

知识工程及语义网技术 2020-04-02 (第一节)-语义网数据管的理-RDF的存储和管理
https://www.bilibili.com/video/BV1vk4y1d7wx/?spm_id_from=333.788.recommend_more_video.12
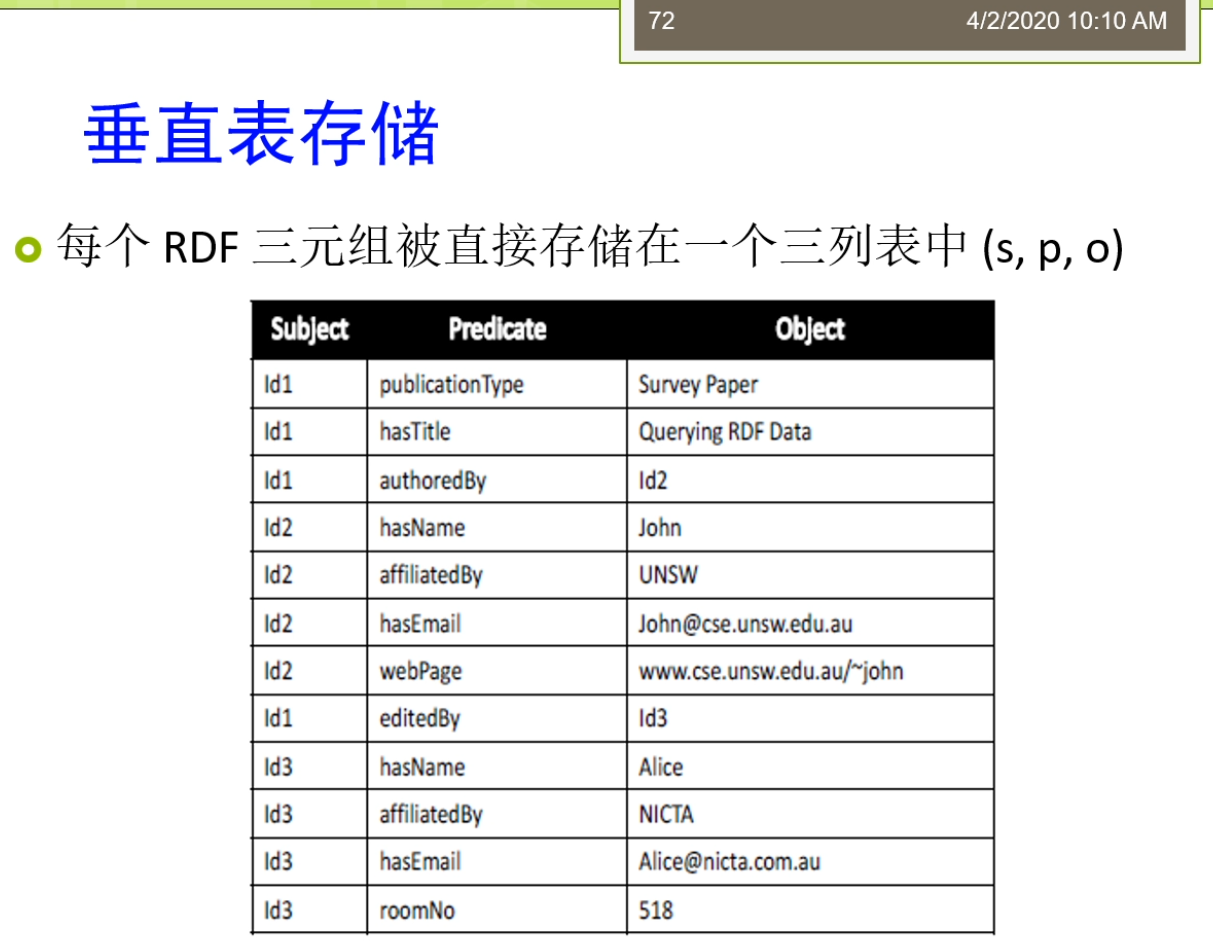












好,嗯,各位同学我们开始这个上课了啊。嗯,大家可以听得见吗?嗯哼,嗯,刚才那个耽误了一点点,那个签到的时间,主要是因为那个这个今天好像网络有点问题,我刚才这个呃推流啊怎么都推不上去。然后修了半天什么也不知道,这个中途啊到底会会不会好?嗯,我们现在反正是这样讲吧。那么我们上节课来开始讲了这个关于这个啊df数据的这个存储和管理这个方面的内容。那么这个方面的内容呢我们讲了一点这个呃关于存储方面的主要讲了关于存储这个方面的一些相关的知识。那么我们这里这个稍微回顾一下,那么首先让我们讲了。存储来她实际上有两种这个最主要的这个形式,一种来是采用原来关机数据库的自动系统,那么去存储。而另外一种男的吗,是采用的是我们做的图数据库的方式再去存储。那么第一种方式里面,那么我们讲的有三种啊这个变形。第一种变形呢是关于称谓叫垂直表的这个存储。那么这个垂直表的存储来就是说每个id f的这个三元组,那么都会被直接存储在一个这个散列表里面,这个三列表呢就是sp的三个列。那么第一列来表示的是主语,第二列来表示的是宾语。第三列代表a,第二列表示的是为第三列的,表示的是并形成了这个三列的方式去存储。这个三列的方式来,那么它正好来和我们说的这个关系数据库啊。那么你面我们把它变到这个表里的三遍,那么他又正好来和我们说的这个啊df数据的这个三元组的形式了。是比较好的,能对应着,也就是说我们的主卫闭症好了就存在这个商店里。那么这样的大家去看的时候来那么很容易看出来怎么是主语,什么是谓语,什么是宾语,什么保留了这个啊df的这个基本结构。那么我们后来呢又讲到这个基本结构了,他可能会变做一些变形。第一个呢是说这个object这个地方他会把它拆分。再问成两种,一种来要不然就是一种这个URI。要不然呢它就是一种这个字段,字面量。那么这两种方式,但是这个不相交的,也就是说要不然他就是个妞矮,要不然他就是个字面量。我们可以把这边去拆分,但是在这前面呢我们座位词还有这个主语,这个料我们适当补彩盒。这个原因时,当大家可以仔细想想,因为啊这个地方那么它涉及到的是我们啊df这个数据的一个规范规范里面说了这个主语或者这个谓语。那么它不可能是一个自变量,它只可能是一个这个ui,那么主语男生他可能是个匿名节点,但匿名节点他也是个资源。所以呢这个时候他不考虑这个字面量的拆分的形式。所以在这个表里面我们一般来讲可以写成三列或者四列的形式。然后呢这个垂直表它还有一种常用的一种这个优化的方法,也就是说为了剪这个减少啊这个占用空间以及他的这个查询的比较低效的问题了,这来他经常会做一个。所以比如说把这个相映的这样的一个URI变成一个编码。这个编码呢是一个规定长度的一个一个短的编码,客服了不同的URI或者不同的字符串,怎么他们长短不一的这样问题。这种呢是我们说的第一种存储方式。第一种存储方式,当本来称未来就要这个垂直表。那么这个垂直表的存储方式它有一个比较大的一个缺点,我们前面说到那么这个缺点就是他在查询一个相关的一个想想做一个查询的时候。那么他可能呢经常需要有大量的连接操作。也就是说我们说话,但之前我们有个例子说要查这个讲师怎么查讲师的时候呢?姓名是怎么的一个讲师,那么你需要做好几次的连接操作。而这个连接操作呢在关系数据库里面是一个比较耗时的,代价很大的这样的一个洞。所以呢导致的这种垂直表的分组方式来,他可能呢效率会比较偏低。那么第二种呢,我们说的利用关系数据库存储的方法来,那么他称未来叫这个水平表的方式。在这个水平表里面,那么啊df三元组就背了这个建模成的一个水平表。或者来被称为来一个垂直分割的这个二元表结果。这里面呢每一个属性就对一个表。