

知识工程及语义网技术 2020-03-19 (第一节)-构建本体
https://www.bilibili.com/video/BV17E411P758/?spm_id_from=333.788.recommend_more_video.5
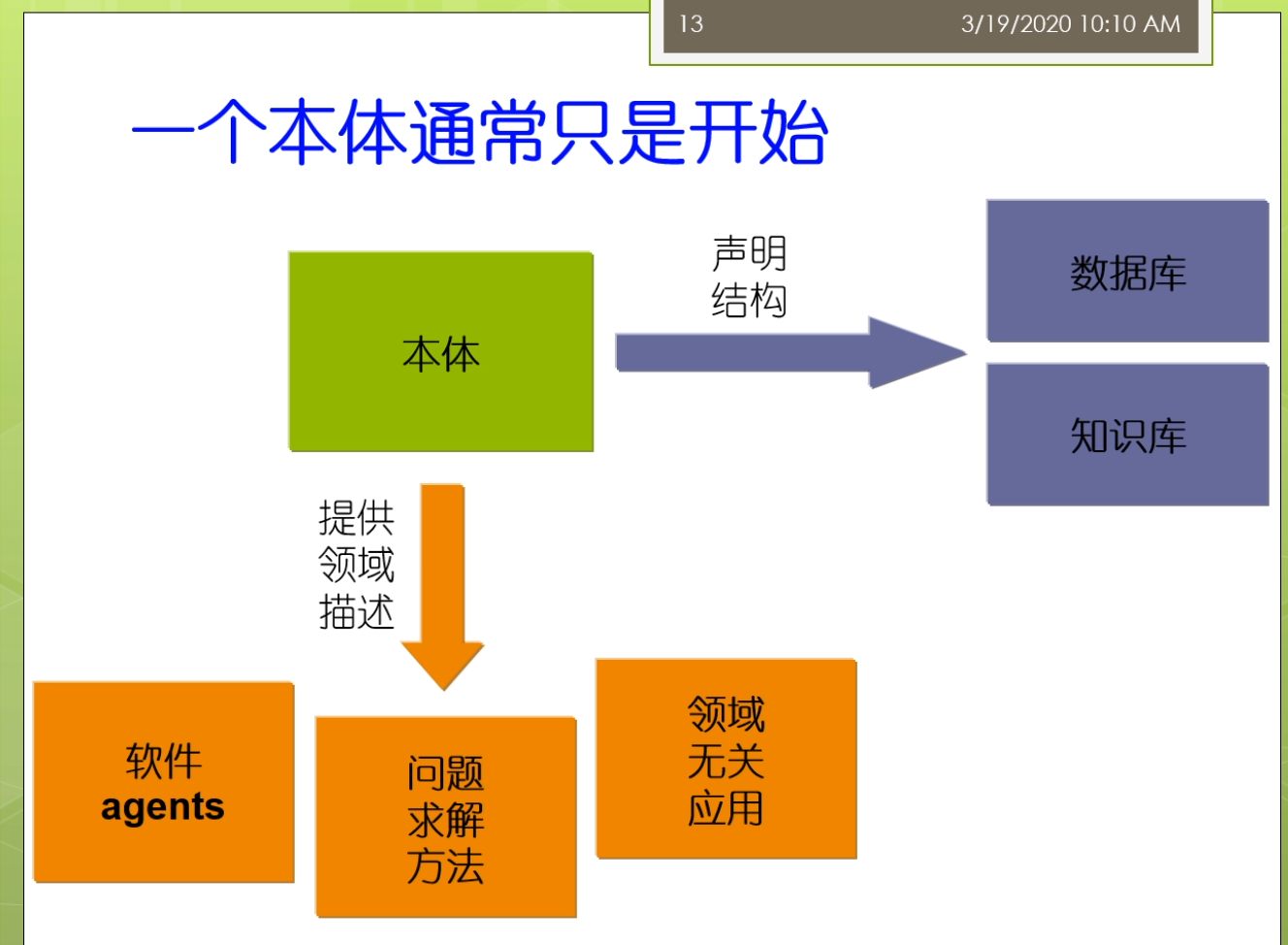
那么我们上节课来讲了大概的这个本体工程啊,那么我们说一个本体呢,它通常呢只是一个开始,因为这个本体啊,他构建完之后,那么他要继续的在一些领域中间去使用,比如说它可能呢会为数据库知识库声明相应的结构,它也可能呢为这些相关的一些应用,比如说软件agent,然后呢问题求解的方法,领域无关的应用等等的,可以去提供一些这个领域的这个描述。
我们在这节课来开始用一个这个例子啊,那么来看一看我们一个本体这个构建的过程
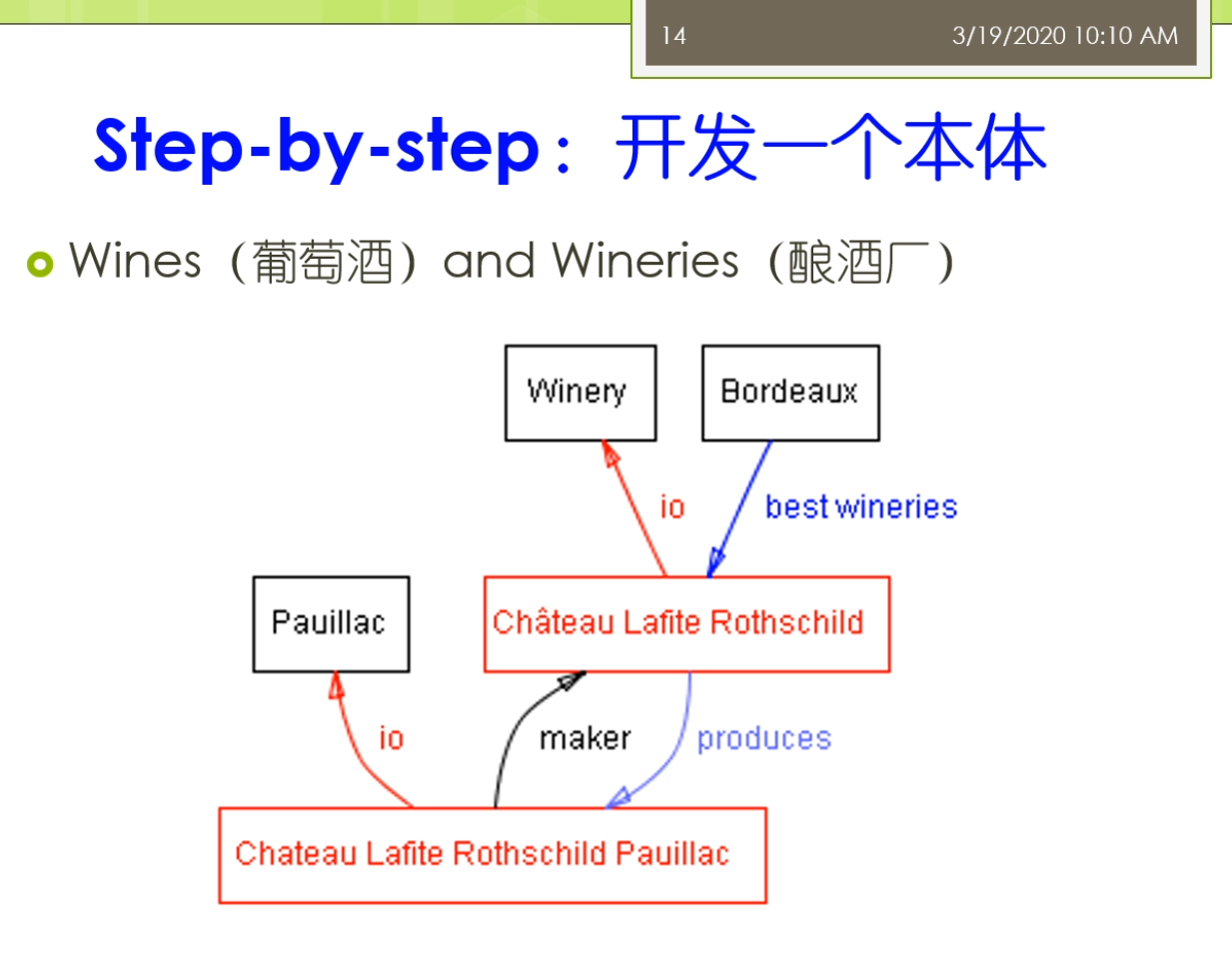
看一看我们一个本体这个构建的过程,那么在这里呢,我们实际上举一个这个就是说一个用于这个本体教学里面常用的一个例子,这个例子来称为叫这个葡萄酒和葡萄酒厂的这样一个例子,那么在这个例子里面,那么实际上呢,我们可以看到,我们可以定义呀,好几种类型的这样的一些概念,或者一些相应的一些他们之间的关系,比如说我们说我们可以定义一个这个酿酒厂,那么底下的这个a表示的是一个instance of,那么实际上是说具体的某一个比如说一个酒厂,那么他呢是葡萄酒厂的一个实例,我们上节课已经讲过,我们是一个实例,然后呢,那么还可以定义的,比如说这个沃尔多,那么它是一个最佳的一个酒厂是哪一个,那么这个酒厂呢生产的酒具体的一种酒是什么,而这种酒呢,它的这个概念呢,是某一种这样的具体的某一种类型的葡萄酒,所以呢,这个是一个大概的这样的一个样子,我们具体来就会来看到这个本体,我们怎么样一步一步的去构建,那么大家呢需要注意的是我们在这个课上面呢,我在这个教学立方里面实际上已经布置了一个课后作业,那么希望呢,大家呢,这个也在课后呢,能够来按照我们今天讲的这样的一些东西,以及结合前面我们对于这个rdf、owl这些相关规范的一些介绍,那么大家来动手来去构建一个自己的这个本体,那么具体的要求呢,大家可以在那个教学立方里面找到那么以及呢,大家不要忘掉这个相应的提交作业的一个时间点,另外呢,我还提供了一个这个相对来讲比较复杂一点的一个本体的作为示例,大家来可以这个看一看,学习一下。
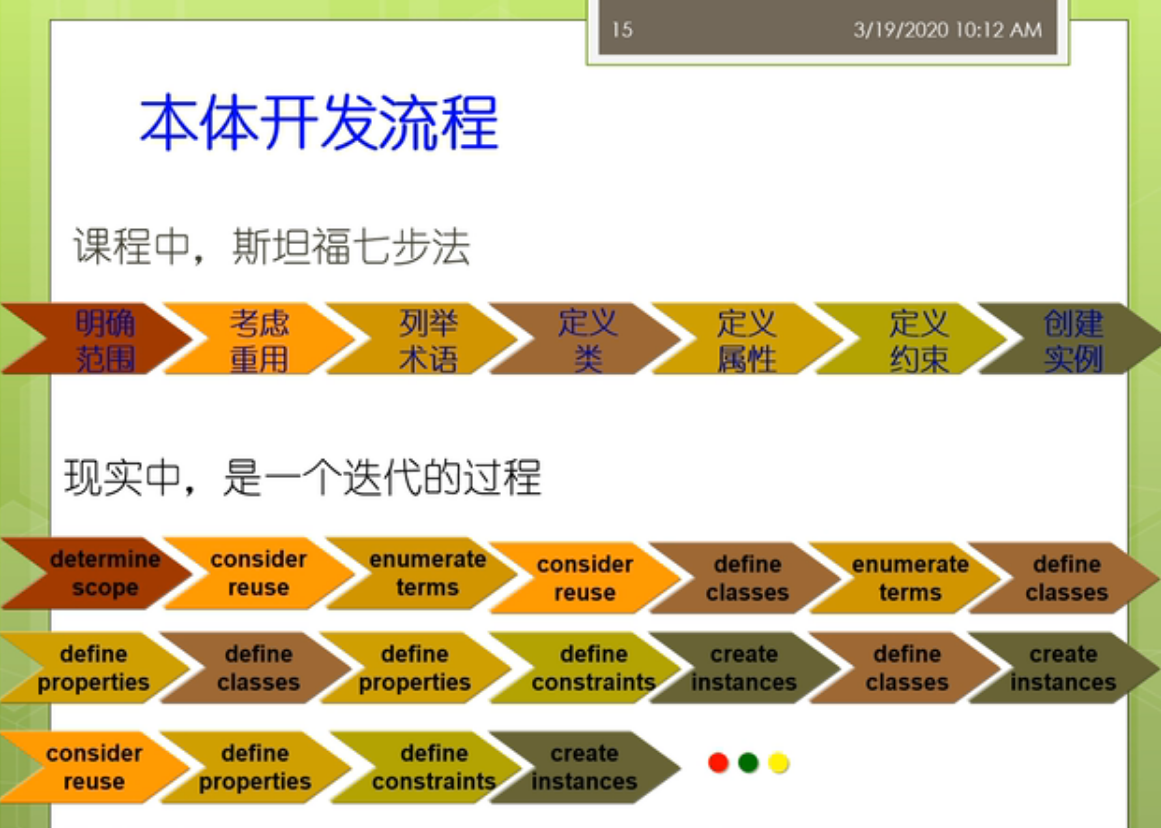
好在我们的这个课里面呢,我们主要介绍的一个开发流程呢,被这个俗称为呢叫斯坦福7步法,那么这7个步骤呢,实际上就是这个图里面所示的第1步呢,称为叫这个明确范围,也就是说我考虑啊,我这个本体它的开发的范围是什么,因为我们不可能对整个的这个真实世界去做建模,我们可能只能考虑其中的一部分,所以呢,这里呢我们只能说,我们要首先要确定我们考虑的这个范围,这个边界在什么地方,第2步呢,我们有一个叫考虑重用,也就是说在我们的开发本体之前,我们要去看一看,我们到底有没有啊相关的这些本体可以直接去使用,如果已经有了一些这个相对来讲别人定义的很好的这些文体,那么实际上我们没有必要啊,在自己从头开发了就变成我们常说的这个重新造轮子的这个过程,那么实际上,特别是的对于有一些领域而言,有些领域啊,他由于已经有了比较大的别人,花了很长时间,比如说好几年好几十年构建的这种权威的本体,那么你如果不重用想自己从头构造的话,那么可能你的这个代价也是很大的,所以在这个场景下你可能还是需要考虑怎么样尽可能去重用它,那么第3个步骤呢称为叫列举术语,也就是说我们考虑一下我们这个本体里面重要的一些概念属性等等的是什么,我们能想到什么我们就把它先列举出来,那么这时候呢,我们没有初步的一些分类,到后面我们就要对他们这些术语进行分类,包括人了类包括了属性,包括了这个约束,最终呢,我们还可以在这个本体中间呢创建一些实例,那么如果这个本体中间包含了大量的实例,以及这些实例之间的这种事实关系,实际上呢,这个就变成了我们现在常说的这个知识图谱,那么课程中间呢,我们呢是一个很简单的这样的7个部分,走的过程我们来是一种互动式的,这种开发能够从头到尾,但是现实中呢,它可能是一个相对比较复杂的一个迭代的过程,那么可能是这样的一个过程,大家可以看到,那么我们不断的循环,这个过程不断的改进,不断的精化我们的这个本体,那么最终呢,实现我们的最好最后的这个要求。

