Ansible-K8S 二进制安装
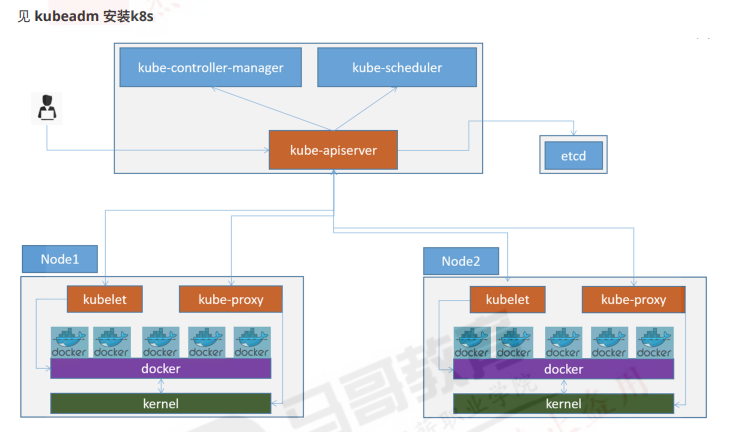
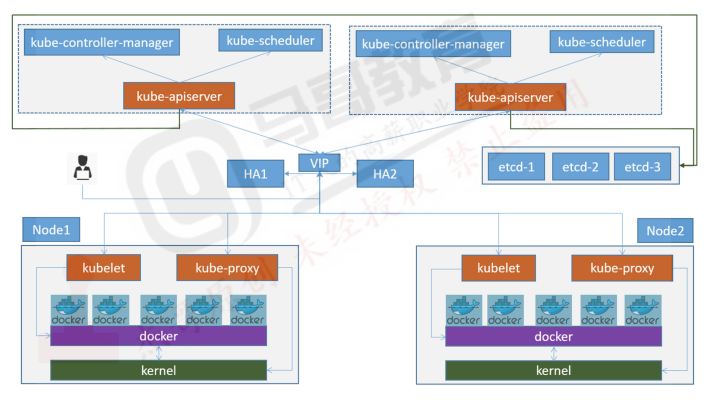
1. k8s集群环境搭建规划信息
1.1 单master环境
1.2 多master环境
1.3 服务器统计
类型
服务器IP地址
备注
Ansible(2台)
K8s集群部署服务器,可以和其他服务器混用
K8S Master(3台)
K8s控制端,通过一个VIP做主备高可用
Harbor(2台)
高可用镜像服务器
Etcd(3台)
保存K8s集群数据的服务器
Haproxy(2台)
高可用etcd代理服务器
Node节点(2-N台)
真正运行容器的服务器,高可用环境至少两台
1.4 服务器准备
服务器可以是私有云的虚拟机或物理机,也可以是公有云环境的虚拟机环境,如果是公司托管IDC环境,可以直接将harbor和node节点部署在物理机环境,master节点、etcd节点、负载均衡等可以是虚拟机
主机名
IP地址
备注
k8s-master1
192.168.1.70
高可用master节点
k8s-master2
192.168.1.71
k8s-ha1(deploy-harbor)
192.168.1.72
负载均衡高可用 VIP 192.168.1.100
k8s-etcd1
192.168.1.73
注册中心高可用
k8s-etcd2
192.168.1.74
k8s-etcd3
192.168.1.75
k8s-node1
192.168.1.76
k8s节点
1.5 系统配置
VIP:192.168.1.69:6443 #在负载均衡上配置
操作系统:ubuntu 20.04
k8s版本: 1.24.x
calico: 3.4.4
1.6 基础环境准备 ubuntu
cat > /etc/apt/sources.list <<'EOF'
deb http:
deb http:
deb http:
deb http:
deb http:
deb http:
deb http:
deb http:
deb http:
deb http:
EOF
apt-get update
apt-get update
hostnamectl set-hostname xxxx
vim /etc/netplan/00-installer-config.yaml
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system
swapoff -a
sed -ri 's/.*swap.*/#&/' /etc/fstab
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
date -R
cat > /etc/hosts <<'EOF'
192.168.1.70 k8s-master1
192.168.1.71 k8s-master2
192.168.1.72 k8s-ha1 harbor.nbrhce.com
192.168.1.73 k8s-etcd1
192.168.1.74 k8s-etcd2
192.168.1.75 k8s-etcd3
192.168.1.76 k8s-node1
EOF
2. 负载均衡部署
2.1 keepalived部署
root@k8s-ha1:~
root@k8s-ha1:~
/usr/share/doc/keepalived/samples/keepalived.conf.vrrp
root@k8s-ha1:~
root@k8s-ha1:~
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 100
advert_int 3
authentication {
auth_type PASS
auth_pass 123 abc
}
virtual_ipaddress {
192 .168 .1 .72 dev eth0 label eth0:1
}
}
root@localhost:~
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 50
advert_int 3
authentication {
auth_type PASS
auth_pass 123 abc
}
virtual_ipaddress {
192 .168 .1 .73 dev eth0 label eth0:1
}
}
systemctl start keepalived.service
systemctl enable keepalived.service
root@k8s-ha1:~
