、什么是正则的贪婪匹配?
# 匹配一个字符串没有节制,能匹配多少就匹配多少,直到匹配完为止
39、求结果: a. [ i % 2 for i in range(10) ] b. ( i % 2 for i in range(10) )
# a结果是一个列表生成式,结果是一个列表(i % 2为生成的元素): [0, 1, 0, 1, 0, 1, 0, 1, 0, 1] # b结果是一个生成器
# <generator object <genexpr> at 0x00000000020CEEB8> 生成器 # 在Python中,有一种自定义迭代器的方式,称为生成器(Generator)。 # 定义生成器的两种方式: # 1.创建一个generator,只要把一个列表生成式的[]改成(),就创建了一个generator: # generator保存的是算法,每次调用next(),就计算出下一个元素的值,直到计算到最后一个元素,
没有更多的元素时,抛出StopIteration的错误。 # 2.定义generator的另一种方法。如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,
而是一个generator
40、求结果: a. 1 or 2 b. 1 and 2 c. 1 < (2==2) d. 1 < 2 == 2
a=1 or 2 #1 b=1 and 2 #2 c=1 < (2==2) #False
2==2==true==1
d=1 < 2 == 2 #True
41、def func(a,b=[]) 这种写法有什么坑?
# 函数传参为列表陷阱,列表是可变数据类型,可能会在过程中修改里面的值
def func(a,b = []):
b.append(1)
print(a,b)
func(a=2)
func(2)
func(2)
'''
[1]
[1, 1]
[1, 1, 1]
函数的默认参数是一个list 当第一次执行的时候实例化了一个list
第二次执行还是用第一次执行的时候实例化的地址存储
所以三次执行的结果就是 [1, 1, 1] 想每次执行只输出[1] ,默认参数应该设置为None
'''
42、如何实现 “1,2,3” 变成 [‘1’,’2’,’3’] ?
a = '1,2,3' a=a.replace(',','') res = [i for i in a] print(res)
43、如何实现[‘1’,’2’,’3’]变成[1,2,3] ?
l = ['1','2','3'] res = [int(i) for i in l] print(res)
44、比较: a = [1,2,3] 和 b = [(1),(2),(3) ] 以及 b = [(1,),(2,),(3,) ] 的区别?
前两个列表内是int
最后一个列表内是元组
45、如何用一行代码生成[1,4,9,16,25,36,49,64,81,100] ?
l = [i*i for i in range(1,11)] print(l)
# 一个列表A=[2,3,4],Python如何将其转换成B=[(2,3),(3,4),(4,2)]? # B = zip(A, A[1:]+A[:1])
46、一行代码实现删除列表中重复的值 ?
l = [1,1,1,2,2,3,3,3,4,4] print(list(set(l))) # [1, 2, 3, 4]
47、如何在函数中设置一个全局变量 ?
通过global指定变量,该变量会变成全局变量
x = 2
def func():
global x
x = 1
return x
func()
print(x) # 1
48、logging模块的作用?以及应用场景?
# 作用: 管理我们程序的执行日志,省去用print记录操作日志的操作,并且可以将标准输入输出保存到日志文件 # 场景: 爬虫爬取数据时,对爬取进行日志记录,方便分析、排错。
49、请用代码简单实现stack 。
class Stack(object): # 初始化栈 def __init__(self): self.items = [] # 判断栈是否为空 def is_empty(self): return self.items == [] # 返回栈顶 def peek(self): return self.items[len(self.items) - 1] # 返回栈大小 def size(self): return len(self.items) # 压栈 def push(self, item): self.items.append(item) # 出栈 def pop(self): return self.items.pop()
50、常用字符串格式化哪几种?
#
1.占位符%
%d 表示那个位置是整数;%f 表示浮点数;%s 表示字符串。
print('Hello,%s' % 'Python')
print('Hello,%d%s%.2f' % (666, 'Python', 9.99)) # 打印:Hello,666Python10.00
# format格式化输出 i = "i am {}".format('zhugaochao') print(i) #i am zhugaochao
51、简述 生成器、迭代器、可迭代对象 以及应用场景?
# 装饰器: 能够在不修改原函数代码的基础上,在执行前后进行定制操作,闭包函数的一种应用 场景: - flask路由系统 - flask before_request - csrf - django内置认证 - django缓存 # 手写装饰器; import functools def wrapper(func): @functools.wraps(func) #不改变原函数属性 def inner(*args, **kwargs): 执行函数前 return func(*args, **kwargs) 执行函数后 return inner 1. 执行wapper函数,并将被装饰的函数当做参数。 wapper(index) 2. 将第一步的返回值,重新赋值给 新index = wapper(老index) @wrapper #index=wrapper(index) def index(x): return x+100 # --------------------------------------------------------------- # 生成器: 一个函数内部存在yield关键字 应用场景: - rang/xrange - redis获取值 - conn = Redis(......) - v=conn.hscan_iter() # 内部通过yield 来返回值 - stark组件中 - 前端调用后端的yield # --------------------------------------------------------------- # 迭代器: 内部有__next__和__iter__方法的对象,帮助我们向后一个一个取值,迭代器不一定是生成器 应用场景: - wtforms里面对form对象进行循环时,显示form中包含的所有字段 - 列表、字典、元组 (可以让一个对象被for循环)
52、用Python实现一个二分查找的函数。
li = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] def search(someone, li): l = -1 h = len(li) while l + 1 != h: m = int((l + h) / 2) if li[m] < someone: l = m else: h = m p = h if p >= len(li) or li[p] != someone: print("元素不存在") else: str = "元素索引为%d" % p print(str) search(3, li) # 元素索引为2
53、谈谈你对闭包的理解?
# 内部函数包含对外部作用域而非全剧作用域变量的引用,该内部函数称为闭包函数,并且外函数的返回值是内函数的引用,常用于装饰器。 # 判断闭包函数的方法:__closure__,输出的__closure__有cell元素说明是闭包函数 # 闭包的意义与应用:延迟计算:
def outer(a):
b = 10 # a和b都是闭包变量
c = [a] # 这里对应修改闭包变量的方法2
# inner是内函数
def inner():
# 内函数中想修改闭包变量
# 方法1 nonlocal关键字声明
nonlocal b
b += 1
# 方法二,把闭包变量修改成可变数据类型 比如列表
c[0] += 1
print(c[0])
print(b)
# 外函数的返回值是内函数的引用
return inner
if __name__ == '__main__':
demo = outer(5)
demo() # 6 11
54、os和sys模块的作用?
# os模块负责程序与操作系统的交互,提供了访问操作系统底层的接口; # sys模块负责程序与python解释器的交互,提供了一系列的函数和变量,用于操控python运行环境
def add_b():
b = 42
def do_global():
b = 10
print(b)
def dd_nonlocal():
nonlocal b
b = b + 20
print(b)
dd_nonlocal()
print(b)
do_global()
print(b)
add_b()
nonlocal关键字举例
55、如何生成一个随机数?
import random print(random.random()) print(random.randint(1, 10))
56、如何使用python删除一个文件?
import os os.remove('文件名以及路径')
57、谈谈你对面向对象的理解?
#封装: 其实就是将很多数据封装到一个对象中,类似于把很多东西放到一个箱子中, 如:一个函数如果好多参数,起始就可以把参数封装到一个对象再传递。 #继承: 如果多个类中都有共同的方法,那么为了避免反复编写,就可以将方法提取到基类中实现, 让所有派生类去继承即可。 #多态: 指基类的同一个方法在不同派生类中有着不同功能。python天生支持多态。
# 4. 鸭子模型
# python
"""
def func(arg):
arg.send() # arg可以是任意对象,必须有send方法
"""
58、Python面向对象中的继承有什么特点?
#Python3的继承机制 # 子类在调用某个方法或变量的时候,首先在自己内部查找,如果没有找到,则开始根据继承机制在父类里查找。 # 根据父类定义中的顺序,以深度优先的方式逐一查找父类! 继承参数的书写有先后顺序,写在前面的被优先继承。
59、面向对象深度优先和广度优先是什么?
# Python的类可以继承多个类,Python的类如果继承了多个类,那么其寻找方法的方式有两种 当类是经典类时,多继承情况下,会按照深度优先方式查找 当类是新式类时,多继承情况下,会按照广度优先方式查找 简单点说就是:经典类是纵向查找,新式类是横向查找 经典类和新式类的区别就是,在声明类的时候,新式类需要加上object关键字。在python3中默认全是新式类
60、面向对象中super的作用?
主要在子类根据mro的顺序执行相关的方法
61、是否使用过functools中的函数?其作用是什么?
在装饰器中,会用到;functools.wraps()主要在装饰器中用来装饰函数 Stark上下文管理源码中,走到视图阶段时有用到functools中的偏函数,request = LocalProxy(partial(_lookup_req_object, 'request'))
62、列举面向对象中带爽下划线的特殊方法,如:__new__、__init__
# __getattr__ CBV django配置文件 wtforms中的Form()示例化中 将"_fields中的数据封装到From类中" # __mro__ wtform中 FormMeta中继承类的优先级 # __dict__ 是用来存储对象属性的一个字典,其键为属性名,值为属性的值 # __new__ 实例化但是没有给当前对象 wtforms,字段实例化时返回:不是StringField,而是UnboundField est frawork many=Turn 中的序列化 # __call__ flask 请求的入口app.run() 字段生成标签时:字段.__str__ => 字段.__call__ => 插件.__call__ # __iter__ 循环对象是,自定义__iter__ wtforms中BaseForm中循环所有字段时定义了__iter__ # -metaclass 作用:用于指定当前类使用哪个类来创建 场景:在类创建之前定制操作 示例:wtforms中,对字段进行排序。
__getitem__
__setitem__
__delitem__
class Session(object):
def __setitem__(self, key, value):
print(key,value)
def __getitem__(self, item):
return 1
def __delitem__(self, key):
pass
obj = Session()
obj['x1'] = 123
obj['x1']
del obj['x1']
__iter__
__enter__
__exit__
63、如何判断是函数还是方法
# 看他的调用者是谁,如果是类,需要传入参数self,这时就是一个函数; # 如果调用者是对象,不需要传入参数值self,这时是一个方法。 (FunctionType/MethodType)
64、静态方法和类方法区别?
Classmethod必须有一个指向类对象的引用作为第一个参数; @classmethod def class_func(cls): """ 定义类方法,至少有一个cls参数 """ print('类方法') --------------------------------------------------------- Staticmethod可以没有任何参数。 @staticmethod def static_func(): """ 定义静态方法 ,无默认参数""" print('静态方法')
65、列举面向对象中的特殊成员以及应用场景
1. __doc__:表示类的描述信息。 2.__module__:表示当前操作的对象在那个模块; 3.__class__:表示当前操作的对象的类是什么。 4.__init__:构造方法,通过类创建对象时,自动触发执行。 5.__call__:对象后面加括号,触发执行。 6.__dict__:类或对象中的所有成员。 7.__str__:如果一个类中定义了__str__方法,那么在打印对象时,默认输出该方法的返回值。 class Foo: def __str__(self): return 'aaa' obj = Foo() print(obj) # 输出:aaa 8.__getitem__、__setitem__、__delitem__:用于索引操作,如字典。以上分别表示获取、设置、删除数据。 9.__iter__:用于迭代器,之所以列表、字典、元组可以进行for循环,是因为类型内部定义了 __iter__。
66、1、2、3、4、5 能组成多少个互不相同且无重复的三位数
import itertools print(len(list(itertools.permutations('12345',3)))) #60个
67、什么是反射?以及应用场景?
反射就是以字符串的方式导入模块,以字符串的方式执行函数 # 应用场景: rest framework里面的CBV
django的中间件的加载 等其他配置均使用了反射。
68、metaclass作用?以及应用场景?
类的metaclass
默认是type。我们也可以指定类的metaclass值。
参考:点击查看
69、用尽量多的方法实现单例模式。
# 单例模式 '''单例模式是一种常用的软件设计模式。在它的核心结构中只包含一个被称为单例类的特殊类。 通过单例模式可以保证系统中一个类只有一个实例而且该实例易于外界访问,从而方便对实例个数的控制并节约系统资源。 如果希望在系统中某个类的对象只能存在一个,单例模式是最好的解决方案。''' # 1、使用__new__方法 class Singleton(object): def __new__(cls, *args, **kw): if not hasattr(cls, '_instance'): orig = super(Singleton, cls) cls._instance = orig.__new__(cls, *args, **kw) return cls._instance class MyClass(Singleton): a = 1 # 2、共享属性 # 创建实例时把所有实例的__dict__指向同一个字典,这样它们具有相同的属性和方法. class Borg(object): _state = {} def __new__(cls, *args, **kw): ob = super(Borg, cls).__new__(cls, *args, **kw) ob.__dict__ = cls._state return ob class MyClass2(Borg): a = 1 # 3、装饰器版本 def singleton(cls, *args, **kw): instances = {} def getinstance(): if cls not in instances: instances[cls] = cls(*args, **kw) return instances[cls] return getinstance @singleton class MyClass: ... # 4、import方法 # 作为python的模块是天然的单例模式 # mysingleton.py class My_Singleton(object): def foo(self): pass my_singleton = My_Singleton() # to use from mysingleton import my_singleton my_singleton.foo()
# 11. 手写单例模式(标准无bug,加锁版本) import time import threading class Singleton(object): lock = threading.RLock() instance = None def __new__(cls, *args, **kwargs): if cls.instance: return cls.instance with cls.lock: if not cls.instance: cls.instance = super().__new__(cls) return cls.instance def task(arg): obj = Singleton() print(obj) for i in range(10): t = threading.Thread(target=task,args=(i,)) t.start() time.sleep(100) obj = Singleton()
70、装饰器的写法以及应用场景。
import functools def wrapper(func): @functools.wraps(func) def inner(*args, **kwargs): print('我是装饰器') return func return inner @wrapper def index(): print('我是被装饰函数') return None index() # 应用场景
flask框架路由
django的csrf
django的缓存
django的auth
- 装饰器 - functools.wraps(func)
# 示例二:写装饰器,重复执行n次
import functools
def couter(times):
def wapper(func):
@functools.wraps(func)
def inner(*args, **kwargs):
for i in range(times):
result = func(*args, **kwargs)
return result
return inner
return wapper
@couter(5)
def f1():
print('f1函数')
f1()
71、异常处理写法以及如何主动抛出异常(应用场景)
while True: try: x = int(input("Please enter a number: ")) break except ValueError: print("Oops! That was no valid number. Try again ") # raise主动抛出一个异常 参考:点击查看
72、什么是面向对象的mro
MRO:方法解析顺序
它定义了 Python 中多继承存在的情况下,解释器查找继承关系的具体顺序
73、isinstance作用以及应用场景?
# 来判断一个对象是否是一个已知的类型。 # 使用isinstance函数还可以来判断'类实例变量'属于哪一个类产生的。
74、写代码并实现:
Given an array of integers, return indices of the two numbers such that they add up to a specific target.You may assume that each input would have exactly one solution, and you may not use the same element twice.Example: Given nums = [2, 7, 11, 15], target = 9, Because nums[0] + nums[1] = 2 + 7 = 9, return [0, 1]
'''Given an array of integers, return indices of the two numbers such that they add up to a specific target.You may assume that each input would have exactly one solution, and you may not use the same element twice. Example: Given nums = [2, 7, 11, 15], target = 9, Because nums[0] + nums[1] = 2 + 7 = 9, return [0, 1]''' class Solution: def twoSum(self, nums, target): """ :type nums: List[int] :type target: int :rtype: List[int] """ # 用len()方法取得nums列表长度 n = len(nums) # x从0到n取值(不包括n) for x in range(n): a = target - nums[x] # 用in关键字查询nums列表中是否有a if a in nums: # 用index函数取得a的值在nums列表中的索引 y = nums.index(a) # 假如x=y,那么就跳过,否则返回x,y if x == y: continue else: return x, y break else: continue
75、json序列化时,可以处理的数据类型有哪些?如何定制支持datetime类型?
# 可序列化数据类型: 字典、列表、数字、字符串、元组;如果是元组,自动转成列表(再转回去的话也是列表) # 自定义时间序列化转换器 import json from json import JSONEncoder from datetime import datetime class ComplexEncoder(JSONEncoder): def default(self, obj): if isinstance(obj, datetime): return obj.strftime('%Y-%m-%d %H:%M:%S') else: return super(ComplexEncoder,self).default(obj) d = { 'name':'alex','data':datetime.now()} print(json.dumps(d,cls=ComplexEncoder)) # {"name": "alex", "data": "2018-05-18 19:52:05"}
76、json序列化时,默认遇到中文会转换成unicode,如果想要保留中文怎么办?
import json a=json.dumps({"xxx":"你好"},ensure_ascii=False) print(a) #{"xxx": "你好"}
77、什么是断言?应用场景?
