

混淆矩阵
https://blog.csdn.net/vesper305/article/details/44927047
Confusion Matrix
在机器学习领域,混淆矩阵(confusion matrix),又称为可能性表格或是错误矩阵。它是一种特定的矩阵用来呈现算法性能的可视化效果,通常是监督学习(非监督学习,通常用匹配矩阵:matching matrix)。其每一列代表预测值,每一行代表的是实际的类别。这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)。
Example
假设有一个用来对猫(cats)、狗(dogs)、兔子(rabbits)进行分类的系统,混淆矩阵就是为了进一步分析性能而对该算法测试结果做出的总结。假设总共有 27 只动物:8只猫, 6条狗, 13只兔子。结果的混淆矩阵如下图:
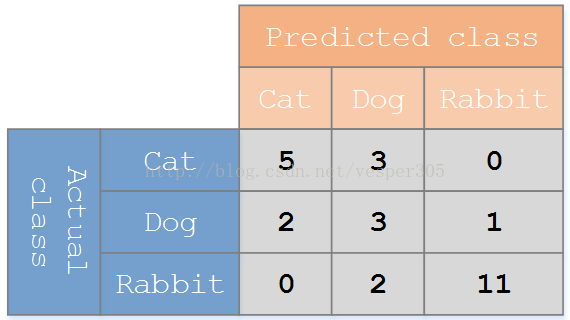