也就是说我们说这个一个表的名字时,当对应的我们RDF三元组里面一组啊像拥有相同的个位的。这样一些三元,而里面的取值了一列赖氏族与一列的是这个宾语。那么你有多少个这个属性呢?那么你就会有多少的这种二元了?什么这种方法来我们看到首先第一个它还是可以比较好地表达出来三元组的节奏的。因为每一个三元组的结构使得意味着这个足浴加上表头的信息加上了这个宾语。就行的了,在原那么他的这个缺点呢是让主要在于几个方面,一个方面呢是由于他对于这个属性啊做了这个拆分。那么这个属性首先它的数量如果比较多的话,那么你拆分出来的这个表的数量就会很多。你们说一个这个属性对应的是一张表,那么你的表的数量可能会很第二个它的主要的问题是对于比如说这个数据,我们现在要做一些这个插入或者删除的一些操作的时候。那么我插入一个关于脏脏的所有的三元,那么这时候意味着我需要对于所有的这些表都需要做一个这个更心动。也就是说比如说说到张三的姓名,我们就要把张三的姓名插到这张表里查到,还是那么这场表演如果说张三的这样的一个学校,那么我们又要把它插到这张表。所以这个数据啊就会被打散,那么打伞的存储的不同的表演导致了这个存储的过程啊实际上是比较复杂的。那么同样的对于3v来讲也是,如果你想删除一些相关的内容的时候,那么你依然需要在各个表里面都去做这个更新操作。那么另外对于这样的一个东西,如果你想做一些联合查询,比如说你想查他的姓名是什么,他的email是什么?这时候你的职啊也会来源于多个表。所以呢这个是水平表怎么说他可能会存在着一些这个不足的情况之前不足的情况主要是由于它分割的力度特别小,特别细而造成。那么第三种呢,我们说到的这个利用关系数据库啊这个存储的方法,那么主要呢是称为叫这个属性表。属性表的整吐,他是以他不是刚才我们坐在椅子哥数刚才前面的这个水平表里面。不是让我们前面的这个水平表里面以这个位置作为表头的,而是在属性表里面,它是以我们的这个主语。也就是说,这时候多个id,f的属性被剑魔成了一个嗯原表这样的列。这样大家注意了,这个时候它既不是我们前面的垂直表的这个三列也不是水平表的两列。而是变成了一个属性点儿。也就是说这个属性实际上一张表是一个类型为驱动的,也就是说这里面比如说我们做一个publication这样的一个类。他下面的所有的这个论文就放了这张表儿,personal是第二个类。第二个,那里面所有的人呢就放在第二个表还在这里,每一列。实际上是拥有这一个类,它下面可能允许的一些取值。所以这时候啊那么不一个不可避免的问题就是你需要搞清楚比如说这个类它允许使用的属性有哪些。也就说,比如说对于publication来讲,它允许的属性包括了id,包括了publication,the type包括了has,title,authored by edited by等等。那么他有好几个不同的属性是允许用在这个publication这个类上。所以这种情况下嘞大家就会看到了这个问题,如果你想建立属性表的时候,首先你需要搞清楚的是哪一些属性和哪一些类啊是应该是捆绑。
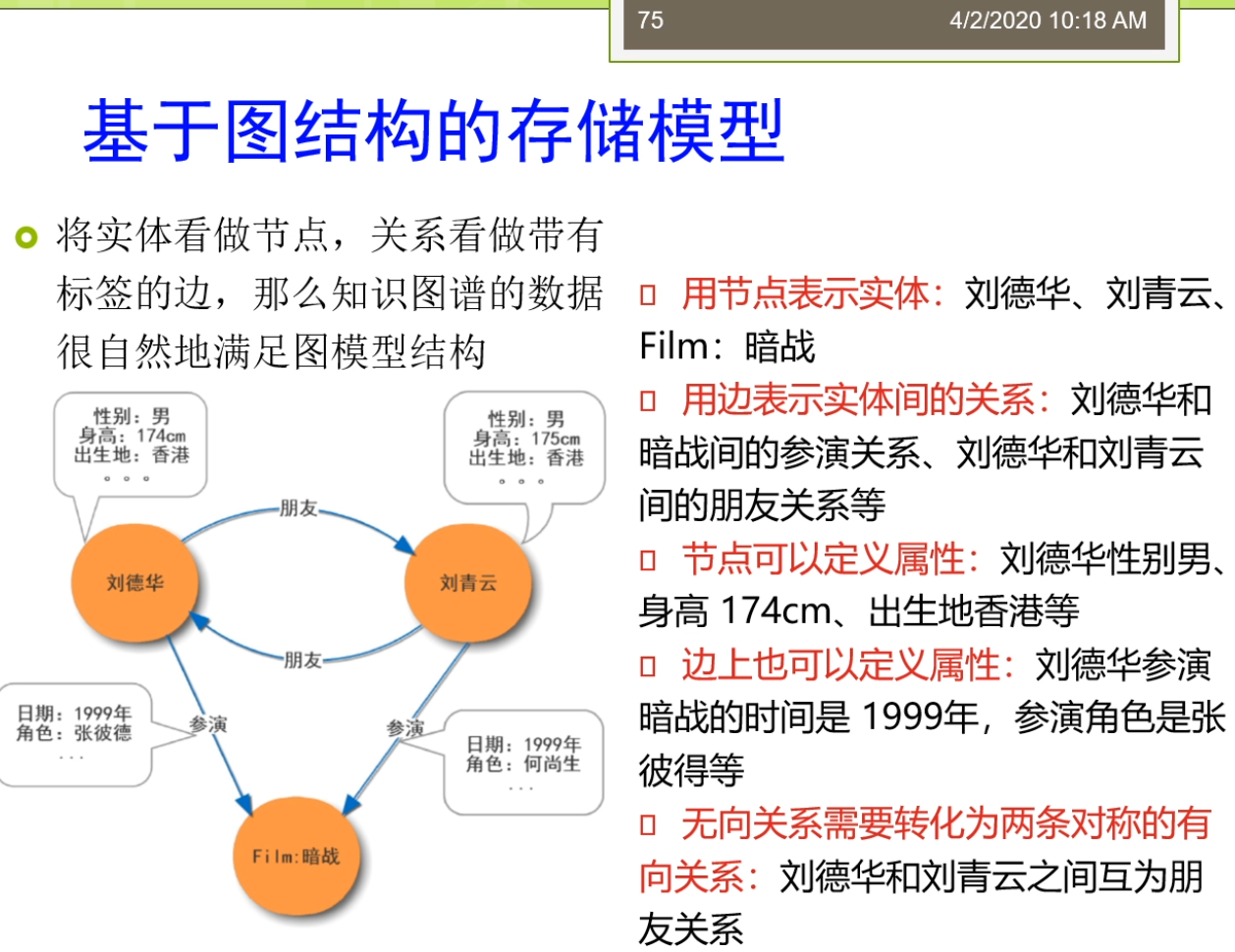
那么这个问题实际上是一个还是比较复杂的问题,因为我们说这个类他会允许这个子类父类的结构,这时候会导致的这个属性啊,把这个类的绑定的一些困难。包括你建一些表困难,有时候这个publication下面我们就说有期刊论文,有会议论文等等的。那么这些论文那他是不是能这个单独见张表呢还是它这个放到我们的publication的这个表呢?所以这个时候就产生了一些这个难题,这是第一个方面。第二个方面实际上在这种贱属性表的过程中间,我们三节课还细化的,他实在要经常应用一些这个聚类方法,或者一些划分方法。来定义出来哪一些主语和属性啊,他应该来讲可能会比较好的放在一起吧。也就是说比如说对于许多属性来讲有一些属性啊,他可能是通用图形。他在很多地方都可以跑得有些属性呢,他可能确实是和publication捆绑的,但是他的数量特别少。也就是说他很不常用,那么到底要不要放在这个属性表里?这实话我们上节课讲的一个叫这个energy的这样的一个agreed,就是利用这个势能的方法进行聚类的一个东西。