#条件成立则继续往下,否则抛出异常; #一般用于:满足某个条件之后,才能执行,否则应该抛出异常。 '应用场景':rest framework中GenericAPIView类里,要设置queryset,否则断言错误
78、有用过with statement吗?它的好处是什么?
with语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,
释放资源,比如文件使用后自动关闭、线程中锁的自动获取和释放等。
79、使用代码实现查看列举目录下的所有文件。
import os path = os.listdir('.') #查看列举目录下的所有文件。 # path = os.listdir(os.getcwd()) print(path)
80、简述 yield和yield from关键字。
1、yield使用 1)函数中使用yield,可以使函数变成生成器。一个函数如果是生成一个数组,就必须把数据存储在内存中,如果使用生成器,则在调用的时候才生成数据,可以节省内存。 2)生成器方法调用时,不会立即执行。需要调用next()或者使用for循环来执行。 2、yield from的使用 1)为了让生成器(带yield函数),能简易的在其他函数中直接调用,就产生了yield from。 参考:点击查看
第二部分 网络编程和并发(34题)
1、简述 OSI 七层协议。
物理层:主要基于电器特性发送高低电压(1、0),设备有集线器、中继器、双绞线等,单位:bit
数据链路层:定义了电信号的分组方式,设备:交换机、网卡、网桥,单位:帧
网络层:主要功能是将网络地址翻译成对应屋里地址,设备:路由
传输层:建立端口之间的通信,tcp、udp协议
会话层:建立客户端与服务端连接
表示层:对来自应用层的命令和数据进行解释,按照一定格式传给会话层。如编码、数据格式转换、加密解密、压缩解压
应用层:规定应用程序的数据格式
2、什么是C/S和B/S架构?
#C/S架构: client端与server端的服务架构 #B/S架构: 隶属于C/S架构,Broswer端(网页端)与server端; 优点:统一了所有应用的入口,方便、轻量级
3、简述 三次握手、四次挥手的流程。
三次握手: (1)第一次握手:Client向服务端发送一个请求建立连接的数据包,随机产生一个值,等待Server确认。
(2)第二次握手:Server收到数据包确认请求,随机产生一个值,并将该数据包发送给Client以确认连接请求。
(3)第三次握手:Client收到确认后,检测数据包,如果正确则连接建立成功,完成三次握手,随后Client与Server之间可以开始传输数据了。
四次挥手 ---> 断开连接
第一次挥手
客户端向服务端发起请求断开连接的请求
第二次挥手
服务端向客户端确认请求
第三次挥手
服务端向客户端发起断开连接请求
第四次挥手
客户端向服务端确认断开请求
断开连接是四次而发起连接是三次?
客户端和服务端的接收和发送数据都需要确认,所以是四次。
4、什么是arp协议?
#ARP(地址解析协议) 其主要用作将IP地址翻译为以太网的MAC地址 #在局域网中,网络中实际传输的是“帧”,帧里面是有目标主机的MAC地址的。 #在以太网中,一个主机要和另一个主机进行直接通信,必须要知道目标主机的MAC地址。 #所谓“地址解析”就是主机在发送帧前将目标IP地址转换成目标MAC地址的过程。 #ARP协议的基本功能就是通过目标设备的IP地址,查询目标设备的MAC地址,以保证通信的顺利进行。
5、TCP和UDP的区别?
#TCP协议:面向连接 - 通信之前先三次握手 - 断开之前先四次握手 - 必须先启动服务端,再启动客户端-->连接服务端 - 安全、可靠、面向连接(不会丢包) #UDP协议:无连接 - 传输速度快 - 先启动哪一端都可以 - 不面向连接,不能保证数据的完整性(如:QQ聊天)
6、什么是局域网和广域网?
局域网和广域网是按规模大小而划分的两种计算机网络。 #范围在几千米以内的计算机网络统称为局域网(LAN、私网、内网); #而连接的范围超过10千米的,则称为广域网,因特网(Intenet)就是目前最大的广域网(WAN、公网、外网)。
7、为何基于tcp协议的通信比基于udp协议的通信更可靠?
因为TCP是面向连接的
通信之前先三次握手,通过握手,确保连接成功之后再通信
断开之前先四次挥手;双方互相确认之后再断开连接,这样一来保证了数据的安全、可靠,避免丢包
8、什么是socket?简述基于tcp协议的套接字通信流程。
#服务端: 创建套接字 绑定IP和端口 监听 accept等待连接 通信(收recv、发send) #客户端: 创建套接字 绑定IP和端口 链接服务器 通信(收revc、发send)
9、什么是粘包? socket 中造成粘包的原因是什么? 哪些情况会发生粘包现象?
粘包:数据粘在一起,主要因为:接收方不知道消息之间的界限,不知道一次性提取多少字节的数据造成的
数据量比较小,时间间隔比较短,就合并成了一个包,这是底层的一个优化算法(Nagle算法)
什么情况会发生: 1、发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据了很小,会合到一起,产生粘包) 2、接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,
服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
10、IO多路复用的作用?
# IO多路复用分为时间上的复用和空间上的复用, # 空间上的复用是指将内存分为几部分,每一部分放一个程序,这样同一时间内存中就有多道程序; # 时间上的复用是指多个程序需要在一个cpu上运行,不同的程序轮流使用cpu, # 当某个程序运行的时间过长或者遇到I/O阻塞,操作系统会把cpu分配给下一个程序, # 保证cpu处于高使用率,实现伪并发。
11、什么是防火墙以及作用?
# 什么是防火墙? 防火墙是一个分离器,一个限制器,也是一个分析器, 有效地监控了内部网和Internet之间的任何活动,保证了内部网络的安全。 # 作用 防火墙可通过监测、限制、更改跨越防火墙的数据流, 尽可能地对外部屏蔽网络内部的信息、结构和运行状况,以此来实现网络的安全保护。
12、select、poll、epoll 模型的区别?
# select本质上是通过设置或者检查存放fd标志位的数据结构来进行下一步处理。这样所带来的缺点是: # 1.单个进程可监视的fd数量被限制 # 2.需要维护一个用来存放大量fd的数据结构 # 这样会使得用户空间和内核空间在传递该结构时复制开销大 # 3.对socket进行扫描时是线性扫描 # poll本质上和select没有区别,它将用户传入的数组拷贝到内核空间, # 它没有最大连接数的限制,原因是它是基于链表来存储的但是同样有一个缺点: # 大量的fd的数组被整体复制于用户态和内核地址空间之间,而不管这样的复制是不是有意义。 # epoll支持水平触发和边缘触发,最大的特点在于边缘触发, # 它只告诉进程哪些fd刚刚变为就需态,并且只会通知一次。
13、简述 进程、线程、协程的区别 以及应用场景?
# 进程 进程拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程由操作系统调度。 # 线程 线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程亦由操作系统调度 # 协程和线程的区别 协程避免了无意义的调度,由此可以提高性能;但同时协程也失去了线程使用多CPU的能力。
进程与线程的区别 (1)地址空间:线程是进程内的一个执行单位,进程内至少有一个线程,他们共享进程的地址空间,而进程有自己独立的地址空间 (2)资源拥有:进程是资源分配和拥有的单位,同一个进程内线程共享进程的资源 (3)线程是处理器调度的基本单位,但进程不是 (4)二者均可并发执行 (5)每个独立的线程有一个程序运行的入口 协程与线程 (1)一个线程可以有多个协程,一个进程也可以单独拥有多个协程,这样Python中则能使用多核CPU (2)线程进程都是同步机制,而协程是异步 (3)协程能保留上一次调用时的状态
14、GIL锁是什么鬼?
# GIL 线程全局锁(Global Interpreter Lock),即Python为了保证线程安全而采取的独立线程运行的限制,说白了就是一个核只能在同一时间运行一个线程. 对于io密集型任务,python的多线程起到作用,但对于cpu密集型任务, python的多线程几乎占不到任何优势,还有可能因为争夺资源而变慢。 解决办法就是多进程和下面的协程(协程也只是单CPU,但是能减小切换代价提升性能).
多线程用于IO密集型,如socket,爬虫,web 多进程用于计算密集型,如金融分析 1. 每个cpython进程内都有一个GIL 2. GIL导致同一进程内多个进程同一时间只能有一个运行 3. 之所以有GIL,是因为Cpython的内存管理不是线程安全的 4. 对于计算密集型用多进程,多IO密集型用多线程
15、Python中如何使用线程池和进程池?
进程池:就是在一个进程内控制一定个数的线程
基于concurent.future模块的进程池和线程池 (他们的同步执行和异步执行是一样的)
参考:点击查看
16、threading.local的作用?
a.threading.local 作用:为每个线程开辟一块空间进行数据存储。 问题:自己通过字典创建一个类似于threading.local的东西。 storage = { 4740: {val: 0}, 4732: {val: 1}, 4731: {val: 3}, } b.自定义Local对象 作用:为每个线程(协程) 开辟一块空间进行数据存储。 try: from greenlet import getcurrent as get_ident except Exception as e: from threading import get_ident from threading import Thread import time class Local(object): def __init__(self): object.__setattr__(self, 'storage', {}) def __setattr__(self, k, v): ident = get_ident() if ident in self.storage: self.storage[ident][k] = v else: self.storage[ident] = {k: v} def __getattr__(self, k): ident = get_ident() return self.storage[ident][k] obj = Local() def task(arg): obj.val = arg obj.xxx = arg print(obj.val) for i in range(10): t = Thread(target=task, args=(i,)) t.start()
17、进程之间如何进行通信?
# 进程间通讯有多种方式,包括信号,管道,消息队列,信号量,共享内存,socket等
18、什么是并发和并行?
# 并发:同一时刻只能处理一个任务,但一个时段内可以对多个任务进行交替处理(一个处理器同时处理多个任务) # 并行:同一时刻可以处理多个任务(多个处理器或者是多核的处理器同时处理多个不同的任务) # 类比:并发是一个人同时吃三个馒头,而并行是三个人同时吃三个馒头。
19、进程锁和线程锁的作用?
线程锁: 大家都不陌生,主要用来给方法、代码块加锁。当某个方法或者代码块使用锁时,那么在同一时刻至多仅有有一个线程在执行该段代码。当有多个线程访问同一对象的加锁方法 / 代码块时,同一时间只有一个线程在执行,其余线程必须要等待当前线程执行完之后才能执行该代码段。但是,其余线程是可以访问该对象中的非加锁代码块的。
进程锁: 也是为了控制同一操作系统中多个进程访问一个共享资源,只是因为程序的独立性,各个进程是无法控制其他进程对资源的访问的,但是可以使用本地系统的信号量控制(操作系统基本知识)。
分布式锁: 当多个进程不在同一个系统之中时,使用分布式锁控制多个进程对资源的访问。
参考:点击查看
20、解释什么是异步非阻塞?
'非阻塞': 遇到IO阻塞不等待(setblooking=False),(可能会报错->捕捉异常) - sk=socket.socket() - sk.setblooking(False) '异步': 回调(ajax),当达到某个指定状态之后,自动调用特定函数
21、路由器和交换机的区别?
'交换机' 用于在同一网络内数据快速传输转发,工作在数据链路层; 通过MAC寻址,不能动态划分子网; 只能在一条网络通路中运行,不能动态分配。 '路由器' 是一个网关设备,内部局域网到公网的一个关卡; 工作在网络层; 通过IP寻址,可以划分子网; 可以在多条网络通道中运行,可以动态分配IP地址。 '简单说' 交换机就是把一根网线变成多根网线; 路由器就是把一个网络变成多个网络; 如果不上外网,只是局域网,交换机即可; 如果上外网,并且给网络划分不同网段,就必须用路由器。
22、什么是域名解析?
# 在网上,所有的地址都是ip地址,但这些ip地址太难记了,所以就出现了域名(比如http://baidu.com)。 # 而域名解析就是将域名,转换为ip地址的这样一种行为。 # 例如:访问www.baidu.com,实质是把域名解析成IP。
23、如何修改本地hosts文件?
'hosts': Hosts就是将一些常用的网址域名与其对应的IP地址建立一个关联“数据库” 可以用来屏蔽一些网站,或者指定一些网站(修改hostsFQ) '修改': # windows: 位置:C:\Windows\System32\drivers\etc 也可以通过第三方软件,我用的火绒,可以直接进行编辑hosts # linux: 位置:/etc/hosts 修改:vi /etc/hosts
24、生产者消费者模型应用场景及优势?
# 处理数据比较消耗时间,线程独占,生产数据不需要即时的反馈等。
生产者与消费者模式是通过一个容器来解决生产者与消费者的强耦合关系,生产者与消费者之间不直接进行通讯,
而是利用阻塞队列来进行通讯,生产者生成数据后直接丢给阻塞队列,消费者需要数据则从阻塞队列获取,
实际应用中,生产者与消费者模式则主要解决生产者与消费者生产与消费的速率不一致的问题,达到平衡生产者与消费者的处理能力,而阻塞队列则相当于缓冲区。 应用场景:用户提交订单,订单进入引擎的阻塞队列中,由专门的线程从阻塞队列中获取数据并处理 优势: 1;解耦 假设生产者和消费者分别是两个类。如果让生产者直接调用消费者的某个方法,那么生产者对于消费者就会产生依赖(也就是耦合)。 将来如果消费者的代码发生变化,可能会影响到生产者。而如果两者都依赖于某个缓冲区,两者之间不直接依赖,耦合也就相应降低了。 2:支持并发 生产者直接调用消费者的某个方法,还有另一个弊端。由于函数调用是同步的(或者叫阻塞的),在消费者的方法没有返回之前,生产者只能一直等着 而使用这个模型,生产者把制造出来的数据只需要放在缓冲区即可,不需要等待消费者来取 3:支持忙闲不均 缓冲区还有另一个好处。如果制造数据的速度时快时慢,缓冲区的好处就体现出来了。 当数据制造快的时候,消费者来不及处理,未处理的数据可以暂时存在缓冲区中。等生产者的制造速度慢下来,消费者再慢慢处理掉。
25、什么是cdn?
# 用户获取数据时,不需要直接从源站获取,通过CDN对于数据的分发, # 用户可以从一个较优的服务器获取数据,从而达到快速访问,并减少源站负载压力的目的。
26、LVS是什么及作用?
# LVS即Linux虚拟服务器,是一个虚拟的四层交换器集群系统, # 根据目标地址和目标端口实现用户请求转发,本身不产生流量,只做用户请求转发。
27、Nginx是什么及作用?
28、keepalived是什么及作用?
Keepalived是Linux下一个轻量级别的高可用解决方案。
高可用,其实两种不同的含义:广义来讲,是指整个系统的高可用行,狭义的来讲就是之主机的冗余和接管,
参考:点击查看
29、haproxy是什么以及作用?
HAProxy提供高可用性、负载均衡以及基于TCP和HTTP应用的代 理,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。
HAProxy特别适用于那些负载特大的web站点,这些站点通常又需要会话保持或七层处理。HAProxy运行在当前的硬件上,
完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架中,
同时可以保护你的web服务器不被暴露到网络上。
参考:点击查看
30、什么是负载均衡?
负载均衡有两方面的含义: # 首先,大量的并发访问或数据流量分担到多台节点设备上分别处理,减少用户等待响应的时间; # 其次,单个重负载的运算分担到多台节点设备上做并行处理,每个节点设备处理结束后, 将结果汇总,返回给用户,系统处理能力得到大幅度提高。
31、什么是rpc及应用场景?
RPC 的全称是 Remote Procedure Call 是一种进程间通信方式。
它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。
即程序员无论是调用本地的还是远程的,本质上编写的调用代码基本相同
(例如QQ远程操作)
参考:点击查看
32、简述 asynio模块的作用和应用场景。
asyncio是Python 3.4版本引入的标准库,直接内置了对异步IO的支持。
asyncio的异步操作,需要在coroutine中通过yield from完成。
参考:点击查看
33、简述 gevent模块的作用和应用场景。
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,
在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。
Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
参考:点击查看
34、twisted框架的使用和应用?
Twisted是一个事件驱动型的网络模型。
时间驱动模型编程是一种范式,这里程序的执行流由外部决定。
特点是:包含一个事件循环,当外部事件发生时,使用回调机制来触发相应的处理。
参考:点击查看
第三部分 数据库和缓存(46题)
1、列举常见的关系型数据库和非关系型都有那些?
'关系型': # sqllite、db2、oracle、access、SQLserver、MySQL # 注意:sql语句通用,需要有表结构 '非关系型': # mongodb、redis、memcache # 非关系型数据库是key-value存储的,没有表结构。
2、MySQL常见数据库引擎及比较?
