DRF频率、分页、解析器、渲染器
DRF的频率
频率限制是做什么的
开放平台的API接口调用需要限制其频率,以节约服务器资源和避免恶意的频繁调用。
频率组件原理
DRF中的频率控制基本原理是基于访问次数和时间的,当然我们可以通过自己定义的方法来实现。
当我们请求进来,走到我们频率组件的时候,DRF内部会有一个字典来记录访问者的IP,
以这个访问者的IP为key,value为一个列表,存放访问者每次访问的时间,
{
IP1: [第三次访问时间,第二次访问时间,第一次访问时间],
IP2: [第三次访问时间,第二次访问时间,第一次访问时间],
}
把每次访问最新时间放入列表的最前面,记录成这样的一个数据结构
如果我们设置的是10秒内只能访问5次,
-- 1,判断访问者的IP是否在这个请求IP的字典里
-- 2,保证这个列表里都是最近10秒内的访问的时间
判断当前请求时间和列表里最早的(也就是最后的)请求时间的差值
如果差大于10秒,说明请求以及不是最近10秒内的,删除(最早的)最后一个时间,
继续判断倒数第二个,直到差值小于10秒
-- 3,判断列表的长度(即访问次数),是否大于我们设置的5次,
如果大于就限流,否则放行,并把时间放入列表的最前面。
频率组件源码
频率组件提供的几大类:

我们以继承下面这个类为例:



from django.conf.urls import url, include from django.contrib import admin urlpatterns = [ url(r'^admin/', admin.site.urls), url(r'^book/', include("SerDemo.urls")), url(r'^api/user/', include("AuthDemo.urls")), url(r'^api/throttle/', include("Throttle.urls")), url(r'^api/pagination/', include("Pagenation.urls")), url(r'^api/(?P<version>[v1|v2]+)/', include("VersionDemo.urls")), ]
from django.conf.urls import url, include from django.contrib import admin from .views import TestView urlpatterns = [ url(r'^test', TestView.as_view()), ]
from django.shortcuts import render from rest_framework.views import APIView from rest_framework.response import Response from utils.throttle import MyThrottle, MyVisit # Create your views here. class TestView(APIView): throttle_classes = [MyVisit, ] def get(self, request): return Response("频率测试接口")
# 以IP地址做限流 # 1 获取访问者的IP地址 # 2 访问列表 {IP: [time2, time1]} # 3 判断IP是否在我们的访问列表里 # 4 如果不在 第一次访问 给访问列表加入IP:[now] # 5 如果在 把now放入IP:[now, time2, time1] # 6 确保列表里最近的访问时间以及最远的访问时间差在限制时间范围内 # 7 判断列表长度是否是限制次数之内 from rest_framework import throttling import time # [now, 5, 4, 3, 2, old] # 自定义60秒访问3次 class MyThrottle(throttling.BaseThrottle): VisitRecord = {} def __init__(self): self.history = "" def allow_request(self, request, view): # 做频率限流 ip = request.META.get("REMOTE_ADDR") now = time.time() if ip not in self.VisitRecord: self.VisitRecord[ip] = [now,] return True history = self.VisitRecord.get(ip) # self.history = self.cache.get(self.key, []) history.insert(0, now) self.history = history while history and history[0] - history[-1] > 60: history.pop() if len(history) > 3: return False else: return True def wait(self): # 还要等多久才能访问 # old + 60 - now return self.history[-1] + 60 - self.history[0] #继承SimpleRateThrottle class MyVisit(throttling.SimpleRateThrottle): scope = "WD" def get_cache_key(self, request, view): # 返回值应该IP return self.get_ident(request)
DRF之分页
