Calico网络组件
35. Calico网络组件
- 简介
Calico是一个纯三层的网络插件,calico的bgp模式类似于flannel的host-gw
Calico方便集成OpenStack这种云架构,为openstack虚拟机、容器、裸机提供多主机间通信
35.1 calico架构
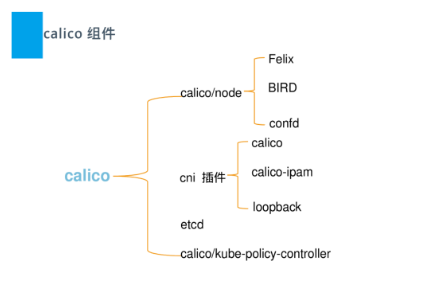
- calico包括如下重要组件:Felix、etcd、BGP Client、BGP Route Reflector
- Felix:主要负责路由配置以及ACLS规则的配置以及下发、它存在每个node节点上
- Etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与Kubernetes共用
- BGP Client:主要负责把Felix写入Kernel的路由信息分发到当前Calico网络,确保workload间的通信的有效性
- BGP Route Reflector:大规模部署时使用,摒弃所有节点互联的mesh模式,通过一个或者多个BGP Route Reflector 来完成集中式的路由转发
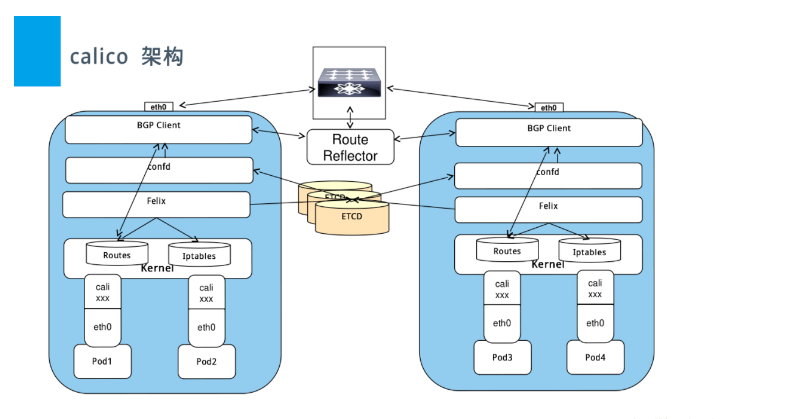
35.2 calico原理
calico是一个纯三层的虚拟网络,它没有复用docker的docker0网桥,而是自己实现的,calico网络不对数据包进行额外封装,不需要NAT和端口映射、扩展性和性能都很好。calico网络提供了DockerDNS服务,容器之间可以通过hostname访问,calico在每一个计算节点利用linux kernel实现了一个高效的vRouter(虚拟路由)来负责数据转发,它会为每个容器分配一个IP,每个节点都是路由,把不同host的容器连接起来,从而实现跨主机间容器通信。而每个vRouter通过BGP协议(边界网关协议)负责把自己节点的路由信息向整个calico网络内传播,小规模部署可以直接互联,大规模下可通过指定的BGProute reflector来完成,calico基于iptables还提供了丰富灵活的网络策略,保证通过各个节点上的ACLs来提供多租户隔离、安全组以及其他可达性限制等功能
35.3 calico网络模式
Calico本身支持多种网络模式,从
overlay和underlay上区分。Calico overlay模式,一般也称Calico IPIP或VXLAN模式,不同Node间Pod使用IPIP或VXLAN隧道进行通信。Calico underlay模式,一般也称calico BGP模式,不同Node Pod使用直接路由进行通信。在overlay和underlay都有nodetonode mesh(全网互联)和Route Reflector(路由反射器)。如果有安全组策略需要开放IPIP协议;要求Node允许BGP协议,如果有安全组策略需要开放TCP 179端口;官方推荐使用在Node小于100的集群,我们在使用的过程中已经通过IPIP模式支撑了100-200规模的集群稳定运行。
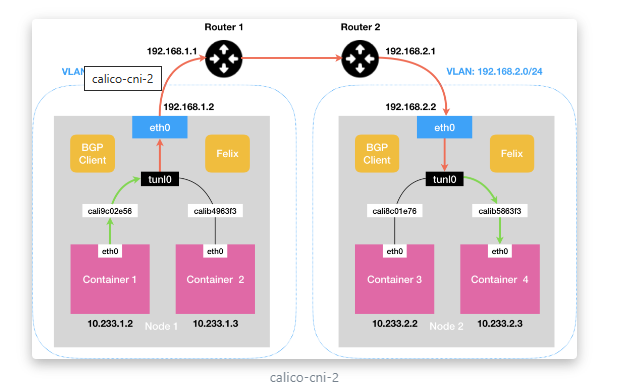
- IPIP模式
把一个IP数据包又套在一个IP包里,即把IP层封装到IP层的一个tunnel,它的作用其实基本上就相当于一个基于IP层的网桥,一般来说,普通的网桥是基于mac层的,根本不需要IP,而这个IPIP则是通过两端的路由做一个tunnel,把两个本来不通的网络通过点对点连接起来
流量:tunl0设备封装数据,形成隧道,承载流量。
适用网络类型:适用于互相访问的pod不在同一个网段中,跨网段访问的场景。外层封装的ip能够解决跨网段的路由问题。
效率:流量需要tunl0设备封装,效率略低
网络走向:pod cali0-->calixxx-->tunl0-->node1 eth0 -->node2 eth0-->tunl0-->calixxx-->pod cali0
calico以ipip模式部署完毕后,node上会有一个tunl0的网卡设备,这是ipip做隧道封装用的,也是一种overlay模式的网络