eth0: flags=4163 <UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192 .168 .1 .73 netmask 255 .255 .255 .0 broadcast 192 .168 .1 .255
inet6 fe80::20 c:29 ff:feab:bfb7 prefixlen 64 scopeid 0x20 <link>
ether 00 :0 c:29 :ab:bf:b7 txqueuelen 1000 (Ethernet)
RX packets 492885 bytes 250991107 (250 .9 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 387918 bytes 23556907 (23 .5 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
eth0:1 : flags=4163 <UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192 .168 .1 .72 netmask 255 .255 .255 .255 broadcast 0 .0 .0 .0
ether 00 :0 c:29 :ab:bf:b7 txqueuelen 1000 (Ethernet)
lo: flags=73 <UP,LOOPBACK,RUNNING> mtu 65536
inet 127 .0 .0 .1 netmask 255 .0 .0 .0
inet6 ::1 prefixlen 128 scopeid 0x10 <host>
loop txqueuelen 1000 (Local Loopback)
RX packets 182 bytes 15942 (15 .9 KB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 182 bytes 15942 (15 .9 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
2.2 haproxy部署
root@k8s-ha1:~
..略
listen k8s_api_nodes_6443
bind 192.168.1.100:6443
mode tcp
server 192.168.1.70 192.168.1.70:6443 check inter 2000 fall 3 rise 5
server 192.168.1.71 192.168.1.71:6443 check inter 2000 fall 3 rise 5
systemctl restart haproxy.service
systemctl enable haproxy.service
已经监听了6443端口
root@k8s-ha1:~
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
udp UNCONN 0 0 127.0.0.53%lo:53 0.0.0.0:* users :(("systemd-resolve" ,pid=790,fd=12))
tcp LISTEN 0 262124 192.168.1.69:6443 0.0.0.0:* users :(("haproxy" ,pid=6349,fd=7))
tcp LISTEN 0 4096 127.0.0.53%lo:53 0.0.0.0:* users :(("systemd-resolve" ,pid=790,fd=13))
tcp LISTEN 0 128 0.0.0.0:22 0.0.0.0:* users :(("sshd" ,pid=854,fd=3))
tcp LISTEN 0 128 127.0.0.1:6010 0.0.0.0:* users :(("sshd" ,pid=1151,fd=11))
tcp LISTEN 0 128 [::]:22 [::]:* users :(("sshd" ,pid=854,fd=4))
tcp LISTEN 0 128 [::1]:6010 [::]:* users :(("sshd" ,pid=1151,fd=10))
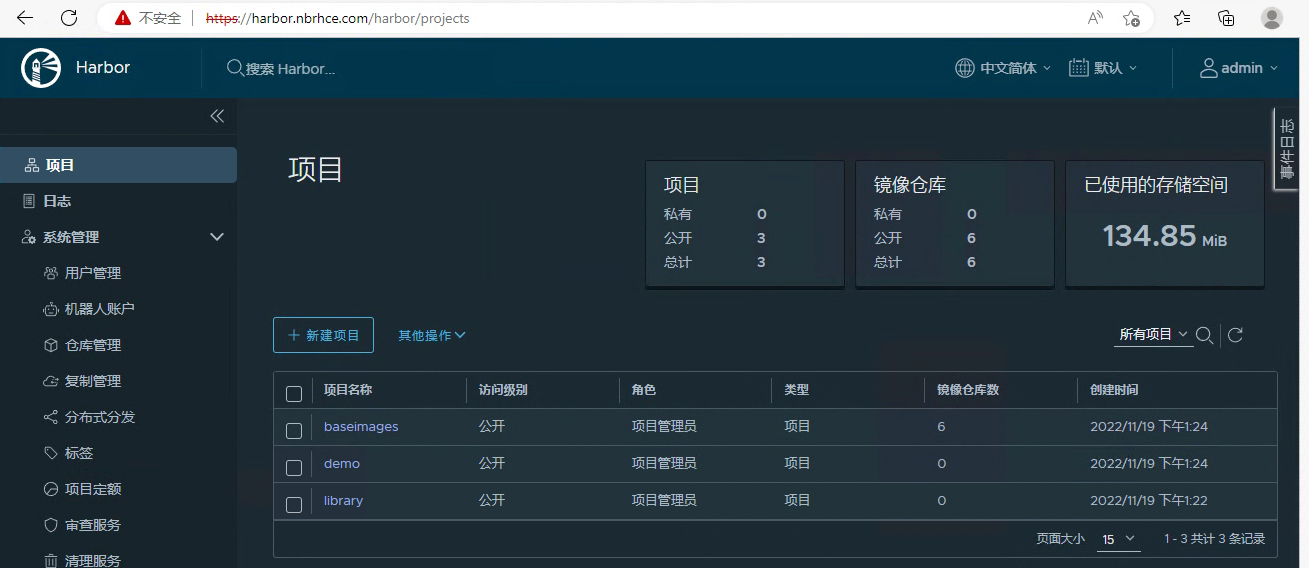
3. harbor部署
由于我机器资源不够harbor服务与ansible在一台机器上
kubernetes master节点和node节点使用containerd 可以提前安装或使用部署工具安装,在harbor节点安装docker,后续需要部署harbor
