
B树、B+树、B*树三者的对比详解
转载至:https://www.2cto.com/database/201805/745822.html
对比
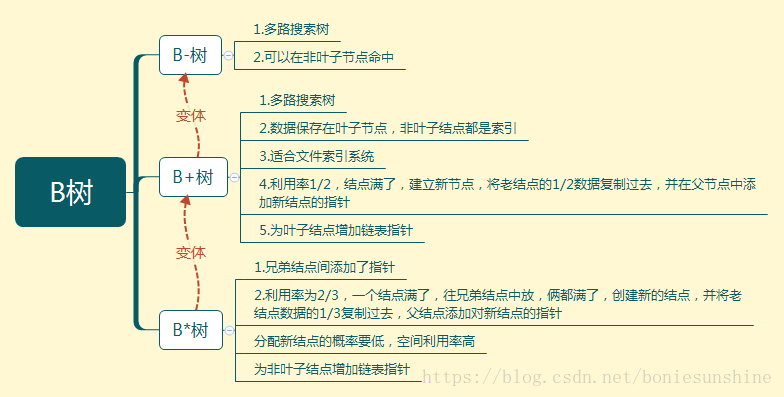
B+树是B树的变体,B*树又是B+树的变体,是一脉相承法治国拉的,不断解决新一阶段的问题。
B树解决的是能快速查询到指定树的问题和查询一个数出现的频率的问题。数据存在叶子节点和非叶子结点中。多路搜索的时候走的树高度不高,所以查询用的时间很短。
B+树适合扫库,解决的是查询某一范围内的数据。它的数据只存在叶子结点中,非叶子结点存的是索引,所以显而易见,B+树不适合搜索某一特定的值,因为到叶子节点的路径肯定要比B树的非叶子结点要短;
B*树的空间利用率高。相比B+树结点满了就建新结点的做法,B*树是先往兄弟结点中放,都放满了再开辟新的结点,创建新结点少,所以空间利用率高。
小结
就像事务的隔离级别一样,一个级别的出现都是背负着解决上一个级别解决不了的问题的使命;B树之间也是这样,客观要求不同了,数据结构也与时俱进。在mysql中用的就是B+树的聚集索引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号