'Myisam': # 支持全文索引 # 查询速度相对较快 # 支持表锁 # 表锁:select * from tb for update;(锁:for update) 'InnoDB': # 支持事务 # 支持行锁、表锁 # 表锁:select * from tb for update;(锁:for update) # 行锁: select id ,name from tb where id=2 for update;(锁:for update)
3、简述数据三大范式?
# 数据库的三大特性: '实体':表 '属性':表中的数据(字段) '关系':表与表之间的关系 ---------------------------------------------------- # 数据库设计三大范式: '第一范式(1NF)' 数据表中的每一列(每个字段),必须是不可拆分的最小单元 也就是确保每一列的原子性。 '第二范式(2NF)' 满足第一范式后(1NF),要求表中的所有列,都必须依赖于主键, 而不能有任何一列 与主键没有关系,也就是说一个表只描述一件事。 '第三范式(3NF)' 必须先满足第二范式(2NF) 要求:表中每一列只与主键直接相关而不是间接相关(表中每一列只能依赖于主键)
4、什么是事务?MySQL如何支持事务?
'什么是事务' 事务由一个或多个sql语句组成一个整体; 在事务中的操作,要么都执行修改,要么都不执行, 只有在该事务中所有的语句都执行成功才会将修改加入到数据库中,否则回滚到上一步。
事务的特性: 原子性: 确保工作单元内的所有操作都成功完成,否则事务将被中止在故障点,和以前的操作将回滚到以前的状态。 一致性: 确保数据库正确地改变状态后,成功提交的事务。 隔离性: 使事务操作彼此独立的和透明的。 持久性: 确保提交的事务的结果或效果的系统出现故障的情况下仍然存在。
'Mysql实现事务' InnoDB支持事务,MyISAM不支持 # 启动事务: # start transaction; # update from account set money=money-100 where name='a'; # update from account set money=money+100 where name='b'; # commit; 'start transaction 手动开启事务,commit 手动关闭事务'
5、数据库五大约束
'数据库五大约束' 1.primary KEY:设置主键约束; 2.UNIQUE:设置唯一性约束,不能有重复值; 3.DEFAULT 默认值约束 4.NOT NULL:设置非空约束,该字段不能为空; 5.FOREIGN key :设置外键约束。
6、简述数据库设计中一对多和多对多的应用场景?
# 一对一关系示例: 一个学生对应一个学生档案材料,或者每个人都有唯一的身份证编号。 # 一对多关系示例:(下拉单选) 一个学生只属于一个班,但是一个班级有多名学生。 # 多对多关系示例:(下拉多选) 一个学生可以选择多门课,一门课也有多名学生。
7、如何基于数据库实现商城商品计数器?
参考:点击查看
8、常见SQL(必备)
详见:点击查看
9、简述触发器、函数、视图、存储过程?
'触发器': 对数据库某个表进行【增、删、改】前后,自定义的一些SQL操作 '函数': 在SQL语句中使用的函数 #例如:select sleep(2) 聚合函数:max、sam、min、avg 时间格式化:date_format 字符串拼接:concat 自定制函数:(触发函数通过 select) '视图': 对某些表进行SQL查询,将结果实时显示出来(是虚拟表),只能查询不能更新 '存储过程': 将提前定义好的SQL语句保存到数据库中并命名;以后在代码中调用时直接通过名称即可
参数类型: in 只将参数传进去 out 只拿结果 inout 既可以传,可以取
函数与存储过程区别: 本质上没区别。只是函数有如:只能返回一个变量的限制。而存储过程可以返回多个。而函数是可以嵌入在sql中使用的,可以在select中调用,而存储过程不行。
10、MySQL索引种类
'主键索引(单列)': primary key 加速查找+约束:不能重复、不能为空 '普通索引(单列)': 加速查找 '唯一索引(单列)': unique 加速查找+约束:不能重复 '联合索引(多列)': 查询时根据多列进行查询(最左前缀) '联合唯一索引(多列)': 遵循最左前缀规则(命中索引) # 其他词语 1、索引合并:利用多个单列索引查询 2、覆盖索引:在索引表中就能将想要的数据查询到
11、索引在什么情况下遵循最左前缀的规则?
你可以认为联合索引是闯关游戏的设计 例如你这个联合索引是state/city/zipCode 那么state就是第一关 city是第二关, zipCode就是第三关 你必须匹配了第一关,才能匹配第二关,匹配了第一关和第二关,才能匹配第三关 你不能直接到第二关的 索引的格式就是第一层是state,第二层才是city 参考:点击查看
12、主键和外键的区别?
'主键' 唯一标识一条记录 用来保证数据的完整性 主键只能有一个 '外键' 表的外键是另一个表的主键,外键可以有重复的,可以是空值 用来和其他表建立联系用的 一个表可以有多个外键 '索引' 该字段没有重复值,但可以有一个空值 提高查询速度 一个表可以有多个唯一索引
13、MySQL常见的函数?
'当前时间' select now(); '时间格式化' select DATE_FORMAT(NOW(), '%Y(年)-%m(月)-%d(日) %H(时):%i(分):%s(秒)') '日期加减' select DATE_ADD(DATE, INTERVAL expr unit) select DATE_ADD(NOW(), INTERVAL 1 DAY) #当前日期加一天 \expr:正数(加)、负数(减) \unit:支持毫秒microsecond、秒second、小时hour、天day、周week、年year '类型转换' cast( expr AS TYPE) select CAST(123 AS CHAR) '字符串拼接' concat(str1,str2,……) select concat('hello','2','world') --> hellow2world '聚合函数' avg() #平均值 count() #返回指定列/行的个数 min() #最小值 max() #最大值 sum() #求和 group_concat() #返回属于一组的列值,连接组合而成的结果 '数学函数' abs() #绝对值 bin() #二进制 rand() #随机数
14、列举 创建索引但是无法命中索引的8种情况。
#使用'like ‘%xx’' select * from tb1 where name like '%cn'; #使用'函数' select * from tb1 where reverse(name)='zgc'; #使用'or' select * from tb1 where nid=1 or email='zgc@gmial.com'; 特别的:当or条件中有未建立索引的列才失效,一下会走索引 # select * from tb1 where nid=1 or name='zgc'; # select * from tb1 where nid=1 or email='zgc@gmial.com' and name='zgc'; #'类型不一致' 如果列是字符串类型,传入条件是必须用引号引起来,不然则可能会无法命中 select * from tb1 where name=666; #含有'!= ' select * from tb1 where name != 'zgc'; 特别的:如果是主键,还是会走索引 # select * from tb1 where nid != 123; #含有'>' select * from tb1 where name > 'zgc'; 特别的:如果是主键或者索引是整数类型,则还是会走索引 # select * from tb1 where nid > 123; # select * from tb1 where name > 123; #含有'order by' select email from tb1 order by name desc; 当根据索引排序时,选择的映射如果不是索引,则不走索引 特别的:如果对主键排序,则还是走索引: # select * from tb1 order by nid desc; #组合索引最左前缀 如果组合索引为:(name,email) name and email #使用索引 name #使用索引 email #不使用索引
15、如何开启慢日志查询?
'可以通过修改配置文件开启' slow_query_log=ON #是否开启慢日志记录 long_query_time=2 #时间限制,超过此时间,则记录 slow_query_log_file=/usr/slow.log #日志文件 long_queries_not_using_indexes=ON #是否记录使用索引的搜索
16、数据库导入导出命令(结构+数据)?
#导出:
mysqldump -h 服务器 -u用户名 -p密码 数据库名 > 备份文件.sql
#导入: 1、mysqldump -uroot -p 数据库名称 < 路径 2、进入数据库; source + 要导入数据库文件路径
17、数据库优化方案?
1、创建数据表时把固定长度的放在前面 2、将固定数据放入内存:choice字段(django中用到,1,2,3对应相应内容) 3、char不可变,varchar可变 4、联合索引遵循最左前缀(从最左侧开始检索) 5、避免使用 select * 6、读写分离: #利用数据库的主从分离:主,用于删除、修改、更新;从,用于查 #实现:两台服务器同步数据 \原生SQL:select * from db.tb \ORM:model.User.object.all().using('default') \路由:db router 7、分库 # 当数据库中的表太多,将某些表分到不同数据库,例如:1W张表时 # 代价:连表查询跨数据库,代码变多 8、分表 # 水平分表:将某些列拆分到另一张表,例如:博客+博客详情 # 垂直分表:将某些历史信息,分到另外一张表中,例如:支付宝账单 9、加缓存 # 利用redis、memcache(常用数据放到缓存里,提高取数据速度) # 缓存不够可能会造成雪崩现象 10、如果只想获取一条数据 select * from tb where name = 'zgc' limit 1;
18、char和varchar的区别?
#char类型:定长不可变 存入字符长度大于设置长度时报错; 存入字符串长度小于设置长度时,用空格填充以达到设置字符串长度; 简单粗暴,浪费空间,存取速度快。 #varchar类型:可变 存储数据真实内容,不使用空格填充; 会在真实数据前加1-2Bytes的前缀,用来表示真实数据的bytes字节数; 边长、精准、节省空间、存取速度慢。
19、简述MySQL的执行计划?
# explain + SQL语句 # SQL在数据库中执行时的表现情况,通常用于SQL性能分析,优化等场景。 'explain select * from rbac_userinfo where id=1;'
查看有没有命中索引,让数据库帮看看运行速度快不快 explain select * from table;

当type为all时,是为全表索引
20、在对name做了唯一索引前提下,简述以下区别:
select * from tb where name = ‘小明’ select * from tb where name = ‘小明’ limit 1 ------------------------------------------------------------- 没做唯一索引的话,前者查询会全表扫描,效率低些 limit 1,只要找到对应一条数据,就不继续往下扫描. 然而 name 字段添加唯一索引了,加不加limit 1,意义都不大;
21、1000w条数据,使用limit offset 分页时,为什么越往后翻越慢?如何解决?
# 例如: #limit 100000,20; 从第十万条开始往后取二十条, #limit 20 offset 100000; limit后面是取20条数据,offset后面是从第10W条数据开始读 因为当一个数据库表过于庞大,LIMIT offset, length中的offset值过大,则SQL查询语句会非常缓慢 -------------------------------------------------------------------------- '优化一' 先查看主键,再分页: select * from tb where id in (select id from tb where limit 10 offset 30) -------------------------------------------------------------------------- '优化二' 记录当前页,数据、ID、最大值和最小值(用于where查询) 在翻页时,根据条件进行筛选,筛选完毕后,再根据 limit offset 查询 select * from(select * from tb where id > 2222) as B limit 10 offset 0; \如果用户自己修改页码,也可能导致变慢,此时可以对 url 页码进行加密,例如rest framework -------------------------------------------------------------------------- '优化三' 可以按照当前业务需求,看是否可以设置只允许看前200页; 一般情况下,没人会咔咔看个几十上百页的;
22、什么是索引合并?
# 索引合并访问方法可以在查询中对一个表使用多个索引,对它们同时扫描,并且合并结果。 # 此访问方法合并来自单个表的索引扫描; 它不会将扫描合并到多个表中。
23、什么是覆盖索引?
# 解释一: 就是select的数据列只用从索引中就能够取得,不必从数据表中读取,换句话说查询列要被所使用的索引覆盖。 # 解释二: 索引是高效找到行的一个方法,当能通过检索索引就可以读取想要的数据,那就不需要再到数据表中读取行了。 如果一个索引包含了(或覆盖了)满足查询语句中字段与条件的数据就叫做覆盖索引。 # 注意:MySQL只能使用B-Tree索引做覆盖索引
24、简述数据库读写分离?
#利用数据库的主从分离:主,用于删除、修改、更新;从,用于查 #实现:两台服务器同步数据(减轻服务器的压力) 原生SQL: select * from db.tb ORM:model.User.object.all().using('default') 路由:db router
25、简述数据库分库分表?(水平、垂直)
# 1、分库 当数据库中的表太多,将某些表分到不同数据库,例如:1W张表时 代价:连表查询跨数据库,代码变多 # 2、分表 水平分表:将某些列拆分到另一张表,例如:博客+博客详情 垂直分表:将某些历史信息,分到另外一张表中,例如:支付宝账单
26、redis和memcached比较?
# 1.存储容量: memcached超过内存比例会抹掉前面的数据,而redis会存储在磁盘 # 2.支持数据类型: memcached只支持string; redis支持更多;如:hash、list、集合、有序集合 # 3.持久化: redis支持数据持久化,可以将内存中的数据保持在磁盘中,memcached无 # 4.主从: 即master-slave模式的数据备份(主从)。 # 5.特性 Redis在很多方面具备数据库的特征,或者说就是一个数据库系统 Memcached只是简单的K/V缓存
27、redis中数据库默认是多少个db 及作用?
#redis默认有16个db,db0~db15(可以通过配置文件支持更多,无上限) #并且每个数据库的数据是隔离的不能共享 #可以随时使用SELECT命令更换数据库:redis> SELECT 1 # 注意: 多个数据库之间并不是完全隔离的 比如FLUSHALL命令可以清空一个Redis实例中所有数据库中的数据。
28、python操作redis的模块?
参考:点击查看
29、如果redis中的某个列表中的数据量非常大,如果实现循环显示每一个值?
# 通过scan_iter分片取,减少内存压力 scan_iter(match=None, count=None)增量式迭代获取redis里匹配的的值 # match,匹配指定key # count,每次分片最少获取个数 r = redis.Redis(connection_pool=pool) for key in r.scan_iter(match='PREFIX_*', count=100000): print(key)
30、redis如何实现主从复制?以及数据同步机制?
# 实现主从复制 '创建6379和6380配置文件' redis.conf:6379为默认配置文件,作为Master服务配置; redis_6380.conf:6380为同步配置,作为Slave服务配置; '配置slaveof同步指令' 在Slave对应的conf配置文件中,添加以下内容: slaveof 127.0.0.1 6379 # 数据同步步骤: (1)Slave服务器连接到Master服务器. (2)Slave服务器发送同步(SYCN)命令. (3)Master服务器备份数据库到文件. (4)Master服务器把备份文件传输给Slave服务器. (5)Slave服务器把备份文件数据导入到数据库中.
31、redis中的sentinel的作用?
# 帮助我们自动在主从之间进行切换(哨兵) # 检测主从中 主是否挂掉,且超过一半的sentinel检测到挂了之后才进行进行切换。 # 如果主修复好了,再次启动时候,会变成从。
32、如何实现redis集群?
#基于【分片】来完成。 - 集群是将你的数据拆分到多个Redis实例的过程 - 可以使用很多电脑的内存总和来支持更大的数据库。 - 没有分片,你就被局限于单机能支持的内存容量。 #redis将所有能放置数据的地方创建了 16384 个哈希槽。 #如果设置集群的话,就可以为每个实例分配哈希槽: - 192.168.1.20【0-5000】 - 192.168.1.21【5001-10000】 - 192.168.1.22【10001-16384】 #以后想要在redis中写值时:set k1 123 - 将k1通过crc16的算法转换成一个数字,然后再将该数字和16384求余, - 如果得到的余数 3000,那么就将该值写入到 192.168.1.20 实例中。 #集群方案: - redis cluster:官方提供的集群方案。 - codis:豌豆荚技术团队。 - tweproxy:Twiter技术团队。
33、redis中默认有多少个哈希槽?
#redis中默认有 16384 个哈希槽。
34、简述redis的有哪几种持久化策略及比较?
#RDB:每隔一段时间对redis进行一次持久化。 - 缺点:数据不完整 - 优点:速度快 #AOF:把所有命令保存起来,如果想重新生成到redis,那么就要把命令重新执行一次。 - 缺点:速度慢,文件比较大 - 优点:数据完整
35、列举redis支持的过期策略。
# 数据集(server.db[i].expires) a、voltile-lru: #从已设置过期时间的数据集中,挑选最近频率最少数据淘汰 b、volatile-ttl: #从已设置过期时间的数据集中,挑选将要过期的数据淘汰 c、volatile-random:#从已设置过期时间的数据集中,任意选择数据淘汰 d、allkeys-lru: #从数据集中,挑选最近最少使用的数据淘汰 e、allkeys-random: #从数据集中,任意选择数据淘汰 f、no-enviction(驱逐):#禁止驱逐数据
36、MySQL 里有 2000w 数据,redis 中只存 20w 的数据,如何保证 redis 中都是热点数据?
# 限定Redis占用的内存,根据自身数据淘汰策略,淘汰冷数据,把热数据加载到内存。 # 计算一下 20W 数据大约占用的内存,然后设置一下Redis内存限制即可。
37、写代码,基于redis的列表实现 先进先出、后进先出队列、优先级队列。???????????????????
Redis能做消息队列得益于他list对象blpop/brpop接口以及Pub/Sub(发布/订阅)的某些接口。他们都是阻塞版的,所以Redis实现消息队列有两种方式: 1、通过数据结构list来实现 2、通过pub/sub来实现
38、如何基于redis实现消息队列?