3.1 Harbor部署
root@k8s-harbor1:~
root@k8s-harbor1:~
root@k8s-harbor1:~
Client: Docker Engine - Community
Version: 19.03.15
API version: 1.40
Go version: go1.13.15
Git commit: 99e3ed8
Built: Sat Jan 30 03:11:43 2021
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 19.03.15
API version: 1.40 (minimum version 1.12)
Go version: go1.13.15
Git commit: 99e3ed8
Built: Sat Jan 30 03:18:13 2021
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: v1.3.9
GitCommit: ea765aba0d05254012b0b9e595e995c09186427f
runc:
Version: 1.0.0-rc10
GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd
docker-init:
Version: 0.18.0
GitCommit: fec3683
3.2 Harbor配置https自签证书
业务镜像将统一上传到Harbor的服务器并实现镜像分发,不用通过互联网在线下载公网镜像,提高镜像分发效率及数据安全性
root@k8s-harbor1:~
root@k8s-harbor1:/apps/certs
root@k8s-harbor1:/apps/certs
-subj "/C=CN/ST=Beijing/L=Beijing/O=example/OU=Personal/CN=harbor.nbrhce.com" \
-key ca.key \
-out ca.crt
root@k8s-harbor1:/apps/certs
root@k8s-harbor1:/apps/certs
-subj "/C=CN/ST=Beijing/L=Beijing/O=example/OU=Personal/CN=harbor.nbrhce.com" \
-key harbor.nbrhce.com.key \
-out harbor.nbrhce.com.csr
root@k8s-harbor1:/apps/certs
authorityKeyIdentifier=keyid,issuer
basicConstraints=CA:FALSE
keyUsage = digitalSignature, nonRepudiation, keyEncipherment, dataEncipherment
extendedKeyUsage = serverAuth
subjectAltName = @alt_names
[alt_names]
DNS.1=harbor.nbrhce.com
DNS.2=harbor.nbrhce.net
DNS.3=harbor.nbrhce.local
EOF
root@k8s-harbor1:/apps/certs
-extfile v3.ext \
-CA ca.crt -CAkey ca.key -CAcreateserial \
-in harbor.nbrhce.com.csr \
-out harbor.nbrhce.com.crt
root@k8s-harbor1:/apps/certs
3.3 配置harbor证书信任
./install.sh --with-trivy --with-chartmuseum
root@k8s-harbor1:/apps/certs
root@k8s-ha-deploy:/apps/certs
root@k8s-ha-deploy:/apps/certs
root@k8s-ha-deploy:/apps/certs
root@k8s-ha-deploy:/apps/certs
ExecStart=/usr/bin/dockerd -H fd:// --insecure-registry=192.168.1.72:5000 --insecure-registry=harbor.nbrhce.com --containerd=/run/containerd/containerd.sock
更改完必要忘记重启&&重启完docker你会发现harbor也会宕机 你也需要重新启动一下
systemctl daemon-reload
