

神经网络原理
神经网络又不是通过记住样本来学习,这样又怎么能泛化到测试集上呢?因此一个epoch并不行。
说到底这个问题就是因为神经网络是个非凸优化问题,使得你不能搞很大的学习率,然而从初始化点到能很好权衡正则化项足够小和后验概率足够大的那个平衡点是有很长的一段路要走的(后验概率最大的那个点我指的是理论上神经网络的最优点)。理论上,如果你有无穷多的样本,那你就可以一直取样本-算梯度-往前走这么循环下去,但是事情并非如此,无奈之下只好重头开始遍历样本以求能得到真实梯度的近似,实际上这个时候算出的梯度实际上只是真实泛化误差(不是训练集误差)梯度的有偏估计量,还好数据量足够大的话这些样本跟实际中碰到的样本还是近似同分布的,所以这样优化到最后的神经网络泛化效果还不错。
链接:https://www.zhihu.com/question/68590666/answer/265740449
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
https://www.zhihu.com/zvideo/1360344853985996801
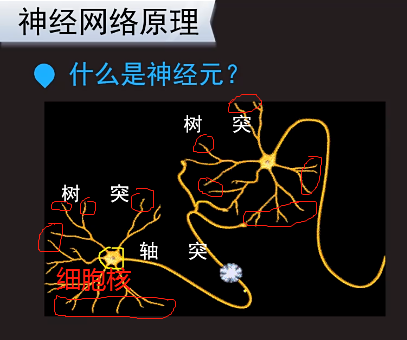
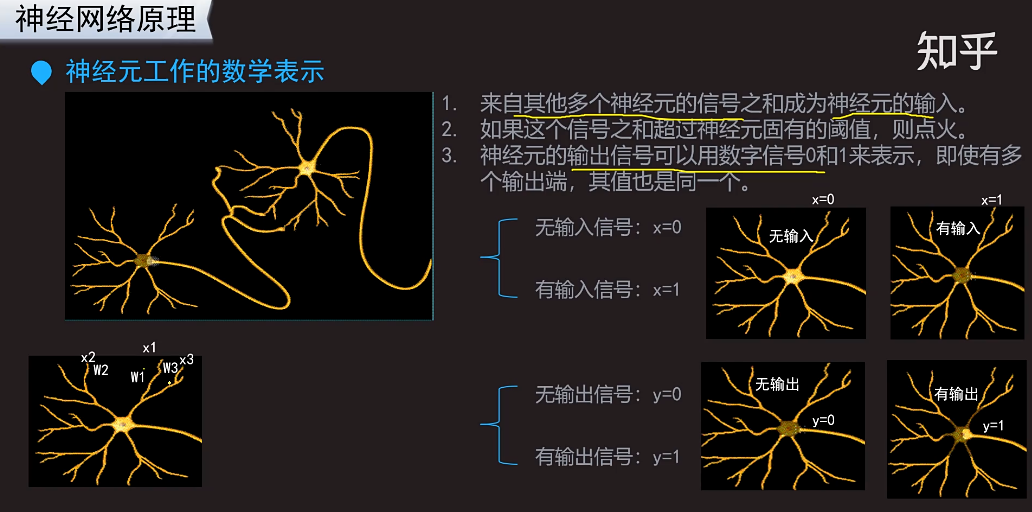
细胞核接受树突传递过来的信息。由这个细胞核决定要不要传递信息给其它的神经元。神经元连接在一起就构成了神经网络。那片雪花就是一个增在传递的信号。
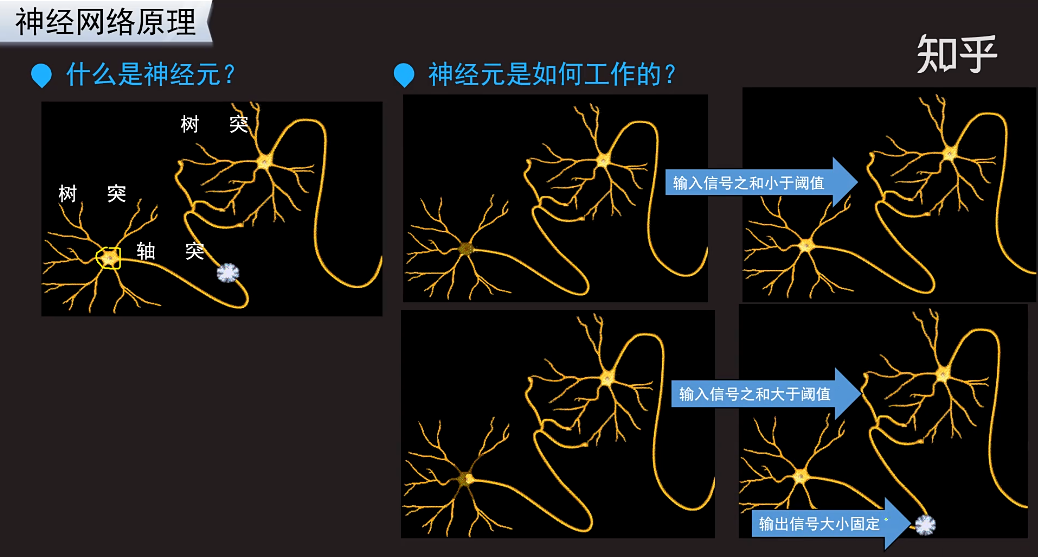
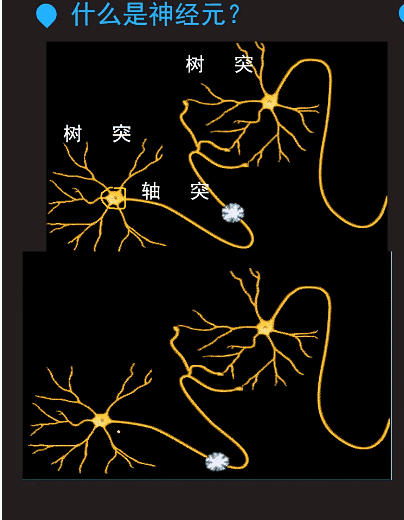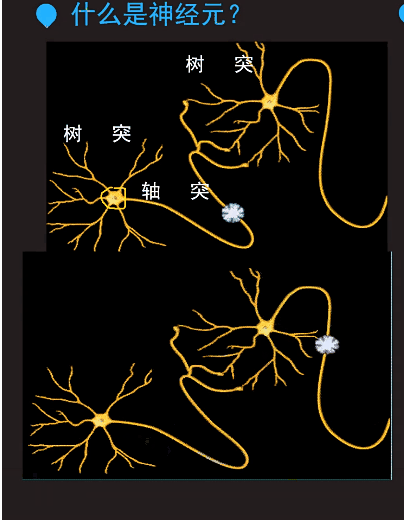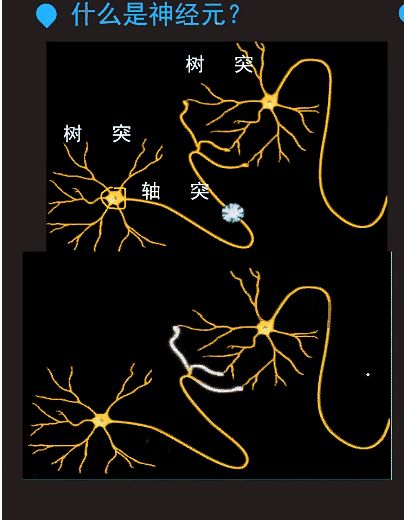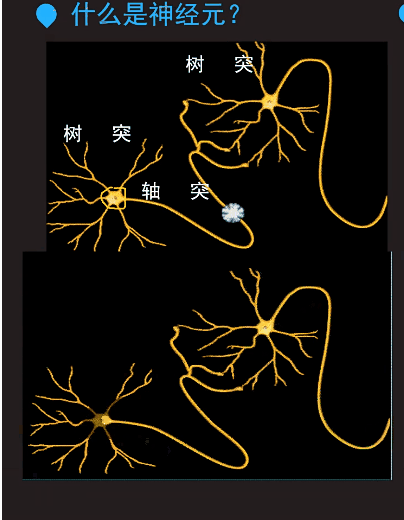
