
一、local
在多个线程之间使用threading.local对象,可以实现多个线程之间的数据隔离
import time
import random
from threading import Thread,local
loc = local()
def func1():
global loc
print(loc.name,loc.age)
def func2(name,age):
global loc
loc.name = name
loc.age = age
time.sleep(random.uniform(0,2))
func1()
Thread(target=func2,args=('明哥',19)).start()
Thread(target=func2,args=('小弟',17)).start()
结果:
小弟 17
明哥 19
解释:
在平时的线程中,应该每次打印的结果应该都是最后进来的线程的数据,即第一次的数据会被第二次的数据覆盖,
但是使用了local对象,可以实现线程的数据隔离,因此打印的两次结果都不一样。
原理:
local对象会创建一个大字典,字典的键是线程的id,值也是一个字典,存储数据,例如:
{
线程id1:{'name':'明哥',age:19}
线程id2:{'name':'小弟',age:17}
...
}
二、
1、阻塞IO(blocking IO)
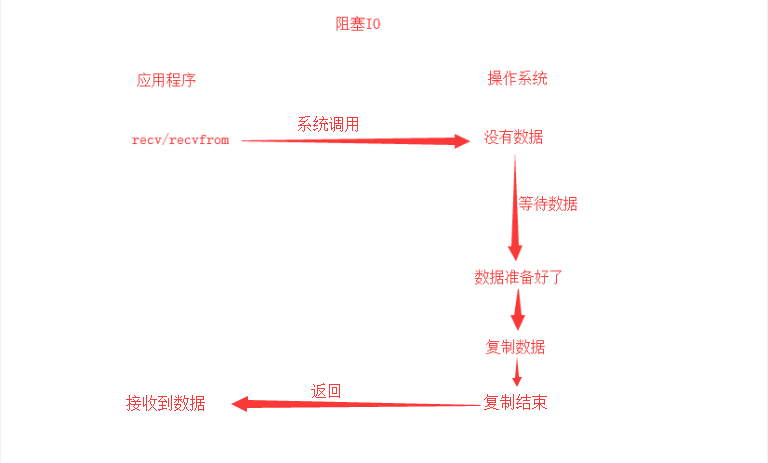 当用户进程调用了recv/recvfrom这些系统调用时,操作系统就开始了IO的第一个阶段:准备数据。因为很多时候数据一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候操作系统就要等待足够的数据到来。
而在用户进程这边,整个进程会被阻塞。操作系统一直等到数据准备好了,它就会将数据拷贝到用户内存,然后返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段(等待数据和拷贝数据两个阶段)都被block了。
几乎所有的程序员第一次接触到的网络编程都是从listen()、send()、recv() 等接口开始的,使用这些接口可以很方便的构建服务器/客户机的模型。然而大部分的socket接口都是阻塞型的。
阻塞型接口是指系统调用(一般是IO接口)不返回调用结果并让当前线程一直阻塞,只有当该系统调用获得结果或者超时出错时才返回。
实际上,除非特别指定,几乎所有的IO接口 ( 包括socket接口 ) 都是阻塞型的。这给网络编程带来了一个很大的问题,如在调用recv(1024)的同时,线程将被阻塞,在此期间,线程将无法执行任何运算或响应任何的网络请求。
解决方案:
在服务器端使用多线程(或多进程)。多线程(或多进程)的目的是让每个连接都拥有独立的线程(或进程),这样任何一个连接的阻塞都不会影响其他的连接。
该方案的问题是:
开启多进程或都线程的方式,在遇到要同时响应成百上千路的连接请求,则无论多线程还是多进程都会严重占据系统资源,降低系统对外界响应效率,而且线程与进程本身也更容易进入假死状态。
改进方案:
很多程序员可能会考虑使用“线程池”或“连接池”。“线程池”旨在减少创建和销毁线程的频率,其维持一定合理数量的线程,并让空闲的线程重新承担新的执行任务。“连接池”维持连接的缓存池,尽量重用已有的连接、减少创建和关闭连接的频率。这两种技术都可以很好的降低系统开销,都被广泛应用很多大型系统,如websphere、tomcat和各种数据库等。
改进后方案其实也存在着问题:
“线程池”和“连接池”技术也只是在一定程度上缓解了频繁调用IO接口带来的资源占用。而且,所谓“池”始终有其上限,当请求大大超过上限时,“池”构成的系统对外界的响应并不比没有池的时候效果好多少。所以使用“池”必须考虑其面临的响应规模,并根据响应规模调整“池”的大小。
对应上例中的所面临的可能同时出现的上千甚至上万次的客户端请求,“线程池”或“连接池”或许可以缓解部分压力,但是不能解决所有问题。总之,多线程模型可以方便高效的解决小规模的服务请求,但面对大规模的服务请求,多线程模型也会遇到瓶颈,可以用非阻塞接口来尝试解决这个问题。
2、非阻塞IO
