数据结构学习笔记(五)--单链表
数据结构学习笔记(五)--单链表
点击进入上一篇:数据结构学习笔记(四)--顺序表
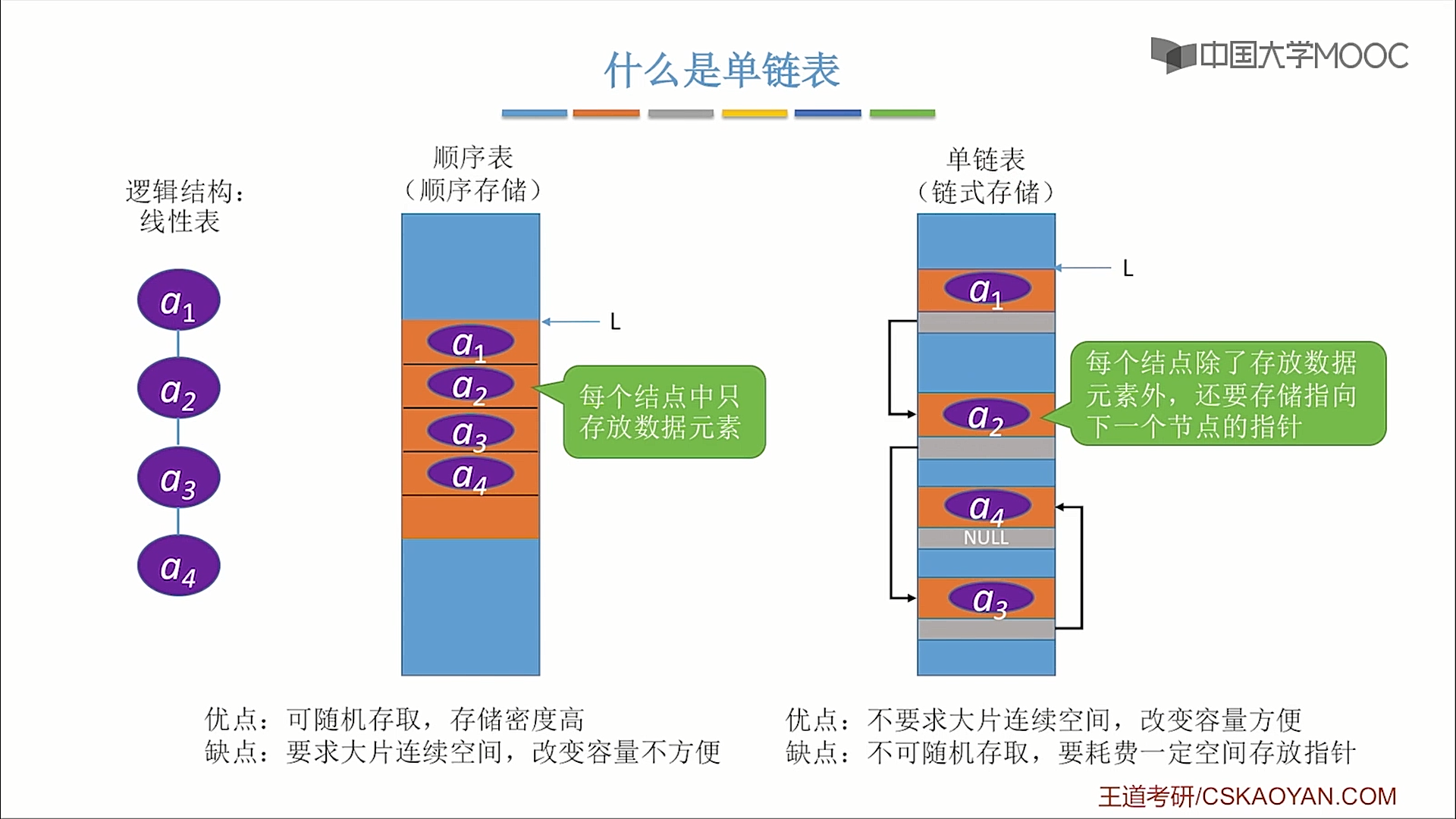
单链表的定义
为用链式存储的方式实现的线性表,与顺序表的异同如图所示:
用代码定义一个单链表
用c/c++实现,如下:
typedef struct LNode{ //定义单链表节点类型
int data; //每个节点存放一个整型元素
struct LNode *next; //指针指向下一个节点
} LNode, *LinkList; //对变量及指针分别命名
代码其实等价于:
typedef struct LNode{ //定义单链表节点类型
int data; //每个节点存放一个整型元素
struct LNode *next; //指针指向下一个节点
};
typedef struct LNode LNode; //对结构体变量 struct LNode 重命名为LNode
typedef struct LNode *Linklist; //对指向结构体变量 struct LNode 的指针重命名为LinkList(等价于LNode *,但侧重于单链表本身,可读性更强)
初始化一个单链表
不带头结点
用C/C++表示,如下:
typedef struct LNode{ //定义单链表节点类型
int data; //每个节点存放一个整型元素
struct LNode *next; //指针指向下一个节点
} LNode, *LinkList; //对变量及指针分别命名
//初始化一个空的单链表(即不带头结点)
bool InitList(LinkList &L) {
L = NULL; //空表,暂时还没有任何节点(防止脏数据)
return true;
}
int main(){
LinkList L; //声明一个指向单链表的指针
//初始化一个空表
InitList(L);
//......后续代码....