那么实际上这里面就会经常会用到一些剧烈的方法,搞清楚哪一些类。和哪一些属性啊,他应该具备在一起呗及访问。那么这个呢也会导致的属性表他平时划分的一些不确定性或者一些困难性。所以属性表的这个轴车主方式总体上来讲,那么它有一定的优点,他把前面两种这个问题那么进行的这个压缩死在这个表结构更加简单。但是在他的缺点呢主要是在于这些访问上的一些困难以及呢另外还有一个问题,就是它更像关系数据库的表,那么它破坏了我们三元。另外呢我们还讲了第二种,这个常见的方法是基于这个图结构的存储模式。这个图解勾的存储模式里面和关系在这个关系数据库啊不太一样。那么在这里他把实体了就看做是这个节点。把关系呢看作是带标签的这个边。然后嘞知识图谱了就自然很明这个很自然地就满足了一个图模型的这样子操作。怎么在这个结构里面呢?比如说我们说刘德华,刘青云,暗战等等的,就是我们做的实体。得实体。可能那会有这个相关的类型,然后呢有这个边有个朋友的参演的等等。节电的自己可以定义一些属性,比如说我们说刘德华,他也性别。是男身高是什么,出生地是什么?这个边上来也可以带一些属性。有时候我们说参演刘德华,刘德华去参演这个暗战的他的日期,他的这个角色是什么?所以这个过程里面就比较像我们在这个关系数据库里面的这个亚图的那种模型,也就是说节点和边都带标签。像那个模型。这个模型呢现在奶奶讲,那么可以用图数据库的模型啊去比较好的知识。我们之前呢这个科长看到过,比如说我们可以常用像but also这样子的事情。怎么这个诶我们上节课的也给大家布置了一个相关的这样的一个作业,希望呢大家来第一个去安装一个这个图数据库,这个我主要手别总拿那么多手。去做,然后呢希望来大家来这个把一些数据能导入进去,然后呢能完成一些sparkle这个查询。这是我们上节课来大家我给大家布置的一个作业。那么这个作业了应该在4月份才要交,因为今天的课呢我们会接着讲,把这个sparkle的这个查询啊。把他这个讲完,什么使得来大家来了解到这个18口子的语言却怎么写这样呢你就可以顺利地完成了这个作业。上节课两门还讲到了一个问题,也就是说我们在这个数据存储下来之后,我们怎么样获取这些数据?那么在这里我们数据获取的方法实际上最常见的,如果是从关系数据库里面的话,我们可以使用了这个SQL语言去采。那么这个sql语言那么它的一个处理的顺序我们上节课讲过主要来首先第一个他是先执行这个
先执行这个from子句,从from子句的这个表里面那么早到来我们说的相关的一些查询的表,这个如果有几张表的时候,他们是做一个笛卡尔层级的。第二个我会利用这个薇儿子句中间的这个条件进行这个原主的选择。抛弃了那些不满足啊where条件的那些原因。第三个,我们会根据一个group by这个子句对保留下来的元组来进行分组。第四个呢,我们会使用了这个having子句中间的条件对分组后的这个元组集合进行选择。抛弃的不满足这个having条件的这些原因。那么第五步呢,我们会根据这个select子句进行一个统计,计算生成结果关系中间的圆。这个嘞这时候就对着我们说的一个分组,对应的结果中间的一行。这里的我们上次课特别讲到的这个Google by的这个里面常犯的一个错误。就是你在这个统计函数里面没有统计的那些属性,你出现在了最后的这个结果你那么这时候这样的一个SQL的解析器就不能明确的知道。你到底是想返回的是这个结果,这个集合中间的哪一条,所以它就会报错。最后呢他的一句来是根据查询的结果呢可以做一个排序。可以用order by的方式进行一个排序,其实我们做的使用SQL语句进行查询的。那么我们今天呢首先来看一看关于XML素的一个这个方式去查询,那么我们可以用express的这个方式去查到。那么我们前面的客人讲到过一个事情,我们讲到这个啊df,他可以以XML的这个形式来去表达。那么如果你使用这个XML的形式去表达的话嘞,那么这时候你就这个有一个很直接的想法,我是不是能用查询XML的语言?去查到这样的一个啊df这样的跟里面的相关的内容。这时候我们时代就可以用的express这个语言去进行这个查询。哦,我们来看看这个express。