

tf.layers.batch_normalization
来源:https://zhuanlan.zhihu.com/p/82354021
Batch Normalization (BN) 的定义
批归一化就是让一组数据的均值变为0,标准差变为1.
给定 维向量
,在每个特征上(即针对每一个维度而言)独立地减均值、除以标准差
深度学习中,以 batch 为单位进行操作,减去 batch 内样本均值,除以 batch 内样本的标准差,最后进行平移和缩放,其中缩放参数 和平移参数
都是可学习的参数。
常见面试问题2:归一化-BN、LN、IN、GN_哔哩哔哩_bilibili

ξ是使得分母不为0的极小数。
γ和β是可以学习的参数,是为了让归一化的变量的分布不那么固定。
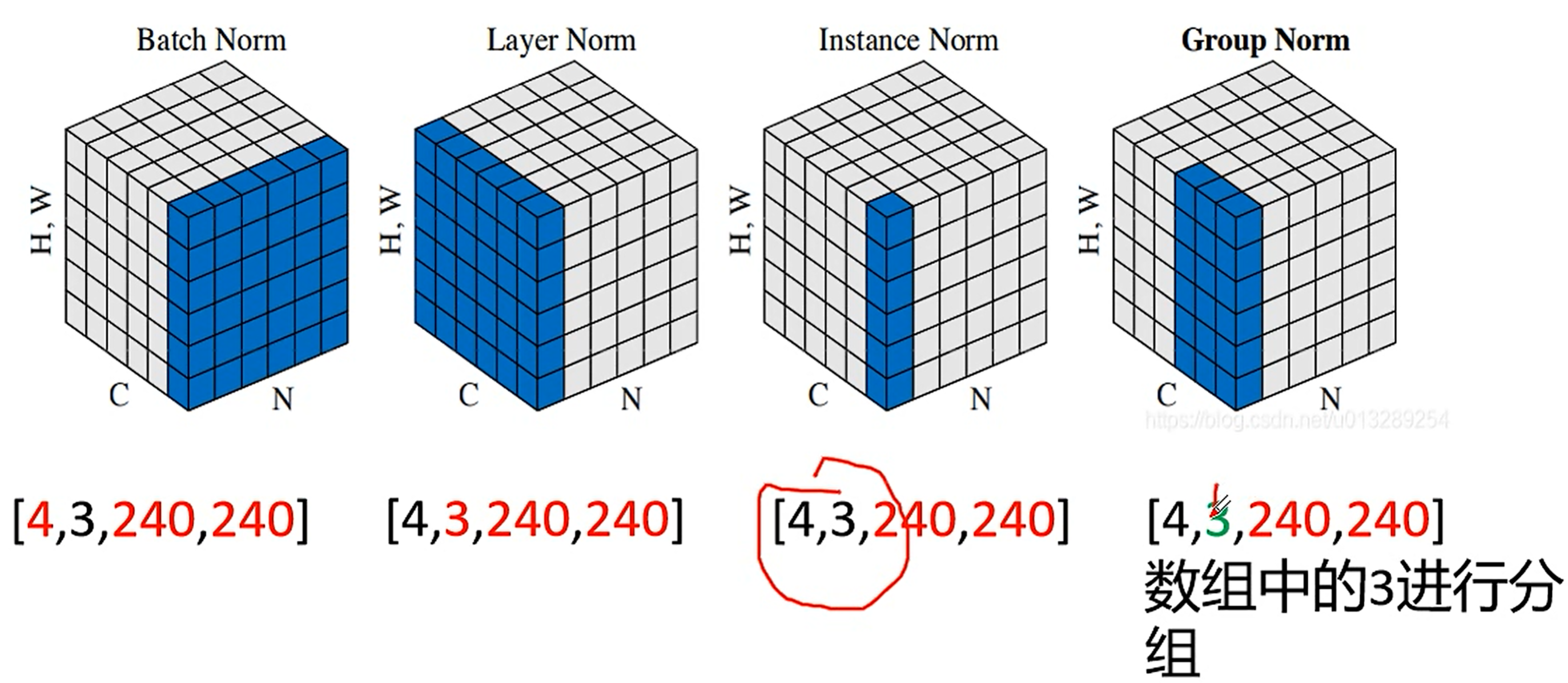
4:4张图片,是batchsize
3:Channel, 神经网络的中间层的话,这个channel可能就不是3了
240:H
240:W
批归一化就是:针对4张图片的第1个Channel做第1次归一化;
针对4张图片的第2个Channel做第2次归一化
针对4张图片的第3个Channel做第3次归一化
后面的图片:
总共做了4次归一化。每次都是针对一整张图片做归一化。
总共做了4×3=12次归一化。针对每一张图片的每一个通道进行归一化。
总共做了?次归一化。针对通道进行分组归一化,3个通道不好分组,假如是64个通道,则可以分成16组,每组4个通道,每次归一化是针对一组通道进行归一化。
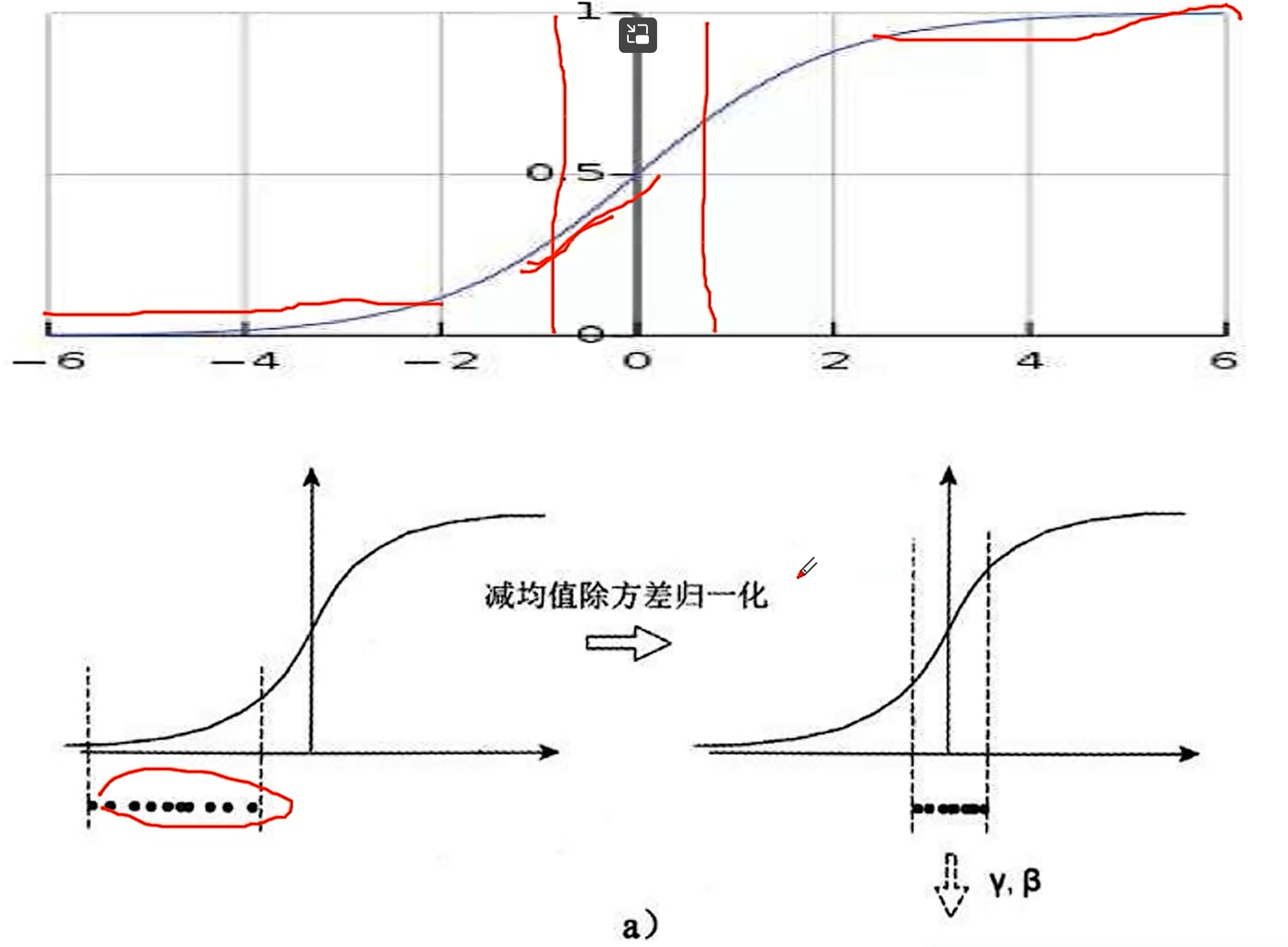
假如不做批归一化,那么分布在两边的数据会被激活函数映射之后会边的很小,甚至接近0,更重要的是,数据变化很小,神经网络学习不到什么东西。所以,我们希望把数据归一化到0周围,这样的话,数据变化是最大的,神经网络会更快的收敛。再者,数据分布在两边的话,根据激活函数求得的梯度很小,接近于0,反向传播的时候,很多接近于0的梯度相乘,会造成梯度消失这样的状况的出现,此时,神经的网络的权重会长时间得不到更新,会变成静态权重,损失函数会得不到收敛。

为何有防止过拟合的好处呢?答:因为每次随机的取4张图片,批归一化会造成特征变化大,这样可以避免只针对一个特征(变量)进行拟合,只针对一个特征进行拟合就会过拟合。感觉上防止过拟合更像是随机梯度下降的好处。
tf.layers.batch_normalization
基本参数
tf.layers.batch_normalization(
inputs,
axis=-1,
momentum=0.99,
epsilon=0.001,
center=True,
scale=True,
beta_initializer=tf.zeros_initializer(),
gamma_initializer=tf.ones_initializer(),
moving_mean_initializer=tf.zeros_initializer(),
moving_variance_initializer=tf.ones_initializer(),
beta_regularizer=None,
