
PostgreSQL流复制之二:pgpool-II实现PostgreSQL数据库集群(转发+整理)
转发来源:
PostgreSQL的集群技术比较:https://iwin.iteye.com/blog/2108807
参考:https://blog.csdn.net/yaoqiancuo3276/article/details/80983201
参考:https://blog.csdn.net/yaoqiancuo3276/article/details/80805783
参考:https://my.oschina.net/u/3308173/blog/900093?nocache=1494825611692
参考:http://www.pgpool.net/docs/latest/en/html/example-cluster.html
pgpool-II实现PostgreSQL数据库集群
以三台服务器,部署三个postgreSQl数据,一Master、2个Standby。在三台服务器上部署pgpool来管理数据库集群为例。

一、数据规划:
PostgreSQL库的IP/Port规划:
|
主库地址/端口 |
10.10.10.1 / 5432 |
|
备库2地址/端口 |
10.10.10.2 / 5432 |
|
备库3地址/端口 |
10.10.10.3 / 5432 |
Pgpool-II的IP/Port规划:
|
Pgpool-II使用的端口 |
9999 |
|
Pgpool-II管理的数据库浮动IP |
10.10.10.101 |
|
Pgpool-II看门狗心跳端口 |
9694 |
|
pgpool-II 服务器上的需要被监控的看门狗的端口 |
9000 |
注:由于安全原因,我们创建了一个单独用于复制目的的用户(u_standby),以及一个用于Pgpool-II流复制延迟检查和健康检查的用户(pgcheck)。
|
1、postgreSQL数据库用户名/密码 2、执行恢复的用户(恢复:主库故障后切换,原主库恢复后变更为备库)User running online recovery |
Postgre / 123456 |
|
postgreSQL备、主库流复制用户名/密码 |
u_standby / standby123 |
|
Pgpool-II监看健康检查用户/密码(需在数据库开户,具备查询权限) |
pgcheck / 123456 |
二、安装配置pgpool-II
步骤一:已经搭建好数据库,并配置流复制
搭建过程见:PostgreSQL流复制之一:原理+环境搭建
步骤二:主、备库安装pgpool-II
1、 主库上安装pgpool-II工具(采用root权限用户)
下载—>解压,在解压目录下:make编译—>make install安装
2、 安装pgpool-II的扩展函数(使用数据库postgres用户)
(1) 安装pgpool_regclass扩展函数
pgpool-II解压目录/src/sql 下执行 make—>make install
pgpool-II解压目录/src/sql/pgpool-regclass 下执行:
psql -p 5433 -f pgpool-regclass.sql template1

(2) 建立insert_lock表
pgpool-II解压目录/src/sql下执行:
psql -p 5433 -f insert_lock.sql template1
![]()
(3) 安装pgpool_recovery扩展函数
pgpool-II解压目录/src/sql/pgpool-recovery下执行make install
pgpool-II解压目录/src/sql/pgpool-recovery下执行:
psql -p 5433 -f pgpool-recovery.sql template1
![]()
3、 在2个备库上安装pgpool-II工具。(同主库操作)
下载—>解压,在解压目录下:make编译—>make install安装
4、 检查2个备库已具备pgpool-II扩展函数。(注:扩展函数在数据库中,数据库的主备流复制已经复制到备库,不需要重复安装)
postgres=# select * from pg_extension;
extname | extowner | extnamespace | extrelocatable | extversion | extconfig | extcondition
-----------------+----------+--------------+----------------+------------+-----------+--------------
plpgsql | 10 | 11 | f | 1.0 | |
pgpool_regclass | 10 | 2200 | t | 1.0 | |
pgpool_recovery | 10 | 2200 | t | 1.1 | |
(3 rows)
步骤三:主库配置pgpool-II
pgpool有四个主要的配置文件,分别是
- pcp.conf 用于管理查、看节点信息,如加入新节点。该文件主要是存储用户名及md5形式的密码。