tunl0: flags=193<UP,RUNNING,NOARP> mtu 1440
inet 10.200.159.128 netmask 255.255.255.255
tunnel txqueuelen 1000 (IPIP Tunnel)
#官方提供的calico.yaml模板里,默认打开了ip-ip功能,该功能会在node上创建一个设备tunl0,容器的网络数据会经过该设备被封装一个ip头再转发。这里,calico.yaml中通过修改calico-node的环境变量:CALICO_IPV4POOL_IPIP来实现ipip功能的开关:默认是Always,表示开启;Off表示关闭ipip
# kubectl get daemonsets. calico-node -n kube-system -o yaml | grep -iA 1 ipip
- name: CALICO_IPV4POOL_IPIP
value: "Always"
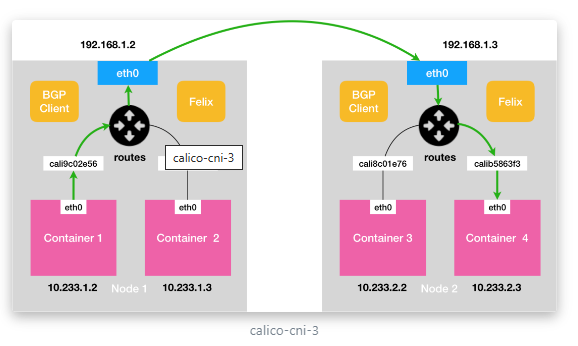
- BGP
边界网关协议(BorderGateway Protocol, BGP)是互联网上一个核心的去中心化的自治路由协议。它通过维护IP路由表或‘前缀’表来实现自治系统(AS)之间的可达性,属于矢量路由协议。BGP不使用传统的内部网关协议(IGP)的指标,而是基于路径、网络策略或规则集来决定路由。因此,它更适合被称为矢量性协议,而不是路由协议,通俗的说就是将接入到机房的多条线路(如电信、联通、移动等)融合为一体,实现多线单IP;
BGP 机房的优点:服务器只需要设置一个IP地址,最佳访问路由是由网络上的骨干路由器根据路由跳数与其它技术指标来确定的,不会占用服务器的任何系统。
流量:使用主机路由表信息导向流量
适用网络类型:适用于互相访问的pod在同一个网段,适用于大型网络。
效率:原生hostGW,效率高
网络走向:pod1 cali0->caliXXXX->node1 eth0->node2 eth0-> caliXXXX->pod2 cali0
35.4 calico通信流程
#运行两个容器要在不同的节点上 另一个用上面的例子
root@k8s-master1:~# kubectl run busybox --image=busybox sleep 100000000
pod/busybox created
root@k8s-node2:~# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox 1/1 Running 0 2m51s 10.200.224.59 10.0.0.102 <none> <none>
nginx-deployment-544dc8b7c4-j95hx 1/1 Running 0 7s 10.200.107.220 10.0.0.111 <none> <none>
#注意这个括号内的地址就是你的目的pod的路由
root@k8s-node2:~# kubectl exec -it busybox sh
/ # ping 10.200.107.220
PING 10.200.107.220 (10.200.107.220): 56 data bytes
root@k8s-node3:~# kubectl exec -it nginx-deployment-544dc8b7c4-j95hx bash
#第一条路由的意思是:去往任何网段的数据包都发往网关169.254.1.1,然后从eth0网卡发送出去
root@nginx-deployment-544dc8b7c4-j95hx:/# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 169.254.1.1 0.0.0.0 UG 0 0 0 eth0
169.254.1.1 0.0.0.0 255.255.255.255 UH 0 0 0 eth0
root@k8s-node3:~# route -n