gamma_regularizer=None,
beta_constraint=None,
gamma_constraint=None,
training=False,
trainable=True,
name=None,
reuse=None,
renorm=False,
renorm_clipping=None,
renorm_momentum=0.99,
fused=None,
virtual_batch_size=None,
adjustment=None
)如果只令 training=True,无法实现缩放参数 和平移参数
的学习(动态更新),需在源代码中加入如下设置。
# 用于设置 tf.layers.batch_normalization 的 training 参数
is_train = tf.placeholder_with_default(False, (), 'is_train')
# 第一种设置方式:手动加入 sess.run()
# tf.GraphKeys.UPDATE_OPS 返回图中 UPDATE_OPS 的名字集合
# UPDATE_OPS 维护一个需要在每步训练之前运行的操作列表。
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(EPOCHS):
for i in range(NUM_BATCHES):
sess.run(
[tf.get_collection(tf.GraphKeys.UPDATE_OPS), optimizer],
feed_dict={
x: x_train[i*BATCH_SIZE:(i+1)*BATCH_SIZE-1,:],
y: y_train[i*BATCH_SIZE:(i+1)*BATCH_SIZE-1,:],
is_train: True}) # 可通过修改该参数打开或关闭 BN。
# 第二种设置方式:利用 tf.control_dependencies
# 定义 optimizer 的时候加上 tf.control_dependencies()。
# control_dependencies 是一种机制,可以将依赖项添加到 with 块中创建的任何操作。
# 具体地说,确保在运行 with 块中定义的任何内容之前,
# 先估计 control_dependencies 的参数中指定的内容。
# 此处 optimizer 的定义依赖于 loss,进而依赖于参与 loss 计算的 BN。
with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
optimizer = tf.train.AdamOptimizer().minimize(loss)完整示例
利用最简单的全链接神经网络在 mnist 数据集上展示 tf.layers.batch_normalization 的两种动态更新缩放参数和平移参数的方法。
第一种设置方式
#! /home/lizhongding/anaconda3/envs/tfp/bin/python3.6
# -*- coding: utf-8 -*-
"""
7-layer fully connected neural network