LimitOffsetPagination
从当前位置向后找几个
看第n页,每页显示默认设置的数据数量 --> http://127.0.0.1:8000/book/?page=1
看第n页,每页显示n条数据 --> http://127.0.0.1:8000/book/?page=2&size=4
1. 分页类 class MyPagination(pagination.PageNumberPagination): # 每页显示的数量 page_size = 2 # 每页显示的最大数量 max_page_size = 5 # 搜索的参数关键字,即 ? page_query_param = 'page' # 控制每页显示数量的关键字 page_size_query_param = 'size' 2. 在自定义视图中使用分页 class BookView(APIView): def get(self, request): queryset = Book.objects.all() # 1.实例化分页器对象 paginator = MyPagination() # 2.调用这个分页器类的分页方法,拿到分页后的数据 page_queryset = paginator.paginate_queryset(queryset, request) # 3.把分页好的数据拿去序列化 ser_obj = BookSerializer(page_queryset, many=True) # 这样返回数据,可以在浏览器输入size参数设置每页显示的数据 # return Response(ser_obj.data) # 调用分页器的get_paginated_response方法 返回带上一页下一页的数据 # 使用这个方法后不能在浏览器输入size参数设置每页显示的数据了 return paginator.get_paginated_response(ser_obj.data) 3. 在DRF的提供的视图中使用分页 class BookView(generics.GenericAPIView, mixins.ListModelMixin): queryset = Book.objects.all() serializer_class = BookSerializer # 配置分页器类 pagination_class = MyPagination def get(self, request): return self.list(request)
LimitOffsetPagination
从当前位置向后找几个
从0开始取两条数据(1、2) --> http://127.0.0.1:8000/api/pagination/book/?limit=2
从第二条数据开始取两条数据(3、4) --> http://127.0.0.1:8000/api/pagination/book/?limit=2&offset=2
class MyPagination(pagination.LimitOffsetPagination): # 从哪里开始拿数据 offset_query_param = 'offset' # 拿多少条数据 limit_query_param = 'limit' # 默认拿多少条数据 default_limit = 2 # 最多拿多少条 max_limit = 5
CursorPagination分页类
-- 游标加密
-- 只能读上一页以及下一页
-- 记录每次的最大id以及最小id
按xx的顺序(倒序)显示xx条数据 --> http://127.0.0.1:8000/api/pagination/book/ 上一页下一页是的值是随机字符串,每页显示3条数据 --> http://127.0.0.1:8000/api/pagination/book/?cursor=cD01&size=3
class MyPagination(pagination.CursorPagination): cursor_query_param = 'cursor' # 每页显示的数量的搜索关键字 page_size_query_param = 'size' # 每页显示的数据数量 page_size = 3 # 每页最大显示的数据数量 max_page_size = 5 # 按id的倒序显示 ordering = '-id'
解析器
解析器的作用就是服务端接收客户端传过来的数据,把数据解析成自己想要的数据类型的过程。
本质就是对请求体中的数据进行解析。
Django的解析器
请求进来的时候,请求体中的数据在request.body中,说明,解析器会把解析好的数据放入request.body,
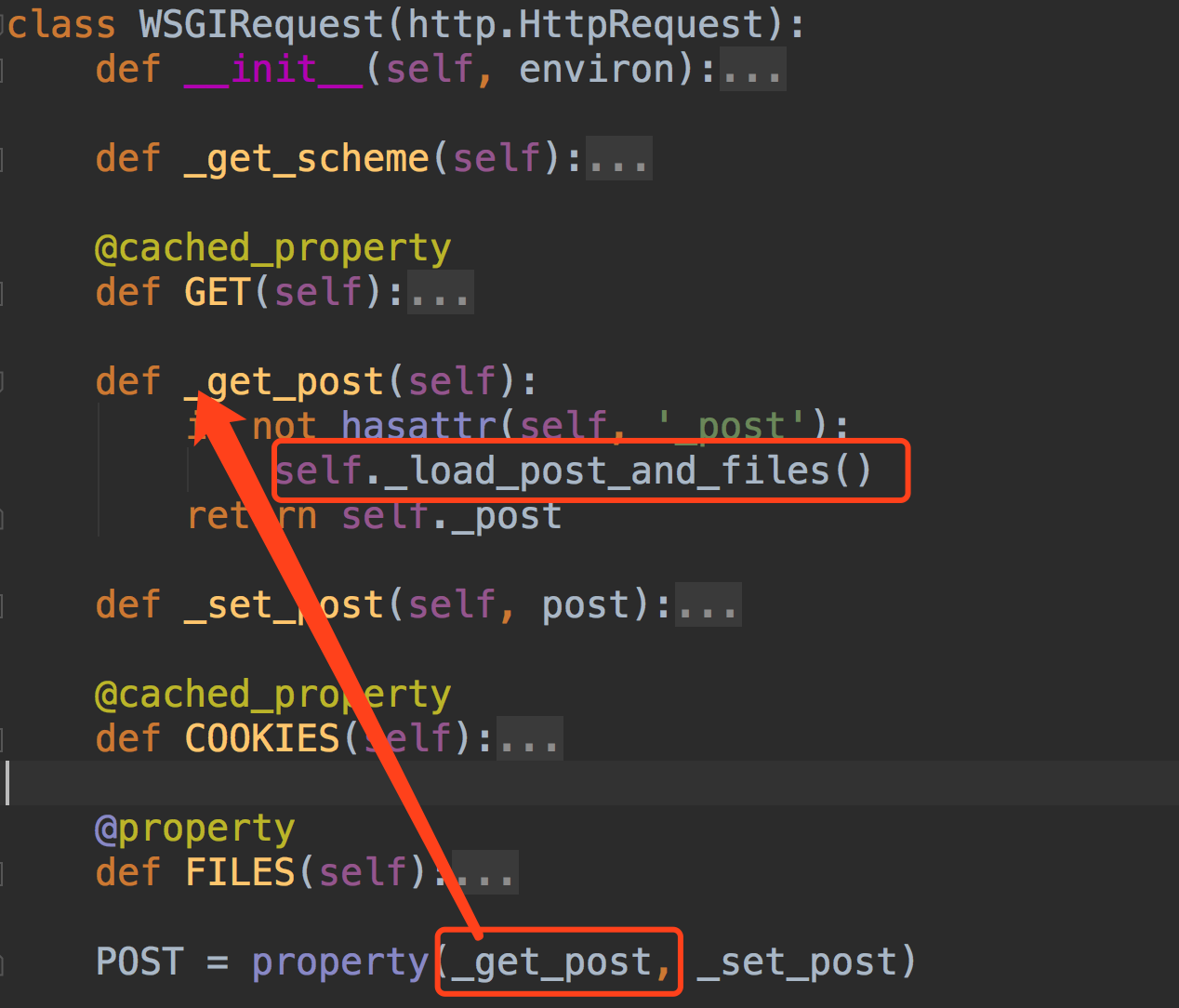
我们在视图中可以打印request的类型,就能够发现request是WSGIRequest这个类。
那我们是怎么拿到request.POST数据的?