systemctl restart docker
docker-compose restart 或者 docker-compsoe up -d
root@k8s-ha-deploy:/apps/harbor
Username:
password:
root@k8s-ha-deploy:/apps/harbor
root@k8s-ha-deploy:/apps/harbor
root@k8s-ha-deploy:/apps/harbor
有这个小锁头就代表配置成功了
测试push镜像到harbor 提前创建好项目
4. ansible部署
由于在导入Ansible 做自动化管理时,服务器版本太老,导致Python也相应比较旧,新版本的Ansible无法调用相关模块来管控
root@k8s-deploy:~
root@k8s-deploy:~
root@k8s-deploy:~
IP="
192.168.1.70
192.168.1.71
192.168.1.73
192.168.1.75
192.168.1.76
192.168.1.77
192.168.1.78
192.168.1.79
192.168.1.80
"
for node in ${IP} ;do
sshpass -p 123456 ssh-copy-id ${node} -o StrictHostKeyChecking=no
echo "${node} 密钥copy完成"
ssh ${node} ln -sv /usr/bin/python3 /usr/bin/python
echo "${node} /usr/bin/python3 软连接创建完成"
done
5. 下载kubeasz开源项目及组件
会有docker环境 是因为先用docker拉去镜像拷贝到容器里面在删除下载的镜像
hub.docker.io kubeasz-k8s-bin
5.1 下载开源项目
root@k8s-deploy:~
root@k8s-deploy:~
root@k8s-deploy:~
root@k8s-deploy:~
root@k8s-deploy:~
root@k8s-deploy:~
root@k8s-deploy:~
total 136
drwxrwxr-x 12 root root 4096 Nov 17 13 :22 ./
drwxr-xr-x 95 root root 4096 Nov 17 13 :22 ../
-rw-rw-r-- 1 root root 20304 Jul 3 20 :37 ansible.cfg
drwxr-xr-x 3 root root 4096 Nov 17 13 :22 bin/
drwxrwxr-x 8 root root 4096 Jul 3 20 :51 docs/
drwxr-xr-x 2 root root 4096 Nov 17 13 :30 down/
drwxrwxr-x 2 root root 4096 Jul 3 20 :51 example/
-rwxrwxr-x 1 root root 25012 Jul 3 20 :37 ezctl*
-rwxrwxr-x 1 root root 25266 Jul 3 20 :37 ezdown*
drwxrwxr-x 3 root root 4096 Jul 3 20 :51 .github/
-rw-rw-r-- 1 root root 301 Jul 3 20 :37 .gitignore
drwxrwxr-x 10 root root 4096 Jul 3 20 :51 manifests/
drwxrwxr-x 2 root root 4096 Jul 3 20 :51 pics/
drwxrwxr-x 2 root root 4096 Jul 3 20 :51 playbooks/
-rw-rw-r-- 1 root root 5058 Jul 3 20 :37 README.md
drwxrwxr-x 22 root root 4096 Jul 3 20 :51 roles/
drwxrwxr-x 2 root root 4096 Jul 3 20 :51 tools/
5.2 创建集群
root@k8s-deploy:/etc/kubeasz
2022-11-17 13:38:04 DEBUG generate custom cluster files in /etc/kubeasz/clusters/k8s-cluster1
2022-11-17 13:38:04 DEBUG set versions
2022-11-17 13:38:04 DEBUG cluster k8s-cluster1: files successfully created.