"""
__author__ = "lizhongding"
import tensorflow as tf
import numpy as np
def one_hot_encoding(x, depth=10):
length = len(x)
coder = np.zeros([length, depth])
for i in range(length):
coder[i, x[i]] = 1
return coder
(x_train, y_train), (x_test, y_test) = \
tf.keras.datasets.mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], -1) / 255
x_test = x_test.reshape(x_test.shape[0], -1) / 255
y_train = one_hot_encoding(y_train)
y_test = one_hot_encoding(y_test)
BATCH_SIZE = 64
EPOCHS = 50
NUM_BATCHES = x_train.shape[0] // BATCH_SIZE
x = tf.placeholder(tf.float32, [None, 784], 'input_x')
y = tf.placeholder(tf.int32, [None, 10], 'input_y')
w1 = tf.Variable(tf.truncated_normal([784, 1024]))
b1 = tf.Variable(tf.truncated_normal([1, 1024]))
w2 = tf.Variable(tf.truncated_normal([1024, 512]))
b2 = tf.Variable(tf.truncated_normal([1, 512]))
w3 = tf.Variable(tf.truncated_normal([512, 512]))
b3 = tf.Variable(tf.truncated_normal([1, 512]))
w4 = tf.Variable(tf.truncated_normal([512, 512]))
b4 = tf.Variable(tf.truncated_normal([1, 512]))
w5 = tf.Variable(tf.truncated_normal([512, 256]))
b5 = tf.Variable(tf.truncated_normal([1, 256]))
w6 = tf.Variable(tf.truncated_normal([256, 64]))
b6 = tf.Variable(tf.truncated_normal([1, 64]))
w7 = tf.Variable(tf.truncated_normal([64, 10]))
b7 = tf.Variable(tf.truncated_normal([1, 10]))
is_train = tf.placeholder_with_default(False, (), 'is_train')