我们请求进来请求体中的数据在request.body中,那也就证明,解析器会把解析好的数据放入request.body
我们在视图中可以打印request的类型,能够知道request是WSGIRequest这个类。
我们可以看下这个类的源码~~~我们是怎么拿到request.POST数据的~~
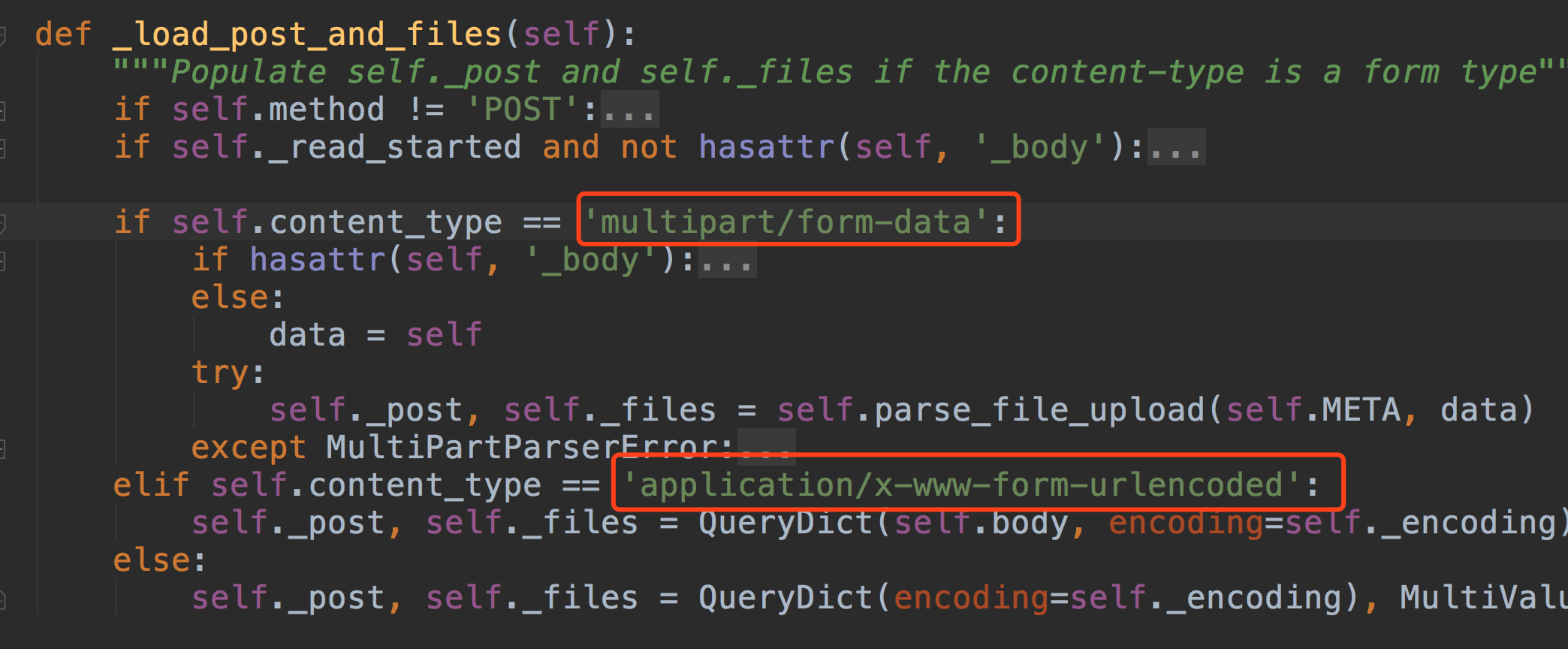