- pgpool.conf 用于设置pgpool的模式,主次数据库的相关信息等。
- pool_hba.conf 用于认证用户登录方式,如客户端IP限制等,类似于postgresql的pg_hba.conf文件。
- pool_passwd 用于保存相应客户端登录帐号名及md5密码。
1、 配置pgpool.conf
listen_addresses = '*' # rtm用于pgpool监听地址,控制哪些地址可以通过pgpool 连接,`*`表示接受所有连接
port = 9999 # rtm pgpool 监听的端口
pcp_listen_addresses = '*' # rtm
pcp_port = 9898 # rtm
backend_hostname0 = '10.10.10.1' # rtm 配置后端postgreSQL 数据库地址,此处为主库
backend_port0 = 5432 # rtm 后端postgreSQL 数据库端口
backend_weight0 = 1 # rtm 权重,用于负载均衡
backend_data_directory0 = '/pgdata/ha/masterdata' # rtm 后端postgreSQL 数据库实例目录
backend_flag0 = 'ALLOW_TO_FAILOVER' # rtm 允许故障自动切换
backend_hostname1 = '10.10.10.2' # rtm 此处为备库1数据库地址
backend_port1 = 5432 # rtm
backend_weight1 = 1 # rtm
backend_data_directory1 = '/pgdata/ha/slavedata' # rtm
backend_flag1 = 'ALLOW_TO_FAILOVER' # rtm
backend_hostname2 = '10.10.10.3' # rtm 此处为备库2数据库地址
backend_port2 = 5432 # rtm
backend_weight2 = 1 # rtm
backend_data_directory2 = '/pgdata/ha/slavedata' # rtm
backend_flag2 = 'ALLOW_TO_FAILOVER' # rtm
enable_pool_hba = on # rtm 开启pgpool认证,需要通过 `pool_passwd` 文件对连接到数据库的用户进行md5认证
pool_passwd = 'pool_passwd' # rtm 认证文件
log_destination = 'stderr,syslog' # rtm 日志级别,标注错误输出和系统日志级别
log_line_prefix = '%t: pid %p: ' # rtm 日志输出格式
log_connections = on # rtm 开启日志
log_hostname = on # rtm 打印主机名称
#log_statement = all # rtm 取消注释则打印sql 语句
#log_per_node_statement = on # rtm 取消注释则开启打印sql负载均衡日志,记录sql负载到每个节点的执行情况
#client_min_messages = log # rtm 日志
#log_min_messages = info # rtm # 日志级别
pid_file_name = '/opt/pgpool-3/run/pgpool/pgpool.pid' # rtm pgpool的运行目录,若不存在则先创建
logdir = '/opt/pgpool-3/log/pgpool' # rtm 指定日志输出的目录
replication_mode = off # rtm 关闭pgpool的复制模式
load_balance_mode = on # rtm 开启负载均衡
master_slave_mode = on # rtm 开启主从模式
master_slave_sub_mode = 'stream' # rtm设置主从为流复制模式
sr_check_period = 10 # rtm 流复制的延迟检测的时间间隔
sr_check_user = 'pgcheck' # rtm Specifiy replication delay check user and password,该用户需要在pg数据库中存在,且拥有查询权限
sr_check_password = '123456' # rtm Pgpool-II 4.0开始,如果这些参数为空,Pgpool-II将首先尝试从sr_check_password文件中获取指定用户的密码
sr_check_database = 'postgres' # rtm 流复制检查的数据库名称
delay_threshold = 10000000 # rtm 设置允许主备流复制最大延迟字节数,单位为kb。定义slave库能够接收读请求所允许的最大延迟时间。比如:设置为1024,slave库只允许滞后master库1KB 的XLOG;否则,slave库将不会接收到请求。
