30. 调度机制
30.1 Pod调度流程
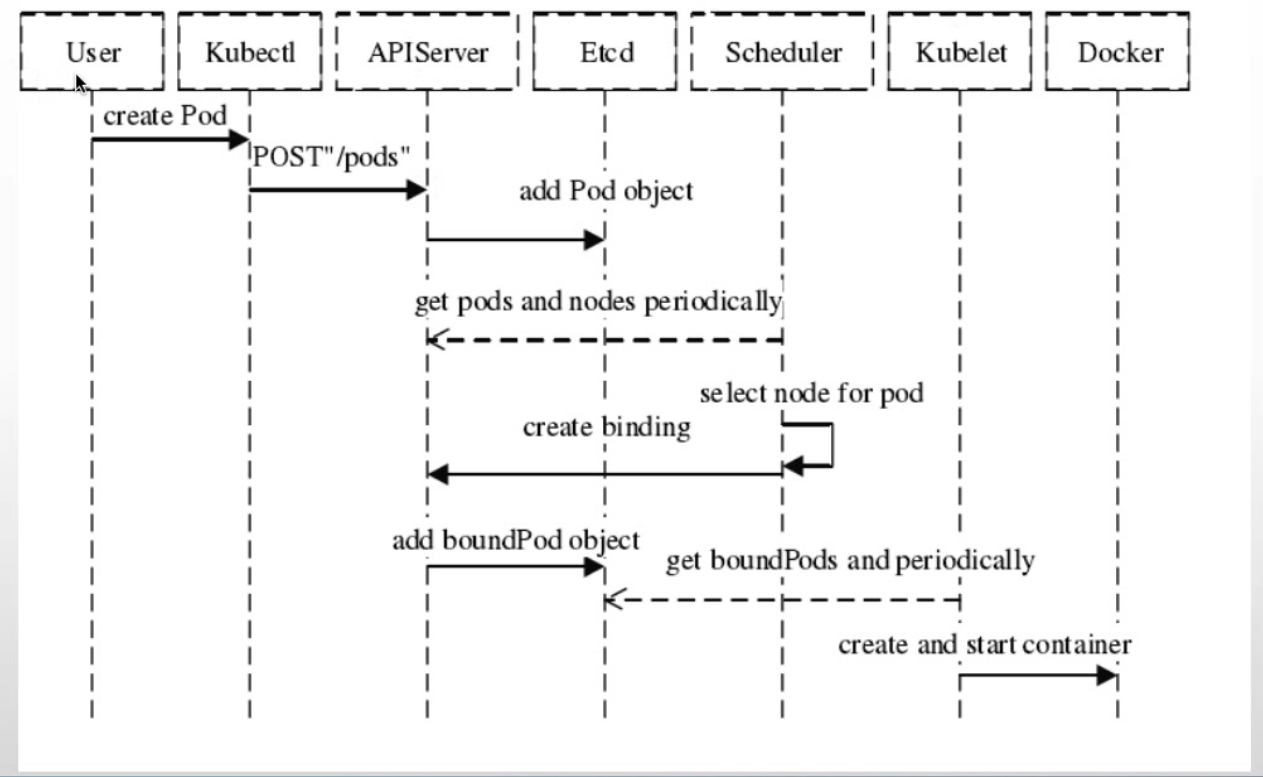
| 1.通过命令kubectl发送命令创建pod发送给api-server |
| 2.api-server把信息写入到etcd |
| 3.kube-Scheduler会从etcd中获取事件就是创建信息,找到之后在返回给api-server,kube-Scheduler会选择一个node把调度结果返回给api-server,这个过程称之为绑定事件,在把这个事件写入到etcd,kube-Scheduler只负责调度,不负责创建容器 |
| 4.kubelet获取绑定的事件kubelet通过一个本地的socker来调用运行时docker,kubelet |
| 5.然后再创建容器 |
30.2 nodeSelector
| nodeSelector基于node标签选择器,将Pod调度的指定的目的节点上 |
| 可用于基于服务类型干预Pod调度结果,如对磁盘I/O要求高的Pod调度到SSD节点,对内存要求比较高的Pod调度的内存较高的节点,也可以用于区分不同项目的Pod,如将node添加不同项目的标签,然后区分调度 |
| |
| kubectl label node 10.0.0.101 project=demo |
| |
| kubectl label node k8s-node1 project- |
| |
| kubectl get node --show-labels |
30.3 nodeName
| 精确调度到主机 |
| 使用场景:例如数据库把这个pod精确调度到某个主机上 |
30.4 node affinity节点亲和性
| affinity是kubernetes 1.2版本后引入的新特性,类似于nodeSelector,允许使用者指定一些Pod在Node间调度的约束,目前支持两种形式: |
| |
| requiredDuringSchedulinglgnoredDuringExecution |
| preferredDuringSchedulinglgnoredDuringExecution |
| lgnoreDuringExecution |
| Affinity与anti-affinity的目的也是控制pod的调度结果,但是相对于nodeSelector,Affinity(亲和)与anti-affinityg(反亲和)的功能更加强大 |
| 1.亲和与反亲和对目的标签的选择匹配不仅仅支持and还支持In、Notln、Exists、DoesNotExist、Gt、Lt。 |
| In:标签的值存在匹配列表中(匹配成功就调度到目的node,实现node亲和) |
| Notln:标签的值不存在指定的匹配列表中(不会调度到目的node,实现反亲和) |
| Gt:标签的值大于某个值(字符串) |
| Lt:标签的值小于某个值(字符串) |
| Exists:指定的标签存在 |
| 2.可以设置软匹配和硬匹配,在软匹配下如果调度器无法匹配节点,仍然将pod调度到其它不符合条件的节点 |
| 3.还可以对pod定义亲和策略,比如允许那些pod可以或者不可以被调度至同一台node |
- 例:硬限制多个匹配条件
- 多个matchExpressions匹配其中一个就可以
| spec: |
| containers: |
| - name: tomcat-app2-container |
| image: tomcat:7.0.94-alpine |
| imagePullPolicy: IfNotPresent |
| |
| ports: |
| - containerPort: 8080 |
| protocol: TCP |
| name: http |
| affinity: |
| nodeAffinity: |
| |
| requiredDuringSchedulingIgnoredDuringExecution: |
| |
| nodeSelectorTerms: |
| |
| - matchExpressions: |
| |
| - key: disktype |
| |
| operator: In |
| values: |
| |
| - ssd |
| - xxx |
| |
| - matchExpressions: |
| - key: project |
| operator: In |
| |
| values: |
| - mmm |
| - nnn |
| spec: |
| containers: |
| - name: magedu-tomcat-app2-container |
| image: tomcat:7.0.94-alpine |
| imagePullPolicy: IfNotPresent |
| |
| ports: |
| - containerPort: 8080 |
| protocol: TCP |
| name: http |
| affinity: |
| nodeAffinity: |
| requiredDuringSchedulingIgnoredDuringExecution: |
| nodeSelectorTerms: |
| - matchExpressions: |
| - key: disktype |
| operator: In |
| values: |
| - ssd |