在这个混淆矩阵中,实际有 8只猫,但是系统将其中3只预测成了狗;对于 6条狗,其中有 1条被预测成了兔子,2条被预测成了猫。从混淆矩阵中我们可以看出系统对于区分猫和狗存在一些问题,但是区分兔子和其他动物的效果还是不错的。所有正确的预测结果都在对角线上,所以从混淆矩阵中可以很方便直观的看出哪里有错误,因为他们呈现在对角线外面。
下图的来源:【小萌五分钟】机器学习 | 混淆矩阵 Confusion Matrix_哔哩哔哩_bilibili
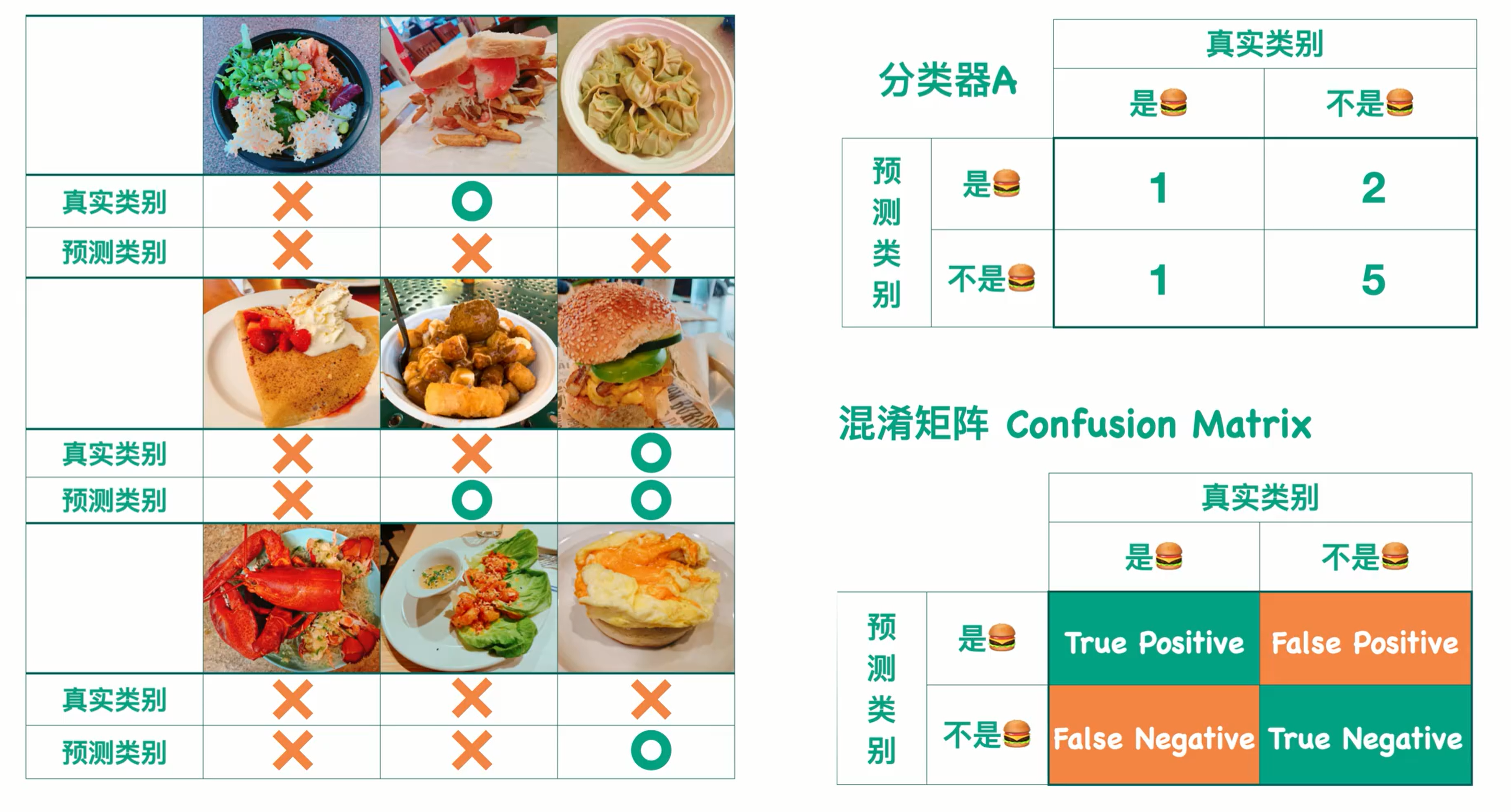
看右下角的矩阵:主对角线上薄荷绿的两块说明是预测对了,所以是以True开头的,非主对角线上橙色的两块说明是预测错误的,所以是以False开头的。另外,第一行都是预测成“是(汉堡)”了,所以第一行的第二个单词都是Positive,第二行都是预测成“不是(汉堡)”了,所以第一行的第二个单词都是Negative.
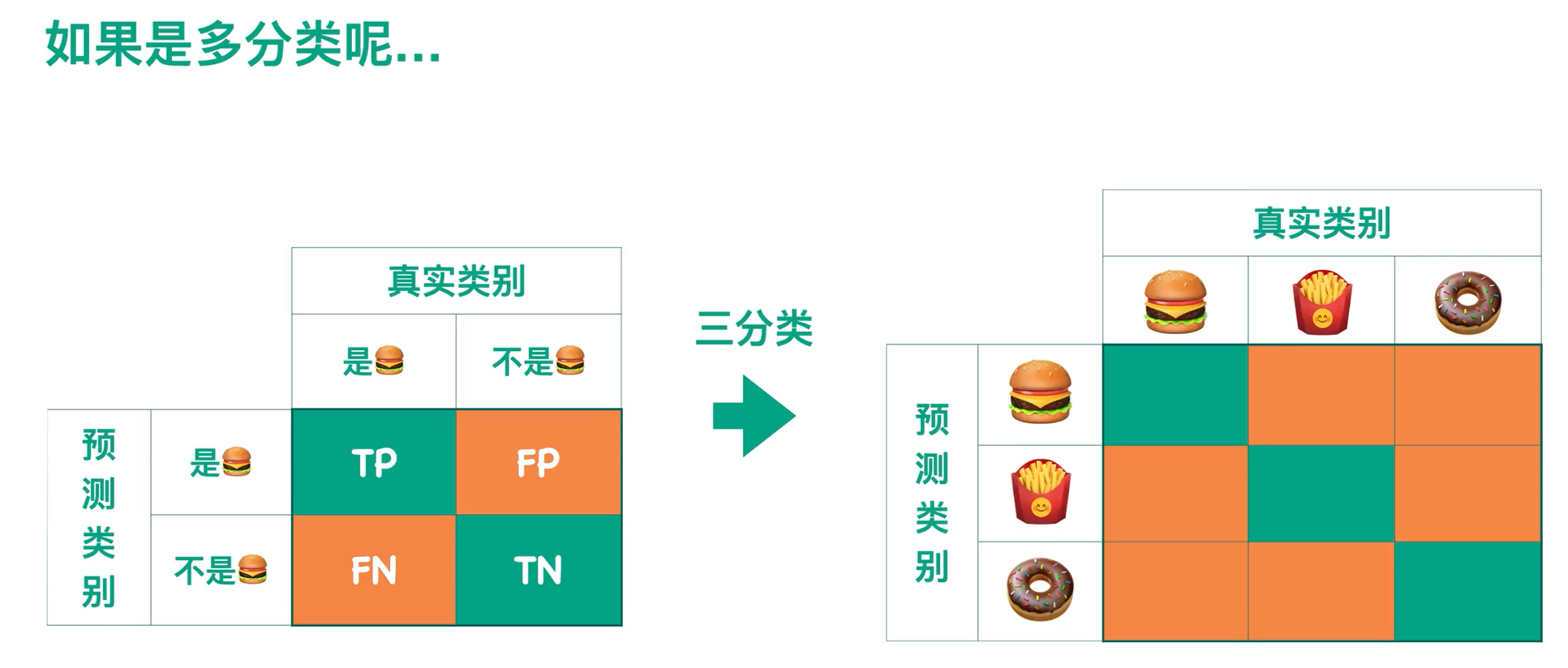
上图是对于二分类而言的混淆矩阵,那对于多分类呢?