那么这里呢,我们来做一个对比,我们把这个本体啊工程和面向对象的建模来做一下比较,我们说这个本体呢,它主要反映的是真实世界的这个结构,而面向对象这个类结构它反映的是数据和代码的这个结构,所以两者呢面向的问题不太一样,第二呢本体里面呢,主要呢包括的比如说是有关概念的一些结构,比如说我们说概念之间的这样的一个包含关系层次关系等等的,而面向对象类结构里面呢,主要通常来是关于行为的,也就是我们常说的这些方法,这些方法怎么样去定义,而另外在本体里面真正的这个物理表达不是特别重要,而面向对象类结构里面呢,我们经常会要有描述数据的物理表示,比如说我们要说这个数据我们定义了一个变量,它是整形的还是字符串呢?等等等这个呢,我们都需要给出明确的定义,否则在这个程序它执行不起来,所以呢,这两个之间呢,实际上是有很大的这个区别
而在我们这个课里面呢,我们会用一个预备的工具称为呢,叫这个approach的这个这个软件这个软件呢,实际上它是一个这个图形化的本体开发工具,它支持了比较丰富的这个知识模型,并且呢,它还是一个免费开源的这个软件,那么这个我们的这个课里面的截图呢,我们特地选了一个相对来讲比较老版本的这个截图,那么这个呢是这个2000年的这个板,那么正好呢,他和我们的这个刚才说的酒啊,葡萄酒厂的这样的一个开发的过程呢能对应起来,但是呢,我们现在呢,大家去使用的时候呢,我这儿来放了一个新版的这样的一个截图,大家可以看到你可以基于这个新版的这样的一个东西来去开发,那么新版中间呢提供了更丰富的一点的功能,那么更加强大也稍微来复杂一些,那么除了这Protege这样的一个软件,像一个软件之外,那么其实还有很多其他可用的工具,比如说这个Ontolingua and Chimaera, OntoEdit或者oiled等等的,那么这些工具呢,实际上也可以用来开发我们的问题,但是总体来说呢,这些工具来实际上他们的这个呃,现在的可用性或者市场上的这个占有程度,实际上跟这个斯坦福的Progete相比呢,那么差距还是比较大的,基本上来这个和这只这个工具啊,斯坦福大学开发出来之后呢,那么通过这么多年的这样的一个一个持续的发展,基本上呢,他已经占领了整个的这个市场,包括我们来这个平时大家可能喜欢去使用这样一个这个离线版本,它现在呢也有这个在线版本等等的,大家都可以去尝试.
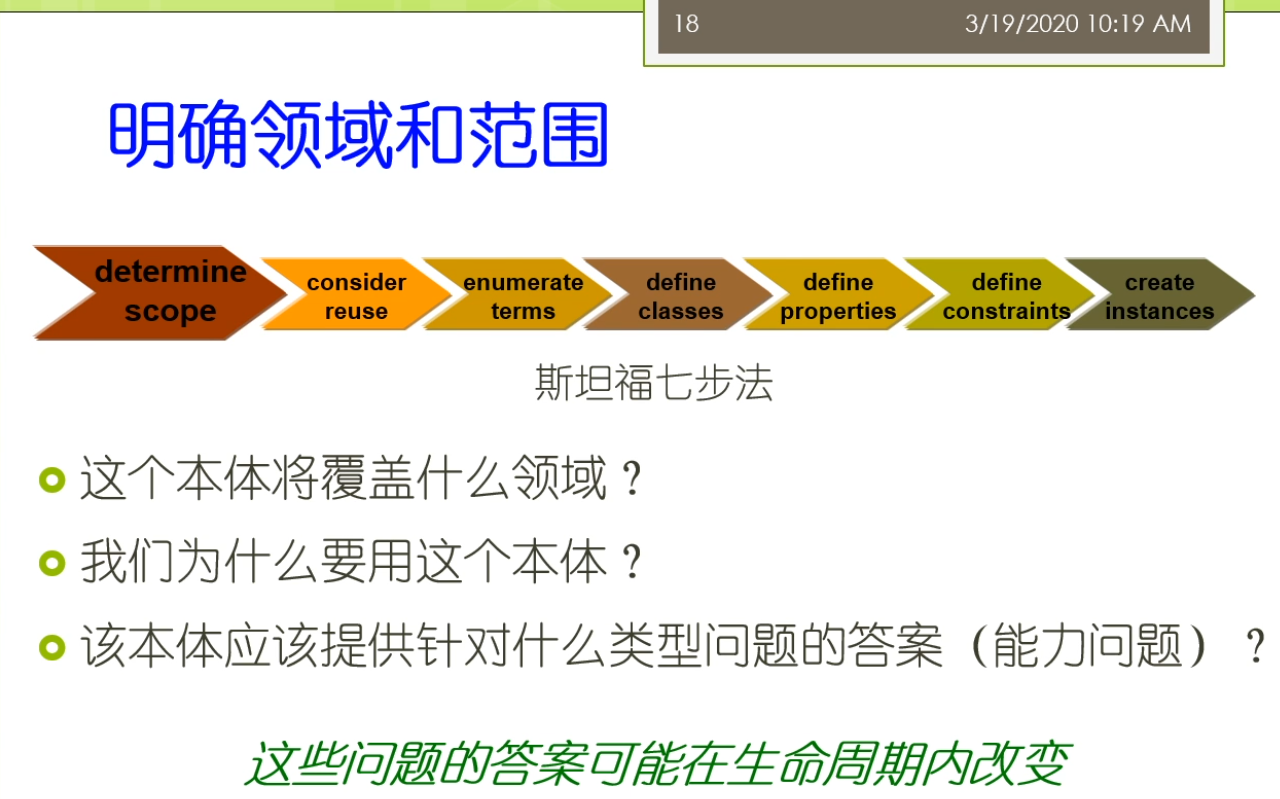
好,具体呢,我们就进入我们的这个开发的过程,第1个我们的步骤称为叫这个明确领域和范围,那么这个步骤里面我们是斯坦福7步法的第1步,那么我们主要需要考虑的几个内容包括了比如说这个本体啊,它将覆盖什么样的一个领域,我们呢为什么要用这个本体,这个本体呢应该提供啊,针对什么类型的这个问题的这样的一个答案,那么这些答案呢,那么可能呢,会在我们的整个的生命周期内呢,发生一些改变,也就是说随着我们本体啊定义的过程,它不断的这个深入,那么很有可能我们一开始设计的时候呢,没有考虑周全,那我们在这个过程中间呢,也会发生不断的改变,那么在这里呢,我们经常会使用一种称为叫这个能力问题的一种这个方法去确定我们的领域,比如说对于我们刚才的这个葡萄酒的这样一个例子来讲的话
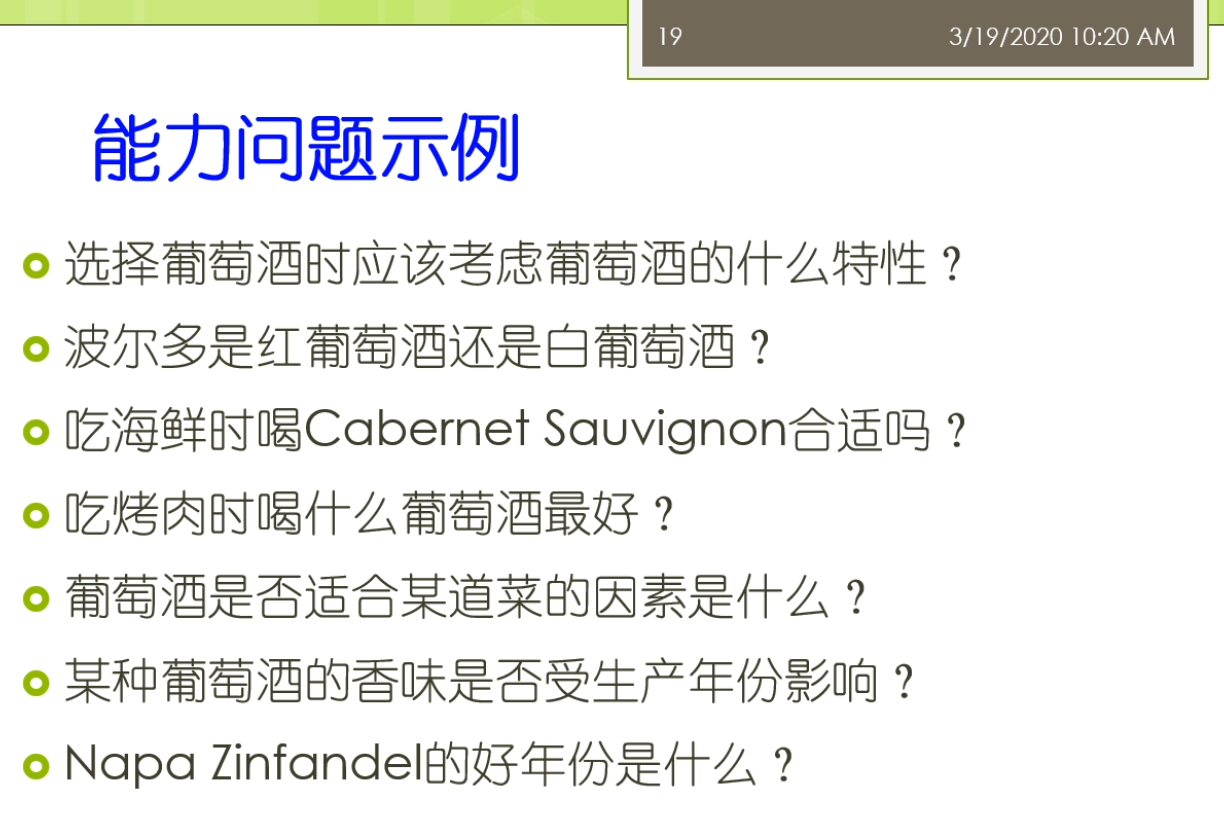
在这里呢,我们经常会使用一种称为叫这个能力问题的一种这个方法去确定我们的领域,比如说对于我们刚才的这个葡萄酒的这样一个例子来讲的话,我们的这个能力问题实际上就有这几个方面,第1个比如说我们选择葡萄酒的时候啊,应该考虑葡萄酒的什么特性,波尔多是红葡萄酒还是白葡萄酒?吃海鲜的时候来喝,这种合适吗?吃烤肉的时候喝什么葡萄酒最好?葡萄酒是否适合魔道菜的因素是什么?这种葡萄酒的香味是否受到年份影响,或者具体某一个什么葡萄酒,那么它最好的年份是什么?这些就是我们想列举出来的一种称为叫能力问题的一些例子,那么这些问题帮助我们去思考我们的这样的一个定义的领域,它的范围到底是什么,也就是说如果我们这些问题都是我们需要回答的,那我们就知道我们本体里面需要包含哪一些概念,哪一些这个关系,哪一些类的,而如果有一些问题,我们觉得不需要回答不是我们的这个覆盖范围,那么我们就可以不考虑这个这个这个相关的概念等等,那么这个就是我们的能力问题的一些例子