那么expressly他是这个简单的一种这个查询语言。那么他呢是这个大多数啊这个和XML相关的查询语言的一个基础。那么它主要呢实际上包含了两个部分。那么第一个部分是一个文档部分的这个选取。也就是说选择你XML到底你去查这个文档的什么地方?第二个嘞,他要进行了这个搜索的这个上下文。也就是说比如说我在一个XML树长,那么我要把这个节点了,这个编码成一个有序的集合,那我需要在这个集合里面可以进行一个便利的操作。那么这个express实际上在XSLT中间是广泛的这个使用。我们前面课时在介绍XML的时候介绍过access lt,那么他是我不做XML的一种呈现的这种语法。你就说你可以把一个XML文件呈现成一种固定格式的网页或者等等的形式。那么这个express适当就在这个XSLT里面广泛的去使用了。这里这个x pass了他的一个不好的地方呢是他本身啊。包含了非XML的语法。所以他不是一个自包含的,也就是说你如果想用express的话。你得了稍微来去学习一些x test语法,而不是说你仅仅啊。只会这个XML就够了,所以这个增加了一些额外的这个负担。但是总体来讲,这个expressed他的,因为他这种简单的查询语言那个他来这个比较容易,那么如果要学的话呢也可以很快的就学会。
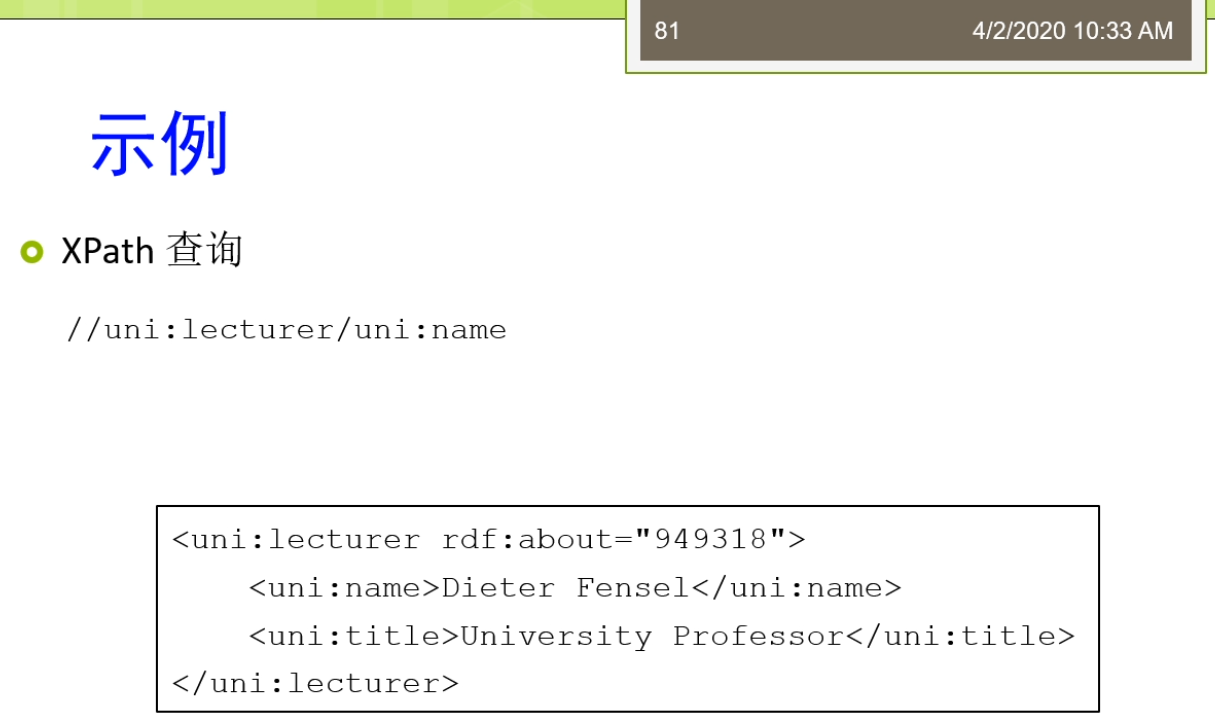
如果在这里,那么它主要的这个express里面的主要的动作或者功能主要有这几款。第一个他可以和文件系统类似。它可以取到这个根。那么或者取得当前的一个路径。这个呢是我们的这个XML他的一个很重要的一个基础。我说XML他是一个树状结构,那么树状结构里面,那么你第一步需要找到的时代就是这个根。你通过这个跟到位置,实际上你可以实现了很多的下面的便利的操作。第二个我们说我们可以有的是一个查询结果,它是最终的搜索的上下文。通常呢它可以是一个节点的这个集合,因为你返回的时候不仅仅可能是一个点。也可能是满足条件的一组底,这时候了你返回的是一个节点的集合。第三个了,他有一个过滤器,这个过滤器的可以定义一些过滤的特征。修改了这个查询的上下文。使得了你可以查询满足一定条件的东西。最后呢,他可以通过元素名,属性,名,类型,内容。侄关系等等的来选择了相应的合适的这个节点。返回来这个查询结果。所以呢这个就是express它的一些主要的这个功能模块。就是这么的。那么如果来你比较这个对XML熟悉的话,实在是比较容易去找到这个express,学会什么续写这个express。那么除了这个express之外了,实际上还有一些其他的XML的查询语言。我可以看到比如说有x query,它是建立在和xs一样的功能和类型照的。The express2.0里面这两种语言呢更加相似。X query来他不是也基于XML的,但是在他存在一个XML的这个标法。叫x query x。怎么1.0版本还是2007年的时候w三c来形成的一个推荐标准?那么以及还有这个apps link。那个他是定义的一种在XML文件中啊创建超链接的一种方法x pointer,那么它允许啊这样超链接指向更具体的部分,还有点XSLT啊,2.0版等等等等。那么这些呢它都可以实现一些XML查询语言,但是就像我们右边的这样的一个图上面表示的一样。在这个过程中间,他们的一个交集,这些语言的交集,时尚都是这个express。所以这也体现出哇呜说这个express它的一个关键的这样的一个特征。啊,具体的我们还是回到我们前面啊df的时候,我们来看一个例子。怎么在这个例子里面,实际上这个例子我们已经看过好几次了。这个例子里面我们呢有一个XML的片段,这个片段里面说了。首先我有个949318这样一个IDF的这样的一个。我们实际上是一个实体实力,他的酞普兰是一个lecture,然后呢他的name来是一个较低tensor的人。他的title来是一个University的professor,这是我们的一个片段。那我们express的写成一个什么样子的express的写成了这样的一个形式。首先,他说的是我要找到一个什么。