3个类别的话就是3*3的矩阵。
如果是N分类呢?
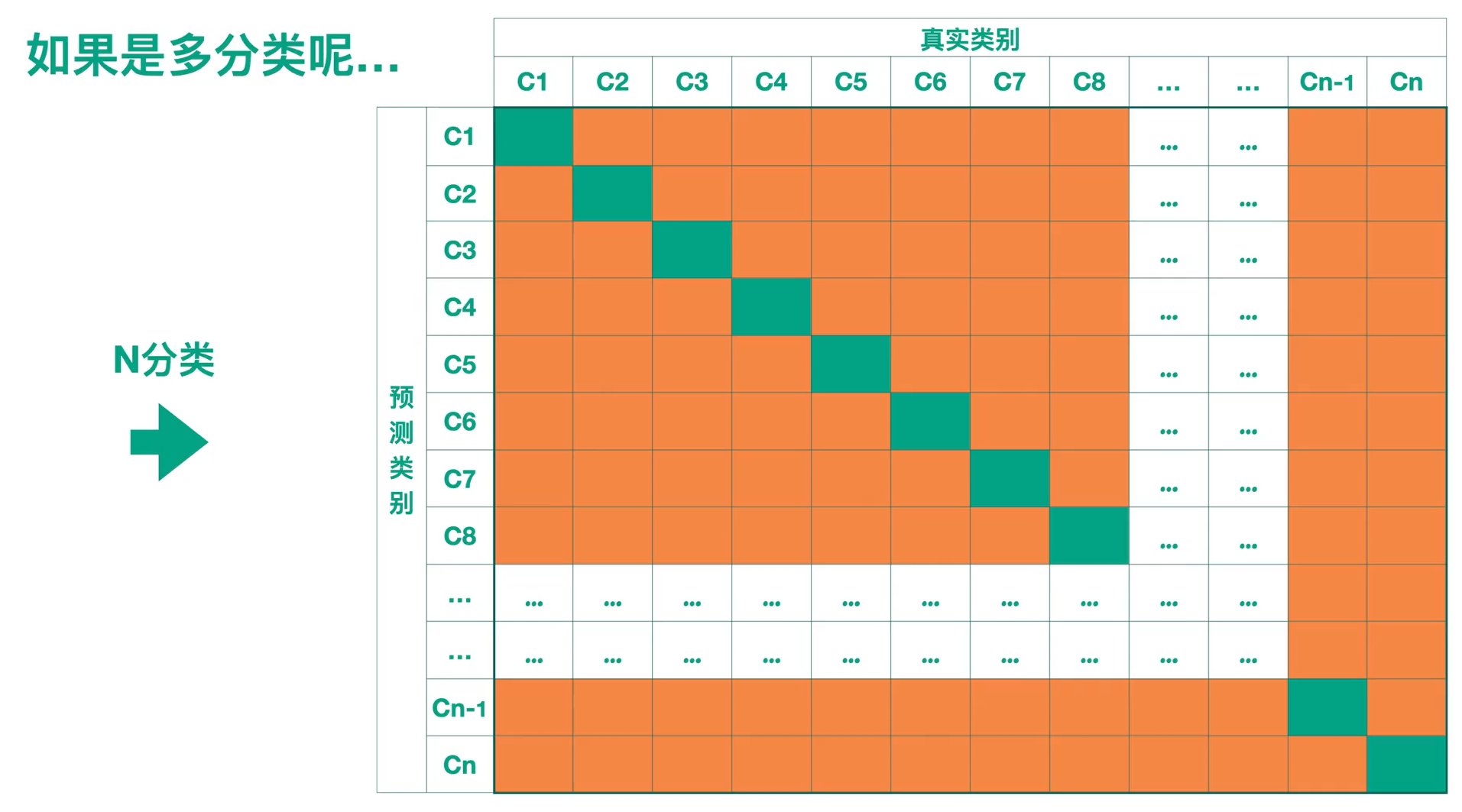
我们总是希薄荷绿位置的数值尽可能的大,其余的地方的数值尽可能的小,这样才说明预测的正确性高。才能说明模型的效果是更好的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
2020-10-15 linux ubuntu蓝牙驱动安装
2020-10-15 火车票座位