return 0;
}
判断是否为空
用C/C++表示,如下:
bool Empty(LinkList L){
return (L==NULL);
}
带头结点
头指针并不初始化,而分配一个初始值,用C/C++表示,如下:
//定义节点类型不变,还是一样
typedef struct LNode{ //定义单链表节点类型
int data; //每个节点存放一个整型元素
struct LNode *next; //指针指向下一个节点
} LNode, *LinkList; //对变量及指针分别命名
//初始化一个单链表(带头结点)
bool InitList(LinkList &L) {
L = (LNode *) malloc(sizeof(LNode)); //内存中分配一个头结点那么大的空间给该指针
if(L==NULL){ //内存不足,分配失败
return false;
}
L->next = NULL; //头结点之后暂时还没有结点,头结点的下一指针指向空(即初始化)
return true;
}
判断是否为空
用C/C++表示,如下:
bool Empty(LinkList L){
//这里判断头结点的下一个节点是否为空
return (L->next==NULL);
}
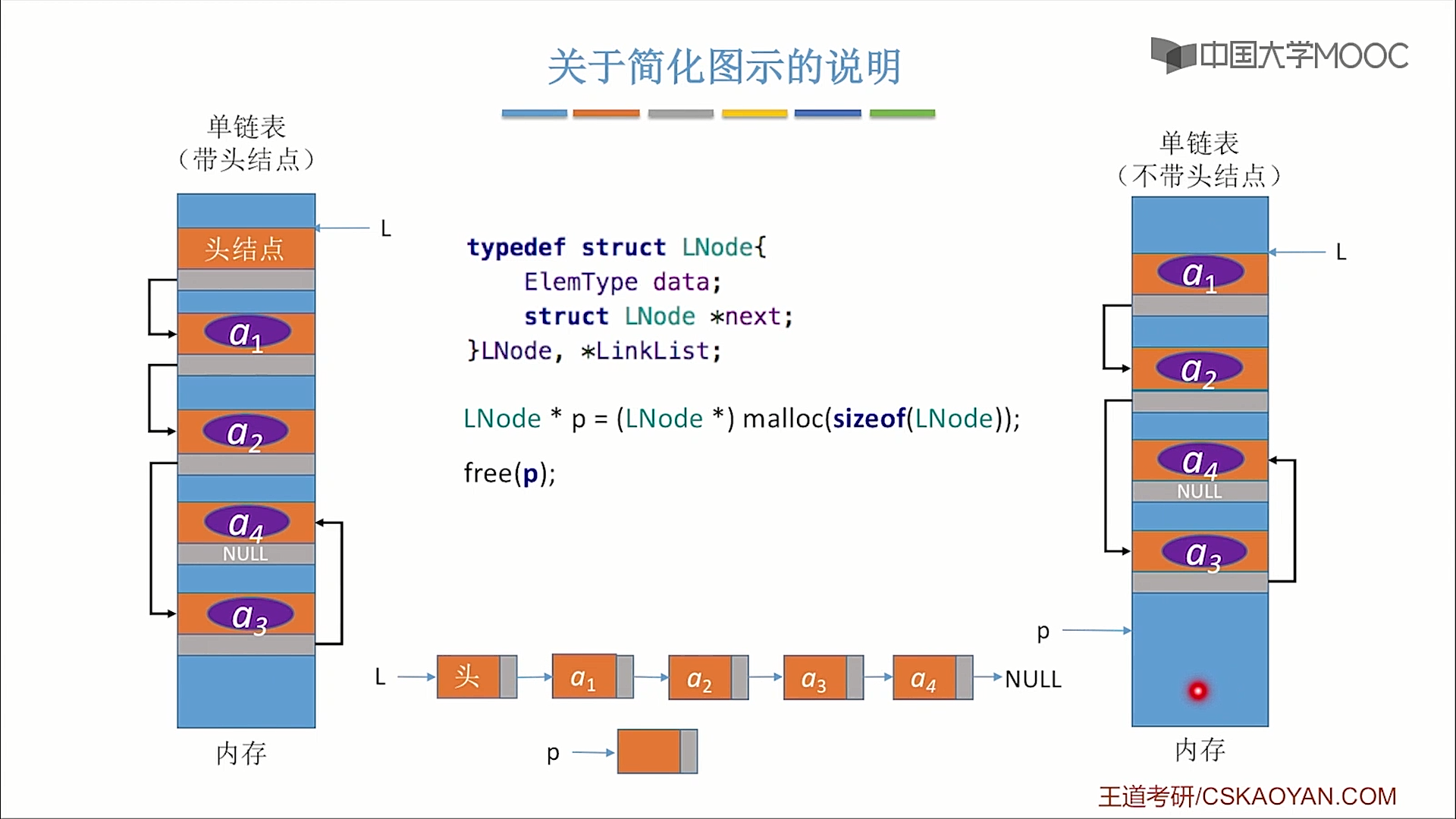
是否带头结点的区别
不带头结点,写代码更麻烦,对第一个数据节点和后续节点的代码逻辑不同,对空表与非空表的处理也需要用不同的代码逻辑;而带头结点则不然。因此,带头结点更方便。
不带头结点的头指针指向的结点会存放数据元素。
带头结点的头指针指向的结点不会存放数据元素,只存放下一节点的指针
如图所示:
单链表的基本操作
位序插入
分为带头结点与不带头结点两部分。
带头结点
大致思路为:
- 根据单链表指针指向遍历,从表头一直指向所需位序的上一个结点P。
- 新建一个结点S。
- 将新建结点S的data值赋值,再将next指针赋值为上一个结点P的next指针指向。
- 再将P的next指针指向S。
代码实现
用C/C++表示,如下:
//在第i个位置插入元素e(带头结点)
bool ListInsert(LinkList &L,int i,int e){
if(i<1)
return false;
LNode *p; //指针p指向当前扫描到的结点
int j = 0; //当前p指向结点的位序
p = L; //L指向头结点,头结点是第0个结点(不存数据)
while(p!=NULL && j<i-1){ //循环找到第i-1个结点
p=p->next;
j++;
}
if(p==NULL) //i值不合法,由所查位序大于单链表本身长度所致
return false;
LNode *s = (LNode *)malloc(sizeof(LNode));
s->data = e;
s->next = p->next;
p->next = s; //将结点s连到p之后
return true; //插入成功
}
插入操作的时间复杂度
- 最好情况:结点插入到表头,最好时间复杂度 = O(1)
- 最坏情况:结点插入到表尾,最坏时间复杂度 = O(n)
- 平均情况:结点插入到表中,平均时间复杂度 = O(n)
不带头结点
大致思路与带头结点类似,但需要注意:
- 不带头结点的单链表对插入表头需要特殊处理
- 插入表头时,先由内存分配一个新节点s,对其赋值data,并将节点的next指针赋值,指向原来的表头所在节点。
- 然后将原来的头指针指向新结点s
- 之后的结点处理与带头结点的相同,但不带头结点的单链表没有位序为0的头结点,所以位序从1开始。
代码实现
用C/C++表示,如下:
//在第i个位置插入元素e(不带头结点)
bool ListInsert(LinkList &L,int i,int e){
if(i<1)
return false;
if(i==1){ //插入第一个结点的操作与其他结点操作不同
LNode *s = (LNode *)malloc(sizeof(LNode));
s->data = e;
s->next = L; //第一个结点next指针指向原来的第一个结点
L = s; //头指针指向新结点
return true;
}
LNode *p; //指针p指向当前扫描到的结点
int j = 1; //当前p指向结点的位序(这里和带头指针的不同)
p = L; //L指向头结点,头结点是第0个结点(不存数据)
while(p!=NULL && j<i-1){ //循环找到第i-1个结点
p=p->next;
j++;
}
if(p==NULL) //i值不合法,由所查位序大于单链表本身长度所致
return false;
LNode *s = (LNode *)malloc(sizeof(LNode));
s->data = e;
s->next = p->next;
p->next = s; //将结点s连到p之后
return true; //插入成功
}
插入操作的时间复杂度
与带头节点的插入操作时间复杂度一致,不再赘述。
指定结点的插入
可分为指定结点的后插与前插,这里默认以带头结点执行。
后插
在指定结点p后插入元素 e,实际上为位序插入的后半段代码逻辑。
代码实现
用C/C++表示,如下:
//后插操作:在P结点之后插入元素e
bool InsertNextNode(LNode *p,int e){
if(p==NULL) //结点不存在
return false;
LNode *s = (LNode *)malloc(sizeof(LNode));
if(s == NULL) //内存分配失败。可能是由于空间不足
return false;
s->data = e; //用结点s保存元素e
s->next = p->next;
p->next = s; //将结点s连到p之后
return true; //插入成功
}
插入操作的时间复杂度
时间复杂度为O(1),牛逼的很。
前插
单链表的结点不指向前一个结点,故初步逻辑为从头指针开始遍历,找到需要插入的结点的前一位,再将其插入,如果这样的话,方法还需要传染头指针的参数,时间复杂度也为O(n),很不爽。故采用第二种方案。
方案二:依旧采用指定结点后插的方式,插入新结点,但插入之后将指定结点p与新结点s的data值调换,实现偷天换日的骚操作。
代码实现
这里采用方案二,用C/C++表示,如下:
//前插操作:在P结点之前插入元素e
bool InsertPriorNode(LNode *p,int e){
if(p==NULL) //结点不存在
return false;
LNode *s = (LNode *)malloc(sizeof(LNode));
if(s == NULL) //内存分配失败。可能是由于空间不足
return false;
s->next = p->next;
p->next = s; //将结点s连到p之后
s->data = p->data; //将p中元素复制到s中
p->data = e; //p中元素覆盖为e
return true; //插入成功
}
插入操作的时间复杂度
时间复杂度为O(1),骚的很。
删除
这里只探讨带头结点的删除,分为按位序删除和指定结点删除。
按位序删除
逻辑为遍历单链表L,将指定位序的前一个结点的指针指向指定位序的后一个结点(即指定位序的next值),再通过free函数释放掉指定位序的结点,并返回指定结点的data值