我要找到一个RDF的description,这是我们的一个根节点。这就是我们的一个根节点。那么这个根节点里面,那么他要求呢满足一个xrdf的type等于这个lecture这样一个情况。所以这时候他就意味着我实际上要在根节点下面找到相映的这个态势,这个lecture的这样的一些节点。然后呢我再说把这个节点的对应的的这个内容把它取出来。所以这样的一个过程呢就形成了我们坐在一个便利的过程,我在这个xp上面从根节点一路向下去寻找关系。那么这里实际上呢我们说如果呢我们刚才的那个形式,你的那个形式啊啊df的形式变了,变写成了这种形式,我算这个是我们之前说的的啊df的一种短型的这个short form的这个写法。而前面的那个时候,每种long form的写法。那么在这个short form的这个写法里面,我们说949318,他的态度就是个lecture。而不是像前面一样我们用的RDF description这种long form的写法,比较繁琐的写法。那么在这里,那么这个时候啊,你的express如果想查他的name的话,就变成了这样的形式做这个nature,然后直接来electoral为根结点,朝下来去便利。让他的那最这个时候啊就带来了有个我们说的这样的一个问题,也就是说虽然对于这个idea而言,他写那两种不同的这个等价的写法。一种呢是这个我们说的整个的这个长方形的囊form的写法。李总来说,我们做的这个short form的写法。那么这两种写法对应的的这个express的却完全不一样。写成不一样的形式。这个呢时尚是一种不太好的形势,我们前面说这个不管是长兴还是短信,他们都是等价的。他们等价的在这个机器解析之后都会在这个系统内部啊解析成这个长形的这个形式。但是你这个只是字面上写法上的一些区别,却导致了你的express要写成不同的形式。才能完成这个相同的任务。那么这样子适当是一个不够智能的,不够方便的一个体现。我们希望的是实际上不管你底层的这个数据啊是写的怎么样的形式。那么我们都可以用统一的这样一个IDF三原图的结构啊把他查询出来。所以的,在这里我不说这种依赖于XML诉状结构的这个express。这种查询语言也不是一个我们学的最好的一种选择。那么这就引出了我们说我们觉得的一个比较更好的一个选择。就是我们要用一个专门的啊df数据啊,他在这个查询语言。这个呢称为叫sparkle,这样给予什么这个语言呢实际上是针对IDs数据特别帅气的。那么它和一般的这个SQL语言呢有一定的相似之处。但是在它的背后的这个原理是那种不太一样。因为这个x SQL这样的一个语言,它背后的理论基础是以这个关系代数为这个基础的。而这个sparkle了他的背后的基础来时大势以这个图的匹配。作为他的背后的技术基础,你的基础。所以这两种基础的差异来也导致了虽然从这个语法结构上看有点相似。但是从原理上看来,他们是完全不太一样的东西。哦,具体我们来看一看我们现在。这样的一个怎么样去查这个是吧?狗它的一些特点。第一个这个sparkle来是一种RDF的这个查询语言。那么第二个它的一个特点来是他基于了一种叫阿dql的这样这个语言开发的这个阿迪是当时这个sparkle语言的他的一个前任。这个阿迪是以前在在我们说的像这个间呐等等的这些ref解析软件里面,那不在工业界这个形成的一种这个语言。这个语言呢当时来那么因为他比较好用,那么大家来都比较喜欢,那么慢慢的。他成了一种这个把他围在这个事实标准,也就是说大家都比较喜欢比较常用的一种标准。那么在这个标准之后来那么w science了,要么万维网联盟难觉得呢这个语言呢那么可以把他升级为一种规范的语言。那么就把id ql了,变成了我们说的18口语。所以呢这个查询啊RDF的降一个sparkle的语言,它的前身呢是啊是来自于这个啊dq。最这些也从另外一个侧面看出来这个语言啊他并不是。这个凭空去定义的不是一开始就这么设计,而是他是在这个广大这个用户啊他的一些使用的基础上归纳出来。第三个18课的特点是它使用了类似于啊SQL的这个语法。这里我们需要对他只是使用了这个语法,他从这个语义上来讲。那么他是完全不太一样。