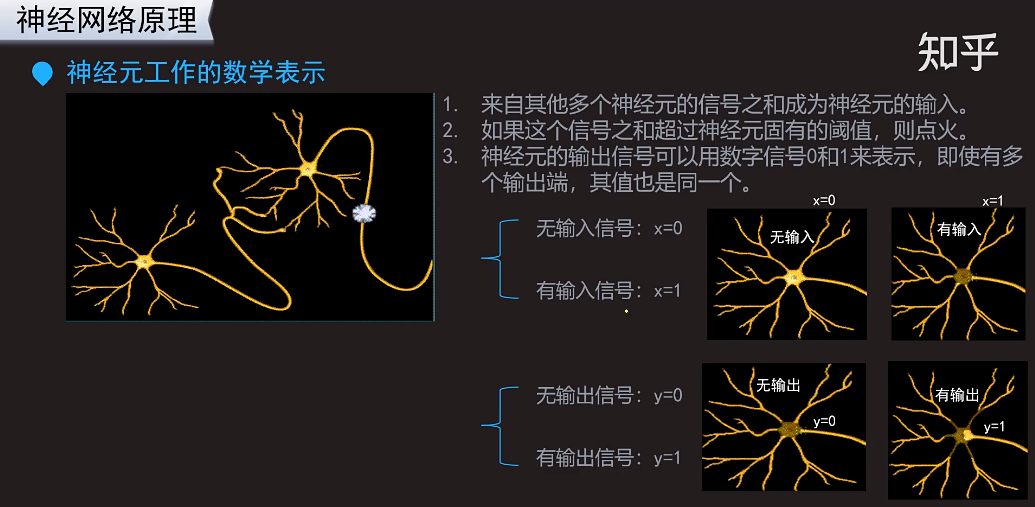
输出信号之和小于阈值,就恢复到输出信号之前的状态,什么也不做。有一些信息需要过滤,暂时不需要做什么反应。不是任何轻微的信息都要做出一定的反应。比如,看喜剧,包袱不出现的时候不会笑。只有到一些笑点的时候,才笑。
输出信号之和大于阈值,就传递信号。对应剧情好笑的时候会笑出来,会接收到好笑的信号。
下面这个动图反应了神经元之间的信息传递是如何工作的:

第3条,神经元的输出信号可以用数字信号0和1表示,可以类比为看一个小品输出结果是笑还是不笑。
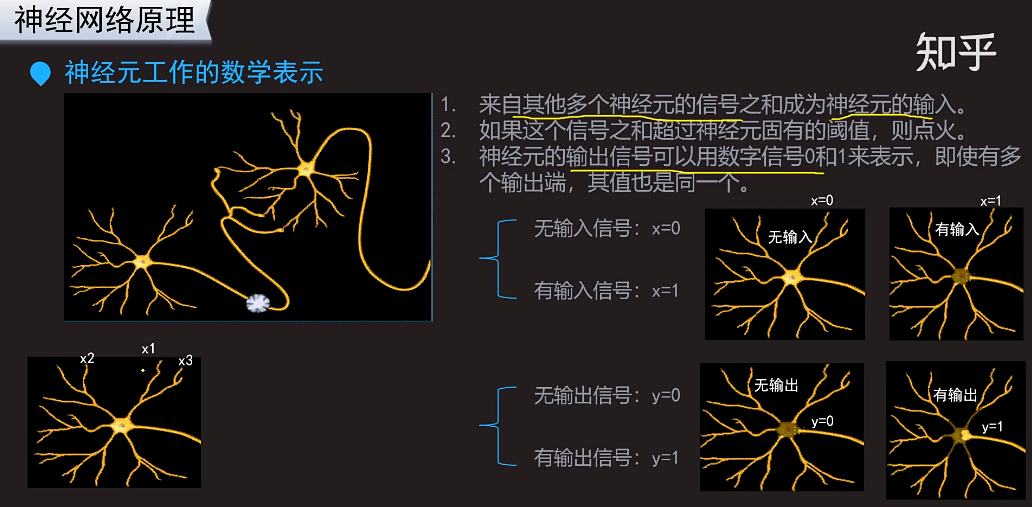