# 通过发布订阅模式的PUB、SUB实现消息队列 # 发布者发布消息到频道了,频道就是一个消息队列。 # 发布者: import redis conn = redis.Redis(host='127.0.0.1',port=6379) conn.publish('104.9MH', "hahahahahaha") # 订阅者: import redis conn = redis.Redis(host='127.0.0.1',port=6379) pub = conn.pubsub() pub.subscribe('104.9MH') while True: msg= pub.parse_response() print(msg) 对了,redis 做消息队列不合适 业务上避免过度复用一个redis,用它做缓存、做计算,还做任务队列,压力太大,不好。
39、如何基于redis实现发布和订阅?以及发布订阅和消息队列的区别?
# 发布和订阅,只要有任务就所有订阅者每人一份。 发布者: #发布一次 import redis conn = redis.Redis(host='127.0.0.1',port=6379) conn.publish('104.9MH', "hahahahahaha") 订阅者: #'while True'一直在接收 import redis conn = redis.Redis(host='127.0.0.1',port=6379) pub = conn.pubsub() pub.subscribe('104.9MH') while True: msg= pub.parse_response() print(msg)
40、什么是codis及作用?
Codis 是一个分布式 Redis 解决方案, 对于上层的应用来说, 连接到 Codis-Proxy(redis代理服务)和连接原生的 Redis-Server 没有明显的区别, 上层应用可以像使用单机的 Redis 一样使用, Codis 底层会处理请求的转发, 不停机的数据迁移等工作, 所有后边的一切事情, 对于前面的客户端来说是透明的, 可以简单的认为后边连接的是一个内存无限大的 Redis 服务.
41、什么是twemproxy及作用?
# 什么是Twemproxy 是Twtter开源的一个 Redis 和 Memcache 代理服务器, 主要用于管理 Redis 和 Memcached 集群,减少与Cache服务器直接连接的数量。 他的后端是多台REDIS或memcached所以也可以被称为分布式中间件。 # 作用 通过代理的方式减少缓存服务器的连接数。 自动在多台缓存服务器间共享数据。 通过配置的方式禁用失败的结点。 运行在多个实例上,客户端可以连接到首个可用的代理服务器。 支持请求的流式与批处理,因而能够降低来回的消耗。
42、写代码实现redis事务操作。
import redis pool = redis.ConnectionPool(host='10.211.55.4', port=6379) conn = redis.Redis(connection_pool=pool) # pipe = r.pipeline(transaction=False) pipe = conn.pipeline(transaction=True) # 开始事务 pipe.multi() pipe.set('name', 'zgc') pipe.set('role', 'haha') pipe.lpush('roless', 'haha') # 提交 pipe.execute() '注意':咨询是否当前分布式redis是否支持事务
43、redis中的watch的命令的作用?
# 用于监视一个或多个key # 如果在事务执行之前这个/些key被其他命令改动,那么事务将被打断
44、基于redis如何实现商城商品数量计数器?
'通过redis的watch实现' import redis conn = redis.Redis(host='127.0.0.1',port=6379) # conn.set('count',1000) val = conn.get('count') print(val) with conn.pipeline(transaction=True) as pipe: # 先监视,自己的值没有被修改过 conn.watch('count') # 事务开始 pipe.multi() old_count = conn.get('count') count = int(old_count) print('现在剩余的商品有:%s',count) input("问媳妇让不让买?") pipe.set('count', count - 1) # 执行,把所有命令一次性推送过去 pipe.execute() 数据库的锁
45、简述redis分布式锁和redlock的实现机制。
# redis分布式锁? # 不是单机操作,又多了一/多台机器 # redis内部是单进程、单线程,是数据安全的(只有自己的线程在操作数据) ---------------------------------------------------------------- #A、B、C,三个实例(主) 1、来了一个'隔壁老王'要操作,且不想让别人操作,so,加锁; 加锁:'隔壁老王'自己生成一个随机字符串,设置到A、B、C里(xxx=666) 2、来了一个'邻居老李'要操作A、B、C,一读发现里面有字符串,擦,被加锁了,不能操作了,等着吧~ 3、'隔壁老王'解决完问题,不用锁了,把A、B、C里的key:'xxx'删掉;完成解锁 4、'邻居老李'现在可以访问,可以加锁了 # 问题: 1、如果'隔壁老王'加锁后突然挂了,就没人解锁,就死锁了,其他人干看着没法用咋办? 2、如果'隔壁老王'去给A、B、C加锁的过程中,刚加到A,'邻居老李'就去操作C了,加锁成功or失败? 3、如果'隔壁老王'去给A、B、C加锁时,C突然挂了,这次加锁是成功还是失败? 4、如果'隔壁老王'去给A、B、C加锁时,超时时间为5秒,加一个锁耗时3秒,此次加锁能成功吗? # 解决 1、安全起见,让'隔壁老王'加锁时设置超时时间,超时的话就会自动解锁(删除key:'xxx') 2、加锁程度达到(1/2)+1个就表示加锁成功,即使没有给全部实例加锁; 3、加锁程度达到(1/2)+1个就表示加锁成功,即使没有给全部实例加锁; 4、不能成功,锁还没加完就过期,没有意义了,应该合理设置过期时间 # 注意 使用需要安装redlock-py ---------------------------------------------------------------- from redlock import Redlock dlm = Redlock( [ {"host": "localhost", "port": 6379, "db": 0}, {"host": "localhost", "port": 6379, "db": 0}, {"host": "localhost", "port": 6379, "db": 0}, ] ) # 加锁,acquire my_lock = dlm.lock("my_resource_name",10000) if my_lock: # 进行操作 # 解锁,release dlm.unlock(my_lock) else: print('获取锁失败') #通过sever.eval(self.unlock_script)执行一个lua脚本,用来删除加锁时的key
46、什么是一致性哈希?Python中是否有相应模块?
# 一致性哈希 一致性hash算法(DHT)可以通过减少影响范围的方式,解决增减服务器导致的数据散列问题,从而解决了分布式环境下负载均衡问题; 如果存在热点数据,可以通过增添节点的方式,对热点区间进行划分,将压力分配至其他服务器,重新达到负载均衡的状态。 # 模块:hash_ring
47、如何高效的找到redis中所有以zhugc开头的key?
redis 有一个keys命令。 # 语法:KEYS pattern # 说明:返回与指定模式相匹配的所用的keys。 该命令所支持的匹配模式如下: 1、?:用于匹配单个字符。例如,h?llo可以匹配hello、hallo和hxllo等; 2、*:用于匹配零个或者多个字符。例如,h*llo可以匹配hllo和heeeello等; 2、[]:可以用来指定模式的选择区间。例如h[ae]llo可以匹配hello和hallo,但是不能匹配hillo。同时,可以使用“/”符号来转义特殊的字符 # 注意 KEYS 的速度非常快,但如果数据太大,内存可能会崩掉, 如果需要从一个数据集中查找特定的key,最好还是用Redis的集合结构(set)来代替。
48、悲观锁和乐观锁的区别?
# 悲观锁 从数据开始更改时就将数据锁住,直到更改完成才释放; 会造成访问数据库时间较长,并发性不好,特别是长事务。 # 乐观锁 直到修改完成,准备提交修改到数据库时才会锁住数据,完成更改后释放; 相对悲观锁,在现实中使用较多。
第四部分 前端、框架和其他(155题)
1.谈谈你对http协议的认识。
浏览器本质,socket客户端遵循Http协议
HTTP协议本质:通过\r\n分割的规范+ 请求响应之后断开链接 == > 无状态、 短连接
具体:
Http协议是建立在tcp之上的,是一种规范,它规范定了发送的数据的数据格式,
然而这个数据格式是通过\r\n 进行分割的,请求头与请求体也是通过2个\r\n分割的,响应的时候,
响应头与响应体也是通过\r\n分割,并且还规定已请求已响应就会断开链接
即---> 短连接、无状态
2.谈谈你对websocket协议的认识。
websocket是给浏览器新建的一套(类似与http)协议,协议规定:(\r\n分割)浏览器和服务器连接之后不断开,
以此完成:服务端向客户端主动推送消息。
websocket协议额外做的一些操作
握手 ----> 连接钱进行校验
加密 ----> payload_len=127/126/<=125 --> mask key
本质
创建一个连接后不断开的socket
当连接成功之后:
客户端(浏览器)会自动向服务端发送消息,包含: Sec-WebSocket-Key: iyRe1KMHi4S4QXzcoboMmw==
服务端接收之后,会对于该数据进行加密:base64(sha1(swk + magic_string))
构造响应头:
HTTP/1.1 101 Switching Protocols\r\n
Upgrade:websocket\r\n
Connection: Upgrade\r\n
Sec-WebSocket-Accept: 加密后的值\r\n
WebSocket-Location: ws://127.0.0.1:8002\r\n\r\n
发给客户端(浏览器)
建立:双工通道,接下来就可以进行收发数据
发送数据是加密,解密,根据payload_len的值进行处理
payload_len <= 125
payload_len == 126
payload_len == 127
获取内容:
mask_key
数据
根据mask_key和数据进行位运算,就可以把值解析出来。
3.什么是magic string ?
客户端向服务端发送消息时,会有一个'sec-websocket-key'和'magic string'的随机字符串(魔法字符串)
# 服务端接收到消息后会把他们连接成一个新的key串,进行编码、加密,确保信息的安全性
4.如何创建响应式布局?
响应式布局是通过@media实现的
@media (min-width:768px){
.pg-header{
background-color:green;
}
}
@media (min-width:992px){
.pg-header{
background-color:pink;
}
}
代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Title</title>
<style>
body{
margin: 0;
}
.pg-header{
background-color: red;
height: 48px;
}
@media (min-width: 768px) {
.pg-header{
background-color: aqua;
}
}
@media (min-width: 992px) {
.pg-header{
background-color: blueviolet;
}
}
</style>
</head>
<body>
<div class="pg-header"></div>
</body>
</html>
5.你曾经使用过哪些前端框架?
jQuery
- BootStrap
- Vue.js(与vue齐名的前端框架React和Angular)
6.什么是ajax请求?并使用jQuery和XMLHttpRequest对象实现一个ajax请求。
基于原生AJAX - Demo基于jQueryAjax - Demohttp://www.cnblogs.com/wupeiqi/articles/5703697.html
7.如何在前端实现轮训?
轮询:通过定时器让程序每隔n秒执行一次操作。
<!DOCTYPE html>
<html lang="zh-cn">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Title</title>
</head>
<body>
<h1>请选出最帅的男人</h1>
<ul>
{% for k,v in gg.items() %}
<li>ID:{{ k }}, 姓名:{{ v.name }} ,票数:{{ v.count }}</li>
{% endfor %}
</ul>
<script>
setInterval(function () {
location.reload();
},2000)
</script>
</body>
</html>
8.如何在前端实现长轮训?
客户端向服务器发送请求,服务器接到请求后hang住连接,等待30秒,30s过后再重新发起请求,
直到有新消息才返回响应信息并关闭连接,客户端处理完响应信息后再向服务器发送新的请求。
利用queue对象实现请求夯住
每个请求进来都要生成一个q对象
如果有人投票 给所有的q对象put数据
拿数据请求从自己的q对象get数据
<!DOCTYPE html>
<html lang="zh-cn">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Title</title>
</head>
<body>
<h1>请选出最帅的男人</h1>
<ul>
{% for k,v in gg.items() %}
<li style="cursor: pointer" id="user_{{ k }}" ondblclick="vote({{ k }});">ID:{{ k }}, 姓名:{{ v.name }} ,票数:<span>{{ v.count }}</span></li>
{% endfor %}
</ul>
<script src="/static/jquery-3.3.1.min.js"></script>
<script>
$(function () {
get_new_count();
});
function get_new_count() {
$.ajax({
url: '/get_new_count',
type:'GET',
dataType:'JSON',
success:function (arg) {
if (arg.status){
// 更新票数
var gid = "#user_" + arg.data.gid;
$(gid).find('span').text(arg.data.count);
}else{
// 10s内没有人投票
}
get_new_count();
}
})
}
function vote(gid) {
$.ajax({
url: '/vote',
type:'POST',
data:{gid:gid},
dataType:"JSON",
success:function (arg) {
}
})
}
</script>
</body>
</html>
9.vuex的作用?
多组件之间共享:vuex
补充luffyvue
1:router-link / router-view
2:双向绑定,用户绑定v-model
3:循环展示课程:v-for
4:路由系统,添加动态参数
5:cookie操作:vue-cookies
6:多组件之间共享:vuex
7:发送ajax请求:axios (js模块)
10.vue中的路由的拦截器的作用?
vue-resource的interceptors拦截器的作用正是解决此需求的妙方。
在每次http的请求响应之后,如果设置了拦截器如下,会优先执行拦截器函数,获取响应体,然后才会决定是否把response返回给then进行接收
11.axios的作用?
发送ajax请求:axios (js模块)
12.列举vue的常见指令。
1、v-if指令:判断指令,根据表达式值得真假来插入或删除相应的值。
2、v-show指令:条件渲染指令,无论返回的布尔值是true还是false,元素都会存在在html中,只是false的元素会隐藏在html中,并不会删除.
3、v-else指令:配合v-if或v-else使用。
4、v-for指令:循环指令,相当于遍历。
5、v-bind:给DOM绑定元素属性。
6、v-on指令:监听DOM事件。
13.简述jsonp及实现原理?
JSONP
jsonp是json用来跨域的一个东西。原理是通过script标签的跨域特性来绕过同源策略。
JSONP的简单实现模式,或者说是JSONP的原型:创建一个回调函数,然后在远程服务上调用这个函数并且将JSON 数据形式作为参数传递,
完成回调。
14.什么是cors ?
CORS
浏览器将CORS请求分成两类:简单请求和赋复杂请求
简单请求(同时满足以下两大条件)
(1)请求方法是以下三种方法之一:
HEAD
GET
POST
(2)HTTP的头信息不超出以下几种字段:
Accept
Accept-Language
Content-Language
Last-Event-ID
Content-Type :只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain
凡是不同时满足上面两个条件,就属于非简单请求
15.列举Http请求中常见的请求方式?
GET、POST、
PUT、patch(修改数据)
HEAD(类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头)
DELETE
传值代码f
Request.QueryString方法针对控件id
Request.Form方法针对控件名称name
16.列举Http请求中的状态码?
分类:
1** 信息,服务器收到请求,需要请求者继续执行操作
2** 成功,操作被成功接收并处理
3** 重定向,需要进一步的操作以完成请求
4** 客户端错误,请求包含语法错误或无法完成请求
5** 服务器错误,服务器在处理请求的过程中发生了错误
常见的状态码
200 -请求成功
202 -已接受请求,尚未处理
204 -请求成功,且不需返回内容
301 - 资源(网页等)被永久转移到其他url
400 - 请求的语义或是参数有错
403 - 服务器拒绝请求
404 - 请求资源(网页)不存在
500 - 内部服务器错误
502 - 网关错误,一般是服务器压力过大导致连接超时
503 - 由于超载或系统维护,服务器暂时的无法处理客户端的请求。
17.列举Http请求中常见的请求头?
- user-agent
- host
- referer
- cookie
- content-type
18.看图写结果(js):

李杰
看图写结果(js):

武沛奇
看图写结果:(js)

老男孩
看图写结果:(js)

undefined
看图写结果:(js)

武沛奇
看图写结果:(js)

Alex
19.django、flask、tornado框架的比较?
对于django,大而全的框架它的内部组件比较多,内部提供:ORM、Admin、中间件、Form、ModelForm、Session、
缓存、信号、CSRF;功能也都挺完善的
- flask,微型框架,内部组件就比较少了,但是有很多第三方组件来扩展它,
比如说有那个wtform(与django的modelform类似,表单验证)、flask-sqlalchemy(操作数据库的)、
flask-session、flask-migrate、flask-script、blinker可扩展强,第三方组件丰富。所以对他本身来说有那种短小精悍的感觉
- tornado,异步非阻塞。
django和flask的共同点就是,他们2个框架都没有写socket,所以他们都是利用第三方模块wsgi。
但是内部使用的wsgi也是有些不同的:django本身运行起来使用wsgiref,而flask使用werkzeug wsgi
还有一个区别就是他们的请求管理不太一样:django是通过将请求封装成request对象,再通过参数传递,而flask是通过上下文管理机制
Tornado
# 是一个轻量级的Web框架,异步非阻塞+内置WebSocket功能。
'目标':通过一个线程处理N个并发请求(处理IO)。
'内部组件
#内部自己实现socket
#路由系统
#视图
#模板
#cookie
#csrf
20.什么是wsgi?