当用户进程调用了recv/recvfrom这些系统调用时,操作系统就开始了IO的第一个阶段:准备数据。因为很多时候数据一开始还没有到达(比如,还没有收到一个完整的UDP包),这个时候操作系统就要等待足够的数据到来。
而在用户进程这边,整个进程会被阻塞。操作系统一直等到数据准备好了,它就会将数据拷贝到用户内存,然后返回结果,用户进程才解除block的状态,重新运行起来。
所以,blocking IO的特点就是在IO执行的两个阶段(等待数据和拷贝数据两个阶段)都被block了。
几乎所有的程序员第一次接触到的网络编程都是从listen()、send()、recv() 等接口开始的,使用这些接口可以很方便的构建服务器/客户机的模型。然而大部分的socket接口都是阻塞型的。
阻塞型接口是指系统调用(一般是IO接口)不返回调用结果并让当前线程一直阻塞,只有当该系统调用获得结果或者超时出错时才返回。
实际上,除非特别指定,几乎所有的IO接口 ( 包括socket接口 ) 都是阻塞型的。这给网络编程带来了一个很大的问题,如在调用recv(1024)的同时,线程将被阻塞,在此期间,线程将无法执行任何运算或响应任何的网络请求。
解决方案:
在服务器端使用多线程(或多进程)。多线程(或多进程)的目的是让每个连接都拥有独立的线程(或进程),这样任何一个连接的阻塞都不会影响其他的连接。
该方案的问题是:
开启多进程或都线程的方式,在遇到要同时响应成百上千路的连接请求,则无论多线程还是多进程都会严重占据系统资源,降低系统对外界响应效率,而且线程与进程本身也更容易进入假死状态。
改进方案:
很多程序员可能会考虑使用“线程池”或“连接池”。“线程池”旨在减少创建和销毁线程的频率,其维持一定合理数量的线程,并让空闲的线程重新承担新的执行任务。“连接池”维持连接的缓存池,尽量重用已有的连接、减少创建和关闭连接的频率。这两种技术都可以很好的降低系统开销,都被广泛应用很多大型系统,如websphere、tomcat和各种数据库等。
改进后方案其实也存在着问题:
“线程池”和“连接池”技术也只是在一定程度上缓解了频繁调用IO接口带来的资源占用。而且,所谓“池”始终有其上限,当请求大大超过上限时,“池”构成的系统对外界的响应并不比没有池的时候效果好多少。所以使用“池”必须考虑其面临的响应规模,并根据响应规模调整“池”的大小。
对应上例中的所面临的可能同时出现的上千甚至上万次的客户端请求,“线程池”或“连接池”或许可以缓解部分压力,但是不能解决所有问题。总之,多线程模型可以方便高效的解决小规模的服务请求,但面对大规模的服务请求,多线程模型也会遇到瓶颈,可以用非阻塞接口来尝试解决这个问题。
2、非阻塞IO
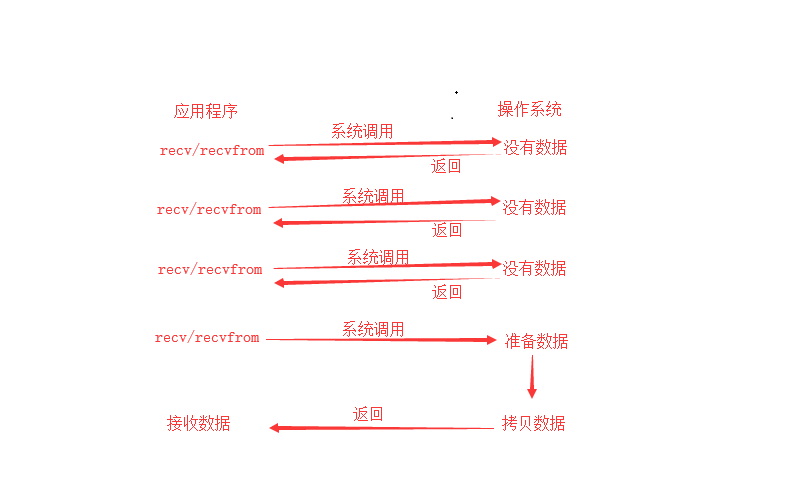 非阻塞IO操作一些时,如果操作系统中的数据还没有准备好,它也不会出现阻塞,而是立刻返回一个error。用户进程可以判断这个返回值是否是error,如果是它就知道数据还没有准备好,于是用户就可以在下次询问前的时间内做其他事情。如果数据准备好了,且用户再次进行询问时,那么数据就可以拷贝到用户内存(这一阶段仍然是阻塞的),然后返回。
其实在非阻塞式IO中,用户进程其实是需要不断的主动询问操作系统数据是否准备好了。
例如:
Server端:
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8080))
sk.setblocking(False) # 设置当前的server为一个非阻塞IO模型
sk.listen()
conn_lst = []
del_lst = []
while True:
try:
conn,addr = sk.accept()
conn_lst.append(conn)
except BlockingIOError:
for conn in conn_lst:
try:
conn.send(b'hello')
print(conn.recv(1024))
except (NameError,BlockingIOError):pass
except ConnectionResetError:
conn.close()
del_lst.append(conn)
for del_conn in del_lst:
conn_lst.remove(del_conn)
del_lst.clear()
Client端:
import socket
sk = socket.socket()