application/x-www-form-urlencoded不是不能上传文件,是只能上传文本格式的文件,
multipart/form-data是将文件以二进制的形式上传,这样可以实现多种类型的文件上传
一个解析到request.POST, request.FILES中。
也就是说我们之前能在request中能到的各种数据是因为用了不同格式的数据解析器~
那么我们的DRF能够解析什么样的数据类型呢~~~
DRF的解析器
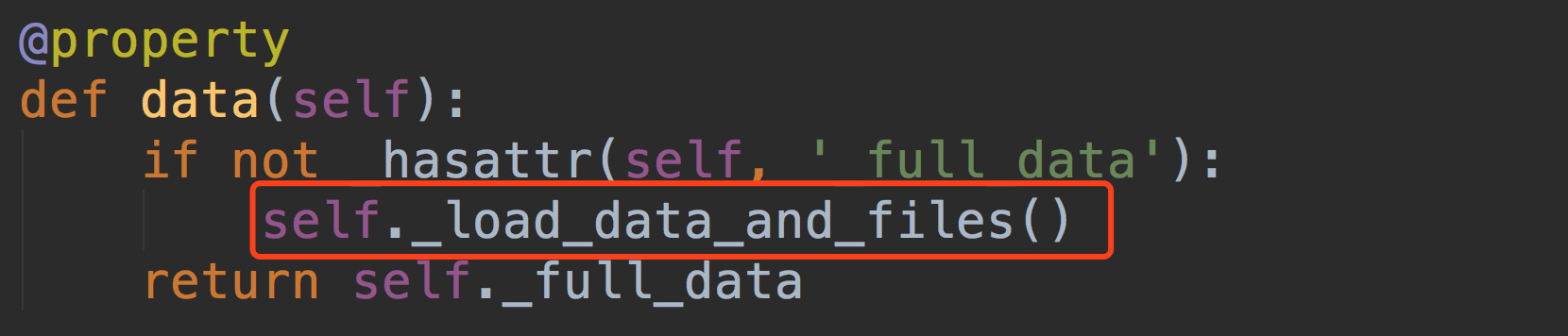
我们想一个问题~什么时候我们的解析器会被调用呢~~ 是不是在request.data拿数据的时候~
我们说请求数据都在request.data中,那我们看下这个Request类里的data~~
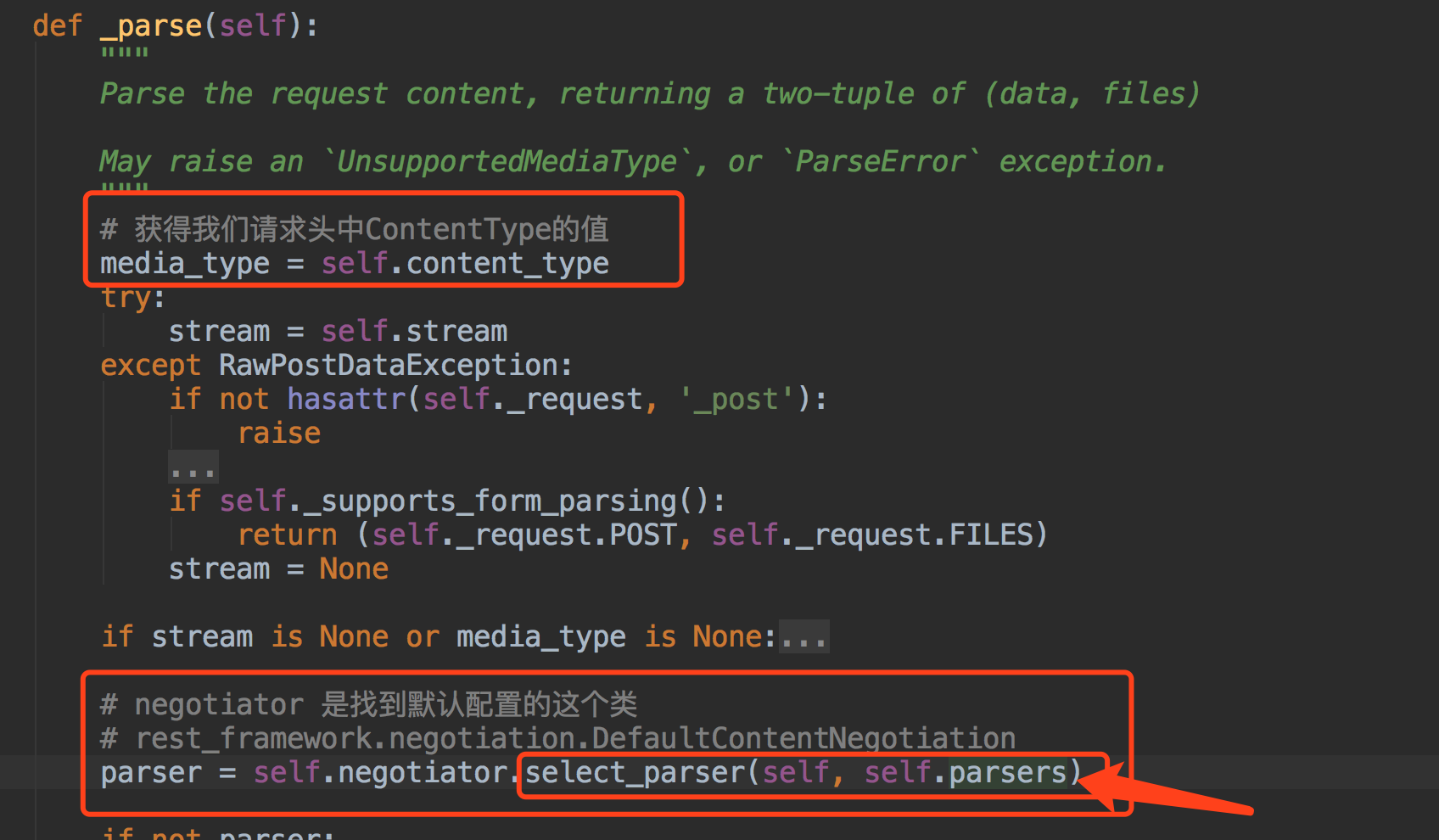
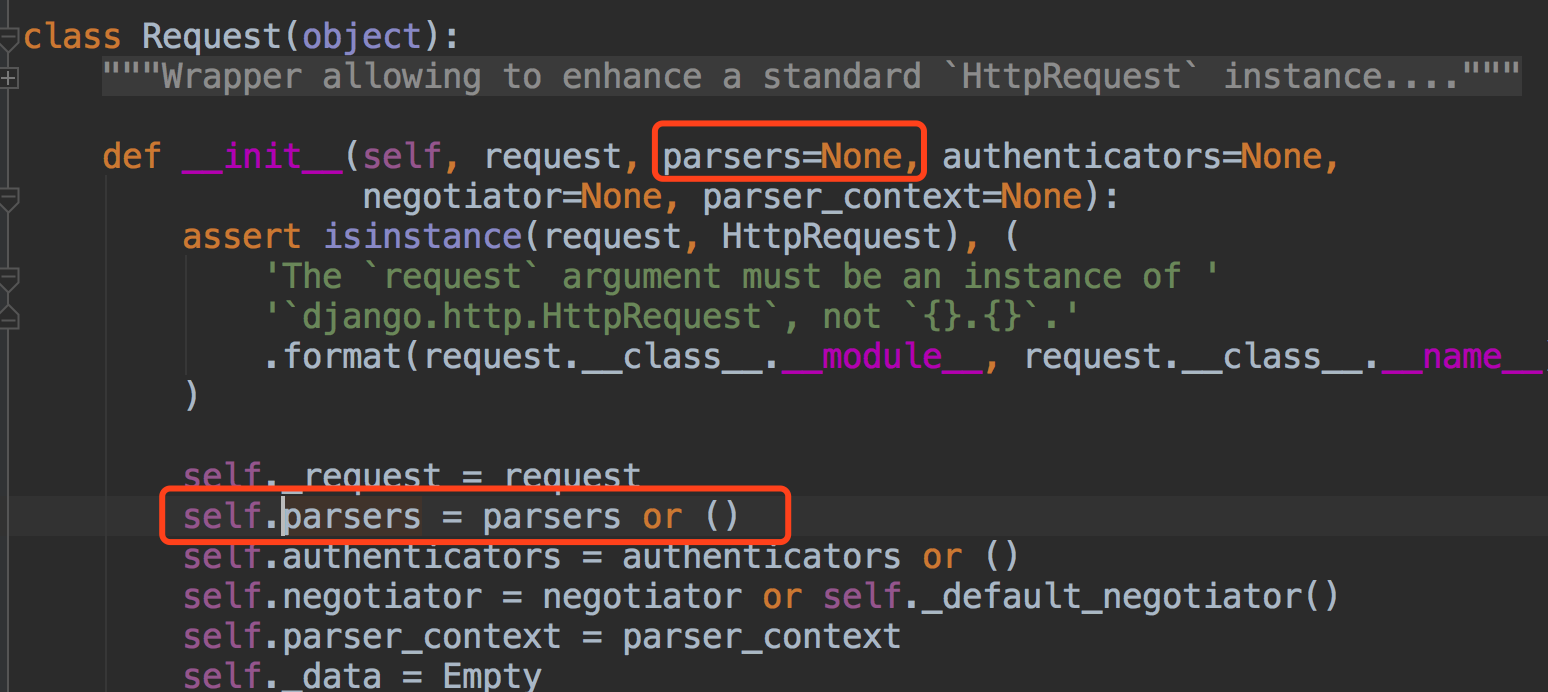