h1 = tf.nn.leaky_relu(
tf.layers.batch_normalization(
tf.add(tf.matmul(x, w1), b1),
training=is_train))
h2 = tf.nn.leaky_relu(
tf.layers.batch_normalization(
tf.add(tf.matmul(h1, w2), b2),
training=is_train))
h3 = tf.nn.leaky_relu(
tf.layers.batch_normalization(
tf.add(tf.matmul(h2, w3), b3),
training=is_train))
h4 = tf.nn.leaky_relu(
tf.layers.batch_normalization(
tf.add(tf.matmul(h3, w4), b4),
training=is_train))
h5 = tf.nn.leaky_relu(
tf.layers.batch_normalization(
tf.add(tf.matmul(h4, w5), b5),
training=is_train))
h6 = tf.nn.leaky_relu(
tf.layers.batch_normalization(
tf.add(tf.matmul(h5, w6), b6),
training=is_train))
h7 = tf.nn.leaky_relu(
tf.add(tf.matmul(h6, w7), b7))
loss = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=tf.argmax(y, 1),
logits=h7
))
# with tf.control_dependencies(
# tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
optimizer = tf.train.AdamOptimizer().minimize(loss)
accuracy = tf.reduce_mean(tf.to_float(
tf.equal(tf.argmax(y, 1), tf.argmax(h7, 1))))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(EPOCHS):
for i in range(NUM_BATCHES):
sess.run(
[tf.get_collection(tf.GraphKeys.UPDATE_OPS), optimizer],
feed_dict={
x: x_train[i*BATCH_SIZE:(i+1)*BATCH_SIZE-1,:],
y: y_train[i*BATCH_SIZE:(i+1)*BATCH_SIZE-1,:],
is_train: True}) # 可通过修改该参数打开或关闭 BN。
print("After Epoch {0:d}, the test accuracy is {1:.4f} ".