| - hddx |
| - key: project |
| operator: In |
| values: |
| - demo |
| spec: |
| containers: |
| - name: magedu-tomcat-app2-container |
| image: tomcat:7.0.94-alpine |
| imagePullPolicy: IfNotPresent |
| |
| ports: |
| - containerPort: 8080 |
| protocol: TCP |
| name: http |
| affinity: |
| nodeAffinity: |
| preferredDuringSchedulingIgnoredDuringExecution: |
| - weight: 80 |
| preference: |
| matchExpressions: |
| - key: project |
| operator: In |
| values: |
| - magedu |
| - weight: 60 |
| preference: |
| matchExpressions: |
| - key: disktype |
| operator: In |
| values: |
| - ssd |
- 例:硬限制与软限制结合
- 用硬限制排除一部分主机在用软限制进行匹配 这个NotIn就相当于反亲和了
| spec: |
| containers: |
| - name: magedu-tomcat-app2-container |
| image: tomcat:7.0.94-alpine |
| imagePullPolicy: IfNotPresent |
| |
| ports: |
| - containerPort: 8080 |
| protocol: TCP |
| name: http |
| affinity: |
| nodeAffinity: |
| requiredDuringSchedulingIgnoredDuringExecution: |
| nodeSelectorTerms: |
| - matchExpressions: |
| - key: "kubernetes.io/role" |
| operator: NotIn |
| values: |
| - "master" |
| preferredDuringSchedulingIgnoredDuringExecution: |
| - weight: 80 |
| preference: |
| matchExpressions: |
| - key: project |
| operator: In |
| values: |
| - magedu |
| - weight: 60 |
| preference: |
| matchExpressions: |
| - key: disktype |
| operator: In |
| values: |
| - hdd |
| |
| spec: |
| containers: |
| - name: magedu-tomcat-app2-container |
| image: tomcat:7.0.94-alpine |
| imagePullPolicy: IfNotPresent |
| |
| ports: |
| - containerPort: 8080 |
| protocol: TCP |
| name: http |
| affinity: |
| nodeAffinity: |
| requiredDuringSchedulingIgnoredDuringExecution: |
| nodeSelectorTerms: |
| - matchExpressions: |
| - key: disktype |
| operator: NotIn |
| values: |
| - hdd |
| |
30.5 pod Affinity亲和性
- 概述 亲和就是pod都在一块 反亲和就都不在一个主机 分开
| Pod亲和性与反亲和性可以基于已经在node节点上运行的pod的标签来约束新创建的pod可以调度到的目的节点,注意不是基于node上的标签而是使用的已经运行在node上的pod标签匹配 |
| |
| 其规则的格式为如果node节点A已经运行了一个或多个满足调度新创建的pod B的规则,那么新的Pod B在亲和的条件下会调度到A节点之上,而在反亲和性的情况下则不会调度到A节点至上 |
| |
| 其中规则表示一个具有可选的关联命名空间列表的LabelSelector,只所以Pod亲和与反亲和需可以通过LabelSelector选择namespace,是因为Pod是命名空间限定的而node不属于任何namespace所以node的亲和与反亲和不需要namespace,因此作用于pod标签的标签选择算符必须指定选择算符应用在那个命名空间 |
| |
| 从概念上讲,node节点是一个拓扑域(具有拓扑结构的域),比如k8s集群中的单台node节点,一个机架、云供应商可用区,云供应商地理区域等,可以使用topologykey来定义亲和或者反亲和的颗粒度是node级别还是可用区级别,以便kubernetes调度系统用来识别并选择正确的目的拓扑域。 |
| spec: |