sk.connect(('127.0.0.1',8080))
while 1:
print(sk.recv(1024))
sk.send(b'heiheihei')
这样就可以实现非阻塞IO下基于TCP的并发socket,
但是这样的非阻塞IO大量的占用了CPU导致了资源的浪费并且给CPU造成了很大的负担
3、多路复用IO
非阻塞IO操作一些时,如果操作系统中的数据还没有准备好,它也不会出现阻塞,而是立刻返回一个error。用户进程可以判断这个返回值是否是error,如果是它就知道数据还没有准备好,于是用户就可以在下次询问前的时间内做其他事情。如果数据准备好了,且用户再次进行询问时,那么数据就可以拷贝到用户内存(这一阶段仍然是阻塞的),然后返回。
其实在非阻塞式IO中,用户进程其实是需要不断的主动询问操作系统数据是否准备好了。
例如:
Server端:
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8080))
sk.setblocking(False) # 设置当前的server为一个非阻塞IO模型
sk.listen()
conn_lst = []
del_lst = []
while True:
try:
conn,addr = sk.accept()
conn_lst.append(conn)
except BlockingIOError:
for conn in conn_lst:
try:
conn.send(b'hello')
print(conn.recv(1024))
except (NameError,BlockingIOError):pass
except ConnectionResetError:
conn.close()
del_lst.append(conn)
for del_conn in del_lst:
conn_lst.remove(del_conn)
del_lst.clear()
Client端:
import socket
sk = socket.socket()
sk.connect(('127.0.0.1',8080))
while 1:
print(sk.recv(1024))
sk.send(b'heiheihei')
这样就可以实现非阻塞IO下基于TCP的并发socket,
但是这样的非阻塞IO大量的占用了CPU导致了资源的浪费并且给CPU造成了很大的负担
3、多路复用IO
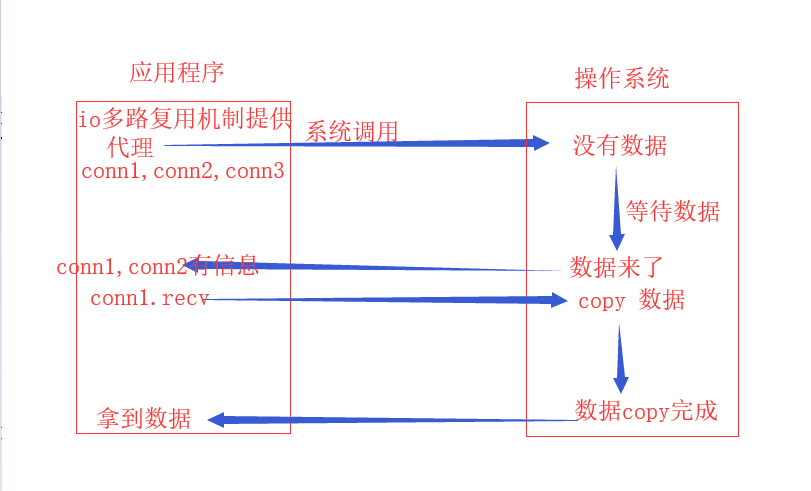 当用户进程调用了select,那么整个进程会被block,同时,操作系统会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从操作系统拷贝到用户进程。
多路复用IO与阻塞IO:
多路复用IO需要使用两次系统调用,而阻塞IO只调用了一个系统调用。但是,用select的优势在于它可以同时处理多个连接,而阻塞IO只能处理一个。
例子:
Server端:
import select # 用来操作操作系统中的select(IO多路复用)机制
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8888))
sk.setblocking(False)
sk.listen()
r_lst = [sk,]
while True:
# 监视r_lst这个列表(所有待接收请求的对象都在这里),谁的请求来了就通知谁,然后把有请求的对象返回给r_l列表,也有可能两个请求一起来
r_l,_,_ = select.select(r_lst,[],[])
for item in r_l: # 循环有请求的对象,判断是什么类型,进行对应的操作
if item is sk:
conn,addr = sk.accept()
r_lst.append(conn)
else:
try:
print(item.recv(1024))
item.send(b'hello')
except ConnectionResetError:
item.close()
r_lst.remove(item)
Client端:
import socket
sk = socket.socket()
sk.connect(('127.0.0.1',8888))