那么在确定的范围之后,第2步我们就要去考虑重用了,我们说为什么要重用其他的本体的,这里面有几个主要的原因,比如说我们可以相对来讲,比较节省人力,因为你不需要再去进行后面的这个斯坦福7步法的步骤,你可以来直接去使用,那么另外呢,你可以使用其他本体的应用啊,这个进行和他们进行交互,因为这个时候呢,你的这个本体是别人开发的,那么在别的一些应用中间,实际上已经有了很多的这个相关的一些具体的使用了,那么可能并且呢,这些使用啊这些应用中间已经检测了这个本体的它的可用性或者有效性,那么在这种情况下那么你去重用它,那么肯定这个质量上有一定的保证,并且呢,你和别的应用因为使用了相同的本体,那么你们之间呢,也方便互相的这个交互了,这个就是我们从用其他本体的一些这个简单的原因。
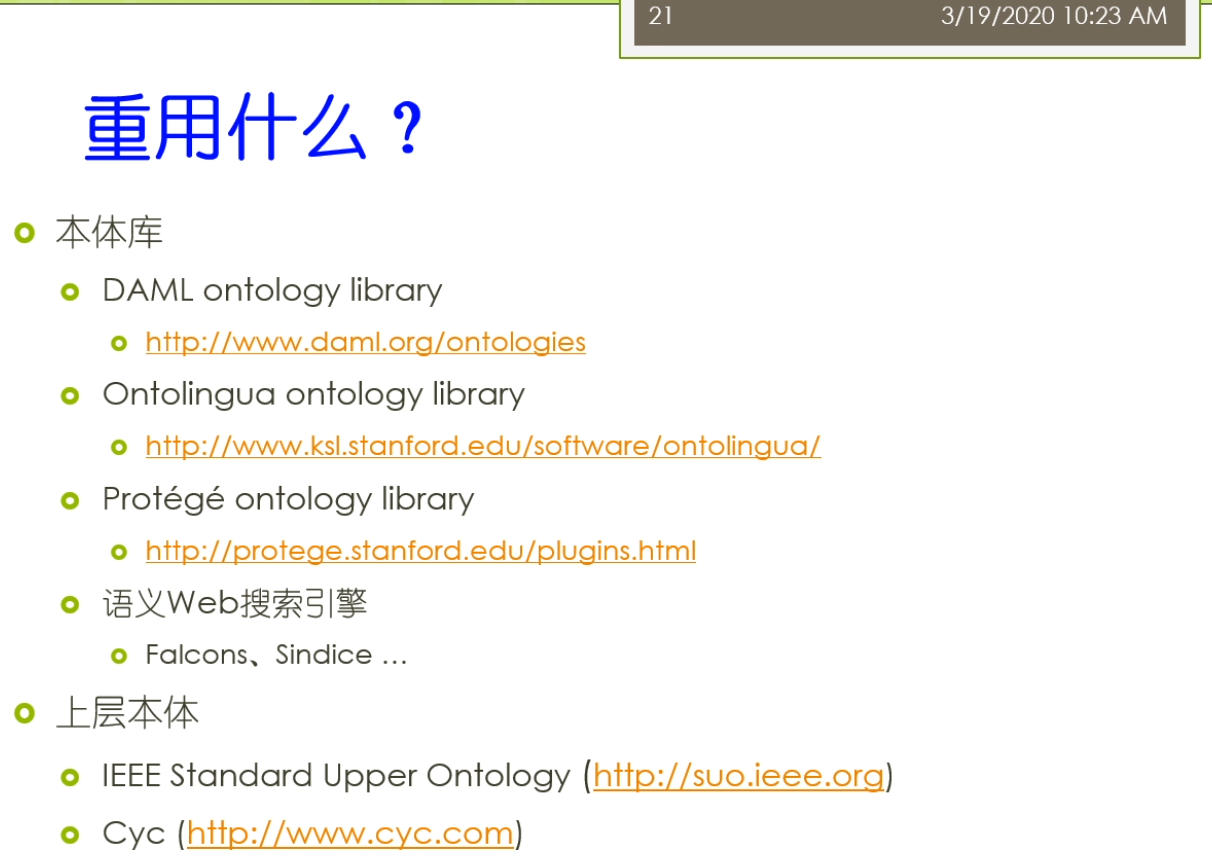
那么具体来讲,我们怎么去重用呢?那么实际上我们这里有许多的这个候选,我们之前也提到过这个在整个的语义web上面,那么现在有一些相应的这个本体库,比如说这个原来有DAML的这个Ontology library或者这个Ontoligua的这样一个librarty或者是现在像这个protege这个软件,由于呢他自己现在支持在线开发了,他也可以有一个他自己的本体库,那么她把大家的这样的一个这个开发的这样一些本体它把它采集下来,存储在那供别人去重用,另外呢,我们也讲到现在呢,还有很多与Web搜索引擎可以来在这些搜索引擎上面去使用,那么另外呢这些除了这个直接的去使用,还有一些相对来讲呢,这个不太一样的一些本体这些本体呢是比较大规模的,针对一些领域里面的这个设计的公认的问题,那么这种情况下你也可以部分的去重用它里面的一些结果,比如说IEEE有一个标准的上层本体,那么cyc呢是一个人类的这样的一个常识知识库,那么这些里面你不见得是这个全部使用它,而你可能呢只是从用它其中的一部分,因为它们的规模比较大,相对比较复杂。