是web服务网关接口,是一套协议。
是通过以下模块实现了wsgi协议:
- wsgiref
- werkzurg
- uwsgi 关于部署
以上模块本质:编写socket服务端,用于监听请求,当有请求到来,则将请求数据进行封装,然后交给web框架处理。
21.django请求的生命周期?
用户请求进来先走到 wsgi 然后将请求交给 jango的中间件 穿过django中间件(方法是process_request)
接着就是 路由匹配 路由匹配成功之后就执行相应的 视图函数
在视图函数中可以调用orm做数据库操作 再从模板路径 将模板拿到 然后在后台进行模板渲染
模板渲染完成之后就变成一个字符串 再把这个字符串经过所有中间件(方法:process_response) 和wsgi 返回给用户

22.列举django的内置组件?
form 组件
- 对用户请求的数据进行校验
- 生成HTML标签
PS:
- form对象是一个可迭代对象。
- 问题:choice的数据如果从数据库获取可能会造成数据无法实时更新
- 重写构造方法,在构造方法中重新去数据库获取值。
- ModelChoiceField字段
from django.forms import Form
from django.forms import fields
from django.forms.models import ModelChoiceField
class UserForm(Form):
name = fields.CharField(label='用户名',max_length=32)
email = fields.EmailField(label='邮箱')
ut_id = ModelChoiceField(queryset=models.UserType.objects.all())
依赖:
class UserType(models.Model):
title = models.CharField(max_length=32)
def __str__(self):
return self.title
信号、
django的信号其实就是django内部为开发者预留的一些自定制功能的钩子。
只要在某个信号中注册了函数,那么django内部执行的过程中就会自动触发注册在信号中的函数。
如:
pre_init # django的modal执行其构造方法前,自动触发
post_init # django的modal执行其构造方法后,自动触发
pre_save # django的modal对象保存前,自动触发
post_save # django的modal对象保存后,自动触发
场景:
在数据库某些表中添加数据时,可以进行日志记录。
CSRF、
目标:防止用户直接向服务端发起POST请求。
对所有的post请求做验证/ 将jango生成的一串字符串发送给我们,一种是从请求体发过来,一种是放在隐藏的标签里面用的是process_view
方案:先发送GET请求时,将token保存到:cookie、Form表单中(隐藏的input标签),
以后再发送请求时只要携带过来即可。
ContentType
contenttype是django的一个组件(app),
为我们找到django程序中所有app中的所有表并添加到记录中。
可以使用他再加上表中的两个字段实现:一张表和N张表创建FK关系。 - 字段:表名称 - 字段:数据行ID
应用:路飞表结构优惠券和专题课和学位课关联。
中间件
对所有的请求进行批量处理,在视图函数执行前后进行自定义操作。
应用:用户登录校验
问题:为甚么不使用装饰器?
如果不使用中间件,就需要给每个视图函数添加装饰器,太繁琐
权限组件:
用户登录后,将权限放到session中,然后再每次请求进来在中间件里,根据当前的url去session中匹配,
判断当前用户是否有权限访问当前url,有权限就继续访问,没有就返回,
(检查的东西就可以放到中间件中进行统一处理)在process_request方法里面做的,
我们的中间件是放在session后面,因为中间件需要到session里面取数据
session
cookie与session区别
(a)cookie是保存在浏览器端的键值对,而session是保存的服务器端的键值对,但是依赖cookie。
(也可以不依赖cookie,可以放在url,或请求头但是cookie比较方便)
(b)以登录为例,cookie为通过登录成功后,设置明文的键值对,并将键值对发送客户端存,明文信息可能存在泄漏,不安全;
session则是生成随机字符串,发给用户,并写到浏览器的cookie中,同时服务器自己也会保存一份。
(c)在登录验证时,cookie:根据浏览器发送请求时附带的cookie的键值对进行判断,如果存在,则验证通过;
session:在请求用户的cookie中获取随机字符串,根据随机字符串在session中获取其对应的值进行验证
cors跨域(场景:前后端分离时,本地测试开发时使用)
如果网站之间存在跨域,域名不同,端口不同会导致出现跨域,但凡出现跨域,浏览器就会出现同源策略的限制
解决:在我们的服务端给我们响应数据,加上响应头---> 在中间件加的
缓存/
常用的数据放在缓存里面,就不用走视图函数,请求进来通过所有的process_request,会到缓存里面查数据,有就直接拿,
没有就走视图函数
关键点:1:执行完所有的process_request才去缓存取数据
2:执行完所有的process_response才将数据放到缓存
关于缓存问题
1:为什么放在最后一个process_request才去缓存
因为需要验证完用户的请求,才能返回数据
2:什么时候将数据放到缓存中
第一次走中间件,缓存没有数据,会走视图函数,取数据库里面取数据,
当走完process_response,才将数据放到缓存里,因为,走process_response的时候可能给我们的响应加处理
为什么使用缓存
将常用且不太频繁修改的数据放入缓存。
以后用户再来访问,先去缓存查看是否存在,如果有就返回
否则,去数据库中获取并返回给用户(再加入到缓存,以便下次访问)
23.列举django中间件的5个方法?以及django中间件的应用场景?
process_request(self,request) 先走request 通过路由匹配返回
process_view(self, request, callback, callback_args, callback_kwargs) 再返回执行view
process_template_response(self,request,response) 当视图函数的返回值
process_exception(self, request, exception) 当视图函数的返回值对象中有render方法时,该方法才会被调用
process_response(self, request, response)
执行流程

24.简述什么是FBV和CBV?
FBV 基于函数
# FBV 写法
# urls.py
url(r'^login/$',views.login, name="login"),
# views.py
def login(request):
if request.method == "POST":
print(request.POST)
return render(request,"login.html")
# HTML
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>登录页面</title>
</head>
<body>
<form action="{% url 'login' %}" method="post" enctype="multipart/form-data">
<input type="text" name="user2">
<input type="file" name="file">
<input type="submit" value="提交">
</form>
</body>
</html>
CBV 基于类
# urls.py
url(r'^login/$',views.Login.as_view(), name="login"),
# views.py
from django.views import View
class Login(View): # 类首字母大写
def get(self,request):
return render(request,"login.html")
def post(self,request):
print(request.POST)
return HttpResponse("OK")
加装饰器
=================================
class IndexView(View):
# 如果是crsf相关,必须放在此处
def dispach(self,request):
# 通过反射执行post/get
@method_decoretor(装饰器函数)
def get(self,request):
pass
def post(self,request):
pass
路由:IndexView.as_view()
25.FBV与CBV的区别
- 没什么区别,因为他们的本质都是函数。CBV的.as_view()返回的view函数,view函数中调用类的dispatch方法,
在dispatch方法中通过反射执行get/post/delete/put等方法。D
非要说区别的话:
- CBV比较简洁,GET/POST等业务功能分别放在不同get/post函数中。FBV自己做判断进行区分。
26.django的request对象是在什么时候创建的?
当请求一个页面时, Django会建立一个包含请求元数据的 HttpRequest 对象.
当Django 加载对应的视图时, HttpRequest对象将作为视图函数的第一个参数.
每个视图会返回一个HttpResponse对象.
27.如何给CBV的程序添加装饰器?
添加装饰器
方式一:
from django.views import View
from django.utils.decorators import method_decorator ---> 需要引入memethod_decorator
def auth(func):
def inner(*args,**kwargs):
return func(*args,**kwargs)
return inner
class UserView(View):
@method_decorator(auth)
def get(self,request,*args,**kwargs):
return HttpResponse('...')
方式二:
- csrf的装饰器要加到dispath前面
from django.views import View
from django.utils.decorators import method_decorator
from django.views.decorators.csrf import csrf_exempt,csrf_protect ---> 需要引入 csrf_exempt
class UserView(View):
@method_decorator(csrf_exempt)
def dispatch(self, request, *args, **kwargs):
return HttpResponse('...')
或者:
from django.views import View
from django.utils.decorators import method_decorator
from django.views.decorators.csrf import csrf_exempt,csrf_protect
@method_decorator(csrf_exempt,name='dispatch') ---> 指定名字
class UserView(View):
def dispatch(self, request, *args, **kwargs):
return HttpResponse('...')
28.列举django orm 中所有的方法(QuerySet对象的所有方法)
返回QuerySet对象的方法有:
all()
filter()
exclude()
order_by()
reverse()
distinct()
特殊的QuerySet:
values() 返回一个可迭代的字典序列
values_list() 返回一个可迭代的元组序列
返回具体对象的:
get()
first()
last()
返回布尔值的方法有:
exists()
返回数字的方法有:
count()
29.only和defer的区别?
def defer(self, *fields):
models.UserInfo.objects.defer('username','id')
或
models.UserInfo.objects.filter(...).defer('username','id')
#映射中排除某列数据
def only(self, *fields):
#仅取某个表中的数据
models.UserInfo.objects.only('username','id')
或
models.UserInfo.objects.filter(...).only('username','id')
30.select_related和prefetch_related的区别?
# 他俩都用于连表查询,减少SQL查询次数
\select_related
select_related主要针一对一和多对一关系进行优化,通过多表join关联查询,一次性获得所有数据,
存放在内存中,但如果关联的表太多,会严重影响数据库性能。
def index(request):
obj = Book.objects.all().select_related("publisher")
return render(request, "index.html", locals())
\prefetch_related
prefetch_related是通过分表,先获取各个表的数据,存放在内存中,然后通过Python处理他们之间的关联。
def index(request):
obj = Book.objects.all().prefetch_related("publisher")
return render(request, "index.html", locals())
def select_related(self, *fields)
性能相关:表之间进行join连表操作,一次性获取关联的数据。
model.tb.objects.all().select_related()
model.tb.objects.all().select_related('外键字段')
model.tb.objects.all().select_related('外键字段__外键字段')
def prefetch_related(self, *lookups)
性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。
# 获取所有用户表
# 获取用户类型表where id in (用户表中的查到的所有用户ID)
models.UserInfo.objects.prefetch_related('外键字段')
from django.db.models import Count, Case, When, IntegerField
Article.objects.annotate(
numviews=Count(Case(
When(readership__what_time__lt=treshold, then=1),
output_field=CharField(),
))
)
students = Student.objects.all().annotate(num_excused_absences=models.Sum(
models.Case(
models.When(absence__type='Excused', then=1),
default=0,
output_field=models.IntegerField()
)))
# 1次SQL
# select * from userinfo
objs = UserInfo.obejcts.all()
for item in objs:
print(item.name)
# n+1次SQL
# select * from userinfo
objs = UserInfo.obejcts.all()
for item in objs:
# select * from usertype where id = item.id
print(item.name,item.ut.title)
select_related()
# 1次SQL
# select * from userinfo inner join usertype on userinfo.ut_id = usertype.id
objs = UserInfo.obejcts.all().select_related('ut') 连表查询
for item in objs:
print(item.name,item.ut.title)
.prefetch_related()
# select * from userinfo where id <= 8
# 计算:[1,2]
# select * from usertype where id in [1,2]
objs = UserInfo.obejcts.filter(id__lte=8).prefetch_related('ut')
for obj in objs:
print(obj.name,obj.ut.title)
31.filter和exclude的区别?
def filter(self, *args, **kwargs)
# 条件查询(符合条件)
# 查出符合条件
# 条件可以是:参数,字典,Q
def exclude(self, *args, **kwargs)
# 条件查询(排除条件)
# 排除不想要的
# 条件可以是:参数,字典,Q
32.列举django orm中三种能写sql语句的方法。
原生SQL ---> connection
from django.db import connection, connections
cursor = connection.cursor() # cursor = connections['default'].cursor()
cursor.execute("""SELECT * from auth_user where id = %s""", [1])
row = cursor.fetchone() # fetchall()/fetchmany(..)
靠近原生SQL-->extra\raw
extra
- extra
def extra(self, select=None, where=None, params=None, tables=None, order_by=None,
select_params=None)
# 构造额外的查询条件或者映射,如:子查询
Entry.objects.extra(select={'new_id': "select col from sometable where othercol > %s"},
select_params=(1,))
Entry.objects.extra(where=['headline=%s'], params=['Lennon'])
Entry.objects.extra(where=["foo='a' OR bar = 'a'", "baz = 'a'"])
Entry.objects.extra(select={'new_id': "select id from tb where id > %s"}, s
elect_params=(1,), order_by=['-nid'])
- raw
def raw(self, raw_query, params=None, translations=None, using=None):
# 执行原生SQL
models.UserInfo.objects.raw('select * from userinfo')
# 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名
models.UserInfo.objects.raw('select id as nid,name as title from 其他表')
# 为原生SQL设置参数
models.UserInfo.objects.raw('select id as nid from userinfo where nid>%s', params=[12,])
# 将获取的到列名转换为指定列名
name_map = {'first': 'first_name', 'last': 'last_name', 'bd': 'birth_date', 'pk': 'id'}
Person.objects.raw('SELECT * FROM some_other_table', translations=name_map)
# 指定数据库
models.UserInfo.objects.raw('select * from userinfo', using="default")
33.django orm 中如何设置读写分离?
方式一:手动使用queryset的using方法
from django.shortcuts import render,HttpResponse
from app01 import models
def index(request):
models.UserType.objects.using('db1').create(title='普通用户')
# 手动指定去某个数据库取数据
result = models.UserType.objects.all().using('db1')
print(result)
return HttpResponse('...')
方式二:写配置文件
class Router1:
# 指定到某个数据库取数据
def db_for_read(self, model, **hints):
"""
Attempts to read auth models go to auth_db.
"""
if model._meta.model_name == 'usertype':
return 'db1'
else:
return 'default'
# 指定到某个数据库存数据
def db_for_write(self, model, **hints):
"""
Attempts to write auth models go to auth_db.
"""
return 'default'
再写到配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
},
'db1': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
}
}
DATABASE_ROUTERS = ['db_router.Router1',]
34.F和Q的作用?
F:主要用来获取原数据进行计算。
Django 支持 F() 对象之间以及 F() 对象和常数之间的加减乘除和取模的操作。
修改操作也可以使用F函数,比如将每件商品的价格都在原价格的基础上增加10
from django.db.models import F
from app01.models import Goods
Goods.objects.update(price=F("price")+10) # 对于goods表中每件商品的价格都在原价格的基础上增加10元
F查询专门对对象中某列值的操作,不可使用__双下划线!
Q:用来进行复杂查询
Q查询可以组合使用 “&”, “|” 操作符,当一个操作符是用于两个Q的对象,它产生一个新的Q对象,
Q对象可以用 “~” 操作符放在前面表示否定,也可允许否定与不否定形式的组合。
Q对象可以与关键字参数查询一起使用,不过一定要把Q对象放在关键字参数查询的前面。
Q(条件1) | Q(条件2) 或
Q(条件1) & Q(条件2) 且
Q(条件1) & ~Q(条件2) 非
35.values和values_list的区别?
def values(self, *fields):
# 获取每行数据为字典格式
def values_list(self, *fields, **kwargs):
# 获取每行数据为元祖
36.如何使用django orm批量创建数据?
def bulk_create(self, objs, batch_size=None):
# 批量插入
# batch_size表示一次插入的个数
objs = [
models.DDD(name='r11'),
models.DDD(name='r22')
]
models.DDD.objects.bulk_create(objs, 10)
37.django的Form和ModeForm的作用?
- 作用:
- 对用户请求数据格式进行校验
- 自动生成HTML标签
- 区别:
- Form,字段需要自己手写。
class Form(Form):
xx = fields.CharField(.)
xx = fields.CharField(.)
xx = fields.CharField(.)
xx = fields.CharField(.)
- ModelForm,可以通过Meta进行定义
class MForm(ModelForm):
class Meta:
fields = "__all__"
model = UserInfo
- 应用:只要是客户端向服务端发送表单数据时,都可以进行使用,如:用户登录注册
38.django的Form组件中,如果字段中包含choices参数,请使用两种方式实现数据源实时更新。
方式一:重写构造方法,在构造方法中重新去数据库获取值
class UserForm(Form):
name = fields.CharField(label='用户名',max_length=32)
email = fields.EmailField(label='邮箱')
ut_id = fields.ChoiceField(
# choices=[(1,'普通用户'),(2,'IP用户')]
choices=[]
)
def __init__(self,*args,**kwargs):
super(UserForm,self).__init__(*args,**kwargs)
self.fields['ut_id'].choices = models.UserType.objects.all().values_list('id','title')
方式二: ModelChoiceField字段
from django.forms import Form
from django.forms import fields
from django.forms.models import ModelChoiceField
class UserForm(Form):
name = fields.CharField(label='用户名',max_length=32)
email = fields.EmailField(label='邮箱')
ut_id = ModelChoiceField(queryset=models.UserType.objects.all())
依赖:
class UserType(models.Model):
title = models.CharField(max_length=32)
def __str__(self):
return self.title
39.django的Model中的ForeignKey字段中的on_delete参数有什么作用?