2022-11-17 13:38:04 INFO next steps 1: to config '/etc/kubeasz/clusters/k8s-cluster1/hosts'
2022-11-17 13:38:04 INFO next steps 2: to config '/etc/kubeasz/clusters/k8s-cluster1/config.yml'
5.3 更改hosts文件
root@k8s-ha1:/etc/kubeasz/clusters/k8s-cluster1
[etcd]
192.168.1.76
192.168.1.77
192.168.1.78
[kube_master]
192.168.1.70
192.168.1.71
[kube_node]
192.168.1.79
[harbor]
[ex_lb]
[chrony]
[all:vars]
SECURE_PORT="6443"
CONTAINER_RUNTIME="containerd"
CLUSTER_NETWORK="calico"
PROXY_MODE="ipvs"
SERVICE_CIDR="10.100.0.0/16"
CLUSTER_CIDR="10.200.0.0/16"
NODE_PORT_RANGE="30000-32767"
CLUSTER_DNS_DOMAIN="cluster.local"
bin_dir="/usr/local/bin"
base_dir="/etc/kubeasz"
cluster_dir="{{ base_dir }}/clusters/k8s-cluster1"
ca_dir="/etc/kubernetes/ssl"
root@k8s-ha1:/etc/kubeasz/clusters/k8s-cluster1
5.4 config.yaml
easzlab.io.local:5000/easzlab/pause:3.7
harbor.nbrhce.com/baseimages/pause:3.7
root@k8s-ha1:/etc/kubeasz/clusters/k8s-cluster1
INSTALL_SOURCE: "online"
OS_HARDEN: false
CA_EXPIRY: "876000h"
CERT_EXPIRY: "438000h"
CLUSTER_NAME: "cluster1"
CONTEXT_NAME: "context-{{ CLUSTER_NAME }}"
K8S_VER: "1.24.2"
ETCD_DATA_DIR: "/var/lib/etcd"
ETCD_WAL_DIR: ""
ENABLE_MIRROR_REGISTRY: false
SANDBOX_IMAGE: "harbor.nbrhce.com/baseimages/pause:3.7"
CONTAINERD_STORAGE_DIR: "/var/lib/containerd"
DOCKER_STORAGE_DIR: "/var/lib/docker"
ENABLE_REMOTE_API: false
INSECURE_REG: '["http://easzlab.io.local:5000","harbor.nbrhce.com"]'
MASTER_CERT_HOSTS:
- "192.168.1.72"
- "api.myserver.com"
NODE_CIDR_LEN: 23
KUBELET_ROOT_DIR: "/var/lib/kubelet"
MAX_PODS: 500
KUBE_RESERVED_ENABLED: "no"
SYS_RESERVED_ENABLED: "no"
FLANNEL_BACKEND: "vxlan"
DIRECT_ROUTING: false
flannelVer: "v0.15.1"
flanneld_image: "easzlab.io.local:5000/easzlab/flannel:{{ flannelVer }}"
CALICO_IPV4POOL_IPIP: "Always"
IP_AUTODETECTION_METHOD: "can-reach={{ groups['kube_master'][0] }}"
CALICO_NETWORKING_BACKEND: "brid"
CALICO_RR_ENABLED: false
CALICO_RR_NODES: []
calico_ver: "v3.19.4"
calico_ver_main: "{{ calico_ver.split('.')[0] }}.{{ calico_ver.split('.')[1] }}"
cilium_ver: "1.11.6"
cilium_connectivity_check: true
cilium_hubble_enabled: false
cilium_hubble_ui_enabled: false
OVN_DB_NODE: "{{ groups['kube_master'][0] }}"
kube_ovn_ver: "v1.5.3"
OVERLAY_TYPE: "full"
FIREWALL_ENABLE: true
kube_router_ver: "v0.3.1"
busybox_ver: "1.28.4"
dns_install: "no"
corednsVer: "1.9.3"
ENABLE_LOCAL_DNS_CACHE: false
dnsNodeCacheVer: "1.21.1"
LOCAL_DNS_CACHE: "169.254.20.10"
metricsserver_install: "no"