那可能我们还有一些这个叫通用本体像dmoz ,word net等等的,那么这个word net如果大家以后去做自然语言处理的时候,那么经常会使用到这个word net,那么这个word net是一个我们说常见的名词等等的它的一些含义,然后它的上位词下谓词同义词等等的一些整理的情况,那么这个呢在平时的自然语言处理里面很有用,另外呢针对一些特定领域,我们也有一些不错的本体,有我们以前课上提到过我们有这个umls,那么它是一个医学领域的这样的一个医学术语表,然后还有啊,像这个生物医学领域的,像这个基因本体等等这些本体,它的开发实际上难度很大,那么这个国外啊等等的一些科研组织,那么花了很大的精力去研究了这样一些特定领域的问题,那么这些特定领域的本体,实际上你如果不重用它,而且要自己从头开发的话,那么很可能你会失败,或者你的开发的周期特别长难度特别大,那么这种情况下你为什么不重用别人的。
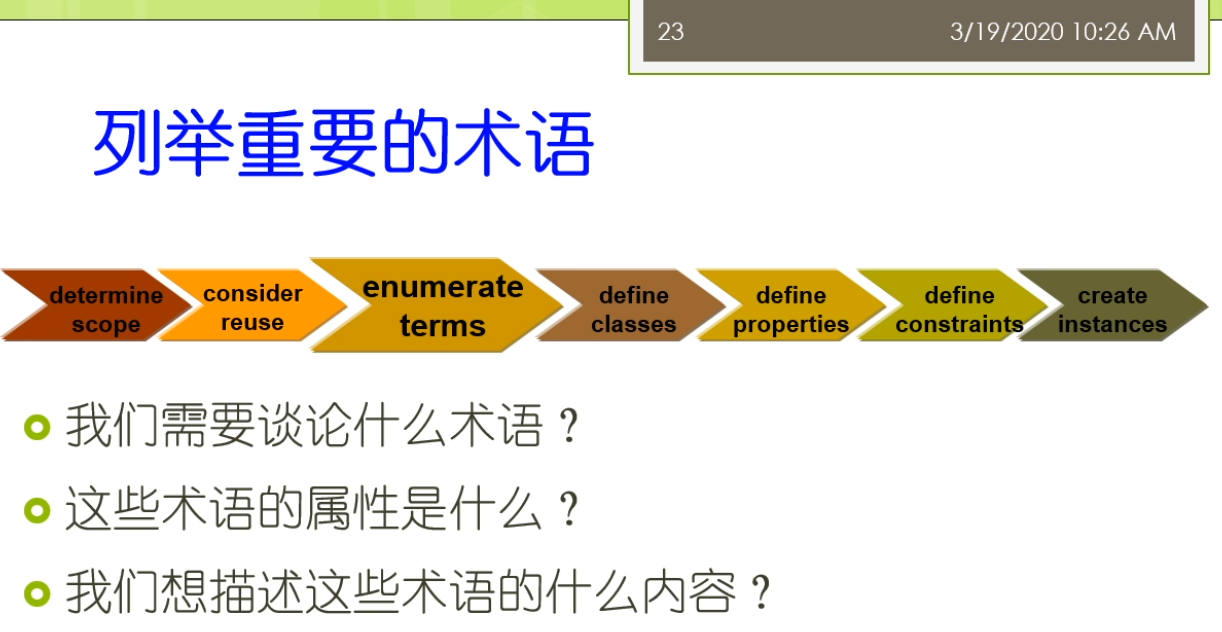

这个课堂呢,我们假设我们不能重用了,因为如果我们这个课以这个重用一个本体,这个找到了一个可以重用的本体,那我们后面的步骤呢就讲不了了,所以呢,在这里我们假设我们应该啊这个没有找到,那么我们接下来去看看斯坦福7步法后面的几个步骤,第1个我们下面遇到的步骤就是列举一些重要的术语,在这里我们可能就会涉及到我们需要谈论啊什么的术语,那么这些术语它有什么样的一些属性,以及我们呢想要描述啊这些术语,什么样的一些内容这里的术语来来讲,它是一些相对来讲没有固定的这个范围的一些东西,你可能是经过自己的思考觉得重要的一些东西,你把它列在了这都统称为了叫这个术语,比如说对于我们刚才的这样的一个本体这个葡萄酒来讲,那么我们可能列举出来一堆术语,比如说葡萄酒,然后呢这个葡萄酒厂地点,葡萄酒的颜色,这个葡萄酒的这个这个酒瓶子那么长什么样?它的香味是什么?然后呢,它含糖量包括它是红葡萄酒,白葡萄酒还是什么波尔多葡萄酒,他适合的食物是怎么?那么是海鲜与这些肉还是蔬菜还是这个奶酪等等的?我们能想到的我们都把它先列举,在这里列举的这个东西,这个过程中间,实际上就是对你之前这样一个领域范围,你确定范围的那些能力问题的一个回答,因为你想回答那些问题,你必须要包含着这些相关的约束,大家这里去注意到了这里面的这些术语不见得一定是一个class或者是一个property,它相对来讲各种各样的东西都可能存在着,比如说我们刚才说Wine它是一个class,那么它的这个color呢,实际上就是我们说的它可能是一个property,比如说它的取值是白颜色还是红颜色.

在列举了这个术语之后,我们就要去定义这个类以及呢我们要定义这个类之间的一种层次关系,在这里这个类就是我们刚才的这些术语中间我们可以挑选出来的一部分,那么他是领域中间的概念,比如说我们说葡萄酒是一个类,葡酒场呢,是一个类,那么红葡萄酒来是一个类。这些类呢,他拥有了相似属性的这个元素的集合,我们根据这个这个定义来去确定什么是累啊,具体来讲呢累有可能有些实例,比如说我们说午餐喝了一杯加利福利亚的葡萄酒,这个加利福利亚可能是这个葡萄酒它具体的一个一种这个葡萄酒的这么一个牌子,那么这个时候呢,它就是一个这个实例,这个后面那么区分什么是一个类什么是一个实例来,实际上啊是我们的这样一个本体定义中间的一个难点,也是经常呢,在一些时候啊,它存在一些这个二义性的一些地方。怎么定义都可以,那么可能你要选择一个你自己觉得更适合的方式

那么泪之穴呢,经常有一个层次结构,这个呢就被称为是一个分类层次,比如说纸类和父类的层次内,层次的通常来势一个额的层次,一个子类的实例来,他也就是一个父类的实例的,这个时候呢,大家一定要注意,比如说我们说研究生是这个学生的一个实例,那么具体,有个研究生叫张姗,那么张三是一个研究生,那么张三呢,也就是这个学生,所以呢,你可以这么想,你把那想象成是一个元素的集合,那么这个子类呢,就是这个集合里面的一个子集了,
比如说在这里我们可以有一些内层次的展示,我们说啊这个这个苹果呢是这个水果的一个子类,因为每一个苹果啊都是一个水果,我说这个红葡萄酒是葡萄酒的一个字类,因为每个红葡萄酒呢都是一个葡萄酒,我们又说这个有一个具体的一种这个葡萄酒,那么它呢是这个红葡萄酒的一个子类等等的,这个就形成了一个层次关系。那么大家呢,又回想到我们之前说的这个,我们这里的这个本体,那么它允许的这样的一个子类,那么它同时是多个附类的这个子类,也就是我们说的多继承的这个关系,那么这个情况下导致了这个类层次的关系,它不是一棵树,那么它是一个这个有向无环图,有向图的这样一个图状的结构,它也不能说是无环的,因为你也可能呢可以去定义这个环的形式,我们之前说的这个等价的Equivalent class,那么这种情况下就可以拆成一个循环的,sub class这样的一个关系,双向的sub class的关系。

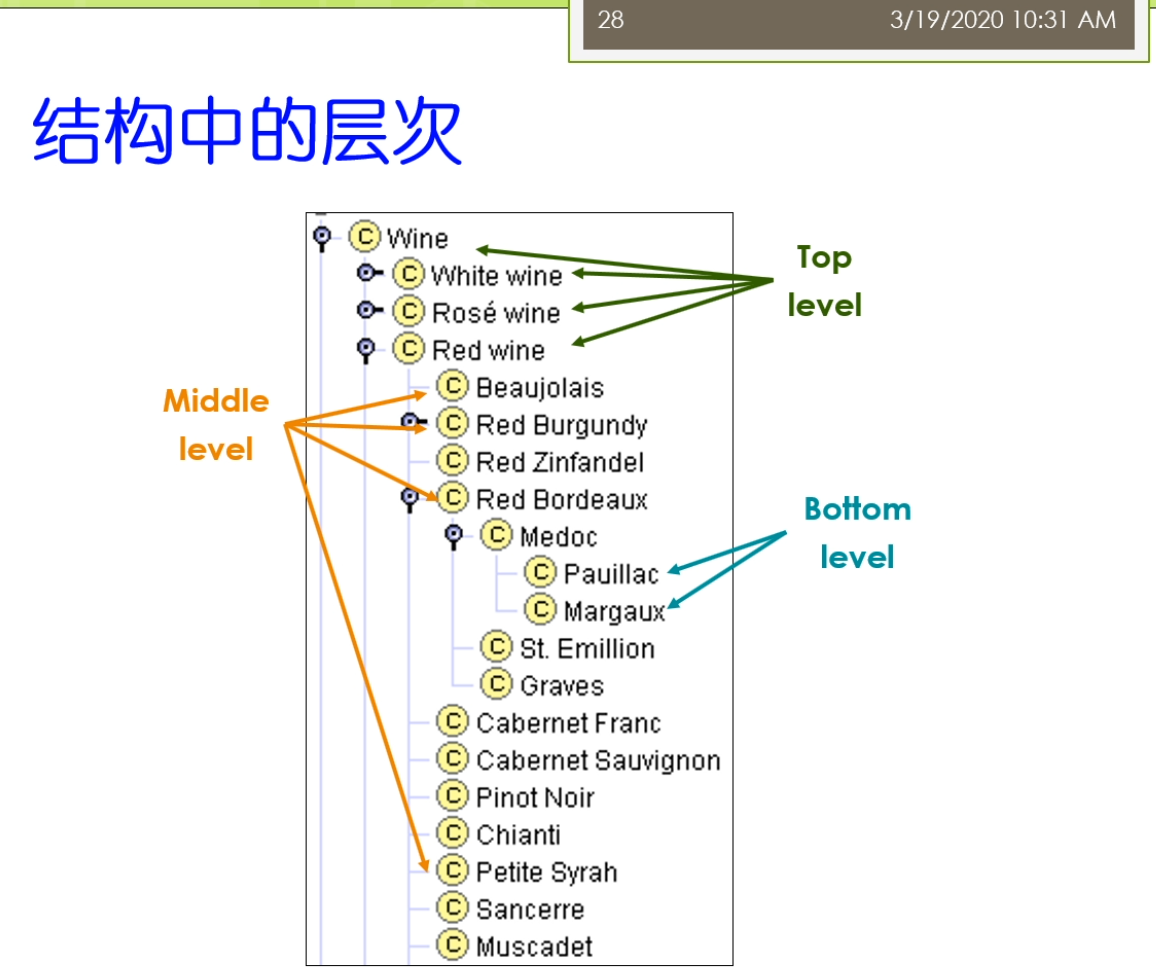
所以这呢,我们展示了一个小的例子,我们说啊,刚才对于葡萄酒来讲,那我们在这可以定义的一个这个层次关系了,这个层次关系里面大家可以看到,比如说我们这上面葡萄酒下面有几个分类,比如说白葡萄酒,玫瑰葡萄酒,红葡萄酒,那么这个又可以进一步展开,红葡萄酒下面呢,又有一些子类,那么逐步层次的向下去展开,那么最底下的这一层呢,如果它是这个叶子节点,那么就是最底层的,而这个上面的几层呢,一开始定义的我们把它称为叫这个上层啊,另外呢剩下的这部分呢就变成了中间的这些层