health_check_period = 10 # rtm pg数据库检查检查间隔时间。定义系统应该多久检查一次哪些XLOG位置,以弄清楚是否是延迟太高或太低。
health_check_timeout = 20 # rtm
health_check_user = 'pgcheck' # rtm 健康检查用户,需pg数据库中存在。连接到primary来检查当前XLOG的位置的用户名。
health_check_password = '123456' # rtm 设置方法同sr_check_password
health_check_database = 'postgres' # rtm 健康检查的数据库名称
health_check_max_retries = 3 # rtm 健康检查最大重试次数
health_check_retry_delay = 3 # rtm 重试次数间隔
failover_command = '/etc/pgpool-II/failover.sh %d %h %p %D %m %H %M %P %r %R' # rtm 在failover_command参数中指定failover后需要执行的failover.sh脚本
follow_master_command = '/etc/pgpool-II/follow_master.sh %d %h %p %D %m %M %H %P %r %R' # rtm如果使用3台PostgreSQL服务器,需要在主节点切换后指定follow_master_command运行,如果是两PostgreSQL服务器,则不需要设置 follow_master_command。
fail_over_on_backend_error = off # rtm 如果设置了health_check_max_retries次数,则关闭该参数
use_watchdog = on # rtm 开启看门狗,用于监控pgpool 集群健康状态
wd_hostname = '10.10.10.1' # rtm 本地看门狗地址,配置为当前库的IP
wd_port = 9000 # rtm
wd_priority = 1 # rtm 看门狗优先级,用于pgpool 集群中master选举
delegate_IP = '10.10.10.101' # rtm 在三个库上指定接受客户端连接的虚拟IP地址。
if_up_cmd = 'ip addr add $_IP_$/24 dev eth0 label eth0:0' # rtm 配置虚拟IP到本地网卡
if_down_cmd = 'ip addr del $_IP_$/24 dev eth0' # rtm
wd_lifecheck_method = 'heartbeat' # rtm 看门狗健康检测方法
wd_heartbeat_port = 9694 # rtm 看门狗心跳端口,用于pgpool 集群健康状态通信
wd_heartbeat_keepalive = 2 # rtm 看门狗心跳检测间隔
wd_heartbeat_deadtime = 30 # rtm
heartbeat_destination0 = '10.10.10.2' # rtm 配置需要监测健康心跳的IP地址,非本地地址,即互相监控,配置对端的IP地址
heartbeat_destination_port0 = 9694 # rtm 监听的端口
heartbeat_device0 = 'eth0' # rtm 监听的网卡名称
heartbeat_destination1 = '10.10.10.3' # rtm 配置需要监测健康心跳的IP地址,非本地地址,即互相监控,配置对端的IP地址
heartbeat_destination_port1 = 9694 # rtm 监听的端口
heartbeat_device1 = 'eth0' # rtm
wd_life_point = 3 # rtm 生命检测失败后重试次数
wd_lifecheck_query = 'SELECT 1' # rtm 用于检查 pgpool-II 的查询语句。默认为“SELECT 1”。
wd_lifecheck_dbname = 'postgres' # rtm 检查健康状态的数据库名称
wd_lifecheck_user = 'pgcheck' # rtm 检查数据库的用户,该用户需要在Postgres数据库存在,且有查询权限
wd_lifecheck_password = '123456' # rtm 看门狗健康检查用户密码
other_pgpool_hostname0 = '10.10.10.2' # rtm 指定被监控的 pgpool-II 服务器的主机名
other_pgpool_port0 = 9999 # rtm 指定被监控的 pgpool-II 服务器的端口号
other_wd_port0 = 9000 # rtm 指定 pgpool-II 服务器上的需要被监控的看门狗的端口号
other_pgpool_hostname1 = '10.10.10.3' # rtm 指定被监控的 pgpool-II 服务器的主机名
other_pgpool_port0 = 9999 # rtm 指定被监控的 pgpool-II 服务器的端口号