while 1:
sk.send(b'world')
print(sk.recv(1024))
多路复用IO小结:
io多路复用(asycio tornado twisted)机制
select 在windows\mac\linux可用
底层是操作系统的轮询
有监听对象个数的限制
随着监听对象的个数增加,效率降低
poll 只在mac\linux可用
底层是操作系统的轮询
有监听对象个数的限制,但是比select能监听的个数多
随着监听对象的个数增加,效率降低
epoll 只在mac\linux可用
给每一个要监听的对象都绑定了一个回调函数
不再受到个数增加 效率降低的影响
socketserver机制
IO多路复用 + threading线程
selectors模块
帮助你在不同的操作系统上进行IO多路复用机制的自动筛选
4、异步IO(Asynchronous I/O)
当用户进程调用了select,那么整个进程会被block,同时,操作系统会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从操作系统拷贝到用户进程。
多路复用IO与阻塞IO:
多路复用IO需要使用两次系统调用,而阻塞IO只调用了一个系统调用。但是,用select的优势在于它可以同时处理多个连接,而阻塞IO只能处理一个。
例子:
Server端:
import select # 用来操作操作系统中的select(IO多路复用)机制
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8888))
sk.setblocking(False)
sk.listen()
r_lst = [sk,]
while True:
# 监视r_lst这个列表(所有待接收请求的对象都在这里),谁的请求来了就通知谁,然后把有请求的对象返回给r_l列表,也有可能两个请求一起来
r_l,_,_ = select.select(r_lst,[],[])
for item in r_l: # 循环有请求的对象,判断是什么类型,进行对应的操作
if item is sk:
conn,addr = sk.accept()
r_lst.append(conn)
else:
try:
print(item.recv(1024))
item.send(b'hello')
except ConnectionResetError:
item.close()
r_lst.remove(item)
Client端:
import socket
sk = socket.socket()
sk.connect(('127.0.0.1',8888))
while 1:
sk.send(b'world')
print(sk.recv(1024))
多路复用IO小结:
io多路复用(asycio tornado twisted)机制
select 在windows\mac\linux可用
底层是操作系统的轮询
有监听对象个数的限制
随着监听对象的个数增加,效率降低
poll 只在mac\linux可用
底层是操作系统的轮询
有监听对象个数的限制,但是比select能监听的个数多
随着监听对象的个数增加,效率降低
epoll 只在mac\linux可用
给每一个要监听的对象都绑定了一个回调函数
不再受到个数增加 效率降低的影响
socketserver机制
IO多路复用 + threading线程
selectors模块
帮助你在不同的操作系统上进行IO多路复用机制的自动筛选
4、异步IO(Asynchronous I/O)
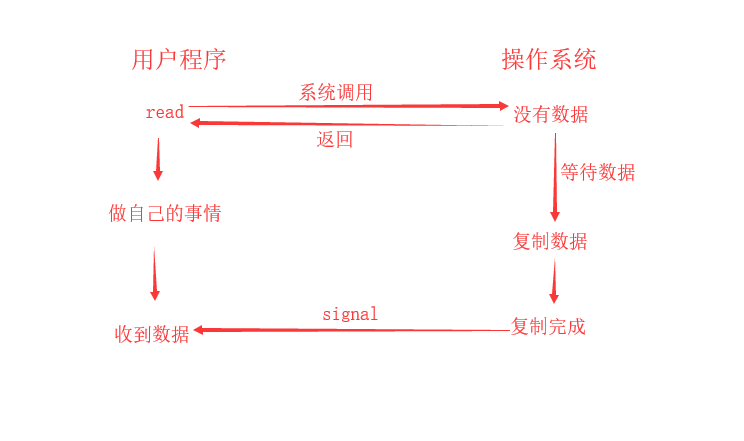 用户进程发起请求之后,操作系统会立刻返回,所有不会形成阻塞,然后用户进程立刻就可以开始去做其它的事。同时操作系统会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,会给用户进程发送一个signal,告诉它操作完成了。
用户进程发起请求之后,操作系统会立刻返回,所有不会形成阻塞,然后用户进程立刻就可以开始去做其它的事。同时操作系统会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,会给用户进程发送一个signal,告诉它操作完成了。