那么这个时候啊我们就会想到,那到底我们怎么样去组织这些类以及类的层次呢?实际上这里呢就会有一些这个相应的开发模式,比如说我可以自顶向下,我先定一下最通用的概念再具体化他们,我也可以来自底向上,我先定义了最具体的概念再组织他们呢构成更通用的类,那么也可以呢,我采用一些这个叫先重要的那么再不重要的这样一个混合的模式,比如说我先定义一些最核心的概念,然后呢,我在泛化和具体化了。泛化的过程呢,那么就是我向上自己向上的过程,而具体化呢,就是自己向下的过程,那么所以呢,这些模式实际上在我们的开发中间都会使用它,那么而且呢它们的使用可能是相互这个交,使用可能是相互这个交织在一块的,不见得你一定说我一定是可以自顶向上的的这样过程的去开发,因为我很可能啊会出现一些时候啊,我定义不太明确,或者我也想到一些很重要的东西,那么这时候我又要去修改
在这样的一个定义的过程中间,我们要进行一些相应的这个文档化。我们对于这个类和属性那么一般来讲,我们都需要呢,通常拥有文档这个文档呢,去使用呢自然语言描述,列出和类定义啊相关的一些领域的这个假设,那么列出来一些相应的这样一些同义词,那么这个类和属性的文档化呢,实际上和我们计算机程序的这个文档化呢一样的重要,那么这个里面呢,特别是在本体里面,我们刚才说到我们本体里面,我们我们上节课实际上说过有一些可以通过rdfs的comment或者seealso等等的一些东西啊,它有一些特殊的面向这些描述的自然语言描述的属性,我们要用好这些属性,那么通过这些属性来提供相应的这个文档,这方面呢和我们的数据库呢,稍微有些不一样,大家可能回想到你,在定义数据库的模式的时候呢,比如说定义一个表设计一个表头的时候呢,相对来讲,文档化来做的会差一点,那么你主要的还是面向数据存储的一个结构去定义,而本体呢,因为希望呢,它需要进行这个共用进行这个和重用或者这个分享,那么这个文档化呢,那么它的重要的程度呢?就更加重要。
那么在定义了这个类之后,我们要为这些类啊定义相应的一些属性,比如说我说类的这些属性实际上是描述的类的实例的属性和实例间的关系,那么比如说我说每种葡萄酒都有颜色含糖量生产商等等,那么这些呢就是我们说要定义的一些属性

那么这个属性我们在这里可以把它分为几类第1类,我们把它分为了这个根据类型的话,有一些是称为叫这个内涵属性内涵属性指的是这个葡萄酒,比如说它的味道,它的颜色等等,这些呢可以称为叫内涵属性,还有一些属性呢,把它称为它叫这个外延属性,比如说葡萄酒的名称和价格那个这样的我们把它称为来叫这个外研的属性,这个外研的属性,大家需要注意的是,它不是葡萄酒本身的一些特点,比如说这个葡萄酒的名字,那么它可能会发生一些变化或者它的价格会不断的发生变化,在市场上但是它都不影响这个是某一种具体的葡萄酒,因为这种葡萄酒它的特点实际上是由它的内涵去进行决定的,另外呢还有一些特殊的属性,比如说我们说这个包含的关系,我们这边称为部分,比如说一道菜它有什么原料,那么这个时候呢就是一种特殊的属性,另外呢,我们还可以有一些称为叫对象属性的东西,对象属性的,它实际上描述的是和其他对象的一些关系,比如说我们说葡萄酒的制造者,那么它的取值呢是一个酿酒厂,酿酒厂呢又是一个实例,那么我之前在这个叫owl规范里面,如果你想定义一个owl的本体,那么你一定呢要注意区分我们说的这个对象属性和这个数据类型的属性,这两种不同的属性,那么另外呢,这个属性啊,我们从这个这个具体的取值上来看呢,也可以把它分为了简单属性和复杂属性,简单属性主要包含基础值,比如说字符串数字等等而复杂属性呢主要包含或者指向其他的对象,比如说一个酿酒厂实例。

那么这里我们可以看到,比如说我们在这个这个界面相对来讲是一个比较老一点的那个界面,那么大家呢现在的这个界面呢可能跟他长得不一样,但是基本的思想指导是一样的。这俩我们可以定义一些这个Wine内的这个属性,比如说这些属性,我们有些名字有的包里。那么它的类型呢是一个这个符号,那么它呢只允许他有一个取值。那么这个里面来它允许的取值可能有几种。比如它是满的还是只有一半呢?还是这个比较轻的就快没有了,知道吧?或者它的颜色是红的还是玫瑰的,还是这个这个白色的。
那么接下来就是我们说的这个葡萄酒的相应的一些属性面板的第一行。那么这里属性它也可以形成这个这个在这个子类可以从这个父类的继承所有的这个属性。比如说我们有一种葡萄酒,它有名称,口味等等的属性,那么这个红葡萄酒来说,葡萄酒的一个子类。那么红葡萄酒了也就有这两个属性。你们俩不是说一个类,如果有多个父类的话,那么他可以从父类继承所有的这些属性。比如说我们说这个波特酒,那么它是一种餐后的甜酒,它也是一种红葡萄酒,那么它从前者来可能继承了一个叫含糖量高的这样的一个属性。而他从后者来又继承的一个叫颜色红色的属性,这个呢就是我们说的这个多继承。那么大家来很容易也可以想到这个多继承会带来很多的问题,这个来自我们大家做这个程序设计的时候,已经考虑
后面呢我们还有一些属性的这个约束。比如说属性的约束,描述或限制一个属性啊,可能的值的这个集合。比如说我们刚才做葡萄酒的名称的属性值嘞,他是一个字符串。某种呢这个葡萄酒的生产商来是酿酒厂的一个实例。我这两门还可以说每个酿酒厂嘞只有一个地址。那么这些人都是我们说的相映的这样的一些约束。那么这些约束了,有的很好表达,有的嘞不是那么好表达。比如说我们说这个葡萄酒的名称的属性值是一个字符串,那么这个唻我们比较容易表达出来。每个酿酒厂只有一个地址,那么这个来就会用到我们在owl里面说的最大的这个基数的限制,最小的基数的限制。这个来表达的时候呢就相对有点复杂了。那么这个来作为我们的这个大家课后作业的时候,你可以尝试着在这个protege这个软件里面。去构造一些相应的比较复杂一点的这个约束来试一试。
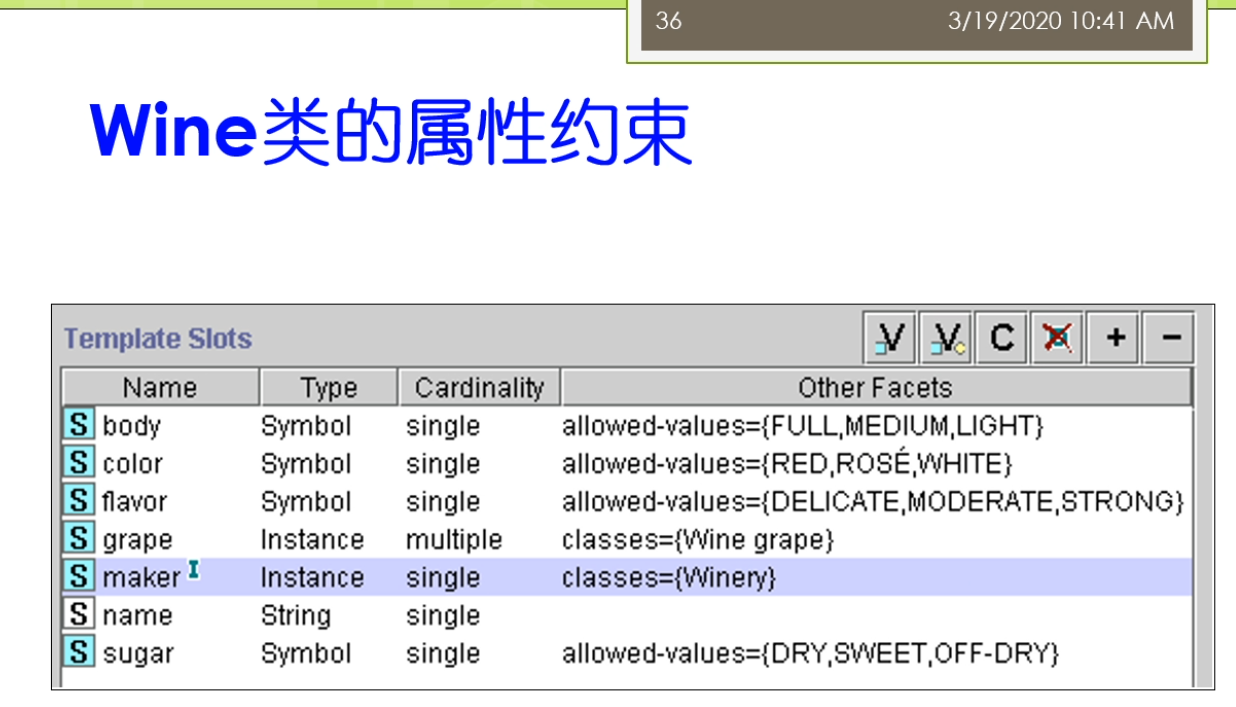
这我们刚才看到了,这边就有一些约束,这些约束里面包括了它是单值的还是多值的。包括他的允许的取值是什么?这个就是我们刚才说到的这些约束。

刚才说到的这些问题。常见的呢几个约束,我们主要有第一个我们把它称为叫这个属性的基数。也就是说一个属性啊能够拥有的值的数,比如说是多个还是一个是最多一个还是最少一个。等等这些我们把它称为来就基数。另外呢,我们还可以来有这个属性值的这个类型,比如说它的值是一个对象。还是个数据类型,那么数据类型里面又有很多。那么还有一些呢这个特殊的可以去定义,比如说它的一些最值,最大值,最小值。我最小有两个。这个取值范围最小的这个是2等等的,我还可以来有一些这个默认值。那么他的属性的一个缺省值等等。