other_wd_port0 = 9000 # rtm 指定 pgpool-II 服务器上的需要被监控的看门狗的端口号
2、 配置pool_passwd,该文件用于配置哪些用户可以访问pgpool。使用如下命令生成:
pg_md5 -p -m -u postgres pool_passwd //执行后输入密码
通过如上命令,设置数据库的postgre用户名和密码,及pgpool进行健康检查的pgcheck用户名和密码。
3、 配置.pgpass。使用pgpool-II进行故障库自动切换(failover)、或在线恢复(online recovery)(在线恢复:主库故障后切换,原主库恢复后变更为备库。注意是Online recovery,而不是自动恢复,需要手工执行命令恢复),需要能够无密码SSH访问其他postgreSQL服务器。为了满足此条件,我们需要在每个postgreSQL服务器上,在postgres用户的home file下创建了.pgpass文件,并修改器文件权限为600。
[all servers]# su - postgres
[all servers]$ vi /var/lib/pgsql/.pgpass
10.10.10.1:5432:replication:repl:<repl user password>
10.10.10.2:5432:replication:repl:<repl user passowrd>
10.10.10.3:5432:replication:repl:<repl user passowrd>
[all servers]$ chmod 600 /var/lib/pgsql/.pgpass
4、 配置pcp.conf。由于pcp命令需要用户认证,该在文件中指定配置pcp命令的pgpool用户的用户名、密码。格式:
用户名:密码MD5编码
注:密码的MD5编码看通过“pg_md5” 密码命令生成
5、 配置pcp的.pcppass。需要follow_master_command脚本情况下,由于此脚本必须在不输入密码的情况下执行pcp命令,所以我们在Pgpool-II用户(root用户)的home directory下创建.pcppass:
# echo 'localhost:9898:pgpool:pgpool' > ~/.pcppass
# chmod 600 ~/.pcppass
6、 配置pool_hba.conf认证文件,类似于PostgreSQL的pg_hba.conf文件。
步骤四:备库配置pgpool-II
类同主库配置pgpool-II步骤:
1、 配置pgpool.conf。类同主库pgpool-II配置。以备库1配置pgpool.conf为例:修改配置中主库、备库2的IP:
use_watchdog = on # rtm 开启看门狗,用于监控pgpool 集群健康状态
wd_hostname = '10.10.10.2' # rtm 本地看门狗地址,配置为当前库地址
wd_port = 9000 # rtm
wd_priority = 1 # rtm 看门狗优先级,用于pgpool 集群中master选举
wd_lifecheck_method = 'heartbeat' # rtm 看门狗健康检测方法
wd_heartbeat_port = 9694 # rtm 看门狗心跳端口,用于pgpool 集群健康状态通信
wd_heartbeat_keepalive = 2 # rtm 看门狗心跳检测间隔
wd_heartbeat_deadtime = 30 # rtm
heartbeat_destination0 = '10.10.10.1' # rtm 配置需要监测健康心跳的IP地址,非本地地址,即互相监控,配置对端的IP地址
heartbeat_destination_port0 = 9694 # rtm 监听的端口
heartbeat_device0 = 'eth0' # rtm 监听的网卡名称
heartbeat_destination1 = '10.10.10.3' # rtm 配置需要监测健康心跳的IP地址,非本地地址,即互相监控,配置对端的IP地址
other_pgpool_hostname0 = '10.10.10.1' # rtm 指定被监控的 pgpool-II 服务器的主机名
other_pgpool_port0 = 9999 # rtm 指定被监控的 pgpool-II 服务器的端口号
other_wd_port0 = 9000 # rtm 指定 pgpool-II 服务器上的需要被监控的看门狗的端口号
other_pgpool_hostname1 = '10.10.10.3' # rtm 指定被监控的 pgpool-II 服务器的主机名
other_pgpool_port0 = 9999 # rtm 指定被监控的 pgpool-II 服务器的端口号
other_wd_port0 = 9000 # rtm 指定 pgpool-II 服务器上的需要被监控的看门狗的端口号
2、 其他部署类同主库配置。
步骤五:启动pgpool-II
注:
- 启动pgpool-II前,必须先启动PostgreSQL;同理,停止PostgreSQL前,必须先停止pgpool-II.