metricsVer: "v0.5.2"
dashboard_install: "no"
dashboardVer: "v2.5.1"
dashboardMetricsScraperVer: "v1.0.8"
prom_install: "no"
prom_namespace: "monitor"
prom_chart_ver: "35.5.1"
nfs_provisioner_install: "no"
nfs_provisioner_namespace: "kube-system"
nfs_provisioner_ver: "v4.0.2"
nfs_storage_class: "managed-nfs-storage"
nfs_server: "192.168.1.10"
nfs_path: "/data/nfs"
network_check_enabled: false
network_check_schedule: "*/5 * * * *"
HARBOR_VER: "v2.1.3"
HARBOR_DOMAIN: "harbor.easzlab.io.local"
HARBOR_TLS_PORT: 8443
HARBOR_SELF_SIGNED_CERT: true
HARBOR_WITH_NOTARY: false
HARBOR_WITH_TRIVY: false
HARBOR_WITH_CLAIR: false
HARBOR_WITH_CHARTMUSEUM: true
root@k8s-ha1:/etc/kubeasz/clusters/k8s-cluster1
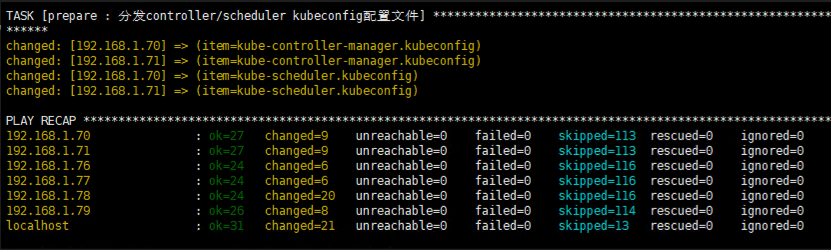
5.5更改ansible 01.prepare.yml文件
root@deploy-harbor:/etc/kubeasz
- hosts:
- kube_master
- kube_node
- etcd
roles:
- { role: os-harden, when: "OS_HARDEN|bool" }
- { role: chrony, when: "groups['chrony']|length > 0" }
- hosts: localhost
roles:
- deploy
- hosts:
- kube_master
- kube_node
- etcd
roles:
- prepare
6. 部署K8S群
通过ansible脚本初始化环境及部署ks高可用集群
root@k8s-ha1:/etc/kubeasz
Usage: ezctl COMMAND [args]
-------------------------------------------------------------------------------------
Cluster setups:
list to list all of the managed clusters
checkout <cluster> to switch default kubeconfig of the cluster
new <cluster> to start a new k8s deploy with name 'cluster'
setup <cluster> <step> to setup a cluster, also supporting a step-by-step way
start <cluster> to start all of the k8s services stopped by 'ezctl stop'
stop <cluster> to stop all of the k8s services temporarily
upgrade <cluster> to upgrade the k8s cluster
destroy <cluster> to destroy the k8s cluster
backup <cluster> to backup the cluster state (etcd snapshot)
restore <cluster> to restore the cluster state from backups
start-aio to quickly setup an all-in-one cluster with 'default' settings
Cluster ops:
add-etcd <cluster> <ip> to add a etcd-node to the etcd cluster
add-master <cluster> <ip> to add a master node to the k8s cluster
add-node <cluster> <ip> to add a work node to the k8s cluster
del-etcd <cluster> <ip> to delete a etcd-node from the etcd cluster
del-master <cluster> <ip> to delete a master node from the k8s cluster
del-node <cluster> <ip> to delete a work node from the k8s cluster
Extra operation:
kcfg-adm <cluster> <args> to manage client kubeconfig of the k8s cluster
Use "ezctl help <command>" for more information about a given command .