那么在这里比如说对于基数来讲,基数n表示来这个属性必须要有嗯个值。而最小基数来表明的是最小激素。一表示这个属性啊必须要拥有一个只,这就形成了我们说的一种强制的约束,而最小基数的是零。表示在这个属性指的是可选I巨大技术,比如说最大基数是一,表明属性能够拥有最多一个值。这个时代就被称为叫单值属性,而最大基数大于1表明这个属性来能够拥有多于一个值。这个呢就被称为来叫这个多指属性。虽然这个基数的实际上是我们比较常用的,但是大家一定要在这儿设计好。因为有一些这个例外的情况,可能你没有考虑周全,那么你的这个基数的设置就会出了问题。比如说我们这里说你的基数。你说一个人他只能拥有一个姓名。那么这个时候呢这个可能那你就你就这个没有问题。那么但是在可能有一个例外的情况,比如说我原来有个同学,这个同学呢他的名字叫东方。那么东方来大家可能知道,那么他是一个这个复姓,对吧?这个是一个复姓就跟西门一样的。但是呢他起名字的时候呢,他这个他的父母的比较特别,那么它来这个就起的名字在就叫东方只有一个姓,他没有取这个名。那么这时候啊你如果刚才用了我们做的基数限制,那么可能就出现了这个违反的情况。所以呢这个东西呢就是设计的时候呢没有设计好。那么后来呢比如说他在这个她的户口本上呢,那么它就变成了姓变成东那么名变成方的否则了他就输入不了。那么这个呢就导致了他的一些这个不方便的地方。所以这个地方来大家一定要注意这个基数啊这些设置的时候要考虑的相对来讲比较周全。


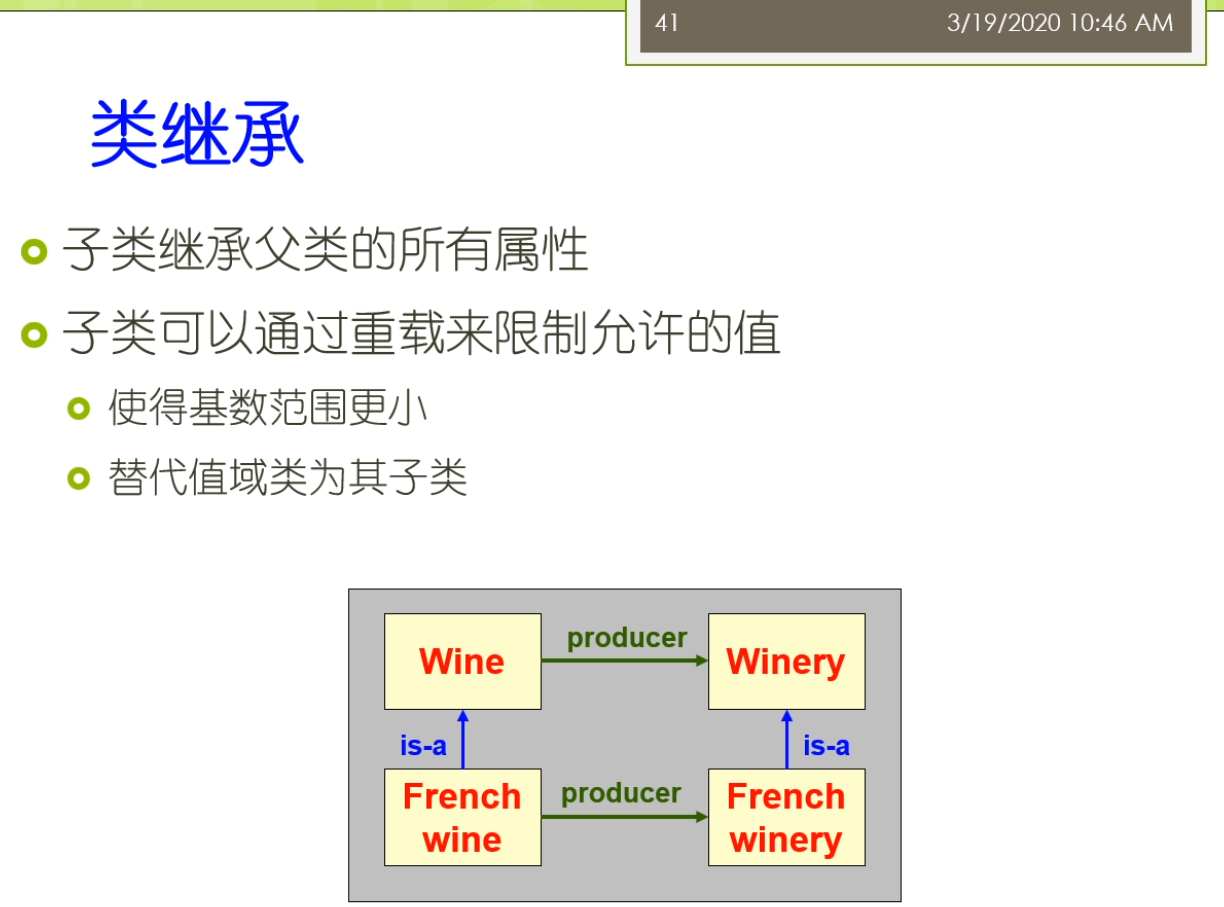
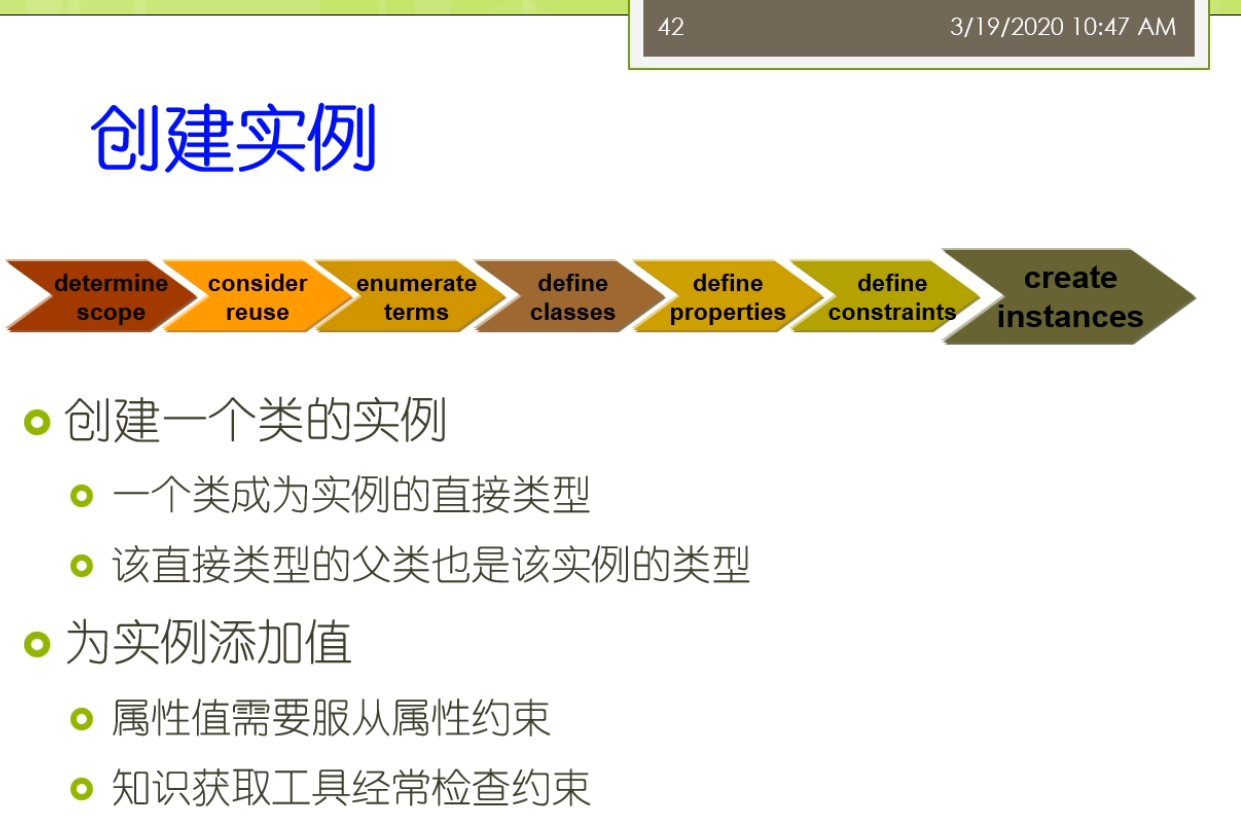
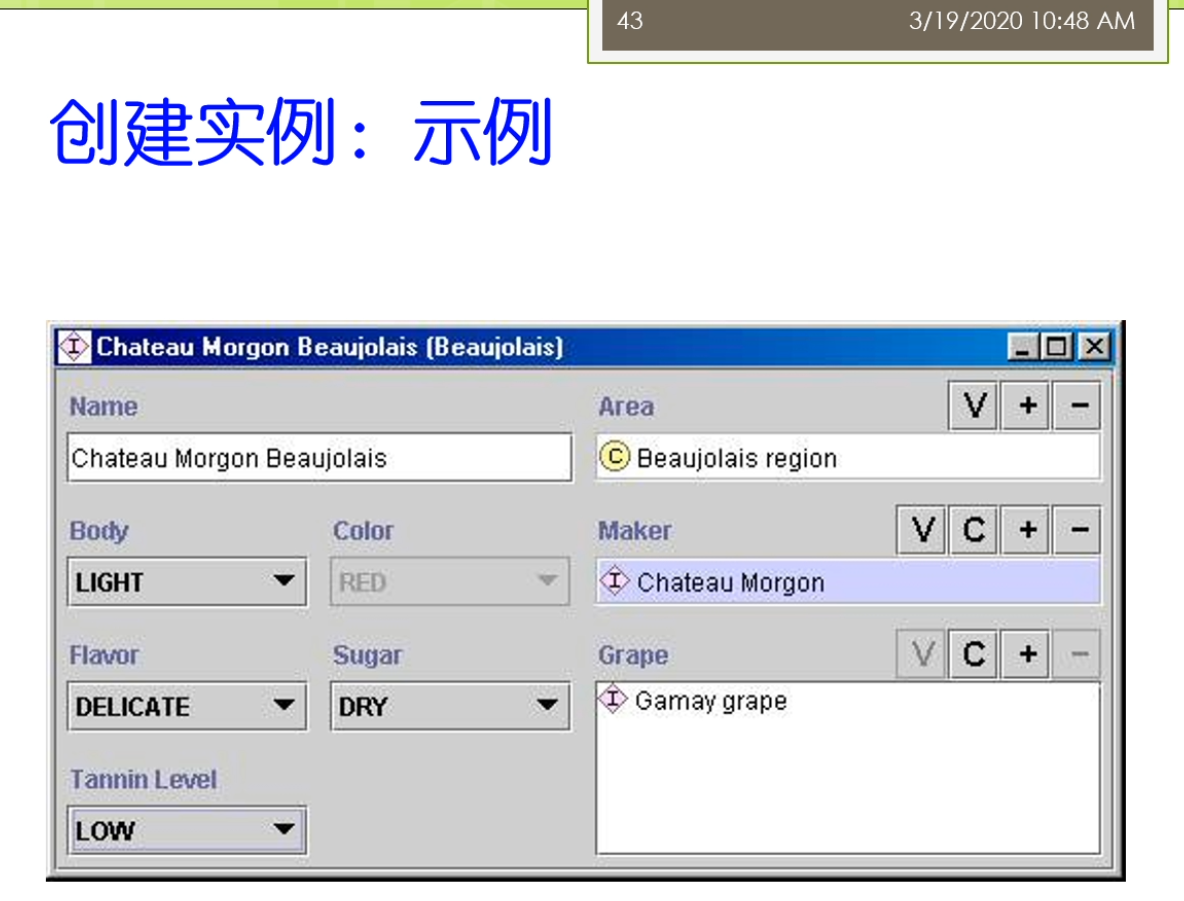