| containers: |
| - name: magedu-tomcat-app2-container |
| image: tomcat:7.0.94-alpine |
| imagePullPolicy: IfNotPresent |
| |
| ports: |
| - containerPort: 8080 |
| protocol: TCP |
| name: http |
| affinity: |
| podAffinity: |
| |
| preferredDuringSchedulingIgnoredDuringExecution: |
| - weight: 100 |
| podAffinityTerm: |
| labelSelector: |
| matchExpressions: |
| - key: project |
| operator: In |
| values: |
| - python |
| topologyKey: kubernetes.io/hostname |
| namespaces: |
| - demo |
- 硬亲和 匹配成功之后才会被调度 匹配失败就显示为pending
| spec: |
| containers: |
| - name: magedu-tomcat-app2-container |
| image: tomcat:7.0.94-alpine |
| imagePullPolicy: IfNotPresent |
| |
| ports: |
| - containerPort: 8080 |
| protocol: TCP |
| name: http |
| affinity: |
| podAffinity: |
| requiredDuringSchedulingIgnoredDuringExecution: |
| - labelSelector: |
| matchExpressions: |
| - key: project |
| operator: In |
| values: |
| - python |
| topologyKey: "kubernetes.io/hostname" |
| namespaces: |
| - demo |
- 硬反亲和
- 个人理解:pod affinity的调度范围为topology
| spec: |
| containers: |
| - name: magedu-tomcat-app2-container |
| image: tomcat:7.0.94-alpine |
| imagePullPolicy: IfNotPresent |
| |
| ports: |
| - containerPort: 8080 |
| protocol: TCP |
| name: http |
| affinity: |
| podAntiAffinity: |
| requiredDuringSchedulingIgnoredDuringExecution: |
| - labelSelector: |
| matchExpressions: |
| - key: project |
| operator: In |
| values: |
| - python |
| topologyKey: "kubernetes.io/hostname" |
| namespaces: |
| - demo |
30.6 维护节点三兄弟
| 在1.2之前,由于没有相应的命令支持,如果要维护一个节点,只能stop该节点上的kubelet将该节点退出集群,是集群不在将新的pod调度到该节点上。如果该节点上本身就没有pod在运行,则不会对业务有任何影响。如果该节点上有pod正在运行,kubelet停止后,master会发现该节点不可达,而将该节点标记为notReady状态,不会将新的节点调度到该节点上。同时,会在其他节点上创建新的pod替换该节点上的pod。 |
| |
| 如此虽能够保证集群的健壮性,但可能还有点问题,如果业务只有一个副本,而且该副本正好运行在被维护节点上的话,可能仍然会造成业务的短暂中断。 |
| kubectl cordon xxx-node-01 |
| kubectl drain xxx-node-01 --force --ignore-daemonsets |
| kubectl uncordon xxx-node-01 |
30.7 污点
| 污点(taints)用于node节点排斥pod调度,与亲和的作用是完全相反的,即taint的node和pod是排斥调度关系 |
| 容忍:用于Pod容忍node节点的污点信息,即node有污点信息也会将新的pod调度到node |
| tolerations容忍: |
| 定义Pod的容忍度(可以接受node的那些污点)容忍后可以将Pod调度至含有该污点的node |
| 基于operator的污点匹配: |
| 如果operator是Exists,则容忍度不需要value而是直接匹配污点类型 |
| 如果operator是Equal,则需要指定value并且value的值需要等于tolerations的key |
| |
| NoSchedule:表示k8s将不会将Pod调度到具有该污点的Node上 |
| |
| PreferNoSchedule:表示k8s将尽量避免将pod调度到具有该污点的node上 |
