

xml文件的解析(用dom4j解析)
有个第三方的包,用来解析.xml文件比较方便,它是DOM4J。由于是第三方的,所以要使用它就要先下载,并包含进来。步骤:
1.打开dom4j官网,这里下载最新版dom4j-2.1.1.jar.

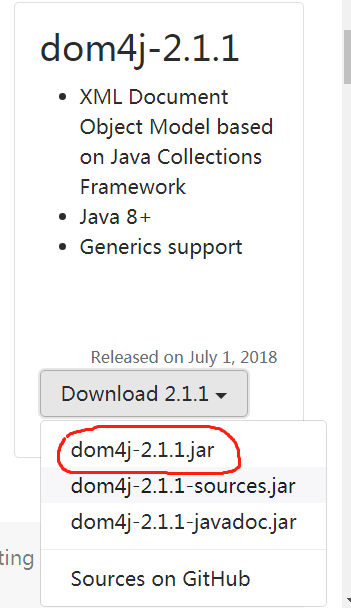
2.新建文件夹lib.

3.把下载好的dom4j.jar放到lib文件夹里面。
4.对着dom4j.jar右键-Build Path-Add to Build Path.(1或者2都可以用来解析.xml).

5.新建类。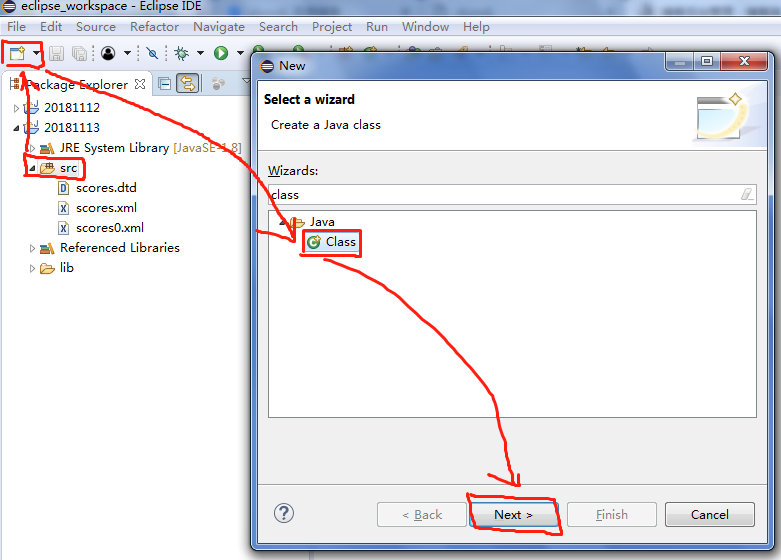

6.开始写代码:
package com.bjsxt.xml; import java.io.File; import javax.swing.text.Document; import javax.swing.text.html.HTMLDocument.Iterator; import javax.swing.text.html.parser.Element; import org.dom4j.Attribute; import org.dom4j.DocumentException; import org.dom4j.io.SAXReader; public class TestXml { public static void main(String[] args) throws Exception { // TODO Auto-generated method stub //[1]创建SAXReader对象,用于读取.xml文件 SAXReader reader = new SAXReader(); //[2]读取.xml文件,得到document对象,它代表了整个.xml文件。 org.dom4j.Document doc = reader.read(new File("src/scores.xml")); //System.out.println(doc); //获取根元素 org.dom4j.Element root=doc.getRootElement(); System.out.println("这是根元素:"+root.getName()); //[4]获取根元素下所有子元素 java.util.Iterator<org.dom4j.Element> it=root.elementIterator();//获取(获取根元素下)所有子元素的一个迭代器。 while(it.hasNext()) {//取出元素 org.dom4j.Element e=it.next(); System.out.println(e.getName()); //获取每个student的id属性: Attribute id=e.attribute("id"); System.out.println(id.getName()+"="+id.getValue());//打印 org.dom4j.Element name=e.element("name"); org.dom4j.Element course=e.element("course"); org.dom4j.Element score=e.element("score"); System.out.println(name.getName()+"="+name.getStringValue()); System.out.println(course.getName()+"="+course.getText()); System.out.println(score.getName() + "=" + score.getText()); System.out.println("----------------------"); } } } /* 运行结果: 这是根元素:scores student id=1 name=王同 course=java score=89 ---------------------- student id=2 name=李佳 course=sql score=58 ---------------------- student id=3 name=王二狗 course=经济学原理 score=88 ---------------------- student id=4 name=刘德华 course=怎样做一个好演员 score=100 ---------------------- */
7.上课老师的总结:用dom4j解析.xml的时候,只需注意两点,a.入手点是先创建一个Document对象;b.然后拿Document对象获取根元素,从根元素开始就可以一路用迭代器迭代下去,碰到元素就迭代元素,碰到属性就迭代属性,就可以用属性.getName/getStringValue/getText取出元素的所有属性。