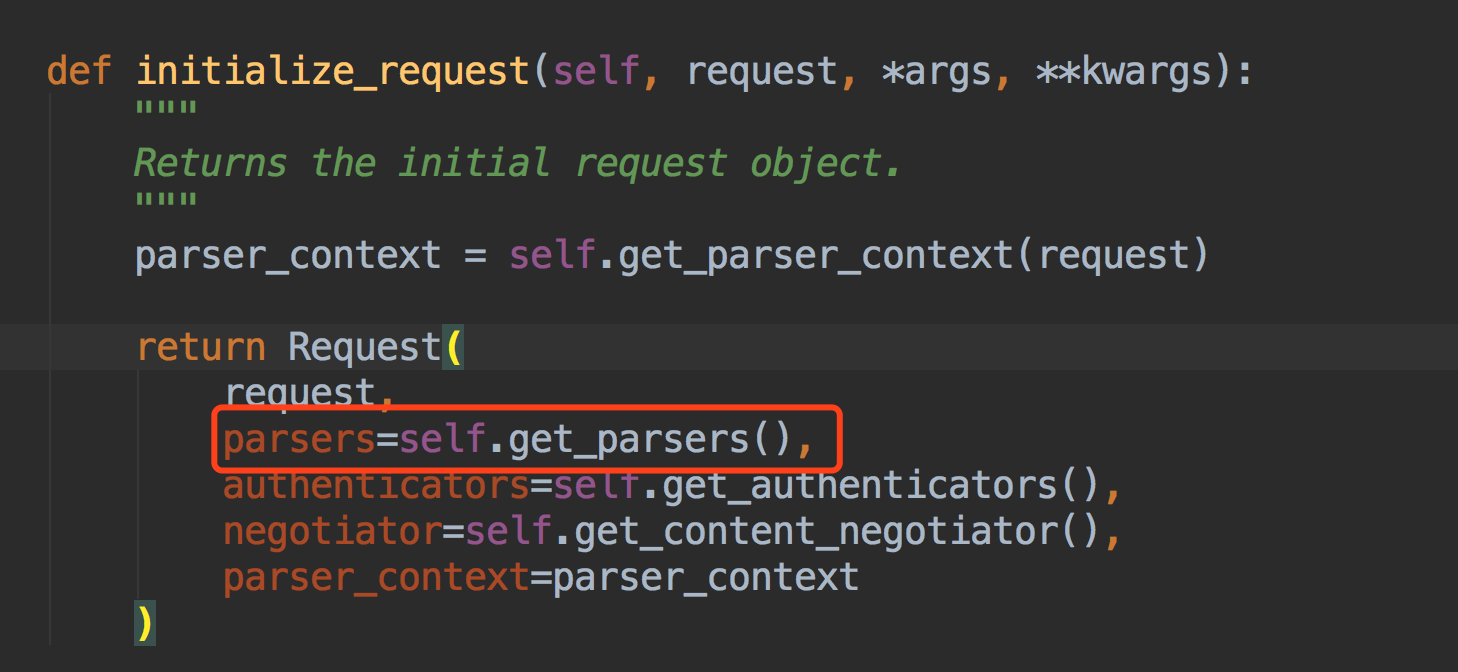
得到解析器后,调用解析器里的parse方法~~
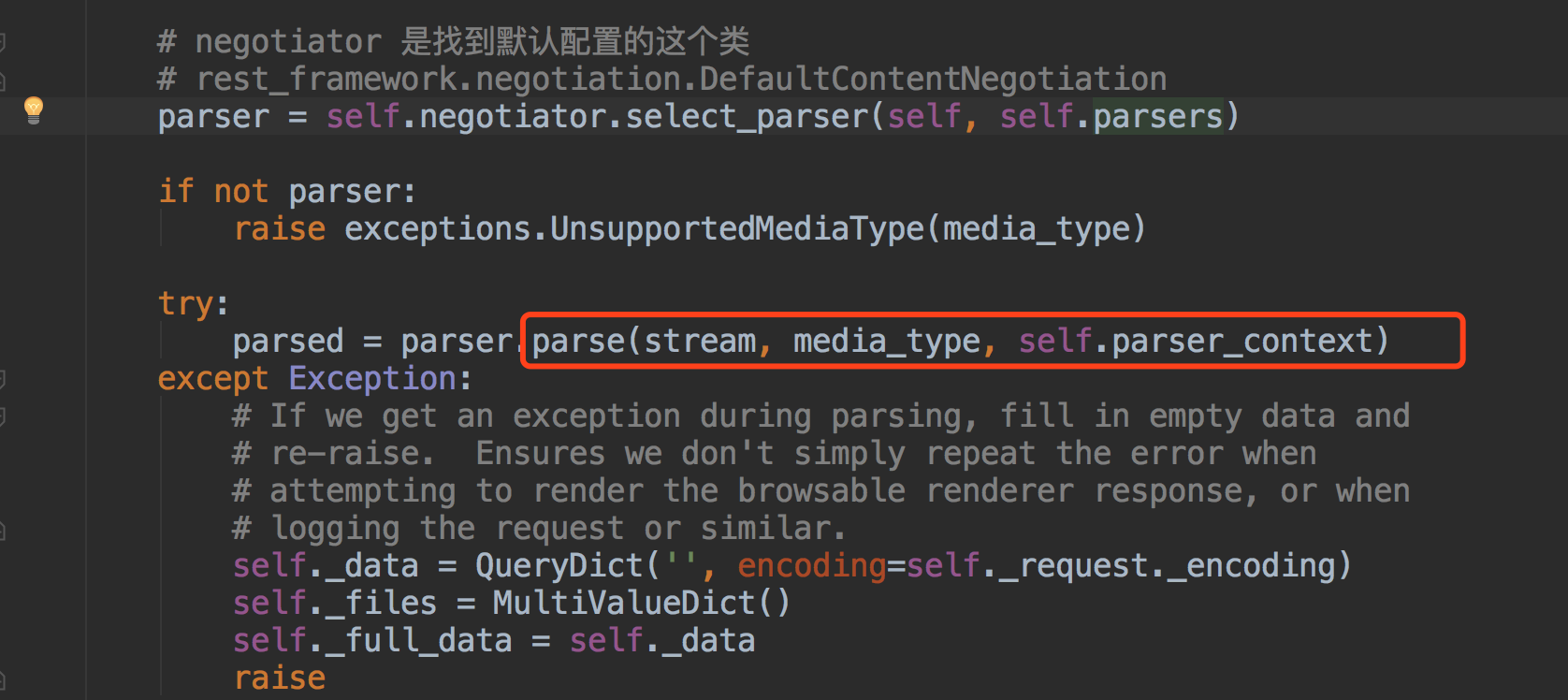
那说到这里~我们看下DRF配置的默认的解析器的类都有哪些~~
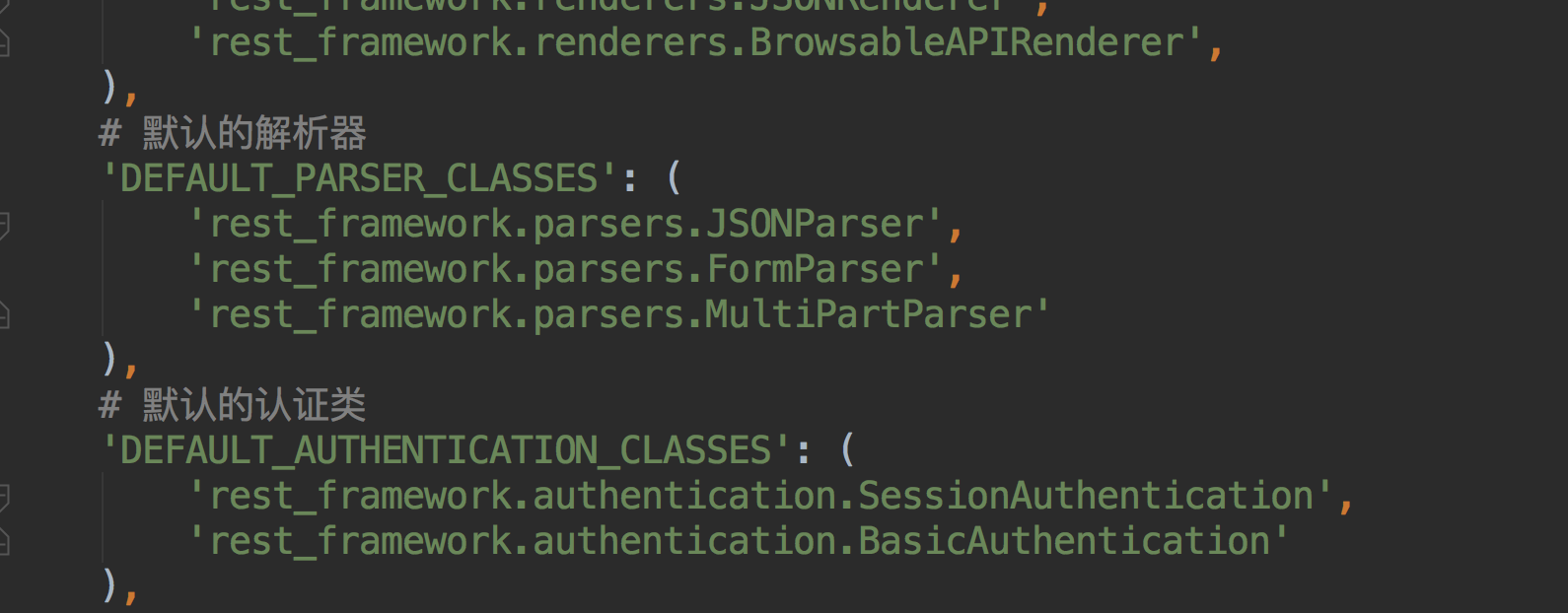
也就是说我们的DRF支持Json,Form表单的请求,包括多种文件类型的数据~~~~