在django2.0后,定义外键和一对一关系的时候需要加on_delete选项,此参数为了避免两个表里的数据不一致问题,不然会报错:
TypeError: __init__() missing 1 required positional argument: 'on_delete'
举例说明:
user=models.OneToOneField(User)
owner=models.ForeignKey(UserProfile)
需要改成:
user=models.OneToOneField(User,on_delete=models.CASCADE) --在老版本这个参数(models.CASCADE)是默认值
owner=models.ForeignKey(UserProfile,on_delete=models.CASCADE) --在老版本这个参数(models.CASCADE)是默认值
参数说明:
on_delete有CASCADE、PROTECT、SET_NULL、SET_DEFAULT、SET()五个可选择的值
CASCADE:此值设置,是级联删除。
PROTECT:此值设置,是会报完整性错误。
SET_NULL:此值设置,会把外键设置为null,前提是允许为null。
SET_DEFAULT:此值设置,会把设置为外键的默认值。
SET():此值设置,会调用外面的值,可以是一个函数。
一般情况下使用CASCADE就可以了。
40.django中csrf的实现机制?
目的:防止用户直接向服务端发起POST请求
- 用户先发送GET获取csrf token: Form表单中一个隐藏的标签 + token - 发起POST请求时,需要携带之前发送给用户的csrf token; - 在中间件的process_view方法中进行校验。 在html中添加{%csrf_token%}标签
41.django如何实现websocket?
django中可以通过channel实现websocket
42.基于django使用ajax发送post请求时,都可以使用哪种方法携带csrf token?
//方式一给每个ajax都加上上请求头
function Do1(){
$.ajax({
url:"/index/",
data:{id:1},
type:'POST',
data:{csrfmiddlewaretoken:'{{ csrf_token }}',name:'alex'}
success:function(data){
console.log(data);
}
});
}
方式二:需要先下载jQuery-cookie,才能去cookie中获取token
function Do1(){
$.ajax({
url:"/index/",
data:{id:1},
type:'POST',
headers:{
'X-CSRFToken':$.cookie('csrftoken') // 去cookie中获取
},
success:function(data){
console.log(data);
}
});
}
方式三:搞个函数ajaxSetup,当有多的ajax请求,即会执行这个函数
$.ajaxSetup({
beforeSend:function (xhr,settings) {
xhr.setRequestHeader("X-CSRFToken",$.cookie('csrftoken'))
}
});
函数版本
<body>
<input type="button" onclick="Do1();" value="Do it"/>
<input type="button" onclick="Do2();" value="Do it"/>
<input type="button" onclick="Do3();" value="Do it"/>
<script src="/static/jquery-3.3.1.min.js"></script>
<script src="/static/jquery.cookie.js"></script>
<script>
$.ajaxSetup({
beforeSend: function(xhr, settings) {
xhr.setRequestHeader("X-CSRFToken", $.cookie('csrftoken'));
}
});
function Do1(){
$.ajax({
url:"/index/",
data:{id:1},
type:'POST',
success:function(data){
console.log(data);
}
});
}
function Do2(){
$.ajax({
url:"/index/",
data:{id:1},
type:'POST',
success:function(data){
console.log(data);
}
});
}
function Do3(){
$.ajax({
url:"/index/",
data:{id:1},
type:'POST',
success:function(data){
console.log(data);
}
});
}
</script>
</body>
43.django中如何实现orm表中添加数据时创建一条日志记录。
给信号注册函数
使用django的信号机制,可以在添加、删除数据前后设置日志记录
pre_init # Django中的model对象执行其构造方法前,自动触发
post_init # Django中的model对象执行其构造方法后,自动触发
pre_save # Django中的model对象保存前,自动触发
post_save # Django中的model对象保存后,自动触发
pre_delete # Django中的model对象删除前,自动触发
post_delete # Django中的model对象删除后,自动触发
44.django缓存如何设置?
jango中提供了6种缓存方式:
开发调试(不加缓存)
内存
文件
数据库
Memcache缓存(python-memcached模块)
Memcache缓存(pylibmc模块)
安装第三方组件支持redis:
django-redis组件
设置缓存
# 全站缓存(中间件)
MIDDLEWARE_CLASSES = (
‘django.middleware.cache.UpdateCacheMiddleware’, #第一
'django.middleware.common.CommonMiddleware',
‘django.middleware.cache.FetchFromCacheMiddleware’, #最后
)
# 视图缓存
from django.views.decorators.cache import cache_page
import time
@cache_page(15) #超时时间为15秒
def index(request):
t=time.time() #获取当前时间
return render(request,"index.html",locals())
# 模板缓存
{% load cache %}
<h3 style="color: green">不缓存:-----{{ t }}</h3>
{% cache 2 'name' %} # 存的key
<h3>缓存:-----:{{ t }}</h3>
{% endcache %}
45.django的缓存能使用redis吗?如果可以的话,如何配置?
pip install django-redis
apt-get install redis-serv
在setting添加配置文件
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache", # 缓存类型
"LOCATION": "127.0.0.1:6379", # ip端口
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient", #
"CONNECTION_POOL_KWARGS": {"max_connections": 100} # 连接池最大连接数
# "PASSWORD": "密码",
}
}
}
使用
from django.shortcuts import render,HttpResponse
from django_redis import get_redis_connection
def index(request):
# 根据名字去连接池中获取连接
conn = get_redis_connection("default")
conn.hset('n1','k1','v1') # 存数据
return HttpResponse('...')
46.django路由系统中name的作用?
反向解析路由字符串
路由系统中name的作用:反向解析
url(r'^home', views.home, name='home')
在模板中使用:{ % url 'home' %}
在视图中使用:reverse(“home”)
47.django的模板中filter和simple_tag的区别?
filter : 类似管道,只能接受两个参数第一个参数是|前的数据
simple_tag : 类似函数
1、模板继承:{ % extends 'layouts.html' %}
2、自定义方法
'filter':只能传递两个参数,可以在if、for语句中使用
'simple_tag':可以无线传参,不能在if for中使用
'inclusion_tags':可以使用模板和后端数据
3、防xss攻击: '|safe'、'mark_safe'
48.django-debug-toolbar的作用?
一、查看访问的速度、数据库的行为、cache命中等信息。
二、尤其在Mysql访问等的分析上大有用处(sql查询速度)
49.django中如何实现单元测试?
对于每一个测试方法都会将setUp()和tearDown()方法执行一遍
会单独新建一个测试数据库来进行数据库的操作方面的测试,默认在测试完成后销毁。
在测试方法中对数据库进行增删操作,最后都会被清除。也就是说,在test_add中插入的数据,在test_add测试结束后插入的数据会被清除。
django单元测试时为了模拟生产环境,会修改settings中的变量,例如, 把DEBUG变量修改为True, 把ALLOWED_HOSTS修改为[*]。
50.解释orm中 db first 和 code first的含义?
db first: 先创建数据库,再更新表模型
code first:先写表模型,再更新数据库
https://www.cnblogs.com/jassin-du/p/8988897.html
51.django中如何根据数据库表生成model中的类?
1、修改seting文件,在setting里面设置要连接的数据库类型和名称、地址
2、运行下面代码可以自动生成models模型文件
- python manage.py inspectdb
3、创建一个app执行下下面代码:
- python manage.py inspectdb > app/models.py
52.使用orm和原生sql的优缺点?
SQL:
# 优点:
执行速度快
# 缺点:
编写复杂,开发效率不高
---------------------------------------------------------------------------
ORM:
# 优点:
让用户不再写SQL语句,提高开发效率
可以很方便地引入数据缓存之类的附加功能
# 缺点:
在处理多表联查、where条件复杂查询时,ORM的语法会变得复杂。
没有原生SQL速度快
53.简述MVC和MTV
MVC:model、view(模块)、controller(视图)
MTV:model、tempalte、view
54.django的contenttype组件的作用?
contenttype是django的一个组件(app),它可以将django下所有app下的表记录下来
可以使用他再加上表中的两个字段,实现一张表和N张表动态创建FK关系。
- 字段:表名称
- 字段:数据行ID
应用:路飞表结构优惠券和专题课和学位课关联
55.谈谈你对restfull 规范的认识?
restful其实就是一套编写接口的'协议',规定如何编写以及如何设置返回值、状态码等信息。
# 最显著的特点:
# 用restful:
给用户一个url,根据method不同在后端做不同的处理
比如:post创建数据、get获取数据、put和patch修改数据、delete删除数据。
# 不用restful:
给调用者很多url,每个url代表一个功能,比如:add_user/delte_user/edit_user/
# 当然,还有协议其他的,比如:
'版本'来控制让程序有多个版本共存的情况,版本可以放在 url、请求头(accept/自定义)、GET参数
'状态码'200/300/400/500
'url中尽量使用名词'restful也可以称为“面向资源编程”
'api标示'
api.luffycity.com
www.luffycity.com/api/
56.接口的幂等性是什么意思?
'一个接口通过1次相同的访问,再对该接口进行N次相同的访问时,对资源不造影响就认为接口具有幂等性。'
GET, #第一次获取结果、第二次也是获取结果对资源都不会造成影响,幂等。
POST, #第一次新增数据,第二次也会再次新增,非幂等。
PUT, #第一次更新数据,第二次不会再次更新,幂等。
PATCH,#第一次更新数据,第二次不会再次更新,非幂等。
DELTE,#第一次删除数据,第二次不在再删除,幂等。
57.什么是RPC?
'远程过程调用协议'
是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
进化的顺序: 现有的RPC,然后有的RESTful规范
58.Http和Https的区别?
#Http: 80端口
#https: 443端口
# http信息是明文传输,https则是具有安全性的ssl加密传输协议。
#- 自定义证书
- 服务端:创建一对证书
- 客户端:必须携带证书
#- 购买证书
- 服务端: 创建一对证书,。。。。
- 客户端: 去机构获取证书,数据加密后发给咱们的服务单
- 证书机构:公钥给改机构
59.为什么要使用django rest framework框架?
# 在编写接口时可以不使用django rest framework框架,
# 不使用:也可以做,可以用django的CBV来实现,开发者编写的代码会更多一些。
# 使用:内部帮助我们提供了很多方便的组件,我们通过配置就可以完成相应操作,如:
'序列化'可以做用户请求数据校验+queryset对象的序列化称为json
'解析器'获取用户请求数据request.data,会自动根据content-type请求头的不能对数据进行解析
'分页'将从数据库获取到的数据在页面进行分页显示。
# 还有其他组件:
'认证'、'权限'、'访问频率控制
60.django rest framework框架中都有那些组件?
#- 路由,自动帮助开发者快速为一个视图创建4个url
www.oldboyedu.com/api/v1/student/$
www.oldboyedu.com/api/v1/student(?P<format>\w+)$
www.oldboyedu.com/api/v1/student/(?P<pk>\d+)/$
www.oldboyedu.com/api/v1/student/(?P<pk>\d+)(?P<format>\w+)$
#- 版本处理
- 问题:版本都可以放在那里?
- url
- GET
- 请求头
#- 认证
- 问题:认证流程?
#- 权限
- 权限是否可以放在中间件中?以及为什么?
#- 访问频率的控制
匿名用户可以真正的防止?无法做到真正的访问频率控制,只能把小白拒之门外。
如果要封IP,使用防火墙来做。
登录用户可以通过用户名作为唯一标示进行控制,如果有人注册很多账号,则无法防止。
#- 视图
#- 解析器 ,根据Content-Type请求头对请求体中的数据格式进行处理。request.data
#- 分页
#- 序列化
- 序列化
- source
- 定义方法
- 请求数据格式校验
#- 渲染器
61.django rest framework框架中的视图都可以继承哪些类
a. 继承APIView(最原始)但定制性比较强
这个类属于rest framework中的顶层类,内部帮助我们实现了只是基本功能:认证、权限、频率控制,
但凡是数据库、分页等操作都需要手动去完成,比较原始。
class GenericAPIView(APIView)
def post(...):
pass
b.继承GenericViewSet(ViewSetMixin,generics.GenericAPIView)
首先他的路由就发生变化
如果继承它之后,路由中的as_view需要填写对应关系
在内部也帮助我们提供了一些方便的方法:
get_queryset
get_object
get_serializer
get_serializer_class
get_serializer_context
filter_queryset
注意:要设置queryset字段,否则会抛出断言的异常。
代码
只提供增加功能 只继承GenericViewSet
class TestView(GenericViewSet):
serialazer_class = xxx
def creat(self,*args,**kwargs):
pass # 获取数据并对数据
c. 继承 modelviewset --> 快速快发
-ModelViewSet(增删改查全有+数据库操作)
-mixins.CreateModelMixin(只有增),GenericViewSet
-mixins.CreateModelMixin,DestroyModelMixin,GenericViewSet
对数据库和分页等操作不用我们在编写,只需要继承相关类即可。
示例:只提供增加功能
class TestView(mixins.CreateModelMixin,GenericViewSet):
serializer_class = XXXXXXX
***
modelviewset --> 快速开发,复杂点的genericview、apiview

62.简述 django rest framework框架的认证流程。
- 如何编写?写类并实现authenticators
请求进来认证需要编写一个类,类里面有一个authenticators方法,我们可以自定义这个方法,可以定制3类返回值。
成功返回元组,返回none为匿名用户,抛出异常为认证失败。
源码流程:请求进来先走dispatch方法,然后封装的request对象会执行user方法,由user触发authenticators认证流程
- 方法中可以定义三种返回值:
- (user,auth),认证成功
- None , 匿名用户
- 异常 ,认证失败
- 流程:
- dispatch
- 再去request中进行认证处理
63.django rest framework如何实现的用户访问频率控制?
# 对匿名用户,根据用户IP或代理IP作为标识进行记录,为每个用户在redis中建一个列表
{
throttle_1.1.1.1:[1526868876.497521,152686885.497521...],
throttle_1.1.1.2:[1526868876.497521,152686885.497521...],
throttle_1.1.1.3:[1526868876.497521,152686885.497521...],
}
每个用户再来访问时,需先去记录中剔除过期记录,再根据列表的长度判断是否可以继续访问。
'如何封IP':在防火墙中进行设置
--------------------------------------------------------------------------
# 对注册用户,根据用户名或邮箱进行判断。
{
throttle_xxxx1:[1526868876.497521,152686885.497521...],
throttle_xxxx2:[1526868876.497521,152686885.497521...],
throttle_xxxx3:[1526868876.497521,152686885.497521...],
}
每个用户再来访问时,需先去记录中剔除过期记录,再根据列表的长度判断是否可以继续访问。
\如1分钟:40次,列表长度限制在40,超过40则不可访问
64.Flask框架的优势?
Flask自由、灵活,可扩展性强,透明可控,第三方库的选择面广,
开发时可以结合最流行最强大的Python库,
65.Flask框架依赖组件
# 依赖jinja2模板引擎 # 依赖werkzurg协议
66.Flask蓝图的作用
# blueprint把实现不同功能的module分开.也就是把一个大的App分割成各自实现不同功能的module. # 在一个blueprint中可以调用另一个blueprint的视图函数, 但要加相应的blueprint名.
67.列举使用的Flask第三方组件?
# Flask组件
flask-session session放在redis
flask-SQLAlchemy 如django里的ORM操作
flask-migrate 数据库迁移
flask-script 自定义命令
blinker 信号-触发信号
# 第三方组件
Wtforms 快速创建前端标签、文本校验
dbutile 创建数据库连接池
gevnet-websocket 实现websocket
# 自定义Flask组件
自定义auth认证
参考flask-login组件
68.简述Flask上下文管理流程?
# a、简单来说,falsk上下文管理可以分为三个阶段:
1、'请求进来时':将请求相关的数据放入上下问管理中
2、'在视图函数中':要去上下文管理中取值
3、'请求响应':要将上下文管理中的数据清除
# b、详细点来说:
1、'请求刚进来':
将request,session封装在RequestContext类中
app,g封装在AppContext类中
并通过LocalStack将requestcontext和appcontext放入Local类中
2、'视图函数中':
通过localproxy--->偏函数--->localstack--->local取值
3、'请求响应时':
先执行save.session()再各自执行pop(),将local中的数据清除
69.Flask中的g的作用?
# g是贯穿于一次请求的全局变量,当请求进来将g和current_app封装为一个APPContext类, # 再通过LocalStack将Appcontext放入Local中,取值时通过偏函数在LocalStack、local中取值; # 响应时将local中的g数据删除:
Flask中上下文管理主要涉及到了那些相关的类?并描述类主要作用?