好,我来看一看,比如说这个下面这个东西就是我们做的一个sparkle的这样一个查询语言。他的一个这个片段大家来先来花一点点时间来看一看这个片段啊,他大概在讲什么?大家来猜一猜,看看你能不能大概看懂这个是八口啊这样的一个句子,他到底想表达是怎么样的含义?啊,这个片段因为比较短,大家就开开始来看一看。首先呢在这个里面我们时段有几个部分。第一个部分是对于sparkle这样的一个查询语言来讲,经常呢他会在上面写一个叫perfect的这个结构。这个perfect的结构了,适当就是一个对于长的URI,我可以进行把它缩减成一个前缀的表示的方法。这里我们对于一个完整的URI来讲,那么一般我们是写在这个监控号里面。这点大家需要注意。他不是直接去写一个URI,而是他要把这个URL放在这个尖括号里。因为如果你不放在坚果号里面,那么他会认为这个来可能就是一个传统的屏这个字面量。他以这个尖括号括起来的作为一种特殊的标记方法标记出来。这个里面的字符串是一个URI。那么而对于这个URI来讲,我们可以把他来写成某种潜队的形式。这个前缀来大家一定要记得这个加一个冒号这个地方。这个前缀来那么主要的用出来是为了使我们后面这个查询语句写的时候来比较简短,比较方便。那么这个呢它的姿势它的主要作用,当然你如果不喜欢这个钱对的话,那么你也可以的不行。那比如说我现在在我写18课的这个过程中间,我也会经常定义几个常用的前有时候我们说IDs are DFS这些这个w三c规定的这些语言。那么实际上很容易应该来讲你会把它变得这个钱。对,因为你后面呢会反复的用途。那么钱对之后就是我们做的一个真正的一个查询的结构了。查询结构里面我们这时候可以看到。他和我们的SQL确实很像,他也是select from where这个结构。那么select就是我们说要挑选出来最终的查询结果from了这个子句了,就是我们要从哪一个IDs的片段里面去查。为了就是我们做的要满足的这个条件。这个地方大家需要注意的是几个地方,第一个我们在原来的SQL语言里面。我们专门说过select from这两个子句是必不可少。而在这个sparkle里面不是这样,spark里面这个from实际上只表明呢他可以从一个我们做的叫命名图,叫named graph里面进行这个查询。也就是说对于一个graph来讲,你可以把它命一个名字。如果不写from实战,意味着就是你想查询这个来源数据里面的所有数据里面进行解锁。而不需要去考虑你从这个刚才来源的所有数据的哪一个片段里面去解锁。所以这个from更类似于我们说缩小范围的这个结构,而不是我们说的真正的一个表的这样的一个查询。对这个地方的from在spark里面是可有可无的。所以一个查询来讲,那么你可以直接只有select和weird这个词群are from可以不要,这让大家又看到这个from实战我们会写成一个URI的形式。第三个。我们说在这个里面我们会以一个问号作为一个开头。
问号开头时,当表明的是我们的一个变量。这个来和SQL不太一样,SQL里面这个变量比如说一个属性名等等的。那么它是直接写他不做这个得做一个特殊的标记。而且sparkle里面所有的这些要查询的变量,那么它是它是一个以问号的形式开头。有时候我们在这个语句里面我们说我们要查到问号,那就是表示我们想查的最终的变量是什么。当然这个变量你起一个有名有异议的,你叫name这个也好,你起一个没有意义的叫x。ABC等等的也好,都不影响了这个查询的结果。那么第四个我们说在这个子句里面,这个物业之局里面实际上它的极里面的东西不太一样。这个里面的东西啊它十大和SQL语言完全不一样,它是基于的一种三元组的结构。那么他查询到结果的方式实在是基于的我们做的子都匹配的家庭结构。大家首先呢来看一看在这个里面我先说有一个问号s,我想让他的name呢是一个问号的,那实际上这个过程这句话就是表示的,我想找到一些满足条件的s和这个内。他们呢这样的一个东西是在同一个三元组里面出现的,而三元组里面的这个谓语了。下是name这样的人有line长的东西。这个让大家又看到了这个Union name时代就对应的我们前面的那个尖括号,HTTP example点org港unit。