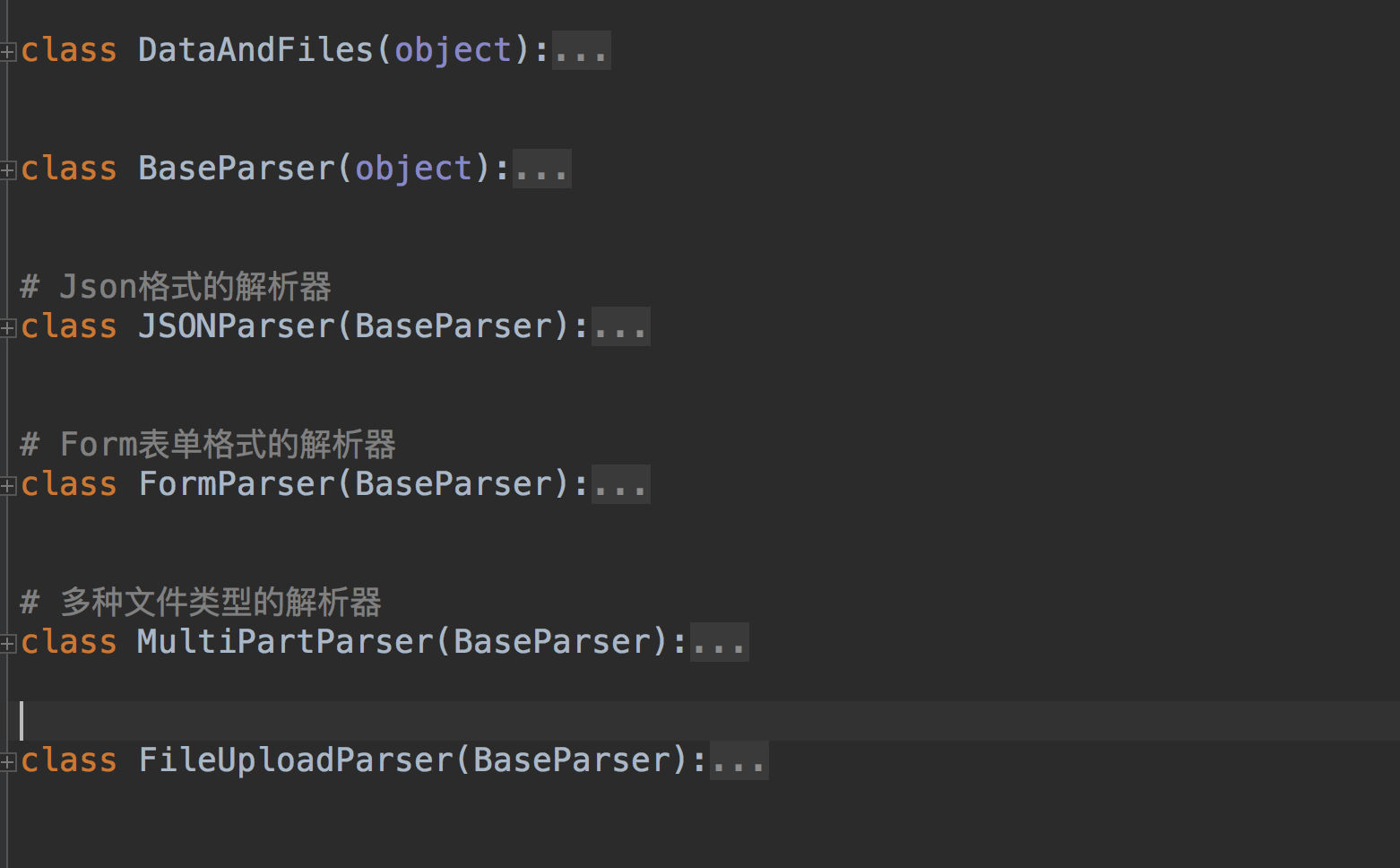
可以在我们的视图中配置视图级别的解析器~~~

原理:
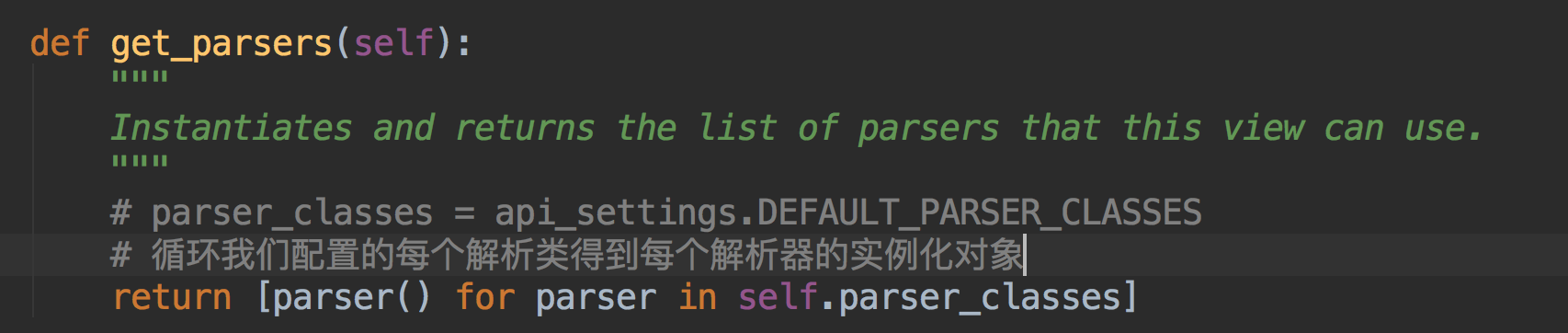
拿到我们配置的所有的解析器类的实例化对象
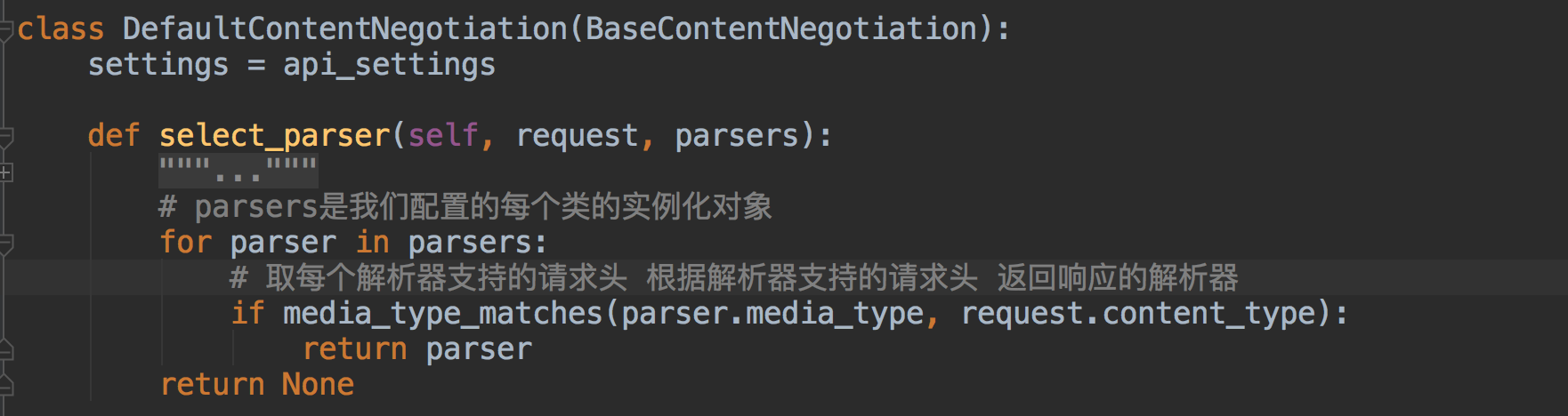
通过ContentType跟解析器的media_type进行匹配