| NoExecute:表示k8s将不会将pod调度到具有该污点的node上,同时会将node上已经存在的pod强制驱逐出去 |
| |
| kubectl taint node 10.0.0.101 key1=value1:NoSchedule |
| |
| |
| kubectl describe node 10.0.0.101 |
| |
| |
| kubectl taint node 10.0.0.101 key1:NoSchedule- |
| |
| kubectl taint node 10.0.0.101 key1=value1:NoSchedule |
| |
| tolerations: |
| - key: "key1" |
| operator: "Equal" |
| value: "value1" |
| effect: "NoSchedule" |
30.8 kubelet pod驱逐
| |
| 节点压力驱逐是由各kubelet进程主动终止Pod,以回收节点上的内存、磁盘空间等资源的过程,kubelet监控当前node节点CPU、内存、磁盘空间和文件系统的inode等资源,当这些资源中的一个或者多个达到特定的消耗水平,kubelet就会主动地将节点上一个或者多个Pod强制驱逐,以防止当前node节点资源无法正常分配而引发的OOM(OutOfMemory) |
| |
| memory.available |
| |
| |
| nodefs.inodesFree |
| nodefs.available |
| |
| |
| imagefs.inodesFree |
| imagefs.available |
| pid.available |
| |
| |
| evictionHard: |
| imagefs.inodesFree: 5% |
| imagefs.available: 15% |
| memory.available: 300Mi |
| nodefs.available: 10% |
| nodefs.indesFree: 5% |
| pid.available: 5% |
| kube-controller-manager实现 eviction |
| node宕机后的驱逐 |
| 节点驱逐,用于当node节点资源不足的时候自动将pod进行强制驱逐,以保证当前node节点的正常运行。Kubernetes基于是QoS(服务质量等级)驱逐Pod,Qos等级包括目前包括以下三个: |
| |
| Guaranteed: |
| resources: |
| limits: |
| cpu: 500m |
| memory: 256Mirequests: |
| cpu: 500m |
| memory: 256Mi |
| Burstable: |
| resources: |
| limits: |
| cpu: 500m |
| memory: 256Mirequests: |
| cpu: 256m |
| memory: 128Mi |
| |
| BestEffort: |
| eviction-signal: kubelet捕获node节点驱逐触发信号,进行判断是否驱逐,比如通过cgroupfs获取memory.available的值来进行下一步匹配 |
| |
| operator: 操作符,通过操作符对比条件是否匹配资源量是否触发驱逐 |
| |
| quantity: 使用量,即基于指定的资源使用值进行判断,如memory.available:300Mi、nodefs.available:10%等 |
| 比如:nodefs.available<10% |
| 当node节点磁盘空间可用率低于10%就会触发驱逐信号 |
| 软驱逐不会立即驱逐pod,可以自定义宽限期,在条件持续到宽限期还没有恢复,,kubelet再强制杀死pod并触发驱逐: |
| 软驱逐条件: |
| eviction-soft:软驱逐触发条件,比如memory.available < 1.5Gi,如果驱逐条件持续时长超过指定的宽限期,可 |
| 以触发Pod驱逐。 |
| eviction-soft-grace-period:软驱逐宽限期,如memory.available=1m30s,定义软驱逐条件在触发Pod驱逐之前 |
| 必须保持多长时间。 |
| eviction-max-pod-grace-period:终止pod的宽限期,即在满足软驱逐条件而终止Pod时使用的最大允许宽限期 |
| (以秒为单位)。 |
| 硬驱逐条件没有宽限期,当达到硬驱逐条件时,kubelet会强制立即杀死pod并驱逐: |
| kubelet具有以下默认硬驱逐条件(可以自行调整): |
| memory.available<100Mi |
| nodefs.available<10% |
| imagefs.available<15% |
| nodefs.inodesFree<5%(Linux节点) |
| kubelet service文件: |
| vim /etc/systemd/system/kubelet.service |
| kubelet配置文件 |
| evictionHard: |
| imagefs.available: 15% |
| memory.available: 30OMi |
| nodefs.available: 10% |
| nodefs.inodesFree: 5% |