- 上面步骤中,配置的三个库的优先级一致(backend_weight)。所以Pgpool-II节点角色取决于Pgpool-II启动的先后顺序
分别在主库、备库1、备库2执行如下命令启动pgpool-II: pgpool -n -d > pgpool.log 2>&1 &
1、 pgpool-II先启动的库,如下打印
显示角色是主库。看门狗向另外两个库发送心跳,也接收另外另个库的响应。
DEBUG: STATE MACHINE INVOKED WITH EVENT = STATE CHANGED Current State = MASTER
DEBUG: watchdog heartbeat: send heartbeat signal to 10.10.10.2:9694
DEBUG: watchdog heartbeat: send heartbeat signal to 10.10.10.3:9694
DEBUG: received heartbeat signal from 。。。。
2、 pgpool-II后启动的库,如下打印
显示角色是备库。看门狗向另外两个库发送心跳,也接收另外另个库的响应。
DEBUG: STATE MACHINE INVOKED WITH EVENT = PACKET RECEIVED Current State = STANDBY
DEBUG: watchdog heartbeat: send heartbeat signal to 10.10.10.1:9694
DEBUG: watchdog heartbeat: send heartbeat signal to 10.10.10.3:9694
DEBUG: received heartbeat signal from "10.10.10.1(10.10.10.1):9999" node:10.10.10.1:9999 Linux CLWDB3
DEBUG: received heartbeat signal from "10.10.10.3(10.10.10.3):9999" node:Not_Set
3、 查看VIP
在主库上执行:#ip addr,看到10.10.10.101虚拟IP绑定在主库的eth0上。
步骤六:查看pgpool集群状态
1、 通过pgpool命令查看pgpool中库状态(IP为pgpool的VIP)
执行:psql -h 10.10.56.87 -p 9999 -U postgres pgpool

其他命令:
查看pgpool配置:# show pool_status;
查看pgpool连接池:# show pool_pools;
2、 通过pcp管理pgpool。Pcp是管理pgpool的linux命令。
(1) 查看pgpool集群状态(IP为pgpool的VIP)
# pcp_watchdog_info -h 10.10.10.101 -p 9898 -U pgcheck -v
可以看到集群Node的IP、Port、状态,虚拟IP绑定的Node等信息。
(2) 查看pgpool集群Node数量(IP为pgpool的VIP)
# pcp_node_count -h 10.10.10.101 -p 9898 -U pgcheck -v
(3) 查看pgpool集群配置(IP为pgpool的VIP)
# pcp_pool_status -h 10.10.10.101 -p 9898 -U pgcheck -v
(4) 查看pgpool processer进程状态连接池(IP为pgpool的VIP)
#pcp_proc_count -h 10.10.10.101 -p 9898 -U pgcheck -v
步骤七:配置主库故障自动切换脚本
PostgreSQL流复制,支持故障情况下两种方式切换:
- recovery.conf配置文件中指定trigger_file(trigger_file = '/home/postgres/pg11/trigger'),且trigger_file在备库中存在,则主库故障自动切换。
- 在备库上通过pg_ctl promote命令使备库升主。