format(epoch + 1,
sess.run(accuracy,
feed_dict={x: x_test, y: y_test})))
print("Finished!")第二种设置方式
#! /home/lizhongding/anaconda3/envs/tfp/bin/python3.6
# -*- coding: utf-8 -*-
"""
7-layer fully connected neural network
"""
__author__ = "lizhongding"
import tensorflow as tf
import numpy as np
def one_hot_encoding(x, depth=10):
length = len(x)
coder = np.zeros([length, depth])
for i in range(length):
coder[i, x[i]] = 1
return coder
(x_train, y_train), (x_test, y_test) = \
tf.keras.datasets.mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], -1) / 255
x_test = x_test.reshape(x_test.shape[0], -1) / 255
y_train = one_hot_encoding(y_train)
y_test = one_hot_encoding(y_test)
BATCH_SIZE = 64
EPOCHS = 50
NUM_BATCHES = x_train.shape[0] // BATCH_SIZE
x = tf.placeholder(tf.float32, [None, 784], 'input_x')
y = tf.placeholder(tf.int32, [None, 10], 'input_y')
w1 = tf.Variable(tf.truncated_normal([784, 1024]))
b1 = tf.Variable(tf.truncated_normal([1, 1024]))
w2 = tf.Variable(tf.truncated_normal([1024, 512]))
b2 = tf.Variable(tf.truncated_normal([1, 512]))
w3 = tf.Variable(tf.truncated_normal([512, 512]))
b3 = tf.Variable(tf.truncated_normal([1, 512]))
w4 = tf.Variable(tf.truncated_normal([512, 512]))
b4 = tf.Variable(tf.truncated_normal([1, 512]))
w5 = tf.Variable(tf.truncated_normal([512, 256]))
b5 = tf.Variable(tf.truncated_normal([1, 256]))
w6 = tf.Variable(tf.truncated_normal([256, 64]))
b6 = tf.Variable(tf.truncated_normal([1, 64]))
w7 = tf.Variable(tf.truncated_normal([64, 10]))
b7 = tf.Variable(tf.truncated_normal([1, 10]))
is_train = tf.placeholder_with_default(False, (), 'is_train')
h1 = tf.nn.leaky_relu(
tf.layers.batch_normalization(
tf.add(tf.matmul(x, w1), b1),
training=is_train))
h2 = tf.nn.leaky_relu(
tf.layers.batch_normalization(
tf.add(tf.matmul(h1, w2), b2),
training=is_train))
h3 = tf.nn.leaky_relu(
tf.layers.batch_normalization(
tf.add(tf.matmul(h2, w3), b3),
training=is_train))
h4 = tf.nn.leaky_relu(
tf.layers.batch_normalization(
tf.add(tf.matmul(h3, w4), b4),
training=is_train))
h5 = tf.nn.leaky_relu(
tf.layers.batch_normalization(
tf.add(tf.matmul(h4, w5), b5),
training=is_train))
h6 = tf.nn.leaky_relu(
tf.layers.batch_normalization(
tf.add(tf.matmul(h5, w6), b6),
training=is_train))
h7 = tf.nn.leaky_relu(
tf.add(tf.matmul(h6, w7), b7))
loss = tf.reduce_mean(
tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=tf.argmax(y, 1),
logits=h7
))
with tf.control_dependencies(
tf.get_collection(tf.GraphKeys.UPDATE_OPS)):
optimizer = tf.train.AdamOptimizer().minimize(loss)
accuracy = tf.reduce_mean(tf.to_float(
tf.equal(tf.argmax(y, 1), tf.argmax(h7, 1))))
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(EPOCHS):
for i in range(NUM_BATCHES):
sess.run(optimizer, feed_dict={
x: x_train[i*BATCH_SIZE:(i+1)*BATCH_SIZE-1,:],
y: y_train[i*BATCH_SIZE:(i+1)*BATCH_SIZE-1,:],
is_train: True}) # 可通过修改该参数打开或关闭 BN。
print("After Epoch {0:d}, the test accuracy is {1:.4f} ".
format(epoch + 1,
sess.run(accuracy,
feed_dict={x: x_test, y: y_test})))
print("Finished!")参考链接



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
2019-08-06 tf.logging.set_verbosity