root@deploy-harbor:/etc/kubeasz
cat <<EOF
available steps:
01 prepare to prepare CA/certs & kubeconfig & other system settings
02 etcd to setup the etcd cluster
03 container-runtime to setup the container runtime(docker or containerd)
04 kube-master to setup the master nodes
05 kube-node to setup the worker nodes
06 network to setup the network plugin
07 cluster-addon to setup other useful plugins
90 all to run 01~07 all at once
10 ex-lb to install external loadbalance for accessing k8s from outside
11 harbor to install a new harbor server or to integrate with an existed one
6.1 创建集群基础设置
root@k8s-ha1:/etc/kubeasz
如果遇到卡导apt 进程了执行如下
sudo rm /var/lib/apt/lists/lock
sudo rm /var/cache/apt/archives/lock
sudo rm /var/lib/dpkg/lock*
sudo dpkg --configure -a sudo apt update
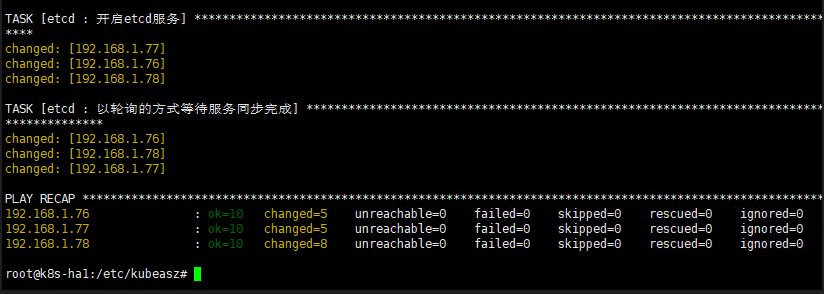
6.2 部署etcd集群
root@k8s-ha1:/etc/kubeasz
[plugins."io.containerd.grpc.v1.cri" .registry.mirrors."harbor.nbrhce.com" ]
endpoint = ["https://harbor.nbrhce.com" ]
[plugins."io.containerd.grpc.v1.cri" .registry.configs."harbor.nbrhce.com" .tls]
insecure_skip_verify = true
[plugins."io.containerd.grpc.v1.cri" .registry.configs."harbor.nbrhce.com" .auth]
username = "quyi"
password = "Harbor12345"
root@k8s-node1:~
systemctl daemon-reload
systemctl restart containerd
ln -s /opt/kube/bin/crictl /usr/bin
crictl pull harbor.nbrhce.com/demo/alpine:v1
root@k8s-ha1:/etc/kubeasz
export NODE_IPS="192.168.1.73 192.168.1.74 192.168.1.75"
for ip in ${NODE_IPS} ; do ETCDCTL_API=3 /opt/kube/bin/etcdctl --endpoints=https://${ip} :2379 --cacert=/etc/kubernetes/ssl/ca.pem --cert=/etc/kubernetes/ssl/etcd.pem --key=/etc/kubernetes/ssl/etcd-key.pem endpoint health;
done
https://192.168.1.76:2379 is healthy: successfully committed proposal: took = 8.57508ms
https://192.168.1.77:2379 is healthy: successfully committed proposal: took = 10.019689ms
https://192.168.1.78:2379 is healthy: successfully committed proposal: took = 8.723699ms
root@k8s-master1:~
6.3 部署运行时
root@k8s-ha1:/etc/ kubeasz
6.4 部署master集群
root@k8s-ha1:/etc/ kubeasz
上面都部署成功了之后 在部署机器上查看以下节点
root@k8s-ha1:/etc/ kubeasz
NAME STATUS ROLES AGE VERSION
192.168 .1.70 Ready,SchedulingDisabled master 102 s v1.24.2
192.168 .1.71 Ready,SchedulingDisabled master 102 s v1.24.2
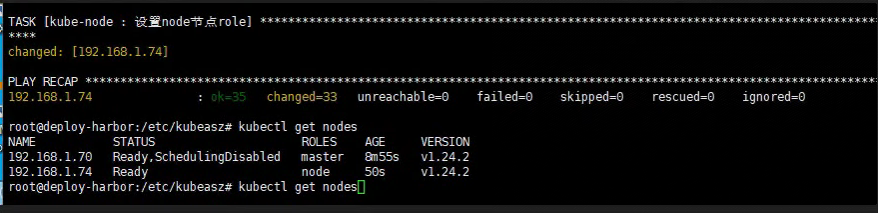
6.5 部署node节点
root@k8s-ha1:/etc/ kubeasz
root@deploy-harbor:/etc/ kubeasz
NAME STATUS ROLES AGE VERSION
192.168 .1.70 Ready,SchedulingDisabled master 8 m55s v1.24.2
192.168 .1.74 Ready node 50 s v1.24.2
6.6 部署calico
root@k8s-ha1:/etc/kubeasz
docker tag easzlab.io.local:5000/calico/node:v3.19.4 harbor.nbrhce.com/baseimages/calico/node:v3.19.4
docker push harbor.nbrhce.com/baseimages/calico/node:v3.19.4
docker tag calico/pod2daemon-flexvol:v3.19.4 harbor.nbrhce.com/baseimages/calico-pod2daemon-flexvol:v3.19.4
docker push harbor.nbrhce.com/baseimages/calico-pod2daemon-flexvol:v3.19.4
docker tag calico/cni:v3.19.4 harbor.nbrhce.com/baseimages/calico/cni:v3.19.4
docker push harbor.nbrhce.com/baseimages/calico/cni:v3.19.4
docker tag calico/kube-controllers:v3.19.4 harbor.nbrhce.com/baseimages/calico/kube-controllers:v3.19.4