在pgpool-II工具场景下,pgpool-II的pgpool.conf配置文件中支持指定故障切换脚本。尤其是多库场景下,此方式可根据用户需要自定义切换规则,在脚本中通过pg_ctl promote命令方式触发指定的备库升主:
failover_command = '/etc/pgpool-II/failover.sh %d %h %p %D %m %H %M %P %r %R' # rtm 在failover_command参数中指定failover后需要执行的failover.sh脚本
failover.sh样例见附录,部分逻辑如下:
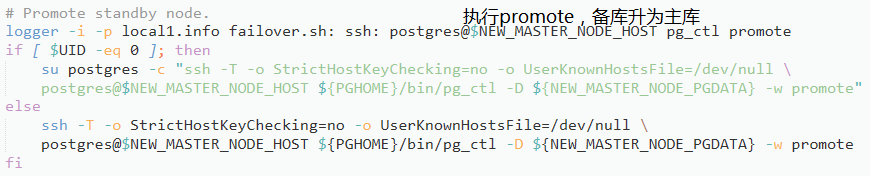
follow_master_command样例见附录,部分逻辑如下:
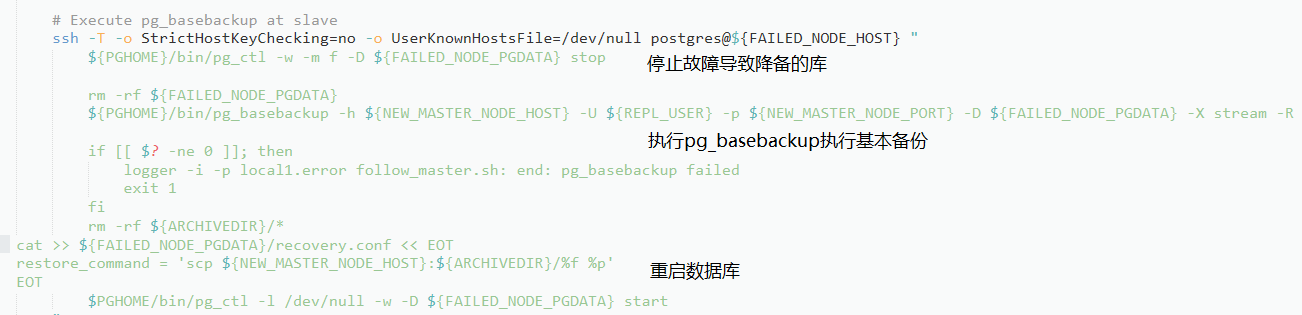
切换过程观察:
1) 切换前状态
# pcp_watchdog_info -h 10.10.10.101 -p 9898 -U pgcheck –v
Host Name : 10.10.10.1
Status Name : MASTER
Host Name : 10.10.10.2
Status Name : STANDBY
Host Name : 10.10.10.3
Status Name : STANDBY
2) 停止主库。可以stop Pgpool-II service或shutdown整个主库
systemctl stop pgpool.service
3) 切换后组状态:
# pcp_watchdog_info -h 10.10.10.101 -p 9898 -U pgcheck –v
Host Name : 10.10.10.1
Status Name : STANDBY
Host Name : 10.10.10.2
Status Name : MASTER
Host Name : 10.10.10.3
Status Name : STANDBY
步骤八:配置故障库恢复后变更为备库(online recovery)
我们期望原主库故障后,恢复后能自动变更为备库,需要:
- 安装pgpool_recovery、pgpool_remote_start、pgpool_switch_xlog扩展函数,方法参考安装步骤。
- 确保原主库recovery_1st_stage和pgpool_remote_start。
1) 配置pgpool.conf文件
在线恢复需要PostgreSQL的超级组权限,所以指定postgres用户为recovery_user。
recovery_user = 'postgres' # Online recovery user
recovery_password = '' # Online recovery password
recovery_1st_stage_command = 'recovery_1st_stage'
2) 在原主库服务器 (10.10.10.1) 的数据库集群目录下创建recovery_1st_stage和pgpool_remote_start,并添加可执行权限。详细脚本参考附录。
# su - postgres
$ vi /var/lib/pgsql/11/data/recovery_1st_stage
$ vi /var/lib/pgsql/11/data/pgpool_remote_start
$ chmod +x /var/lib/pgsql/11/data/{recovery_1st_stage,pgpool_remote_start}
recovery_1st_stage脚本内容见附件,部分逻辑如下:

3) 使用pcp命令执行恢复备库节点(如下地址为数据库集群的虚拟地址)
# pcp_recovery_node -h 10.10.10.101 -p 9898 -U pgpool -n 0
Password:
pcp_recovery_node -- Command Successful
附1:failover.sh、fialover_master.sh、recovery_1st_stag、pgpool_remote_start件样例参考:http://www.pgpool.net/docs/latest/en/html/example-cluster.html