假设神经元x1是眼睛看到的信息,神经元x2是耳朵听到的一个信息,x3是鼻子闻到的一个信息。这3中信息汇总过来,其实它们带来的信息量的权重是不一样的,权重应该不相等,比如说看一场球赛,眼睛看到的权重直觉上应该更大一些。比如看小品的时候,如果只是听,可能不会发笑,但是结合视觉和听觉的话,可能更容易发笑。
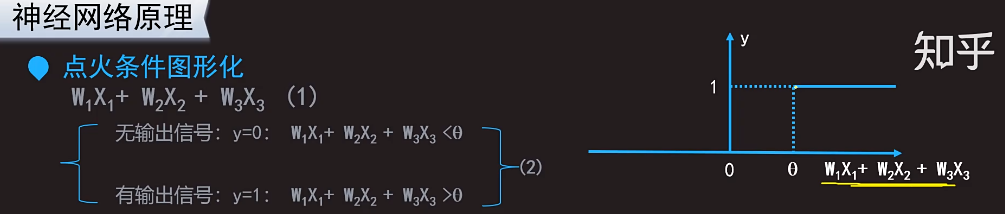
给每个神经元标上一个权重,那么可以得到下面的式子:

(1)式可扩展到更多的神经元输入。
这个瑟塔就是上文说的能激活神经元让神经元点火的那个固有的阈值。
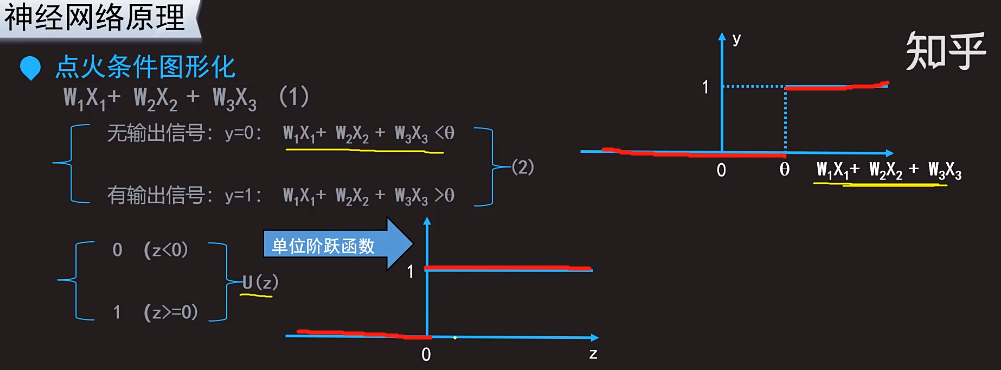
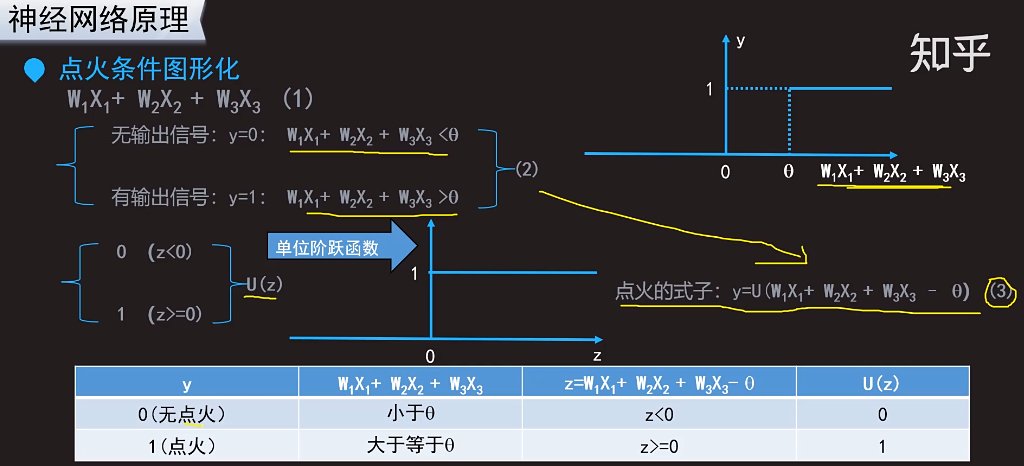
(2)和(3)是一致的。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
2020-04-16 matlab发出声音蜂鸣响声