然后来到name,然后呢反过来的见过好这样一个形式。虽然这个量大家要注意的,如果你是写成那这个短的这个形式用钱堆的方式去写。你就不需要在两边了加引号啊,加这个坚果好,如果来你不是用这种。这种一个前缀的形式去写的话,那么你就需要用尖括号括起来之后写上完整的you are。那么在这个过程里面,我们说啊我们有两条,第二条小查的是s,他的太破了。是一个lecture。这里面在这个查询里面,如果这个变量取了相同的名字。使让的我们就认为它的取值应该是一样,它指的是相同的一个变量。所以在这样的过程里面,我们where子句里面想找的内容就是。我有一个s。他来他的类型是一个lecture,并且在这个s的name,我想把它取出来。最终呢我的这个结果里面实际上有两个变量,但是我最终在这个投影的这个操作里面,我只要把name投影出来,s的这个里面的细节的,我就不需要他做一个中间变量。最这个就是我们说一个sparkle语句,他的一个大体的一个结构。这个结构里面了大家需要做。啊,这边呢还差个几万块,也就是说在这个句子里面,那么每一条这个查询了三元组结束之后,我应该在后面来加一个这个句号。这个句号的十大表明了我这个查询啊时间到这来结束了。那么在整个的这个sparkle的查询里面,我们呢总体上来讲会分为了四种查询。第一种查询被称为来教这个select查询。Select查询但是返回来变量绑定的一个结果。这个号码SQL里面的select实际上是类似,也就是说我把相映的问号的下面的东西,把它的结果来这个返回出来。这个是最好理解。而另外两门还有三类是这个XML里面呃这个SQL里面这个没有见过。第一种呢被称为叫construct查询。It struck的查询呢返回的是这个威尔中间满足这个where条件的。这个啊df的图。所以这个地方他和select不一样,它不是返回的是一个变量绑定的结果不像关系数据库一样把那个结果值班的去做。Construct返回的是一个RDF图,这个图呢是根据我们做where子句的条件描述出来。
第三个是一个这个ask查询这个20个查询呢主要用于去测试返回是否有满足。这个weird这样的一个IDF的企图。也就是说这时候他不关心的是查询的结果到底是多少,有多少个,他关心的是我是不是能查到结果。所以这时候来他可以用ask的命令去做。那么如果有一个能返回制造一个结果的话,那么这个查询呢就终止,我告诉你把这个结果来是满足的。那么最后呢是我们做的一个describe查询。他用鱼的得到关于某个实体的描述信息。也就是说这时候我做describe一个URI,那么实际上意味着我想把这个ui里面。所有的和这个实体相关的这些三元全部把它取出来。这个嘞就被称为叫describe查询。那么第一个select是我们刚才做SQL里面比较常见而construct ask。和这个describe来是我们之前了没有怎么建的,但是呢他的这个语法或者雨衣的身上都是比较简单的。他们而且都可以变成以select为基础的这个查询,因为比如说我们是吧?关于这个ask来讲。那么如果你已经用select语句能查询出来一个结果了,那么你就可以终止,然后说这个ask的返回结果来世真。Are described时代,就相当于你用select语句把某一个实体相关的所有的三元组的群。就是described,虽然在这些查询里面还是以这个select为基础的。那么另外也要说到我们说这个select的这个查询在swap里面。对吧?主要都是以这个查询为主。那么而SQL里面我们前面说的这个SQL里面我们可以有。这个呃这个删除,更新,插入等等的操作,而只写了18课里面暂时还是不考虑。18个里面他考虑的主要还是以查询为主,虽然很多的系统比如说我们说一下我驼所这种系统等等的。他可以来这个区在这个自己的里面支持,比如说数据的插入啊,更新啊等等的。但是他可能使用的不是一个严格的sparkle的规范是做的,而是使用这个系统的。自己实现的东西。啊,下面呢我们来开始啊来看一看这样子一个这个啊df他的一个句子一个事例。怎么在具体来讲呢?