代码实现
用C/C++表示,如下:
//在第i个位置删除结点q(带头结点)
bool ListDelete(LinkList &L,int i,int &e){
if(i<1)
return false;
LNode *p; //指针p指向当前扫描到的结点
int j = 0; //当前p指向结点的位序
p = L; //L指向头结点,头结点是第0个结点(不存数据)
while(p!=NULL && j<i-1){ //循环找到第i-1个结点
p=p->next;
j++;
}
if(p==NULL) //i值不合法,由所查位序大于单链表本身长度所致
return false;
if(p->next == NULL) //第i-1个结点后已无其他结点
return false;
LNode *q = p->next; //另q指向被删除的结点
e = q->data; //用e元素返回元素的值
p->next = q->next; //将*q结点从链中"断开"
free(q); //释放被删除结点的存储空间
return true; //删除成功
}
删除操作的时间复杂度
- 最好情况:删除表头结点,最好时间复杂度 = O(1)
- 最坏情况:删除表尾结点,最坏时间复杂度 = O(n)
- 平均情况:删除表中结点,平均时间复杂度 = O(n)
指定结点删除
由于指定结点并不能通过指针定位到结点本身(结点中的指针数据只指向下一位),故传统方案只能通过遍历头结点来找到自己的指定结点,这里不做赘述。
取巧方案逻辑与指定结点的前插类似。将指定结点的data值赋值为指定结点的后继结点,再将指定结点的next指针值赋值为后继结点的next指针值,此时指定结点直接指向后继的后继结点。并且指定结点的data值也等于后继结点,此时可以说指定结点在效果上被删除了(自己的理解),这时,我们再将指定结点的后续节点释放内存,防止内存泄漏。
注:如果指定结点是最后一个结点,该方案无效,依旧得按传统方案从表头遍历。
代码实现
取巧方案的删除法,用C/C++表示,如下:
//删除指定结点p(不适用于删除最后一个结点)
bool DeleteNode(LNode *p){
if(p==NULL)
return false;
LNode *q = p->next; //用q指向p的后继结点
p->data = q->data; //将后继结点的数据域赋值给自己,把自己变成后续节点的模样
p->next = q->next; //指向原本后续结点指向的next
free(q); //释放后继结点的存储空间
return true;
}
删除操作的时间复杂度
通过取巧方案的骚操作,时间复杂度为O(1)。
查找
这里只探讨单链表带头结点的查找。
按位查找
按位查找的逻辑其实已经在实现插入和删除算法时有所实现,唯一区别为插入删除时,所要查找的结点为位序为i-1的结点,而我们现在要找的是i所在节点并返回。
代码实现
用C/C++表示,如下:
//按位查找,返回第i个元素(带头结点)
LNode * GetElem(LinkList L, int i){
if(i<0){
return NULL;
}
LNode *p; //指针p指向当前扫描到的结点
int j = 0;//当前p指向的位序
p = L; //L指向头结点,头结点是第0个结点(不存数据)
while(p!=NULL && j<i){ //循环找到第i个结点
p = p->next;
j++;
}
return p;
}
时间复杂度
- 最好情况:表头结点,最好时间复杂度 = O(1)
- 最坏情况:表尾结点,最坏时间复杂度 = O(n)
- 平均情况:表中结点,平均时间复杂度 = O(n)