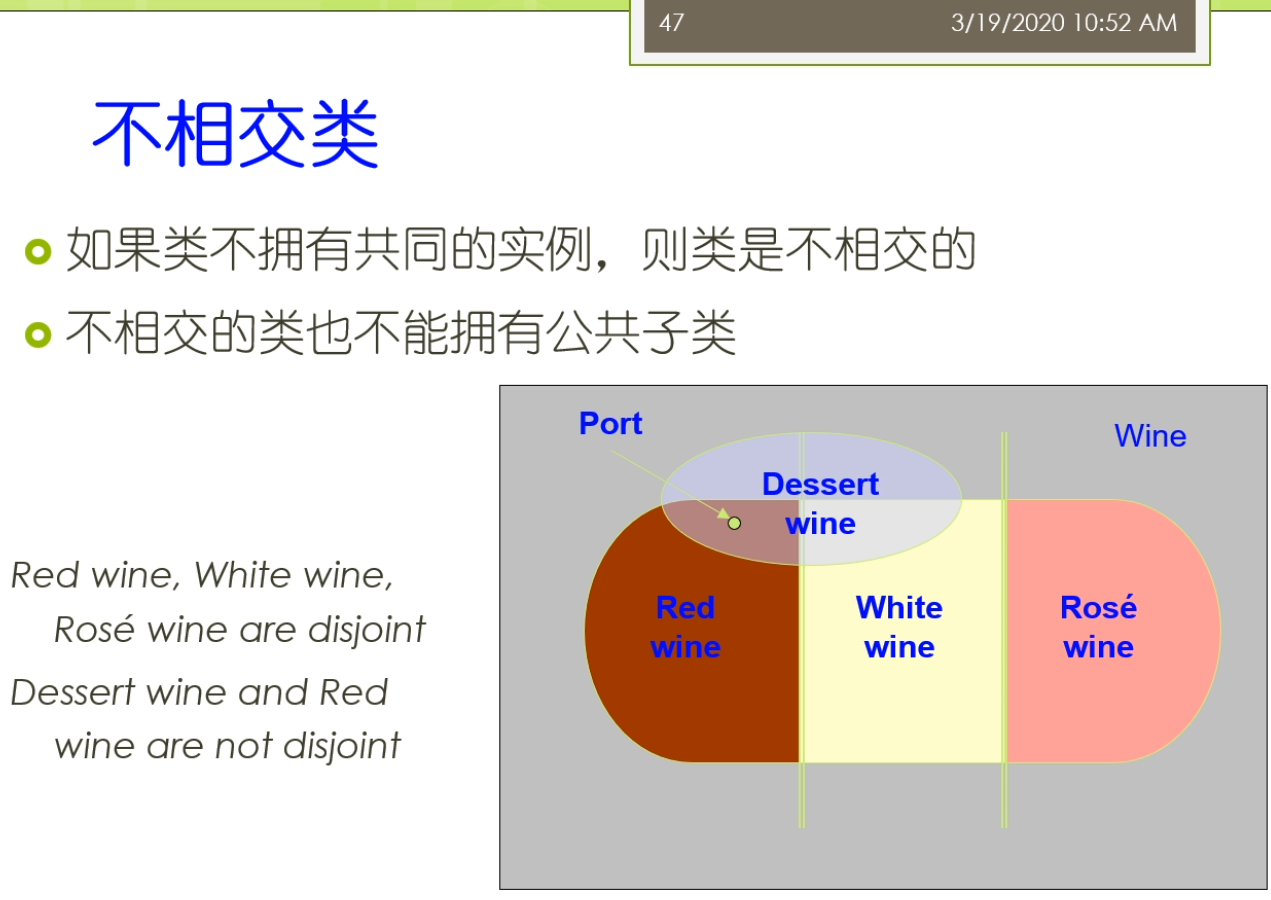
大家一定要注意这个基数啊这些设置的时候要考虑的相对来讲比较周全。数字是一个整型或者浮点型,还可能呢是布尔型的。或者来说没举行的还可以来说复杂类型,有的是另外一个类的实例。比如说我们说我们指定实力所属的类是什么?我们说有一个属性叫produces。那么对于葡萄酒来讲,那么它的produces的取值类型呢就是这个酒厂这样的各类那么实际上你在添加具体的数据的时候就变成了某一种这个这个具体的这个属性。那么具体的葡萄酒他的这个身材上来是某一个具体的酒厂。我形成了这样的一些事实,我们坐在fact。因为这个属性里面我们常见的还要去定义它的定义域和值域。低于玉表示的是拥有属性的类或者一组类。更精确地才是类或者一组类的实例还可以拥有这个数字。而侄女来说的是这个属性值属于在这个类或者来一组来。那么这个亮亮我们还稍微再强调一下我们之前说的这个定义域和值域,如果你定义了多个定义域,他们之间呢实际上是一个教的关系。而不是一个这个病的关系。这个呢是大家常犯的一个错误,所以在大家一定要注意。因为你在这里我们还可以定义这个类的继承子类来会继承父类的所有属性。而此类的也可以通过了这个重载来限制允许的这个值使得在这个激素的范围呀。这个更小或者来替代来治愈类为他的这个子类。比如说我们这里可以说我们一个葡萄酒的这个生产商,那么是这个葡萄酒厂。那么法国葡萄酒来是葡萄酒的一个子类,呃,然后呢呃这个法国葡萄酒的是一个葡萄酒,一种葡萄酒,而这个法国的葡萄酒厂来也是一种这个这个葡萄酒厂。那么这时候呢他们之间呢就是法国葡萄酒来,那么它的生产商呢就是法国的这个葡萄酒厂。那么你最后嘞我们就会要去创建了一些相关的一些类的实例了。比如说一个类成为实力的一个直接类型。那么该直接类型的这个父类人他也是这个实力了和类型。我们之前举到的这个招商的例子,当灾难是一个研究生。那么张三呢也就是一个学生,他的这个类的它既是这个研究生的这个实力。也是在学生的实力,而研究生但是它的直接类型。而为这个实力呢还可以去添加一些值属性,只在需要服从我们刚才属性的约束。而这个知识来,那么需要来这个呃需要这个知识获取的工具来经常来进行这些检查,看看了是否存在这个违反约束的这样一些情况。这里比如说我们可以看到一个实力,在这里我们添加那个具体的一个实例。这个实力,但是它的一个名字,然后呢说它的这个具体的一些相应的属性属性的取值是什么?大家可以看到刚才来对于有一些取值只允许单值的时候,那么它就变成了从候选中间选择相映的一个。结果如果在它的取值来是一个我做的一个一个这个对象的话,那么这来他可以选一个相应的一个实例,比如说他的葡萄酒是具体的某一啊,这个葡萄是具体的某一种葡萄,它在这个生产商是具体的某一个酒厂等等的。那么这个呢前面呢我们主要是介绍了这个斯坦福啊这个七步法,那么它的一个过程的七个步骤到底是怎么样的含义?那么在这个开发的过程中年时,当我们还会遇到各种常见的一些问题,那我们这儿来会把它稍微介绍一下,并且来我们也介绍一下这个大家常使用的一些解决的方案。比如说第一个我们对于这个开发的流程上来讲,我们的这个流程主要是使用的是广度优先的这个覆盖还是这个深度有限的这个覆盖。谁让这就是我们开发总监经常会遇到的一个问题。因为我去定义这个类属性和约束的时候,比如说对鱼类而言。我可以一开始组建的想去定义的是这个这个兄弟类的这样的关系。这种事后来我就是个广东有线的过程,而如果呢我总是不断的去深挖,去这个考虑这样的一个父子类的关系。那么这时候呢就会去变成那个深度有限的这样的一个。在这个过程里面呢,那么我们就需要考虑到底我是广度还是深度的涨的有限幅度。那么我们需要在定义类和类层次的时候,我们需要记住。正确的这个类层次啊,他不是唯一的。他不是做这个类层次,某一种必须只有一种类型。那么大家身上也会看到在很多的不同的本体里面,比如说对于生物医学这个领域而言,他在这个内存是定义啊经常不太一样,因为这个来事和现实世界对现实世界里面许多的概念,这个不同的这个专家学者他的理解也不太一样。没有一个公认的所必须怎么样去做才是最正确的这样的一个一个指导。那么这种情况下呢就不存在唯一正确的这个类层次。但是呢这里来也有一些这个指导的原则。这些指导的原则来可以帮助你区分出来什么是一个相对比较好的类层次的定义儿,怎么了?可能是一个错误的,或者不太好的想内存四的电。比如说我们这里可能要问一些问题,是这个子类的每一个实例。是不是都是负累的这个实力?如果他不是得,那么这时候呢就可能会出现了一些这个定义上的错误。另外我们还可以做到我们可能有这个多继承。这个多继承了一个类,它可以有多个这个父类。那么子类的会从父类继承所有的属性和约束。那么这个前面我们回会很直接的考虑到多继承会引起这个冲突的问题。那么不同的系统了,他处理冲突的方法不一样,常见的时候呢有一些是一种他可能就要冲突忽略。那么他遇到冲突啊,他不管他。那么也有来这个叫冲突消解的这样的一个方法,他可能会弹出一个框,让这个用户去解决说我更相信谁,或者我选择哪一个别的这个冲突的,我就把它处理掉。那么这个里面的有很多不同的处理方法,也有很多相应的一些研究。那么另外呢我们说在这个类里面,我们刚才主要去定义了是这个类层次的关系。那么累层次的关系来表明他们之间的有关,那么也可以来去定义,比如说在殴打布莱尔里面,我们也可以去定义这个不相交的人。也就是说如果这个类啊不拥有共同的实力,则这个类来他是不想交。那么不相交的这个类来他也就不能拥有了共同的这个子类了。所以这个量来大家可以看到我们比如说假设,我们说我们有红葡萄酒,白葡萄酒和这个玫瑰葡萄酒。那么他们俩是这个不相交的。我们又可以来说这个具体的一个这个甜点的这样一个葡萄酒和这个红葡萄酒来。那么他不是不相交的。也就是说大家可以看到在这个里面我们说的比如说对于这样的一个葡萄酒,他可能既是这个红葡萄酒也是这个白葡萄酒,那么这时候我们就产生了一个矛盾的,因为我们刚才说这个红葡萄酒和白葡萄酒是不想交的。那么但是有一种这个葡萄酒,他可能说他既是红葡萄酒,又可能是这个白葡萄酒。这种情况下就不太好。所以在这个地方对于这个不相交的这个定义啊,一定要这个相对来讲这个比较严格的处理。那么有许多例外的一些情况可能会导致的你的定义呀出现了一些这个不完备的介情况。另外俩我们还可以说我们要避免了一些累的这个循环定义。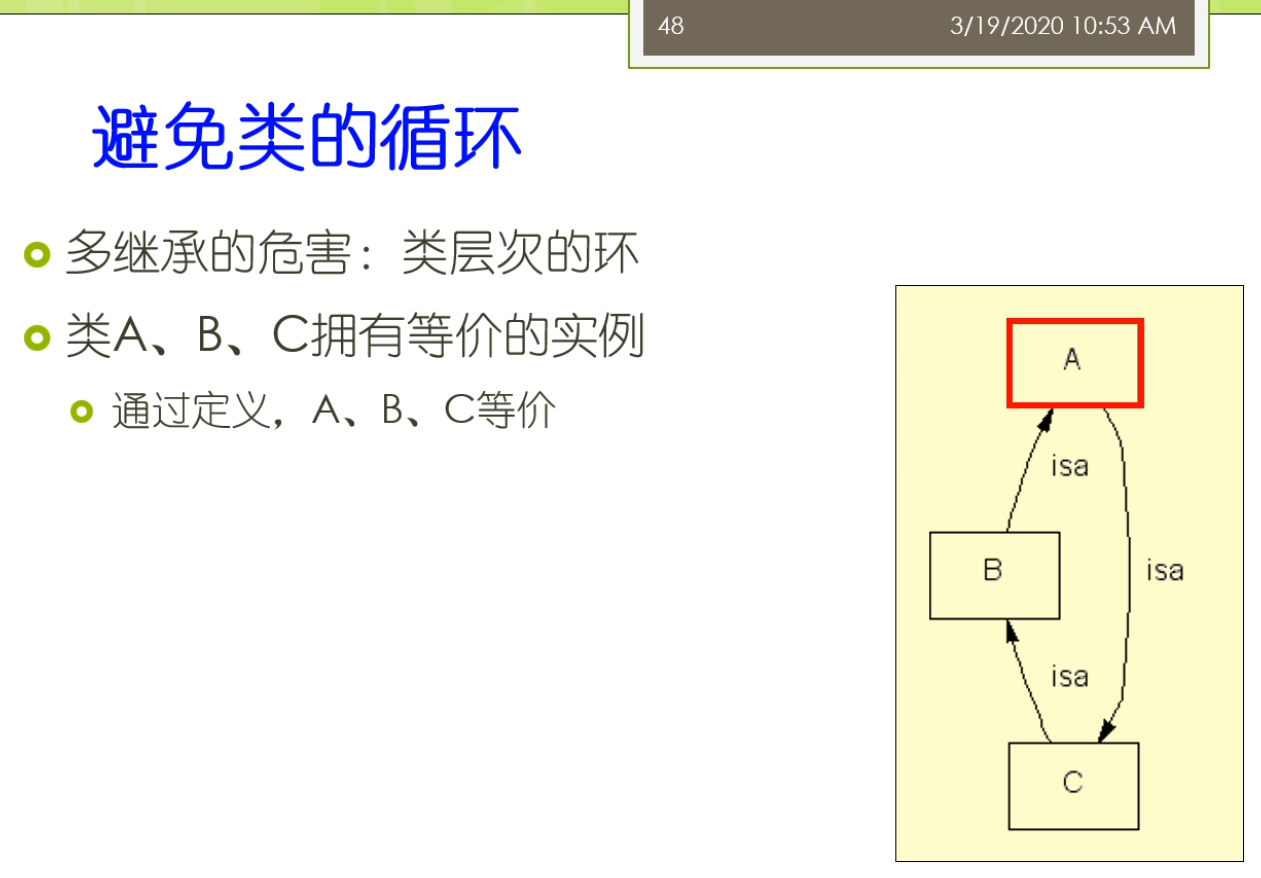
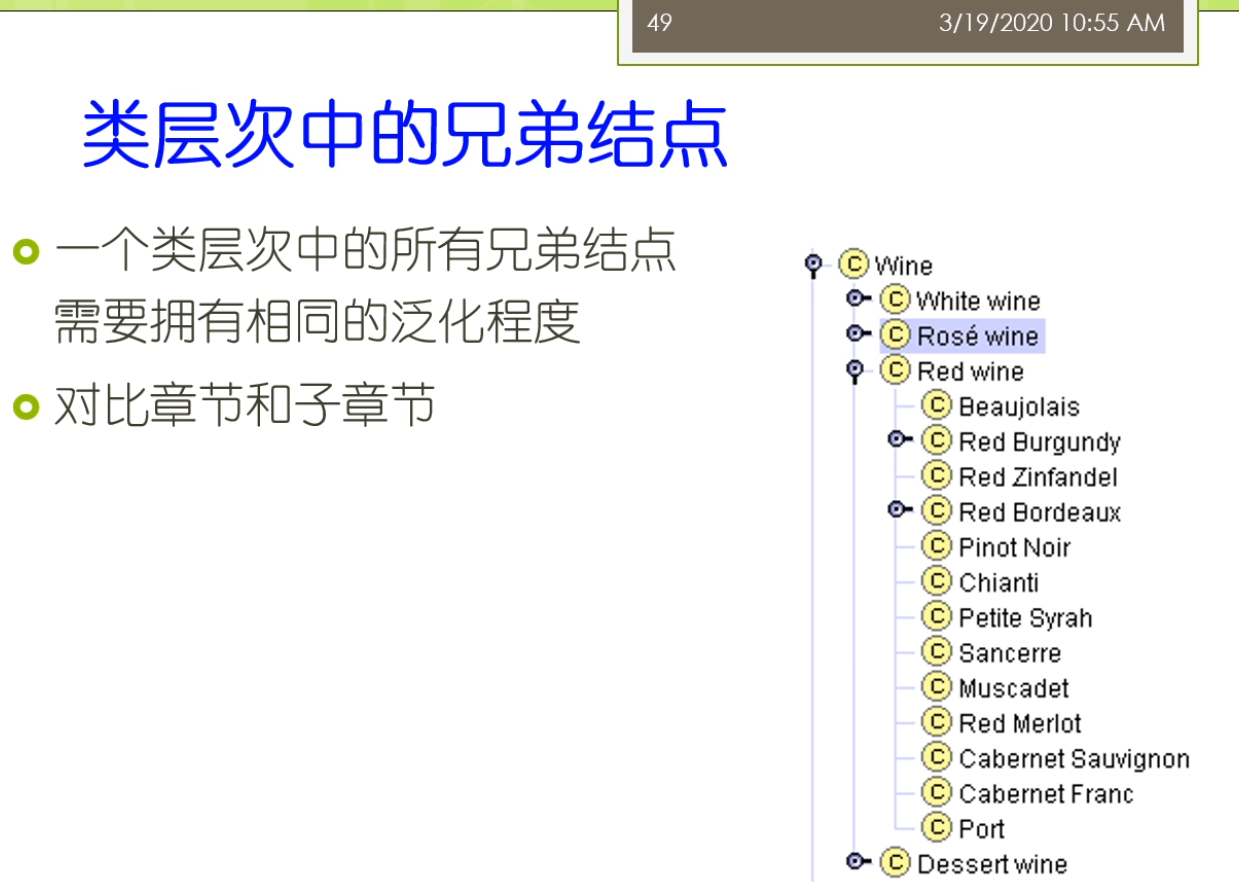