RequestContext #封装进来的请求(赋值给ctx) AppContext #封装app_ctx LocalStack #将local对象中的数据维护成一个栈(先进后出) Local #保存请求上下文对象和app上下文对象
为什么要Flask把Local对象中的的值stack 维护成一个列表?
# 因为通过维护成列表,可以实现一个栈的数据结构,进栈出栈时只取一个数据,巧妙的简化了问题。 # 还有,在多app应用时,可以实现数据隔离;列表里不会加数据,而是会生成一个新的列表 # local是一个字典,字典里key(stack)是唯一标识,value是一个列表
Flask中多app应用是怎么完成?
请求进来时,可以根据URL的不同,交给不同的APP处理。蓝图也可以实现。
#app1 = Flask('app01')
#app2 = Flask('app02')
#@app1.route('/index')
#@app2.route('/index2')
源码中在DispatcherMiddleware类里调用app2.__call__,
原理其实就是URL分割,然后将请求分发给指定的app。
之后app也按单app的流程走。就是从app.__call__走。
在Flask中实现WebSocket需要什么组件?
gevent-websocket
wtforms组件的作用?
#快速创建前端标签、文本校验;如django的ModelForm
Flask框架默认session处理机制?
# 前提:
不熟的话:记不太清了,应该是……分两个阶段吧
# 创建:
当请求刚进来的时候,会将request和session封装成一个RequestContext()对象,
接下来把这个对象通过LocalStack()放入内部的一个Local()对象中;
因为刚开始 Local 的ctx中session是空的;
所以,接着执行open_session,将cookie 里面的值拿过来,重新赋值到ctx中
(Local实现对数据隔离,类似threading.local)
# 销毁:
最后返回时执行 save_session() 将ctx 中的session读出来进行序列化,写到cookie
然后给用户,接着把 ctx pop掉
解释Flask框架中的Local对象和threading.local对象的区别?
# a.threading.local
作用:为每个线程开辟一块空间进行数据存储(数据隔离)。
问题:自己通过字典创建一个类似于threading.local的东西。
storage = {
4740: {val: 0},
4732: {val: 1},
4731: {val: 3},
}
# b.自定义Local对象
作用:为每个线程(协程)开辟一块空间进行数据存储(数据隔离)。
class Local(object):
def __init__(self):
object.__setattr__(self, 'storage', {})
def __setattr__(self, k, v):
ident = get_ident()
if ident in self.storage:
self.storage[ident][k] = v
else:
self.storage[ident] = {k: v}
def __getattr__(self, k):
ident = get_ident()
return self.storage[ident][k]
obj = Local()
def task(arg):
obj.val = arg
obj.xxx = arg
print(obj.val)
for i in range(10):
t = Thread(target=task, args=(i,))
t.start()
Flask中 blinker 是什么?
# flask中的信号blinker
信号主要是让开发者可是在flask请求过程中定制一些行为。
或者说flask在列表里面预留了几个空列表,在里面存东西。
简言之,信号允许某个'发送者'通知'接收者'有事情发生了
@ before_request有返回值,blinker没有返回值
# 10个信号
request_started = _signals.signal('request-started') #请求到来前执行
request_finished = _signals.signal('request-finished') #请求结束后执行
before_render_template = _signals.signal('before-render-template')#模板渲染前执行
template_rendered = _signals.signal('template-rendered')#模板渲染后执行
got_request_exception = _signals.signal('got-request-exception') #请求执行出现异常时执行
request_tearing_down = _signals.signal('request-tearing-down')#请求执行完毕后自动执行(无论成功与否)
appcontext_tearing_down = _signals.signal('appcontext-tearing-down')# 请求上下文执行完毕后自动执行(无论成功与否)
appcontext_pushed = _signals.signal('appcontext-pushed') #请求app上下文push时执行
appcontext_popped = _signals.signal('appcontext-popped') #请求上下文pop时执行
message_flashed = _signals.signal('message-flashed')#调用flask在其中添加数据时,自动触发
SQLAlchemy中的 session和scoped_session 的区别?
# Session:
由于无法提供线程共享功能,开发时要给每个线程都创建自己的session
打印sesion可知他是sqlalchemy.orm.session.Session的对象
# scoped_session:
为每个线程都创建一个session,实现支持线程安全
在整个程序运行的过程当中,只存在唯一的一个session对象。
创建方式:
通过本地线程Threading.Local()
# session=scoped_session(Session)
创建唯一标识的方法(参考flask请求源码)
SQLAlchemy如何执行原生SQL?
# 使用execute方法直接操作SQL语句(导入create_engin、sessionmaker)
engine=create_engine('mysql://root:*****@127.0.0.1/database?charset=utf8')
DB_Session = sessionmaker(bind=engine)
session = DB_Session()
session.execute('alter table mytablename drop column mycolumn ;')
ORM的实现原理?
# ORM的实现基于一下三点
映射类:描述数据库表结构,
映射文件:指定数据库表和映射类之间的关系
数据库配置文件:指定与数据库连接时需要的连接信息(数据库、登录用户名、密码or连接字符串)
DBUtils模块的作用?
# 数据库连接池
使用模式:
1、为每个线程创建一个连接,连接不可控,需要控制线程数
2、创建指定数量的连接在连接池,当线程访问的时候去取,不够了线程排队,直到有人释放(推荐)
---------------------------------------------------------------------------
两种写法:
1、用静态方法装饰器,通过直接执行类的方法来连接使用数据库
2、通过实例化对象,通过对象来调用方法执行语句
https://www.cnblogs.com/ArmoredTitan/p/Flask.html
以下SQLAlchemy的字段是否正确?如果不正确请更正:
fromdatetime importdatetime
fromsqlalchemy.ext.declarative
importdeclarative_base
fromsqlalchemy importColumn, Integer, String, DateTime
Base =declarative_base()
classUserInfo(Base):
__tablename__ ='userinfo'
id=Column(Integer, primary_key=True, autoincrement=True)
name =Column(String(64), unique=True)
ctime =Column(DateTime, default=datetime.now())
from datetime import datetime
from sqlalchemy.ext.declarative
import declarative_base
from sqlalchemy import Column, Integer, String, DateTime
Base = declarative_base()
class UserInfo(Base):
__tablename__ = 'userinfo'
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(64), unique=True)
ctime = Column(DateTime, default=datetime.now())
-----------------------------------------------------------------------
不正确:
Ctime字段中参数应为’default=datetime.now’
now 后面不应该加括号,加了的话,字段不会实时更新。
SQLAchemy中如何为表设置引擎和字符编码?
sqlalchemy设置编码字符集,一定要在数据库访问的URL上增加'charset=utf8'
否则数据库的连接就不是'utf8'的编码格式
eng=create_engine('mysql://root:root@localhost:3306/test2?charset=utf8',echo=True)
1. 设置引擎编码方式为utf8。
engine = create_engine("mysql+pymysql://root:123456@127.0.0.1:3306/sqldb01?charset=utf8")
2. 设置数据库表编码方式为utf8
class UserType(Base):
__tablename__ = 'usertype'
id = Column(Integer, primary_key=True)
caption = Column(String(50), default='管理员')
# 添加配置设置编码
__table_args__ = {
'mysql_charset':'utf8'
}
这样生成的SQL语句就自动设置数据表编码为utf8了,__table_args__还可设置存储引擎、外键约束等等信息。
SQLAchemy中如何设置联合唯一索引?
通过'UniqueConstraint'字段来设置联合唯一索引
__table_args=(UniqueConstraint('h_id','username',name='_h_username_uc'))
#h_id和username组成联合唯一约束
简述Tornado框架的特点。
异步非阻塞+websocket
简述Tornado框架中Future对象的作用?
# 实现异步非阻塞
视图函数yield一个futrue对象,futrue对象默认:
self._done = False ,请求未完成
self._result = None ,请求完成后返回值,用于传递给回调函数使用。
tornado就会一直去检测futrue对象的_done是否已经变成True。
如果IO请求执行完毕,自动会调用future的set_result方法:
self._result = result
self._done = True
参考:http://www.cnblogs.com/wupeiqi/p/6536518.html(自定义异步非阻塞web框架)
Tornado框架中如何编写WebSocket程序?
Tornado在websocket模块中提供了一个WebSocketHandler类。
这个类提供了和已连接的客户端通信的WebSocket事件和方法的钩子。
当一个新的WebSocket连接打开时,open方法被调用,
而on_message和on_close方法,分别在连接、接收到新的消息和客户端关闭时被调用。
此外,WebSocketHandler类还提供了write_message方法用于向客户端发送消息,close方法用于关闭连接。
Tornado中静态文件是如何处理的? 如: <link href="{{static_url("commons.css")}}" rel="stylesheet" />
# settings.py
settings = {
"static_path": os.path.join(os.path.dirname(__file__), "static"),
# 指定了静态文件的位置在当前目录中的"static"目录下
"cookie_secret": "61oETzKXQAGaYdkL5gEmGeJJFuYh7EQnp2XdTP1o/Vo=",
"login_url": "/login",
"xsrf_cookies": True,
}
经上面配置后
static_url()自动去配置的路径下找'commons.css'文件
Tornado操作MySQL使用的模块?
torndb
torndb是基于mysqldb的再封装,所以使用时要先安装myqldb
Tornado操作redis使用的模块?
tornado-redis
简述Tornado框架的适用场景?
web聊天室,在线投票
git常见命令作用:
# git init
初始化,当前所在的文件夹可以被管理且以后版本相关的数据都会存储到.git文件中
# git status
查看当前文件夹以及子目录中文件是否发生变化:
内容修改/新增文件/删除,已经变化的文件会变成红色,已经add的文件会变成绿色
# git add .
给发生变化的文件(贴上一个标签)或 将发生变化的文件放到某个地方,
只写一个句点符就代表把git status中红色的文件全部打上标签
# git commit -m
新增用户登录认证功能以及xxx功能将“绿色”文件添加到版本中
# git log
查看所有版本提交记录,可以获取版本号
# git reset --hard 版本号
将最新的版本回退到更早的版本
# git reflog
回退到之前版本后悔了,再更新到最新或者最新之前的版本
# git reset --hard 版本 回退
简述以下git中stash命令作用以及相关其他命令。
'git stash':将当前工作区所有修改过的内容存储到“某个地方”,将工作区还原到当前版本未修改过的状态
'git stash list':查看“某个地方”存储的所有记录
'git stash clear':清空“某个地方”
'git stash pop':将第一个记录从“某个地方”重新拿到工作区(可能有冲突)
'git stash apply':编号, 将指定编号记录从“某个地方”重新拿到工作区(可能有冲突)
'git stash drop':编号,删除指定编号的记录
git 中 merge 和 rebase命令 的区别。
merge:
会将不同分支的提交合并成一个新的节点,之前的提交分开显示,
注重历史信息、可以看出每个分支信息,基于时间点,遇到冲突,手动解决,再次提交
rebase:
将两个分支的提交结果融合成线性,不会产生新的节点;
注重开发过程,遇到冲突,手动解决,继续操作
公司如何基于git做的协同开发?
1、你们公司的代码review分支怎么做?谁来做?
答:组长创建review分支,我们小功能开发完之后,合并到review分支交给老大(小组长)来看,
1.1、你组长不开发代码吗?
他开发代码,但是它只开发核心的东西,任务比较少。
或者抽出时间,我们一起做这个事情
2、你们公司协同开发是怎么协同开发的?
每个人都有自己的分支,阶段性代码完成之后,合并到review,然后交给老大看
--------------------------------------------------------------------------
# 大致工作流程
公司:
下载代码
git clone https://gitee.com/wupeiqi/xianglong.git
或创建目录
cd 目录
git init
git remote add origin https://gitee.com/wupeiqi/xianglong.git
git pull origin maste
创建dev分支
git checkout dev
git pull origin dev
继续写代码
git add .
git commit -m '提交记录'
git push origin dev
回家:
拉代码:
git pull origin dev
继续写:
继续写代码
git add .
git commit -m '提交记录'
git push origin dev
如何基于git实现代码review?
https://blog.csdn.net/june_y/article/details/50817993
git如何实现v1.0 、v2.0 等版本的管理?
在命令行中,使用“git tag –a tagname –m “comment”可以快速创建一个标签。
需要注意,命令行创建的标签只存在本地Git库中,还需要使用Git push –tags指令发布到服务器的Git库中
什么是gitlab
gitlab是公司自己搭建的项目代码托管平台
github和gitlab的区别?
1、gitHub是一个面向开源及私有软件项目的托管平台
(创建私有的话,需要购买,最低级的付费为每月7刀,支持5个私有项目)
2、gitlab是公司自己搭建的项目托管平台
如何为github上牛逼的开源项目贡献代码?
1、fork需要协作项目
2、克隆/关联fork的项目到本地
3、新建分支(branch)并检出(checkout)新分支
4、在新分支上完成代码开发
5、开发完成后将你的代码合并到master分支
6、添加原作者的仓库地址作为一个新的仓库地址
7、合并原作者的master分支到你自己的master分支,用于和作者仓库代码同步
8、push你的本地仓库到GitHub
9、在Github上提交 pull requests
10、等待管理员(你需要贡献的开源项目管理员)处理
git中 .gitignore文件的作用
一般来说每个Git项目中都需要一个“.gitignore”文件,
这个文件的作用就是告诉Git哪些文件不需要添加到版本管理中。
实际项目中,很多文件都是不需要版本管理的,比如Python的.pyc文件和一些包含密码的配置文件等等。
什么是敏捷开发?
'敏捷开发':是一种以人为核心、迭代、循序渐进的开发方式。
它并不是一门技术,而是一种开发方式,也就是一种软件开发的流程。
它会指导我们用规定的环节去一步一步完成项目的开发。
因为它采用的是迭代式开发,所以这种开发方式的主要驱动核心是人
简述 jenkins 工具的作用?
'Jenkins'是一个可扩展的持续集成引擎。
主要用于:
持续、自动地构建/测试软件项目。
监控一些定时执行的任务。
公司如何实现代码发布?
简述 RabbitMQ、Kafka、ZeroMQ的区别?
https://blog.csdn.net/zhailihua/article/details/7899006
RabbitMQ如何在消费者获取任务后未处理完前就挂掉时,保证数据不丢失?
为了预防消息丢失,rabbitmq提供了ack
即工作进程在收到消息并处理后,发送ack给rabbitmq,告知rabbitmq这时候可以把该消息从队列中删除了。
如果工作进程挂掉 了,rabbitmq没有收到ack,那么会把该消息 重新分发给其他工作进程。
不需要设置timeout,即使该任务需要很长时间也可以处理。
ack默认是开启的,工作进程显示指定了no_ack=True
RabbitMQ如何对消息做持久化?
1、创建队列和发送消息时将设置durable=Ture,如果在接收到消息还没有存储时,消息也有可能丢失,就必须配置publisher confirm
channel.queue_declare(queue='task_queue', durable=True)
2、返回一个ack,进程收到消息并处理完任务后,发给rabbitmq一个ack表示任务已经完成,可以删除该任务
3、镜像队列:将queue镜像到cluster中其他的节点之上。
在该实现下,如果集群中的一个节点失效了,queue能自动地切换到镜像中的另一个节点以保证服务的可用性
RabbitMQ如何控制消息被消费的顺序?
默认消息队列里的数据是按照顺序被消费者拿走,
例如:消费者1 去队列中获取奇数序列的任务,消费者2去队列中获取偶数序列的任务。
channel.basic_qos(prefetch_count=1)
表示谁来谁取,不再按照奇偶数排列(同时也保证了公平的消费分发)
以下RabbitMQ的exchange type分别代表什么意思?如:fanout、direct、topic。
amqp协议中的核心思想就是生产者和消费者隔离,生产者从不直接将消息发送给队列。
生产者通常不知道是否一个消息会被发送到队列中,只是将消息发送到一个交换机。
先由Exchange来接收,然后Exchange按照特定的策略转发到Queue进行存储。
同理,消费者也是如此。Exchange 就类似于一个交换机,转发各个消息分发到相应的队列中。
--------------------------------------------------
type=fanout 类似发布者订阅者模式,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中
type=direct 队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
type=topic 队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,
则将数据发送到指定队列。
---------------------------------------------------
发送者路由值 队列中
old.boy.python old.* -- 不匹配 *表示匹配一个
old.boy.python old.# -- 匹配 #表示匹配0个或多个
简述 celery 是什么以及应用场景?
# Celery是由Python开发的一个简单、灵活、可靠的处理大量任务的分发系统, # 它不仅支持实时处理也支持任务调度。 # http://www.cnblogs.com/wupeiqi/articles/8796552.html
简述celery运行机制。

celery如何实现定时任务?