其实这些与问题规模n(单链表L的长度)有直接的关系的算法,时间复杂度直接为O(n)即可,之后不赘述
按值查找
代码实现
用C/C++表示,如下:
//按值查找,找到数据域==e的结点(带头结点)
LNode * LocateElem(LinkList L, int e){
LNode *p = L->next;
//从第一个结点开始查找数据域为e的结点
while(p!=NULL && p->data !=e)
p = p->next;
return p; //找到后返回该指针,否则返回NULL
}
时间复杂度
时间复杂度就是O(n),这里不赘述好坏情况。
求表的长度
这里默认不带头结点。
思考:带头结点咋子整?
代码实现
用C/C++表示,如下:
//求表的长度(带头结点)
int Length(LinkList L){
int len = 0; //统计表长
LNode * p = L;
while(p->next !=NULL){
p = p->next;
len++;
}
return len;
}
时间复杂度
O(n)
单链表的建立
如果多个数据元素,需要存入单链表中。如何?
- 初始化一个单链表。
- 每次取一个数据元素,插入到表尾\表头(尾插法/头插法)。
这里我们仅探讨带头结点的情况。
尾插法
核心思想与后插相同,唯一区别为多了一个指向表尾的记录指针r,以减少时间复杂度。
代码实现
用C/C++表示,如下:
//尾插法建立单链表
LinkList List_TailInsert(LinkList &L){ //正向建立单链表
int x;
L = (LinkList)malloc(sizeof(LNode)); //建立头结点(初始化空表)
LNode *s,*r = L; //r为表尾指针
scanf("%d",&x); //输入结点的值
while(x!=9999){ //输入9999表示结束
s=(LNode *)malloc(sizeof(LNode));
s->data = x;
r->next = s;
r = s; //指针指向新的表尾结点(永远表示r指向最后一个结点)
scanf("%d",&x);
}
r->next = NULL; //尾指针结点置空
return L;
}
时间复杂度
随问题规模变化,为O(n)
思考:不带头结点咋子整?
头插法
核心思想与后插相同,每次头插向头结点的下一个节点。
代码实现
用C/C++表示,如下:
//头插法建立单链表
LinkList List_HeadInsert(LinkList &L){ //逆向建立单链表
LNode *s;
int x;
L = (LinkList)malloc(sizeof(LNode)); //建立头结点(初始化空表)
L->next = NULL; //尾指针结点置空
scanf("%d",&x); //输入结点的值
while(x!=9999){ //输入9999表示结束
s=(LNode *)malloc(sizeof(LNode)); //创建新结点
s->data = x;
s->next = L->next;
L->next = s; //指针指向新的表尾结点(永远表示r指向最后一个结点)
scanf("%d",&x);
}
return L;
}
时间复杂度
随问题规模变化,为O(n)
重要应用!!!链表的逆置
思考:不带头结点咋子整?
单链表的局限性
单链表每个结点都只指向下一个结点而不指向上一个,检索时只能从头检索无法逆向检索,有时便不太方便。因此有双链表解决这个问题。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· AI与.NET技术实操系列(二):开始使用ML.NET
· 单线程的Redis速度为什么快?