匹配成功把解析器类实例化对象返回
调用解析器类的parse方法去解析数据
把解析好的数据返回
DRF的渲染器
渲染器就是友好的展示数据~~
DRF给我们提供的渲染器有~~
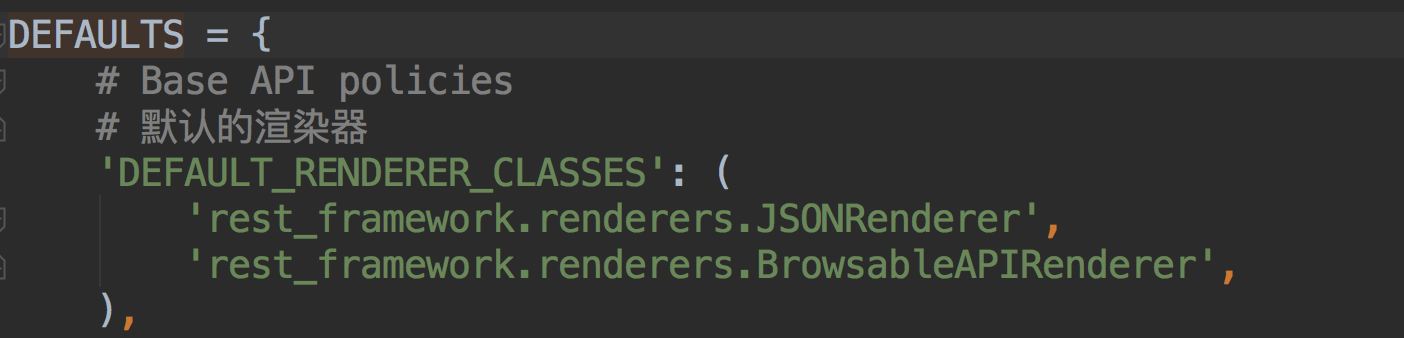
我们在浏览器中展示的DRF测试的那个页面~就是通过浏览器的渲染器来做到的~~
当然我们可以展示Json数据类型~~~~渲染器比较简单~~~~