#node2 10.0.0.107是node2地址,这是node2发往node3的路由然后再到tunl0
#busybox的pod在10.0.0.111上。所以数据包就通过设备tunl0发往到 k8s-node3 节点上
10.200.169.128 10.0.0.107 255.255.255.192 UG 0 0 0 tunl0
root@k8s-node2:~# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
10.200.107.192 10.0.0.111 255.255.255.192 UG 0 0 0 tunl0
#再node3的容器中查看 这个编号是13
root@nginx-deployment-544dc8b7c4-j95hx:/# ip a
4: eth0@if13: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether ba:33:eb:47:8a:06 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.200.107.220/32 brd 10.200.107.220 scope global eth0
#然后你再宿主机上在查一下 找到了编号13的网卡
root@k8s-node3:~# ip link show
13: calia7109fca170@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether ee:ee:ee:ee:ee:ee brd ff:ff:ff:ff:ff:ff link-netns cni-8c514107-1ca8-c17b-2573-1a2749a394eb
#再次查看宿主机路由 报文就是从calia7109fca170网卡进来的就直接访问到了pod
root@k8s-node3:~# route -n
10.200.107.220 0.0.0.0 255.255.255.255 UH 0 0 0 calia7109fca170
35.5 Calico Overlay网络
在Calico Overlay网络中有两种模式可选(仅支持IPV4地址)
- IP-in-IP (使用BGP实现)基于tunl0实现隧道封装及解封装
#Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "Always"
- Vxlan (不使用BGP实现)
- Directrouting:关闭IPIP模式,此模式下跨主机通信的报文不会进行IPIP封装,而是直接使用宿主机物理网卡进行报文转发,转发性能比IPIP强
# vim calico-ipip-Directrouting.yaml
#Enable IPIP
- name: CALICO_IPV4P0OL_IPIP
value: "off" #Directrouting
两种模式均支持如下参数
- Always: 永远进行 IPIP 封装(默认)
- CrossSubnet: 表示在同一个二层,跨节点通信走本地路由,而跨三层的节点互相通信则会通过 IPIP 封装。
- name: CALICO_IPV4P0OL_IPIP
#value: "Always"#IPIP
value: "CrossSubnet"
- Never: 从不进行 IPIP 封装,适合确认所有 Kubernetes 节点都在同一个网段下的情况(配置此参数就开启了BGP模式)
在默认情况下,默认的 ipPool 启用了 IPIP 封装(至少通过官方安装文档安装的 Calico 是这样),并且封装模式为 Always;这也就意味着任何时候都会在原报文上封装新 IP 地址,在这种情况下将外部流量路由到 RR 节点,RR 节点再转发进行 IPIP 封装时,可能出现网络无法联通的情况(没仔细追查,网络渣,猜测是 Pod 那边得到的源 IP 不对导致的);此时我们应当调整 IPIP 封装策略为 CrossSubnet