我们要并可能会导致的你的定义呀出现了一些这个不完备的介情况。另外两个我们还可以说我们要避免了一些累的这个循环定义。多继承的一种危害来就会导致比如说我这个类来出现一些这个还。那么比如说我们这里有一个例子,我们做b是a的这个子类,虽然又是b的子类,那么ad就是c的子类。那么这说话它就形成了一个环状静环状的这样一个定义,通过最重要的定义了谁让它表明的是这个ABC三者之间是一个等价的。那么这个等价的处理我们前面在里面说过,那么等价类他有专门的叫equivalent class,那么等加的属性呢友equivalent的property尔等家的实力来叫c must,那么实际上呢他有相映的这个处理方法可以寄出。可以去做。那么在这里呢,那么你应该来首专业的术语去定义,而不是在这个用这种隐含的这种循环定义的这样的一个方式去表明他们之间等价关系。那么如果你采用的是这样的一个策略的话,那么你又发现了你有这种循环定义,那么可能呢你就知道哦这个是你定义中间的一个错误,而不是你故意想定义它们之间等价关系了。另外我们在这里我们还会看到一点,我们做这个类层次,中间我们有这些兄弟节点。一个内存是中间的这个所有兄弟节点呢,一般来讲它需要有相同的这个泛化程度。不能说啊这个幻化的这个程度来不一样。这个地方来大家可以类比一下我们这个大家可能去看论文或者写论文里面的这个章节和章节的这个关系。一般来讲一个章节下面的各个子章节他们应该是一种平行的关系,相对来讲就是泛化程度比较相近,相同的。那么在我们这个例子里面,比如说我们说葡萄酒下面有三种,白葡萄酒,红葡萄酒和这个玫瑰葡萄酒。那么他们呢是相对来讲这个饭花锦缎比较类似的价格。那么否则的话呢你如果定义的不太对等的,那么就会感觉这个建模有一点这个不合适。那么还有嘞你定义的这样的一个子类的时候,那么你就可能会有一个规模的问题。比如说一个成员他的最佳的规模是多少?比如说我说如果有一个类,他只有一个子类。那么这实话你就可能存在一些建模的问题。比如说我们说有一种叫这个红的这样的一个葡萄酒,它只有一个子类。那么这时候别人就会反问你了,说那你这时候为什么还要引入这个子类的层次结构呢?那你为什么还要定义这个red的这个样的一个一个概念呢?那么这样的一个类它是让可能不需要你直接把这个子类本的。这个取出来就可以了,因为他只有这一个字。那么所以正确的定义来讲,一般来讲一个类它至少得要有比如说两个字的相对来讲的比较合适。那么以后只有唯一的一个子类的有一点不太好。而和他相对应的是有的时候啊一个类它可能拥有众多的子类。比如说我们在右边的这个图里面,我们做外下面有这么多的子类。在最右边的这个图里,这种情况下这个定义也不是很好。这种情况下呢,那么他可能就需要一些额外的一些这个子的分类结构去帮助你把众多的子类更好的这个组织起来,就变成了我们左边的这个图的样子。虽然大家看看如果写的左边的图的这个样子,大家感觉这个结构来更加清晰一点儿,右边了把所有的罗列都罗列成这个葡萄酒的子类的话,这种定义的适当的不太好。但是这里有个例外的情况,就是如果你列举了这一大堆子类,那么这种情况下呢你可能列举了这样所有的这些列表也可能呢是一种很自然的这种方式,你就说你做不出来这个具体的一些分类的时候,那么你也只有了把这个所有的这样的一些例子。把他列在这。