docker push harbor.nbrhce.com/baseimages/calico/kube-controllers:v3.19.4
root@k8s-ha1:/etc/ kubeasz
root@k8s-ha1:/etc/kubeasz
root@deploy-harbor:/etc/kubeasz
NAME STATUS ROLES AGE VERSION
192.168.1.70 Ready,SchedulingDisabled master 21h v1.24.2
192.168.1.74 Ready node 21h v1.24.2
root@deploy-harbor:/etc/kubeasz
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-68555f5f97-fks8p 1/1 Running 1 (99m ago) 21h
kube-system calico-node-gdc8m 1/1 Running 40 (9m8s ago) 21h
kube-system calico-node-h5drr 1/1 Running 36 (78s ago) 21h
7. 运行容器测试
root@deploy-harbor:/etc/kubeasz
root@deploy-harbor:/etc/kubeasz
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
net-test1 1/1 Running 0 66s 10.200.36.65 192.168.1.74 <none> <none>
root@deploy-harbor:/etc/kubeasz
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
[root@net-test1 /]
ping: baidu.com: Name or service not known
8. 添加master节点(扩容/缩容)
root@k8s-node1:~
user root;
worker_processes 1;
error_log /etc/kube-lb/logs/error.log warn;
events {
worker_connections 3000;
}
stream {
upstream backend {
server 192.168.1.70:6443 max_fails=2 fail_timeout=3s;
}
server {
listen 127.0.0.1:6443;
proxy_connect_timeout 1s;
proxy_pass backend;
}
}
root@deploy-harbor:/etc/kubeasz
root@deploy-harbor:/etc/kubeasz
9. 添加node节点(扩容/缩容)
root@deploy-harbor:/etc/kubeasz
root@deploy-harbor:/etc/kubeasz
10. K8S升级(小版本)
10.1 官方位置
10.2 下载二进制安装包
10.3 master升级
root@k8s-node1:~
user root;
worker_processes 1;
error_log /etc/kube-lb/logs/error.log warn;
events {
worker_connections 3000;
}
stream {
upstream backend {
}
server {
listen 127.0.0.1:6443;
proxy_connect_timeout 1s;
proxy_pass backend;
}
}
systemctl stop kube-apiserver kube-sontroller-manager kube-scheduler kube-proxy kubelet
kube-apiserver kube-sontroller-manager kube-scheduler kube-proxy kubelet
/usr/local/bin
/usr/local/bin/kube-apiserver --version
vim /var/lib/kube-proxy/kube-proxy-config.yaml
api版本是指
apiVersion: kubeproxy.config.k8s.io/v1alpha1
systemctl start kube-apiserver kube-sontroller-manager kube-scheduler kube-proxy kubelet
kubectl get nodes
systemctl reload kube-lb.service
以上都是升级master
10.4 node升级
一定要驱除pod然后将服务停止然后替换二进制
kubectl drain 192.168.x.x --ignore-daemonsets --force
kubectl get pods -A -o wide
systemctl stop kubelet kube-proxy
kubelet kube-proxy /usr/local/bin
systemctl reload kube-lb.service
vim /etc/kube-lb/conf/kube-lb.conf
cp ./* /etc/kubeasz/bin/containerd-bin/
10.5 containerd升级runc升级客户端命令升级
wget https://github.com/containerd/containerd/releases/download/v1.6.10/containerd-1.6.10-linux-amd64.tar.gz
cp ./* /etc/kubeasz/bin/containerd-bin/
wget https://github.com/opencontainers/runc/releases/download/v1.1.4/runc.amd64
scp ./* 192.168.*:/usr/local/bin/
拷贝的时候会发现runc是拷贝不了的 因为node有占用
systemctl disable kubelet kube-proxy
systemctl disable containerd.setvice
reboot
然后在拷贝二进制命令
scp ./* 192.168.*:/usr/local/bin/
systemctl enable --now kubelet kube-proxy containerd.setvice
systemctl restart kubelet
scp ./* 192.168.*:/usr/local/bin/
systemctl disable kubelet kube-proxy
systemctl disable containerd.setvice
reboot
systemctl enable --now kubelet kube-proxy containerd.setvice