# celery实现定时任务
启用Celery的定时任务需要设置CELERYBEAT_SCHEDULE 。
CELERYBEAT_SCHEDULE='djcelery.schedulers.DatabaseScheduler'#定时任务
'创建定时任务'
# 通过配置CELERYBEAT_SCHEDULE:
#每30秒调用task.add
from datetime import timedelta
CELERYBEAT_SCHEDULE = {
'add-every-30-seconds': {
'task': 'tasks.add',
'schedule': timedelta(seconds=30),
'args': (16, 16)
},
}
简述 celery多任务结构目录
pro_cel
├── celery_tasks # celery相关文件夹
│ ├── celery.py # celery连接和配置相关文件
│ └── tasks.py # 所有任务函数
├── check_result.py # 检查结果
└── send_task.py # 触发任务
celery中装饰器 @app.task 和 @shared_task的区别?
# 一般情况使用的是从celeryapp中引入的app作为的装饰器:@app.task # django那种在app中定义的task则需要使用@shared_task
简述 requests模块的作用及基本使用?
# 作用:
使用requests可以模拟浏览器的请求
# 常用参数:
url、headers、cookies、data
json、params、proxy
# 常用返回值:
content
iter_content
text
encoding="utf-8"
cookie.get_dict()
简述 beautifulsoup模块的作用及基本使用?
# BeautifulSoup
用于从HTML或XML文件中提取、过滤想要的数据形式
#常用方法
解析:html.parser 或者 lxml(需要下载安装)
find、find_all、text、attrs、get
简述 seleninu模块的作用及基本使用?
Selenium是一个用于Web应用程序测试的工具,
他的测试直接运行在浏览器上,模拟真实用户,按照代码做出点击、输入、打开等操作
爬虫中使用他是为了解决requests无法解决javascript动态问题
scrapy框架中各组件的工作流程?
#1、生成初始的Requests来爬取第一个URLS,并且标识一个回调函数
第一个请求定义在start_requests()方法内默认从start_urls列表中获得url地址来生成Request请求,
默认的回调函数是parse方法。回调函数在下载完成返回response时自动触发
#2、在回调函数中,解析response并且返回值
返回值可以4种:
a、包含解析数据的字典
b、Item对象
c、新的Request对象(新的Requests也需要指定一个回调函数)
d、或者是可迭代对象(包含Items或Request)
#3、在回调函数中解析页面内容
通常使用Scrapy自带的Selectors,但很明显你也可以使用Beutifulsoup,lxml或其他你爱用啥用啥。
#4、最后,针对返回的Items对象将会被持久化到数据库
通过Item Pipeline组件存到数据库
或者导出到不同的文件(通过Feed exports)
http://www.cnblogs.com/wupeiqi/articles/6229292.html
在scrapy框架中如何设置代理(两种方法)?
方式一:内置添加代理功能
# -*- coding: utf-8 -*-
import os
import scrapy
from scrapy.http import Request
class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['chouti.com']
start_urls = ['https://dig.chouti.com/']
def start_requests(self):
os.environ['HTTP_PROXY'] = "http://192.168.11.11"
for url in self.start_urls:
yield Request(url=url,callback=self.parse)
def parse(self, response):
print(response)
方式二:自定义下载中间件
import random
import base64
import six
def to_bytes(text, encoding=None, errors='strict'):
"""Return the binary representation of `text`. If `text`
is already a bytes object, return it as-is."""
if isinstance(text, bytes):
return text
if not isinstance(text, six.string_types):
raise TypeError('to_bytes must receive a unicode, str or bytes '
'object, got %s' % type(text).__name__)
if encoding is None:
encoding = 'utf-8'
return text.encode(encoding, errors)
class MyProxyDownloaderMiddleware(object):
def process_request(self, request, spider):
proxy_list = [
{'ip_port': '111.11.228.75:80', 'user_pass': 'xxx:123'},
{'ip_port': '120.198.243.22:80', 'user_pass': ''},
{'ip_port': '111.8.60.9:8123', 'user_pass': ''},
{'ip_port': '101.71.27.120:80', 'user_pass': ''},
{'ip_port': '122.96.59.104:80', 'user_pass': ''},
{'ip_port': '122.224.249.122:8088', 'user_pass': ''},
]
proxy = random.choice(proxy_list)
if proxy['user_pass'] is not None:
request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
encoded_user_pass = base64.encodestring(to_bytes(proxy['user_pass']))
request.headers['Proxy-Authorization'] = to_bytes('Basic ' + encoded_user_pass)
else:
request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
配置:
DOWNLOADER_MIDDLEWARES = {
# 'xiaohan.middlewares.MyProxyDownloaderMiddleware': 543,
}
scrapy框架中如何实现大文件的下载?
from twisted.web.client import Agent, getPage, ResponseDone, PotentialDataLoss
from twisted.internet import defer, reactor, protocol
from twisted.web._newclient import Response
from io import BytesIO
class _ResponseReader(protocol.Protocol):
def __init__(self, finished, txresponse, file_name):
self._finished = finished
self._txresponse = txresponse
self._bytes_received = 0
self.f = open(file_name, mode='wb')
def dataReceived(self, bodyBytes):
self._bytes_received += len(bodyBytes)
# 一点一点的下载
self.f.write(bodyBytes)
self.f.flush()
def connectionLost(self, reason):
if self._finished.called:
return
if reason.check(ResponseDone):
# 下载完成
self._finished.callback((self._txresponse, 'success'))
elif reason.check(PotentialDataLoss):
# 下载部分
self._finished.callback((self._txresponse, 'partial'))
else:
# 下载异常
self._finished.errback(reason)
self.f.close()
scrapy中如何实现限速?
http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/autothrottle.html
scrapy中如何实现暂停爬虫?
# 有些情况下,例如爬取大的站点,我们希望能暂停爬取,之后再恢复运行。
# Scrapy通过如下工具支持这个功能:
一个把调度请求保存在磁盘的调度器
一个把访问请求保存在磁盘的副本过滤器[duplicates filter]
一个能持续保持爬虫状态(键/值对)的扩展
Job 路径
要启用持久化支持,你只需要通过 JOBDIR 设置 job directory 选项。
这个路径将会存储所有的请求数据来保持一个单独任务的状态(例如:一次spider爬取(a spider run))。
必须要注意的是,这个目录不允许被不同的spider 共享,甚至是同一个spider的不同jobs/runs也不行。
也就是说,这个目录就是存储一个 单独 job的状态信息。
scrapy中如何进行自定制命令?
在spiders同级创建任意目录,如:commands
在其中创建'crawlall.py'文件(此处文件名就是自定义的命令)
from scrapy.commands import ScrapyCommand
from scrapy.utils.project import get_project_settings
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return '[options]'
def short_desc(self):
return 'Runs all of the spiders'
def run(self, args, opts):
spider_list = self.crawler_process.spiders.list()
for name in spider_list:
self.crawler_process.crawl(name, **opts.__dict__)
self.crawler_process.start()
在'settings.py'中添加配置'COMMANDS_MODULE = '项目名称.目录名称''
在项目目录执行命令:'scrapy crawlall'
scrapy中如何实现的记录爬虫的深度?
'DepthMiddleware'是一个用于追踪每个Request在被爬取的网站的深度的中间件。
其可以用来限制爬取深度的最大深度或类似的事情。
'DepthMiddleware'可以通过下列设置进行配置(更多内容请参考设置文档):
'DEPTH_LIMIT':爬取所允许的最大深度,如果为0,则没有限制。
'DEPTH_STATS':是否收集爬取状态。
'DEPTH_PRIORITY':是否根据其深度对requet安排优先
scrapy中的pipelines工作原理?
Scrapy 提供了 pipeline 模块来执行保存数据的操作。
在创建的 Scrapy 项目中自动创建了一个 pipeline.py 文件,同时创建了一个默认的 Pipeline 类。
我们可以根据需要自定义 Pipeline 类,然后在 settings.py 文件中进行配置即可
scrapy的pipelines如何丢弃一个item对象?
通过raise DropItem()方法
简述scrapy中爬虫中间件和下载中间件的作用?1
http://www.cnblogs.com/wupeiqi/articles/6229292.html
scrapy-redis组件的作用?
实现了分布式爬虫,url去重、调度器、数据持久化
'scheduler'调度器
'dupefilter'URL去重规则(被调度器使用)
'pipeline'数据持久化
scrapy-redis组件中如何实现的任务的去重?
a. 内部进行配置,连接Redis
b.去重规则通过redis的集合完成,集合的Key为:
key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())}
默认配置:
DUPEFILTER_KEY = 'dupefilter:%(timestamp)s'
c.去重规则中将url转换成唯一标示,然后在redis中检查是否已经在集合中存在
from scrapy.utils import request
from scrapy.http import Request
req = Request(url='http://www.cnblogs.com/wupeiqi.html')
result = request.request_fingerprint(req)
print(result) # 8ea4fd67887449313ccc12e5b6b92510cc53675c
scrapy和scrapy-redis的去重规则(源码)
1. scrapy中去重规则是如何实现?
class RFPDupeFilter(BaseDupeFilter):
"""Request Fingerprint duplicates filter"""
def __init__(self, path=None, debug=False):
self.fingerprints = set()
@classmethod
def from_settings(cls, settings):
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(job_dir(settings), debug)
def request_seen(self, request):
# 将request对象转换成唯一标识。
fp = self.request_fingerprint(request)
# 判断在集合中是否存在,如果存在则返回True,表示已经访问过。
if fp in self.fingerprints:
return True
# 之前未访问过,将url添加到访问记录中。
self.fingerprints.add(fp)
def request_fingerprint(self, request):
return request_fingerprint(request)
2. scrapy-redis中去重规则是如何实现?
class RFPDupeFilter(BaseDupeFilter):
"""Redis-based request duplicates filter.
This class can also be used with default Scrapy's scheduler.
"""
logger = logger
def __init__(self, server, key, debug=False):
# self.server = redis连接
self.server = server
# self.key = dupefilter:123912873234
self.key = key
@classmethod
def from_settings(cls, settings):
# 读取配置,连接redis
server = get_redis_from_settings(settings)
# key = dupefilter:123912873234
key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())}
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(server, key=key, debug=debug)
@classmethod
def from_crawler(cls, crawler):
return cls.from_settings(crawler.settings)
def request_seen(self, request):
fp = self.request_fingerprint(request)
# This returns the number of values added, zero if already exists.
# self.server=redis连接
# 添加到redis集合中:1,添加工程;0,已经存在
added = self.server.sadd(self.key, fp)
return added == 0
def request_fingerprint(self, request):
return request_fingerprint(request)
def close(self, reason=''):
self.clear()
def clear(self):
"""Clears fingerprints data."""
self.server.delete(self.key)
scrapy-redis的调度器如何实现任务的深度优先和广度优先?
https://www.cnblogs.com/pupilheart/articles/9851936.html
https://www.cnblogs.com/pupilheart/articles/9851964.html
分布式爬虫的更新中。。。
简述 vitualenv 及应用场景?
'vitualenv'是一个独立的python虚拟环境
如:
当前项目依赖的是一个版本,但是另一个项目依赖的是另一个版本,这样就会造成依赖冲突,
而virtualenv就是解决这种情况的,virtualenv通过创建一个虚拟化的python运行环境,
将我们所需的依赖安装进去的,不同项目之间相互不干扰
简述 pipreqs 及应用场景?
可以通过对项目目录扫描,自动发现使用了那些类库,并且自动生成依赖清单。
pipreqs ./ 生成requirements.txt
在Python中使用过什么代码检查工具?
1)PyFlakes:静态检查Python代码逻辑错误的工具。
2)Pep8: 静态检查PEP8编码风格的工具。
3)NedBatchelder’s McCabe script:静态分析Python代码复杂度的工具。
Python代码分析工具:PyChecker、Pylint
简述 saltstack、ansible、fabric、puppet工具的作用?
B Tree和B+ Tree的区别?
1.B树中同一键值不会出现多次,并且有可能出现在叶结点,也有可能出现在非叶结点中。
而B+树的键一定会出现在叶结点中,并有可能在非叶结点中重复出现,以维持B+树的平衡。
2.因为B树键位置不定,且在整个树结构中只出现一次,
请列举常见排序并通过代码实现任意三种。
冒泡/选择/插入/快排
https://www.cnblogs.com/Liqiongyu/p/5911613.html
http://www.cnblogs.com/feixuelove1009/p/6143539.html
请列举常见查找并通过代码实现任意三种。
请列举你熟悉的设计模式?
工厂模式/单例模式等
有没有刷过leetcode?
leetcode是个题库,里面有多很编程题目,可以在线编译运行。
https://leetcode-cn.com/problemset/all/
列举熟悉的的Linux命令。
1创建目录
mkdir /data
cd /
mkdir data
2:查看目录
ls
ls -l 显示详细信息
公司线上服务器是什么系统?
Linux/Centos
解释 PV、UV 的含义?
PV访问量(Page View),即页面访问量,每打开一次页面PV计数+1,刷新页面也是。
UV访问数(Unique Visitor)指独立访客访问数,一台电脑终端为一个访客。
解释 QPS的含义?
'QPS(Query Per Second)'
每秒查询率,是对一个特定的查询服务器在规定时间内所处理流量多少的衡量标准
uwsgi和wsgi的区别?
wsgi是一种通用的接口标准或者接口协议,实现了python web程序与服务器之间交互的通用性。
uwsgi:同WSGI一样是一种通信协议
uwsgi协议是一个'uWSGI服务器'自有的协议,它用于定义传输信息的类型,
'uWSGI'是实现了uwsgi和WSGI两种协议的Web服务器,负责响应python的web请求。
supervisor的作用?
# Supervisor:
是一款基于Python的进程管理工具,可以很方便的管理服务器上部署的应用程序。
是C/S模型的程序,其服务端是supervisord服务,客户端是supervisorctl命令
# 主要功能:
1 启动、重启、关闭包括但不限于python进程。
2 查看进程的运行状态。
3 批量维护多个进程。
什么是反向代理?
正向代理代理客户端(客户端找哟个代理去访问服务器,服务器不知道你的真实IP)
反向代理代理服务器(服务器找一个代理给你响应,你不知道服务器的真实IP)
简述SSH的整个过程。
SSH 为 'Secure Shell' 的缩写,是建立在应用层基础上的安全协议。
SSH 是目前较可靠,为远程登录会话和其他网络服务提供的安全性协议。
利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。
有问题都去那些找解决方案?
起初是百度,发现搜到的答案不精准,净广告
转战谷歌,但墙了;捣鼓怎么FQ
还会去知乎、stackoverfloow、必应、思否(segmentfault)
是否有关注什么技术类的公众号?
python之禅(主要专注Python相关知识,作者:刘志军)
码农翻身(主要是Java的,但不光是java,涵盖面很广,作者:刘欣)
实验楼(在线练项目)
and so on
最近在研究什么新技术?
Numpy
pandas(金融量化分析、聚宽)
百度AI
图灵API
智能玩具
是否了解过领域驱动模型?
Domain-Driven Design
二进制与十进制之间的转换
1、十进制 与 二进制之间的转换
(1)、十进制转换为二进制,分为整数部分和小数部分
整数部分
方法:除2取余法,即每次将整数部分除以2,余数为该位权上的数,而商继续除以2,余数又为上一个位权上的数。
这个步骤一直持续下去,直到商为0为止,最后读数时候,从最后一个余数读起,一直到最前面的一个余数。下面举例:
例:将十进制的168转换为二进制
得出结果 将十进制的168转换为二进制,(10101000)2
168 / 2 = 84 -- 0
84 / 2 = 42 -- 0
42 / 2 = 21 -- 0
21 / 2 = 10 -- 1
10 / 2 = 5 -- 0
5 / 2 = 2 -- 1
2 / 2 = 1 -- 0
1 / 2 = 0 -- 1
二进制(从后往前读): 10101000
小数部分
方法:乘2取整法,即将小数部分乘以2,然后取整数部分,剩下的小数部分继续乘以2,然后取整数部分,
剩下的小数部分又乘以2,一直取到小数部分为零为止。如果永远不能为零,就同十进制数的四舍五入一样,
按照要求保留多少位小数时,就根据后面一位是0还是1,取舍,如果是零,舍掉,如果是1,向入一位。
换句话说就是0舍1入。读数要从前面的整数读到后面的整数
小数部分二进制转换为十进制 (不分整数和小数部分)
方法:按权相加法,即将二进制每位上的数乘以权,然后相加之和即是十进制数。
例:将二进制数101.101转换为十进制数。
得出结果:(101.101)2=(5.625)10
在做二进制转换成十进制需要注意的是
1)要知道二进制每位的权值
2)要能求出每位的值 101.101 转换为十进制
整数部分:2^2 + 2^0 = 5
小数部分:2^(-1) + 2^(-3) = 1/2 + 1/8 = 0.5 + 0.125 = 0.625
十进制: 2^2 + 2^0 + 2^(-1) + 2^(-3) = 5.625