这个地方我们大家可以看到在这个里面。我们做的一个事情,我们把这个啊df啊直接写成了一个三元组的形式。这个三元组的形式的第一行,比如说John,然后呢他的饭这个full name是John Smith。这就是一个简单的一个三元组的形式。这个呢和我们之前说到的这个XML表达方法不太一样,这个表达方法的相对来讲呢比较这个直接。现在的用的也比较多,比如说在我们的这个呃一般进厂里,如果以后这个做比较多的和这个知识图谱相关的一些研究的手,你会发现很多知识图谱,他在这个数据文件你给我当下来之后。那么它都是采用的这种三元组的结构。这种三元组的结构。有的时候来被称为就要这个entry破的结构也有的时候了,还有一些更简化的,比如说turtle的结构啊等等的,那么本质上它们背后的模型都是一样。都是这个三元组的模型,只不过呢他写的这种形式的可能比x玩的形式的首先第一个更短一些,因为XML形式你需要变成一个树状结构,那么需要展开。另外呢这个形式相对来讲来对人来讲或者对机器来讲也比较容易去看。也就是说每行就是一个三元,我可以把它原封不动的拿出来,把它导入进去就完成。所以这是我们所啊df的图的一个示例。包括比如说我们现在在这个右下角看到的这一种是另外一种格式,这个啊df这种IDF的格式里面,我们在这个格式里面我们把它写成了一种这个类似于像Jason的这样的格式。这个格式里面也实际,但也是一个三元组,比如说我们做装它的这个for name,v card,the four names,John Smith。他的这个那
他的这个for name,v card的four names,John Smith,他的这个name下面又分两块,一块是given,是一个job。Family的是一个Smith等等,谁要都有很多种不同的这个id,f的写法。大家这个量一定要注意这个啊df的这个写法来,不要拘泥于一定是写在XML的形式。RDF我们前面说它是一个数据模型,它以什么样的这个呃语法区写十道都无所谓的。那这个呢大家去不?啊,首先我们来看看第一个查询。在第一个查询里面,我们想返回的是这个所有人的。在这个图里面的一个for name。
全民那这时候来我们时代就可以把我们的这个查询啊,是吧?过来写成这样的一个形式。在这个寝室里面大家适当又可以看到,我说刚才我们说有一个perfect。Norfolk讲的是我这个查询我有第一个查询,那么这个才呃这个查询里面的第一个URI。我把它缩写成了一个叫v card这样的一个形式,这个前缀。这里的这个we could这个钱对我们缩写成这样一个冒号的形式。那么这个未看的用在哪儿了?用在这个物业只居里面。我说我要查一些满足条件的这个三元。这个三元组的条件是什么呢?说他要用到一个叫for name的这个属性。那么我不管x是张三还是李四,只要他用到了four name,我就把这个full name属性的取值版的拿出来。然后呢这个取值就作为select的这个返回结果。所以这个量大家看到了,那么在这个句子里面这个查询里面实际上它是没有from子句。那么它没有from子句,意味着它就是想再整个的id,f图上啊进行一个这个插曲。那么在这里我们说很简单,如果我对照这边的xr这个啊df数据的话,我就可以看到。我要查的实际大事x他有个for name,那么x的,不管是谁。有for name,比如说这个量有一个four name用的了,然后呢这个点也用了for那所以这时候我们说x可以取装,也可以取来这个Mary。而他的full name的一个是John Smith,也是Mary Smith。然后呢因为我们select语句里面我们要返回的只是这个falling。所以我最终结果了上就是John Smith of Mary Smith这两个结果再找。对,这个就是我们说第一种select查询,我们把它称为了按这个是吧口查询把它称为来叫select的形式的。叫咱学。啊,我们这个呃第一节课来先上到这边,我们先下课了,这个休息一会儿。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号